使用 InfluxDB 进行基础设施监控 | 现场演示
分布式追踪
追踪是一种了解分布式系统中互连组件如何相互交互的方法。
什么是分布式追踪?
追踪是一种了解分布式系统中互连组件如何相互交互的方法。流程和服务之间的互连意味着某些流程和服务可能依赖于应用程序或流程中的其他流程和服务。因此,一个(或多个)区域中的错误、延迟和瓶颈可能会影响整体系统性能。
追踪揭示了所有这些不同的部分如何协同工作。追踪提供了请求、任务、操作、作业或其他有用的工作单元在分布式系统中运行的视图。许多子任务(算法、网络调用、数据库事务、缓存查询等)协同工作以满足请求。每个子任务都是一个 Span。
一个追踪由 Span 的集合组成,这些 Span 提供了有关请求更精细细节的时间信息。
追踪如何工作?
Span 有零个到多个子 Span,称为子 Span 或子级。子 Span 可以有自己的子级,依此类推。
追踪从根 Span 开始。根 Span 没有父 Span,并且由于它是追踪中所有其他 Span 的递归父级,因此根 Span 的持续时间表示追踪的总时间。
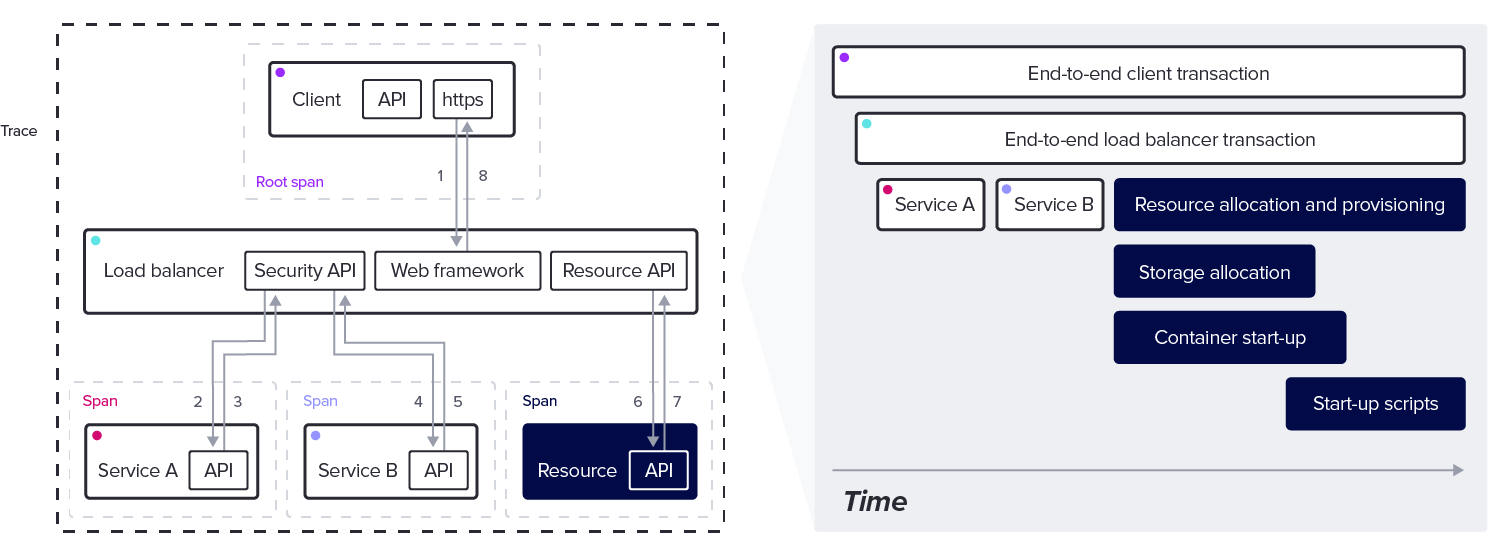
如图所示,单个追踪包含许多潜在的 Span。
每个 Span 都需要识别信息,以确保追踪可以正确地将所有数据拼凑在一起。每个 Span 都有一个追踪 ID、一个 Span ID,以及在适用的情况下,一个父 Span ID。
这些构建块创建了子任务的层次树,为构建追踪提供了关键结构。
使用 InfluxDB 进行追踪
由于每个 Span 都包含唯一的 ID,因此追踪数据是高基数时间序列数据。InfluxDB 的时间序列合并树 (TSM) 引擎在高基数追踪数据方面遇到了困难,但其更新的存储引擎解决了基数问题,使 InfluxDB 成为存储和分析追踪数据的理想解决方案。



