InfluxQL 在 3.0 中的重生:配置和使用快速入门指南
作者:Jay Clifford / 产品
2023 年 6 月 30 日
导航至
如果我们把时间倒回到 2013 年 9 月,我们发布了 InfluxQL 以及 InfluxDB。InfluxQL 是一种类似 SQL 的查询语言,专门设计用于查询时间序列数据。对于我们的许多用户来说,InfluxQL 仍然是他们与 InfluxDB 交互的主要方式。基于此反馈,InfluxQL 在 InfluxDB 3.0 中与 SQL 查询语言的本机支持一起重生。
那么我说的重生是什么意思呢?好吧,如果您不知道,我们在三个关键的开源项目上构建了 InfluxDB 3.0
Apache DataFusion 充当 InfluxDB 3.0 的基础查询引擎,提供我们的本机 SQL 支持。我们的工程师扩展了查询引擎,以本机支持 InfluxQL。这使开发人员能够在使用基于 InfluxQL 的查询时,充分利用 Apache Arrow Flight 的全部性能。
在本博客中,我们将了解如何通过我们新的 v3 客户端库来利用 InfluxQL。我们将讨论如何为 Serverless 和 Dedicated 配置 v1 InfluxQL API,这为 InfluxQL 插件(如 Grafana 和 NodeRed)提供了向后兼容性。
v3 客户端库
我们目前有五个 v3 基于社区的客户端库
| 客户端库 | 状态 | 查询语言 |
|---|---|---|
| C# | 就绪 | SQL, InfluxQL |
| Go | 就绪 | SQL, InfluxQL |
| Python | 就绪 | SQL, InfluxQL |
| Java | 就绪 | SQL, InfluxQL |
| JavaScript | 就绪 | SQL, InfluxQL |
这些客户端库都支持使用 InfluxDB 进行写入和查询。如果您想深入了解它们的当前状态,我强烈建议您查看这篇博客。
让我们看一下几个利用新的 InfluxQL 查询功能的客户端示例。
Python
让我们从一个 Python 示例开始
import influxdb_client_3 as InfluxDBClient3
