使用 Python 中的 DataFusion 查询 Arrow 表
作者:Anais Dotis-Georgiou / 开发者
2023 年 10 月 23 日
导航至
InfluxDB v3 允许用户以 每秒 430 万个数据点的速度写入数据。然而,如果没有查询这些数据的能力,如此惊人的快速摄取速率就毫无意义。Apache DataFusion 是一个“可扩展的查询执行框架,用 Rust 编写,它使用 Apache Arrow 作为其内存格式。” 与以前不使用 Apache 生态系统的 InfluxDB 版本相比,它可以在各种查询类型中实现 5-25 倍更快的查询响应。Apache Arrow 是一个用于定义内存列式数据的框架。对于查询,InfluxDB v3 利用 SQL DataFusion API,DataFusion 也提供 Python DataFrame API。在本教程中,我们将学习如何:
- 使用 InfluxDB v3 Python 客户端库以 pyarrow 表格式查询和获取数据。
- 将 pyarrow 表转换为 Pandas 并进行一些转换。
- 将表另存为 Parquet 文件。
- 将 Parquet 文件加载回 Arrow 表。
- 创建 DataFusion 实例并使用 SQL 查询 Parquet 数据
Pandas 2.0
在 Arrow 中,Table 相当于 Pandas DataFrame。如果您关注了有关 Pandas 2.0 的新闻,您就会知道它支持 Arrow 和 NumPy 作为后端。但是,您必须通过为任何 read_* 方法指定 dtype_backend 参数来显式选择 Pandas 2.0 才能使用它。以下是 Pandas 1.0 和 Pandas 2.0 之间的性能比较。
您可以查询和将 Pandas DataFrame 写入 InfluxDB v3。但是,使用 Arrow 表和 DataFusion 可以提供性能优势。例如,PyArrow 表使用所有内核,而 Pandas 仅使用一个。此外,对于具有 SQL 背景的用户来说,使用 SQL 查询 Arrow 表比使用 Pandas 进行转换更容易。
使用 DataFusion 和 SQL 查询、转换和改造 Arrow 表
首先,我们将使用 InfluxDB v3 Python 客户端库以 pyarrow 表格式查询和获取数据。导入您的依赖项后,实例化客户端并查询您的数据。
from influxdb_client_3 import InfluxDBClient3
import pandas as pd
import datafusion
import pyarrow
client = InfluxDBClient3(token="[your authentication token]",
host="us-east-1-1.aws.cloud2.influxdata.com",
database="demo")
query = "SELECT * FROM \"cpu\" WHERE time >= now() - INTERVAL '2 days' AND \"cpu\" IN ('cpu-total')"
