使用 InfluxDB 进行基础设施监控 | 现场演示
Apache Parquet
Apache Parquet 是一种开源列式数据文件格式,它支持不同的编码和压缩方案,以优化批量高效数据存储和检索。
Apache Parquet 是一种开源列式数据文件格式,起源于 Cloudera,专为快速处理复杂数据而设计。最初旨在处理 Apache Hadoop 生态系统的数据交换,此后已被许多开源项目(如 Delta Lake、Apache Iceberg 和 InfluxDB)以及大数据系统(如 Hive、Drill、Impala、Presto、Spark、Kudu、Redshift、BigQuery、Snowflake、Clickhouse 等)采用。许多这些项目都围绕 Parquet 文件和弹性查询层构建,后者处理这些文件。
Parquet 支持基于列的不同编码和压缩方案,从而可以批量高效地存储和检索数据。它还支持字典编码和行程长度编码 (RLE),以及各种数据类型,如数值数据、文本数据和结构化数据(如 JSON)。Parquet 是自描述的,并允许在每个列的基础上包含元数据(如模式、最小值/最大值和 Bloom 过滤器)。这有助于查询计划器和执行器优化需要从 Paquet 文件中读取和解码的内容。
此外,它围绕使用 记录切分和组装算法 的嵌套数据结构构建,该算法首次在 Google 发布的 Dremel 论文中描述。
Apache Parquet 是 Apache Arrow 项目的一部分,因此它支持多种语言,包括 Java、C++、Python、R、Ruby、JavaScript、Rust 和 Go。
Parquet 的优势
性能 — 由于在执行查询时可以扫描列的子集,因此减少了 I/O 和计算。每个列的元数据和压缩对此有所帮助。
压缩 — 将同构数据组织成列可以实现更好的压缩。字典和行程长度编码为重复值提供了高效的存储。