client = InfluxDBClient3.InfluxDBClient3(
token="<INSERT TOKEN>",
host="eu-central-1-1.aws.cloud2.influxdata.com",
org="6a841c0c08328fb1",
database="database")
table = client.query(
query="SELECT * FROM <MEASUREMENT> WHERE time > now() - 4h",
language="influxql")
print(table.to_pandas())正如您所见,我们创建了一个名为“client”的新客户端实例。然后我们调用 query(),它接受以下参数:
-
Query:您要执行的查询的字符串字面量表示形式。这可以是基于 SQL 或 InfluxQL 的。
-
Language:此参数指示您的查询字符串字面量是 InfluxQL 还是 SQL。
注意:将 language 参数设置为 influxql 非常重要,因为 SQL 是默认查询语言。
Go
接下来,我们来看一个 Go 示例
import (
"context"
"encoding/json"
"fmt"
"os"
"github.com/InfluxCommunity/influxdb3-go/influx"
)
url := os.Getenv("INFLUXDB_URL")
token := os.Getenv("INFLUXDB_TOKEN")
database := os.Getenv("INFLUXDB_DATABASE")
// Create a new client using an InfluxDB server base URL and an authentication token
client, err := influx.New(influx.Configs{
HostURL: url,
AuthToken: token,
})
// Close client at the end and escalate error if present
defer func (client *influx.Client) {