table = client.query(query=query)
print(table)
# Alternatively use the pandas mode to return a Pandas DataFrame directly.
# pd = client.query(query=query, mode="pandas")
# pd.head()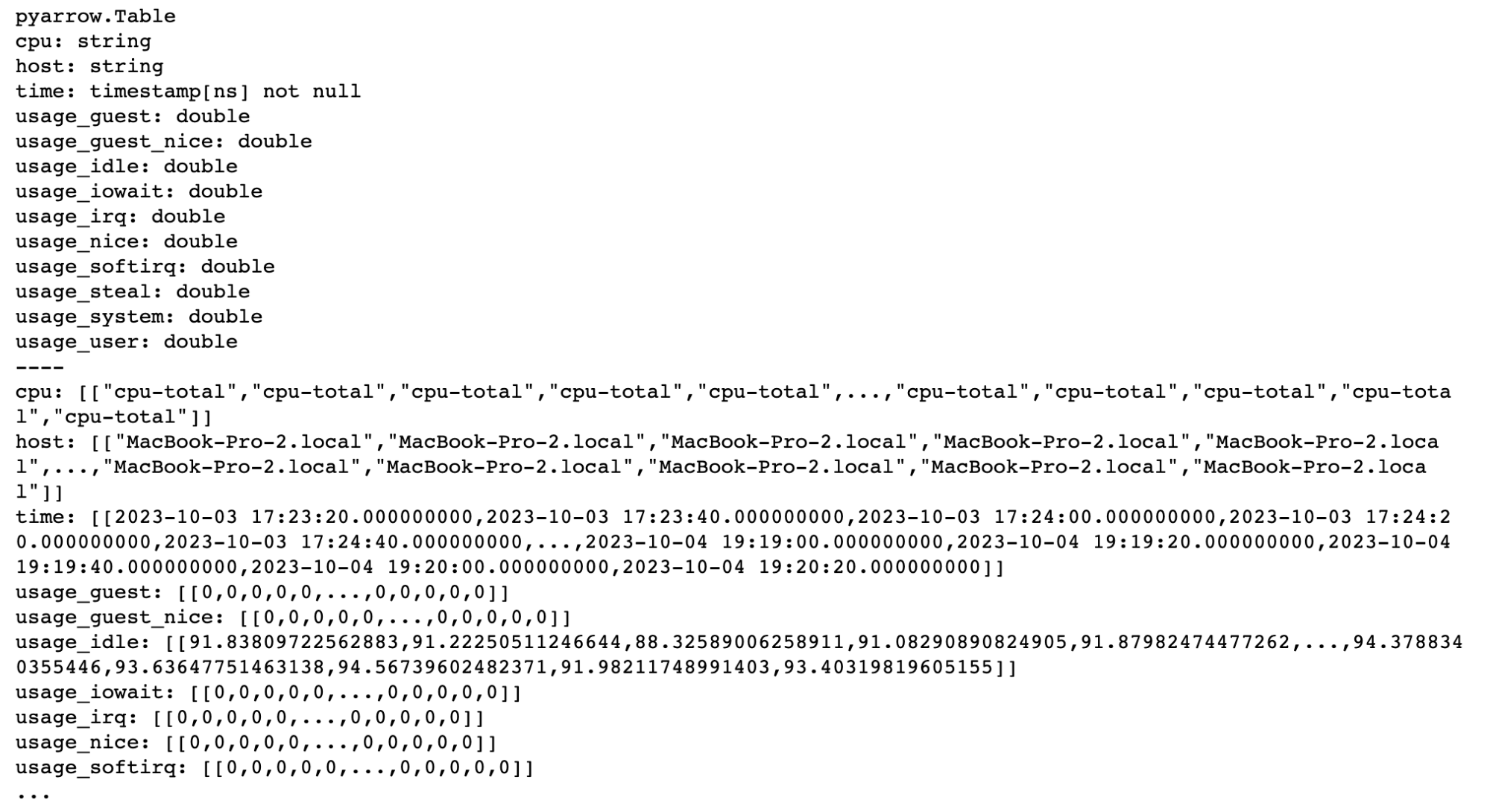
接下来,我们将使用 DataFusion 将 Arrow 表转换为 Pandas DataFrame 并执行一些转换。为了专注于本示例中数据类型之间的转换,我们将仅使用 Pandas 删除一些无关的列。但是,这正是您最有可能利用 Pandas 的全部功能来执行所有数据准备和分析的地方。
df = table.to_pandas()
pd = df[['cpu', 'usage_system', 'time']]
pd.head()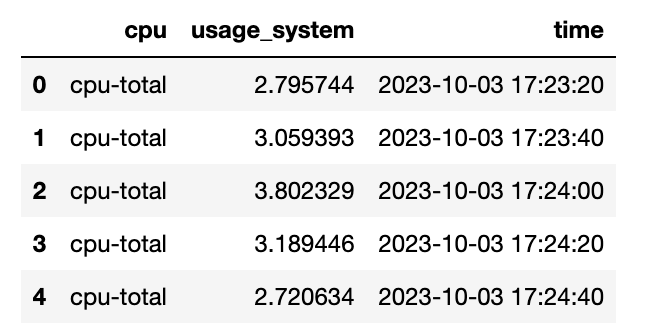
现在,我们使用以下代码将 DataFrame 保存到 Parquet 文件
pd.to_parquet(path="./cpu.parquet")将 Parquet 加载回 Arrow 表并将其转换回 Pandas DataFrame
table = pyarrow.parquet.read_pandas("cpu.parquet")
table最后,创建一个 DataFusion 实例并使用 SQL 查询 Parquet 数据。
# create a context
ctx = datafusion.SessionContext()
# Register table with context
ctx.register_parquet("cpu", "cpu.parquet")
# Query with SQL
df = ctx.sql(
"select 'usage_system' from 'cpu'"
)
df.show()
# To convert back into a Pandas DataFrame
# pandas_df = df.to_pandas()虽然您目前需要通过 Arrow 查询 Parquet 文件,但有初步计划允许用户直接从 InfluxDB 查询 Parquet 文件。这将使用户能够在 InfluxDB v3 中更好地利用 DataFusion 和 SQL。
最终想法
InfluxDB 是存储所有时间序列数据的一个出色工具。它构建于 Apache 生态系统之上,并利用 DataFusion、Arrow 和 Parquet 等技术来实现高效的写入、存储和查询。我希望本教程能够帮助您熟悉如何在这些不同的数据类型之间进行转换,以及如何使用 SQL 查询 Parquet 文件。请在此处开始使用 InfluxDB Cloud 3.0。如果您需要任何帮助,请使用我们的社区网站或 Slack 频道与我们联系。我很乐意了解您尝试实现的目标以及您希望 InfluxDB 拥有的功能。