开源 — 强大的开源生态系统,由充满活力的社区不断改进和维护。
Parquet 如何存储数据
让我们使用一个示例来了解 Parquet 如何以列的形式存储数据。以下是包含 ID、类型和位置信息的 3 个传感器的简单数据集。当您以基于行的格式(如 csv 或 Arvo)保存时,它看起来像这样

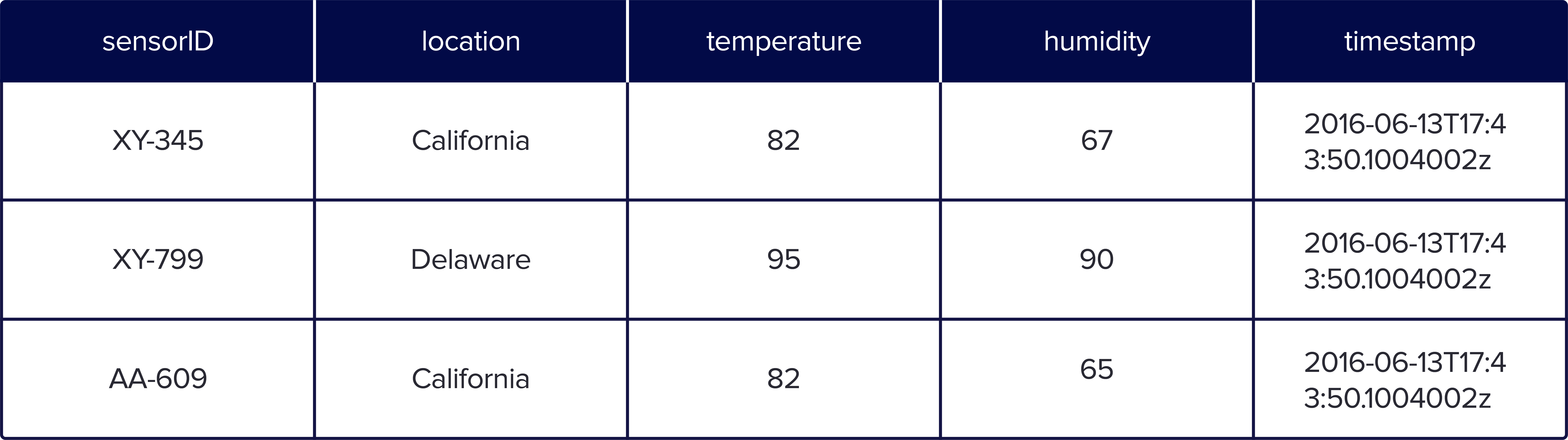
当您以 Parquet 列式格式存储时,您的数据将按列组织,每列包含特定的数据类型,如下所示
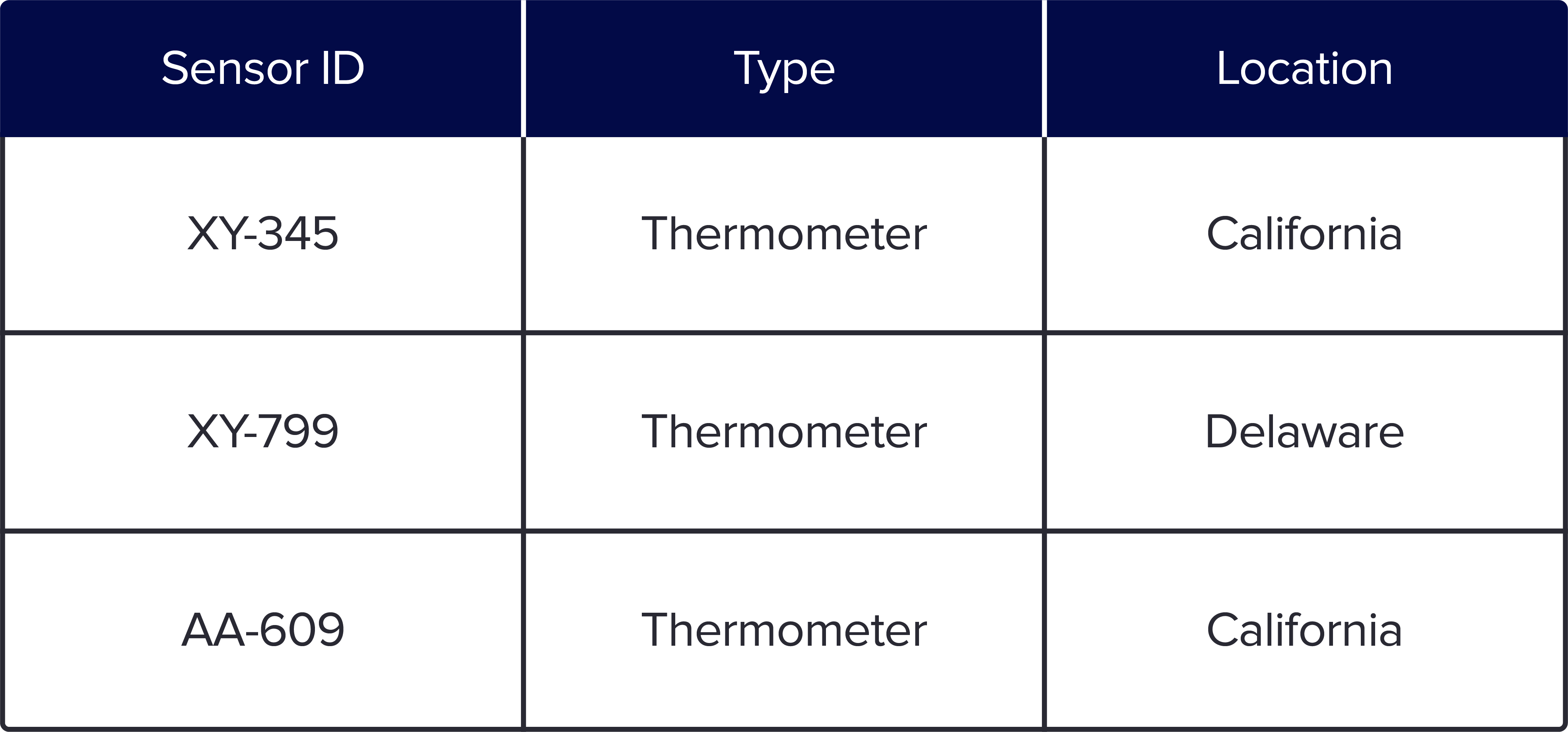
基于行的格式易于理解,因为它是在电子表格中看到的典型格式。但是,对于任何类型的大规模查询,列式格式都具有优势,因为您可以查询回答查询所需的列子集。此外,存储更具成本效益,因为基于行的存储(如 CSV)的数据压缩效率不如 Parquet。
InfluxDB 和 Parquet 文件格式
这是一个我们将用于演示 InfluxDB 如何以 Parquet 文件格式存储时序数据的示例。

度量映射到一个或多个 Parquet 文件,标签、字段和时间戳映射到单个列。这些列使用不同的编码方案以获得最佳的压缩效果。
此外,数据以非重叠的时间范围组织。这里我们有 3 个示例 Parquet 文件,用于相同的度量,但分为 3 个不同的时间分组。
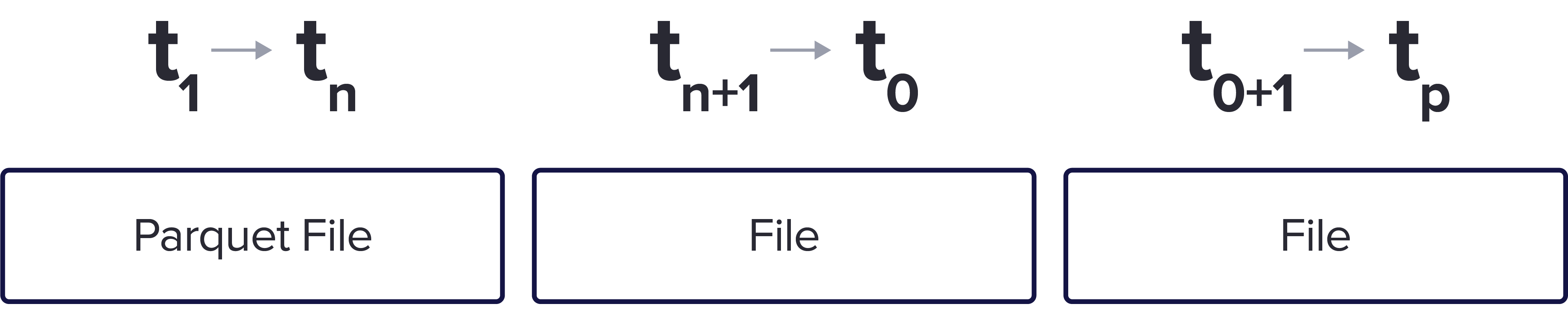
这可以执行更快的查询,因为它允许用户收集特定时间范围内的数据。此外,如果需要,以这种方式存储时序数据可以轻松地清除数据以节省空间。
Parquet 和互操作性
Parquet 的开源性质及其在其他技术和生态系统中的广泛采用意味着 Parquet 用户可以在其他应用程序中利用以 Parquet 文件存储的时序数据。这允许用户将时序数据的价值和功效扩展到以前不可能实现的领域和应用。