err := client.Close()
if err != nil {
panic(err)
}
}(client)
query := `SELECT * FROM <MEASUREMENT> WHERE time > now() - 4h`;
iterator, err := client.QueryInfluxQL(context.Background(), database, query, nil)
if err != nil {
panic(err)
}
for iterator.Next() {
value := iterator.Value()
fmt.Printf("avg is %f\n", value["avg"])
fmt.Printf("max is %f\n", value["max"])
}在此示例中,我们遵循与 Python 客户端库类似的实践,但我们没有使用 language 参数,而是使用了 client.QueryInfluxQL 函数。
JavaScript
最后,让我们考虑一个 JavaScript 示例
import {InfluxDBClient, Point} from '../index' // replace with @influxdata/influxdb3-client in your project
type Defined<T> = Exclude<T, undefined>
/* allows to throw error as expression */
const throwReturn = <T>(err: Error): Defined<T> => {
throw err
}
async function main() {
// Use environment variables to initialize client
const url = 'INFLUXDB_URL'
const token = 'INFLUXDB_TOKEN'
const database = 'INFLUXDB_DATABASE'
// Create a new client using an InfluxDB server base URL and an authentication token
const client = new InfluxDBClient({url, token})
// Prepare flightsql query
const query = `SELECT * FROM <MEASUREMENT> WHERE time > now() - 4h`
// Execute query
const queryResult = await client.query(database, query, ‘influxql’)
for await (const row of queryResult) {
console.log(`avg is ${row.get('avg')}`)
console.log(`max is ${row.get('max')}`)
}
} catch (err) {
console.error(err)
} finally {
await client.close()
}
}
main()与 Python 库一样,我们提供凭据来实例化客户端。我们调用 client.query(),包括 influxql 作为 queryType 参数。
v1 InfluxQL API
我们介绍了客户端库,它们使用 Arrow Flight 与 InfluxDB 3.0 通信。这对于构建新应用程序非常有效,但没有为当前的 InfluxQL 应用程序和插件提供通用的通信方法,因为它们使用 InfluxDB API 运行。这就是 v1 API 发挥作用的地方。
v1 API 有一个 v1 查询端点,它接收传入的查询请求,将其传递给查询调度程序,然后运行查询。然后,结果被传递回 v1 API 端点,然后返回以完成 API 请求。
注意:在撰写本博客时,Serverless 和 Dedicated 之间 V1 API 的设置方式存在明显的差异。
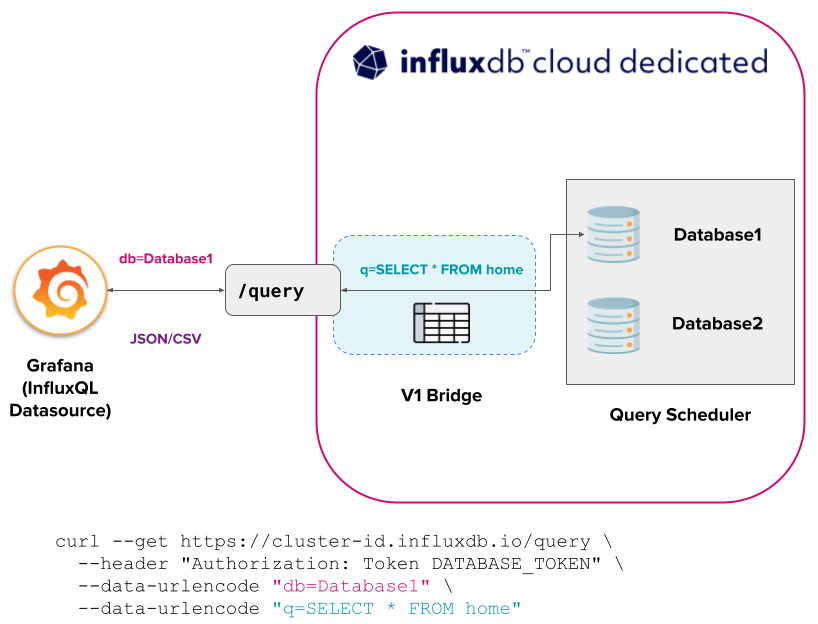
InfluxDB Cloud Dedicated
由于 v1 API 桥接,创建的每个数据库都固有地与 v1 API 兼容。
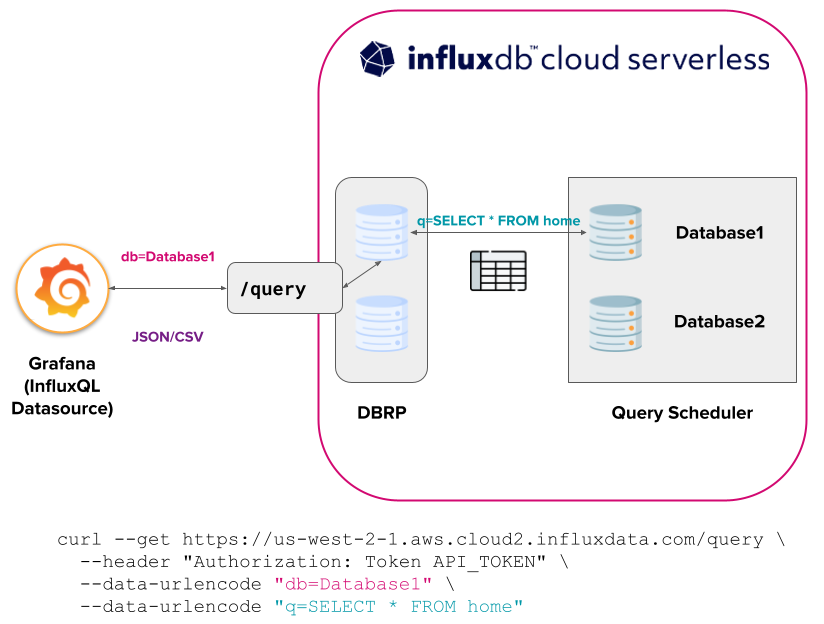
InfluxDB Cloud Serverless
Serverless 当前需要创建 DBRP 映射,以初始化针对 InfluxDB 3.0 数据库执行 v1 API InfluxQL 查询。
接下来,让我们看一下如何为 Serverless 配置 DBRP 映射。
使用 DBRP 配置桥接(Serverless)
注意:请务必查看文档以获取更新,因为此功能正在积极开发中。 Cloud Dedicated 用户可以跳过此步骤!
目前,您必须手动为每个希望通过 v1 API Bridge 使用的数据库创建 DBRP。您可以通过两种方式执行此操作
- InfluxDB CLI:使用此方法,您必须在主机上安装 InfluxDB CLI。确保您还配置了指向 InfluxDB 3.0 实例的初始配置配置文件。接下来,运行以下命令
influx v1 dbrp create \ --token API_TOKEN \ --db DATABASE_NAME \ --rp RETENTION_POLICY_NAME \ --bucket-id BUCKET_ID \ --default - API 令牌进行身份验证。我们建议将您的令牌设置为 influx CLI 中的活动 InfluxDB 连接配置,这样您就不必将这些参数添加到每个命令中。要设置您的活动 InfluxDB 配置,请参阅 influx config set。
- 数据库名称以进行映射
- 保留策略名称以进行映射
- 要映射到的Bucket ID
- Default — 此标志将提供的保留策略设置为数据库的默认保留策略。
- InfluxDB API:如果您希望直接与 API 交互,您可以通过以下 curl 请求执行此操作
curl --request POST https://us-west-2-1.aws.cloud2.influxdata.com/api/v2/dbrps \ --header "Authorization: Token API_TOKEN" \ --header 'Content-type: application/json' \ --data '{ "bucketID": "BUCKET_ID", "database": "DATABASE_NAME", "default": true, "orgID": "ORG_ID", "retention_policy": "RETENTION_POLICY_NAME" }'
正如您所见,curl 需要与 CLI 相同的参数。如果您有很多数据库要映射到 Serverless 中,那么我强烈建议您设置 InfluxDB CLI 并使用此 bash 脚本
#!/bin/bash
# Run influx bucket list and parse the output
influx bucket list | awk '
BEGIN {
# Skip the header line
getline
}
{
# Extract the values
bucket_id = $1
database_name = $2
# Construct and run the influx v1 dbrp create command
cmd = "influx v1 dbrp create --db " database_name " --rp " database_name " --bucket-id " bucket_id " --default"
system(cmd)
}'这将每个数据库/Bucket 映射到其自己的 DBRP。
Grafana InfluxQL 数据源
现在我们创建了第一个 v1 映射,让我们在 Grafana 中将其与 InfluxQL 数据源一起使用。让我们分两个阶段查看配置
阶段 1:身份验证
在此插件配置阶段,我们必须修改三个参数(这不包括创建 Name 和指定 InfluxQL 作为您的 Query Language)。
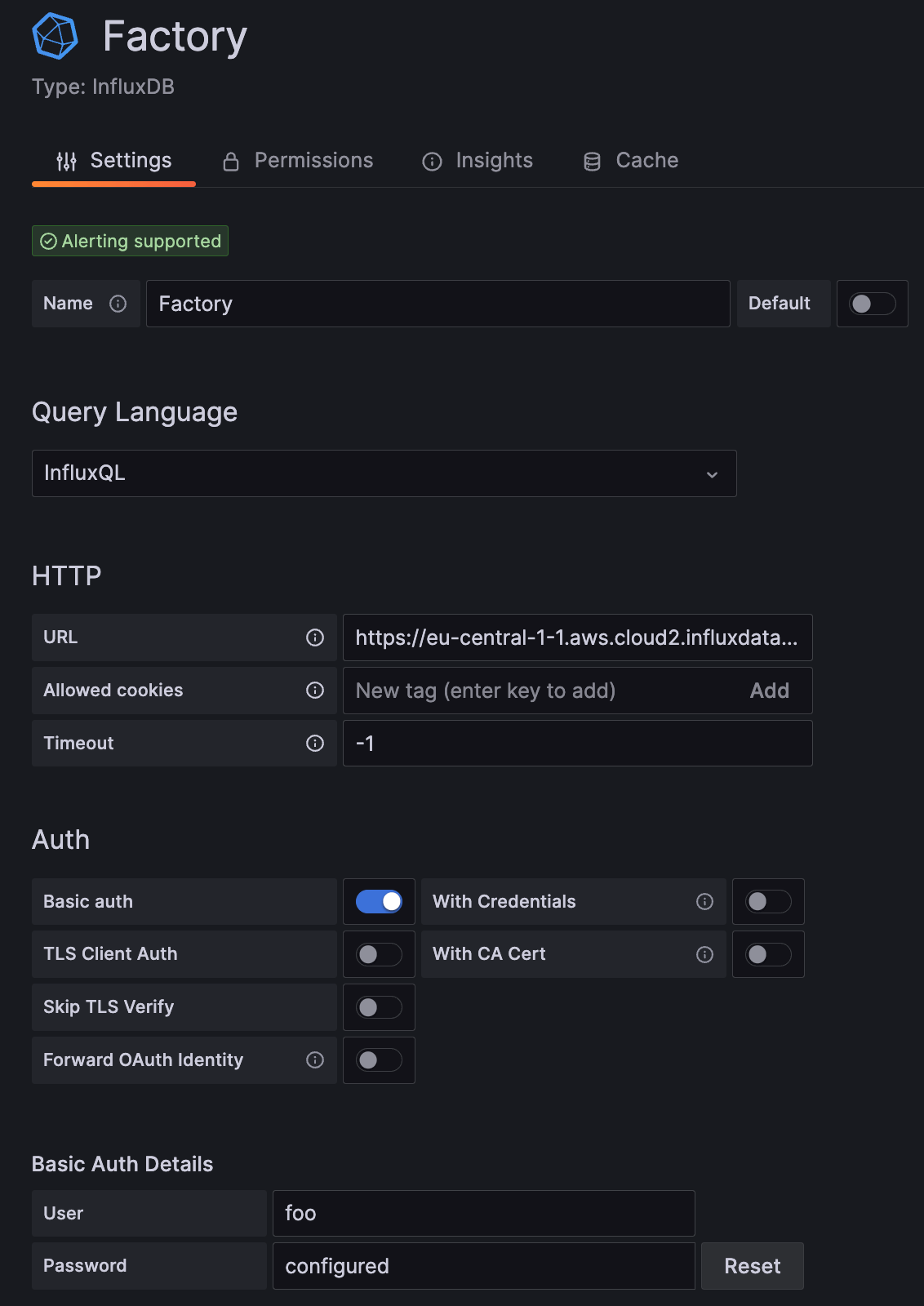
URL:确保将您的协议和域名添加到此表单中。一个示例将如下所示:https://eu-central-1-1.aws.cloud2.influxdata.com
基本身份验证:切换为 true。
用户/密码:用户名可以是任何字符串;它不用于身份验证目的,但不能为空。密码必须是具有足够权限从您要使用的数据库进行查询的 InfluxDB API 令牌。
阶段 2:数据库详细信息
在最后阶段,您只需更改一个参数。请注意,配置不使用用户名和密码参数。
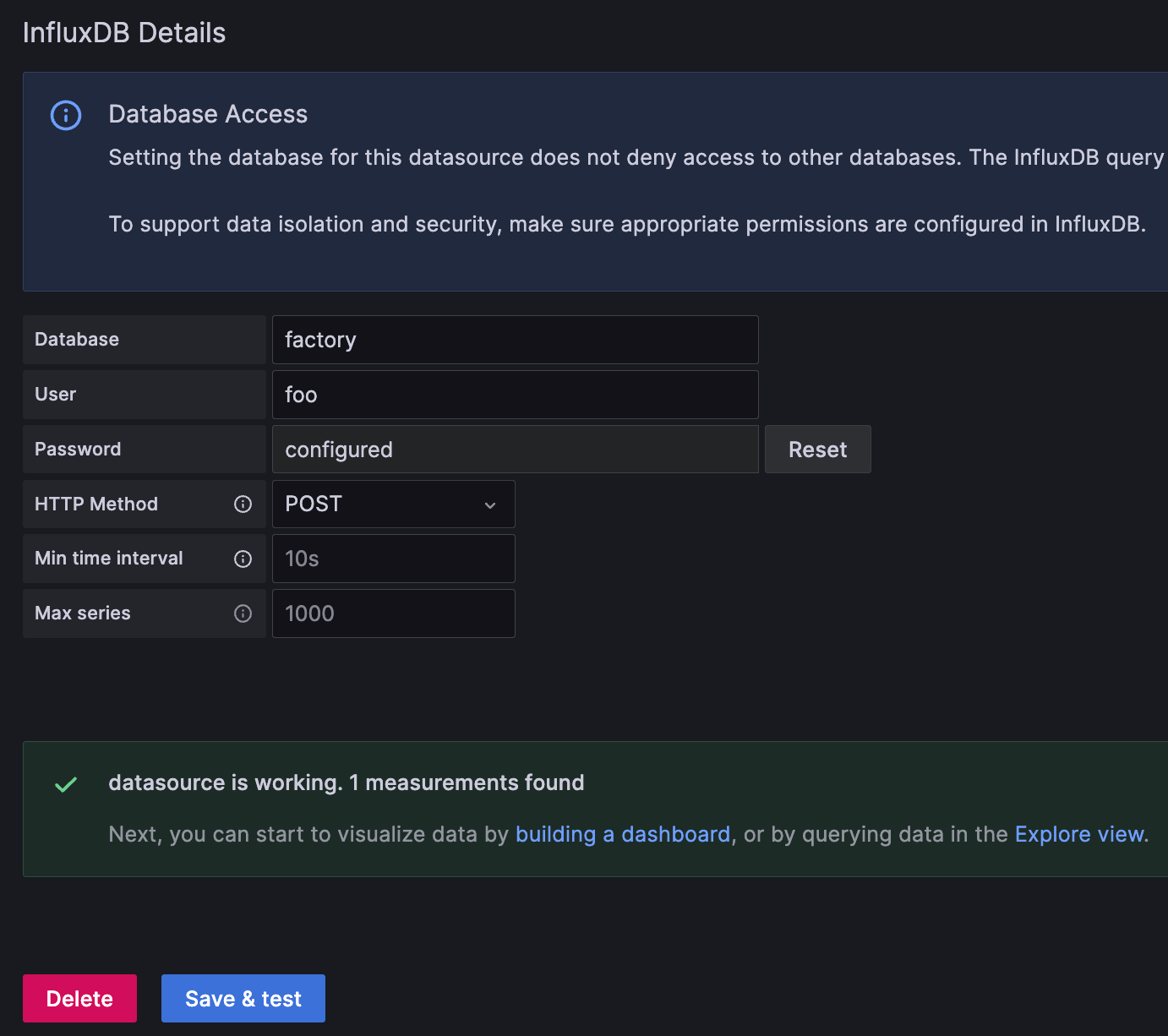
数据库:指定您要从中查询的数据库的名称。
Node-RED 插件
让我们再看一个示例 — Node-RED 的 node-red-contrib-influxdb 插件。我们社区成员的这项贡献使 InfluxDB 可以在 Node-Red 中进行查询和写入。使用 v1 API,我们可以再次使用此插件。让我们将设置分为两个阶段
阶段 1:身份验证
与 Grafana 数据源一样,我们首先需要配置与 v1 桥接的连接和身份验证。为此,我们需要配置几个参数
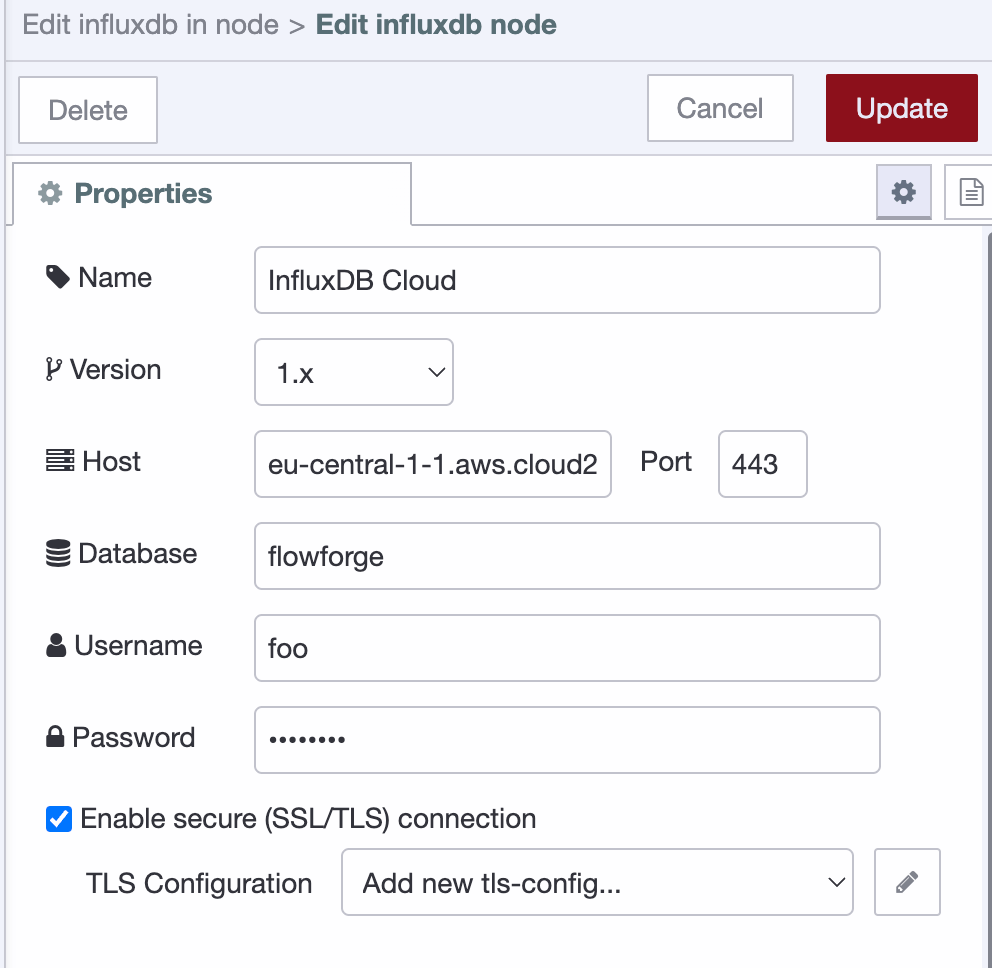
版本:确保将其设置为 1.X
主机和端口:从您的域名 URL 中剥离任何协议 (https://),并指定端口“443”。
数据库:要从中查询的数据库的名称。
用户/密码:用户名可以是任何字符串;它不用于身份验证目的,但不能为空。密码必须是具有足够权限从您要使用的数据库进行查询的 InfluxDB API 令牌。
启用安全:确保启用 SSL/TLS
阶段 2:查询详细信息
现在您可以在 Node-RED 中形成您的查询。只有两个参数需要注意
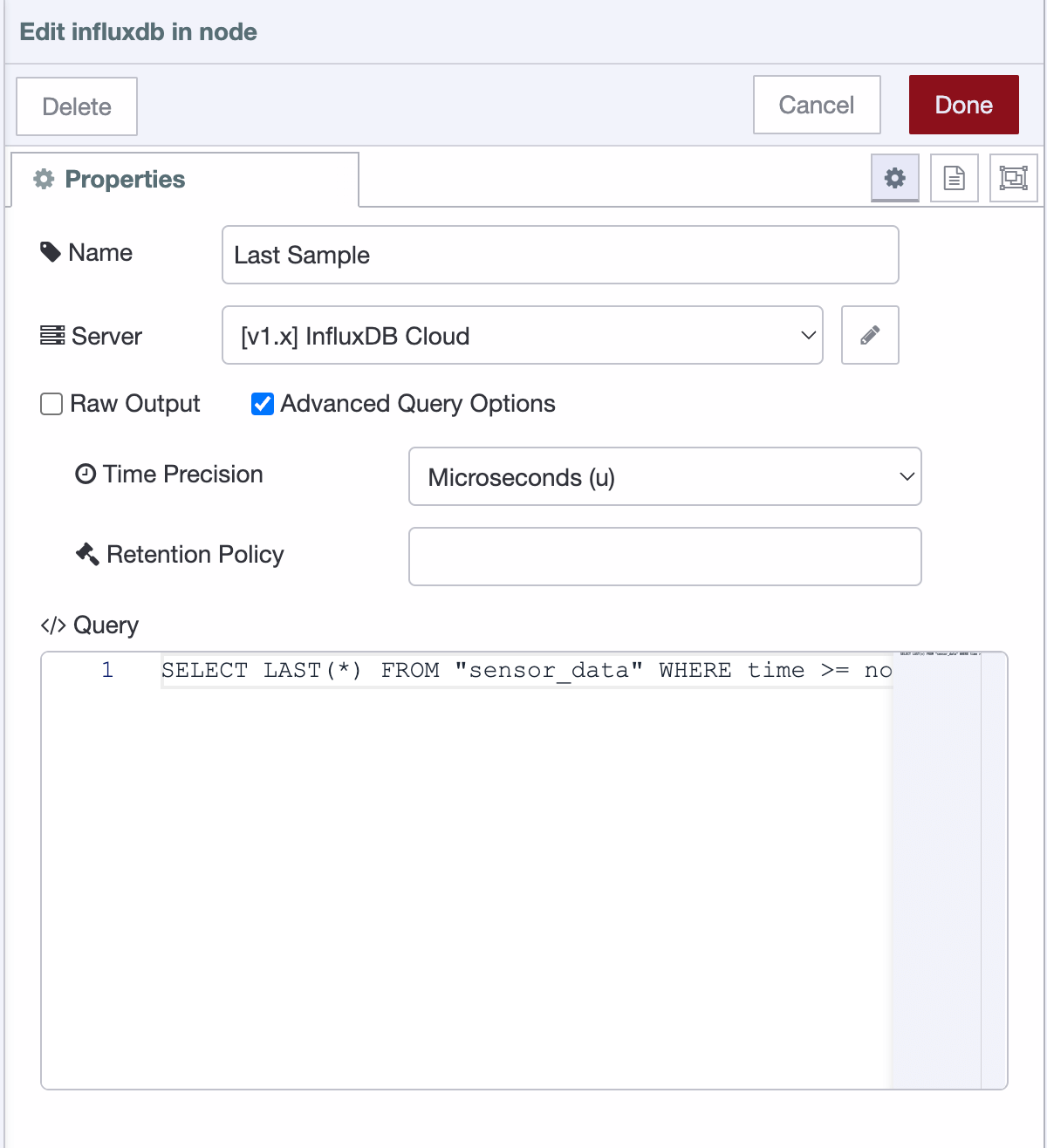
时间精度:确保根据存储的时间戳适当设置此参数。
查询:提供您的 InfluxQL 查询。
主要要点
InfluxQL 强势回归,更胜以往。当使用 v3 客户端库时,InfluxQL 高级用户可以继续利用该语言,同时获得 InfluxDB 3.0 和矢量化、列式 DataFusion 查询引擎的性能提升。v1 API 还为广泛使用的生态系统产品(如 Grafana 和 Node-RED)的向后兼容性提供了急需的垫脚石。
现在来说一些残酷的真相 — InfluxQL 仍在积极开发中,因此 v1 InfluxQL 尚没有完全相同的功能表示。我的建议是查看 InfluxQL 参考文档,并查看 当前可能实现的功能。目前,它支持大多数核心查询功能,或者即将支持。我的行动号召是开始将您的 InfluxQL 应用程序指向 InfluxDB 3.0,并在我们的社区中告诉我们您的体验。在以后的博客中,我们将深入探讨一些核心 InfluxQL 功能。
