使用 InfluxDB 和 AWS Kinesis 驱动实时数据处理
作者:Anais Dotis-Georgiou / 开发者
2024年2月14日
导航至
想象一下,一位数据工程师为一家大型电子商务公司工作,任务是构建一个可以实时处理和分析客户点击流数据的系统。通过利用 Amazon Kinesis 和 InfluxDB,他们可以高效且有效地实现这一目标。
那么,我们如何从想法到完成解决方案呢?首先,我们需要了解手头的工具。为此,我们将探讨 InfluxDB 3.0 的优势,包括其处理大量数据以用于实时分析应用程序的能力。然后,我们将深入探讨如何通过使用 Telegraf(一个用于指标和事件的开源收集代理),有效地将 InfluxDB 与 Amazon Kinesis(一个用于摄取和处理流数据的可扩展且完全托管的平台)结合使用。
InfluxDB 3.0 的优势
如果您有大量设备生成带时间戳的数据,那么您需要一个时间序列数据库。InfluxDB 3.0 经过优化,可以实时且大规模地存储和查询数据,为您的时间序列数据提供无与伦比的性能。它可以每秒摄取数百万个数据点,而不会影响性能。一些额外的优势包括:
- 它构建在 Apache Arrow 生态系统之上,提供与开源解决方案的互操作性,包括可视化、ETL 和数据科学工具。
- 3.0 版本比以前的版本性能显著提升,如这份基准测试报告所述。
- 完整的 SQL 支持,这意味着许多开发人员的学习曲线非常低。这使团队能够高效地提取见解并提高整体生产力。
- 无限制的基数。请查看链接中的视频,但基数与您的数据库相对于数据库性能可以处理的数据量有关。无限制的基数支持意味着 InfluxDB 3.0 可以处理大型、复杂的数据集,而不会影响性能。
- 3.0 可以将指标、跟踪和日志存储在一个地方。
将 Amazon Kinesis 与 InfluxDB 结合使用
AWS Kinesis 在实时数据处理方面表现出色,这对于实时分析、物联网、视频流处理和其他时间序列用例至关重要。其可扩展性使其成为应对流量波动变化的理想选择,而与 AWS 服务(如 Lambda 和 S3)的无缝集成有助于在 AWS 生态系统中高效地处理数据。此外,Kinesis 的按需付费模式具有成本效益,可满足各种规模和需求的企业。
那么,我们对 InfluxDB 和 Kinesis 有了一些了解,并且知道 InfluxDB 可以处理我们所有的时间序列数据。我们如何构建我们的实时分析应用程序呢?
我们需要设置 Telegraf 以从 Amazon Kinesis 流中收集数据,并将其写入 InfluxDB 3.0 Cloud Serverless 实例。幸运的是,Telegraf 已经有一个 Kinesis 插件。
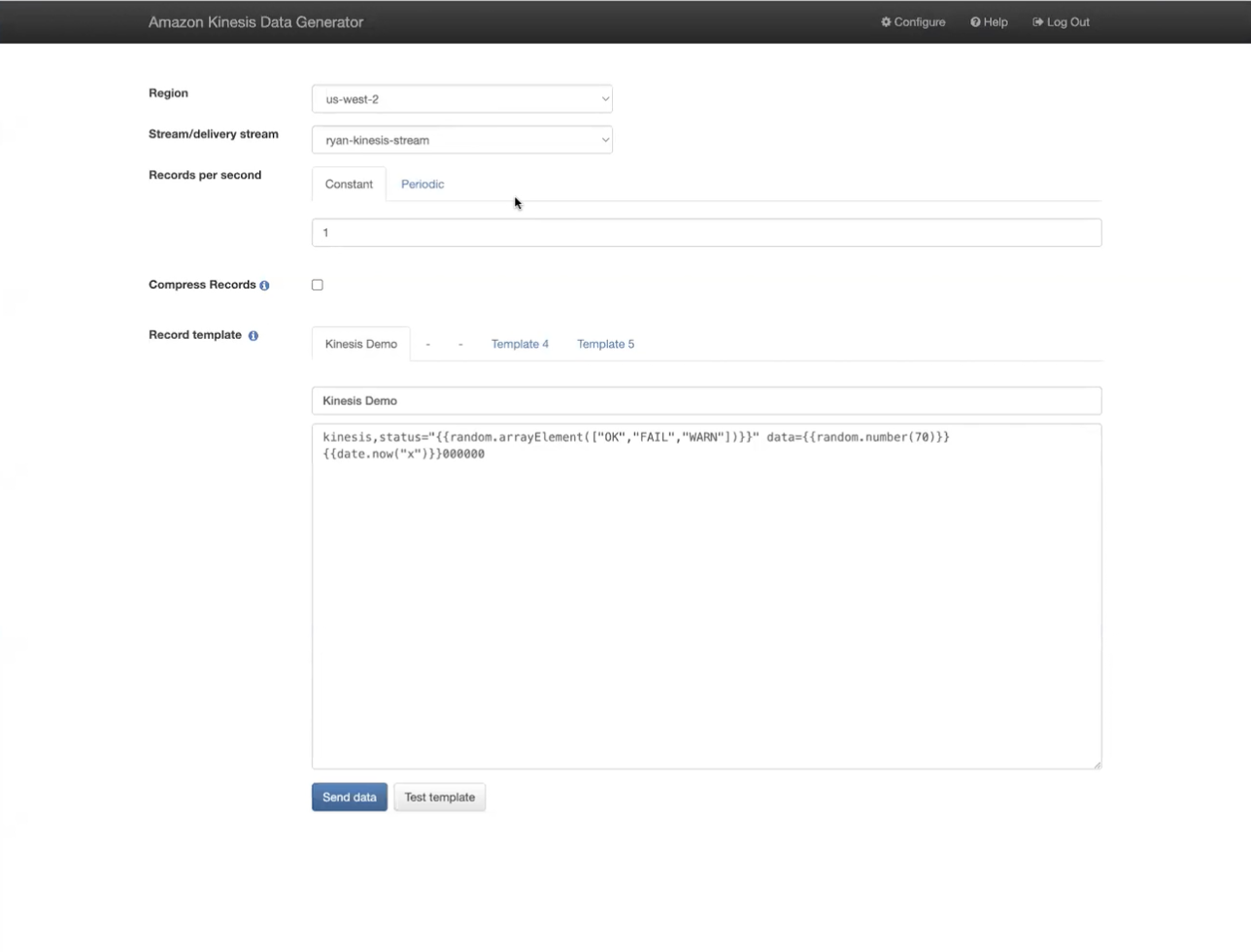
在此示例中,我们使用 Amazon Kinesis Data Generator 将 Line Protocol 数据发送到 Kinesis 流。Telegraf 代理使用 Kinesis 输入插件从流中收集数据,并使用 InfluxDB 输出插件将数据发送到存储。
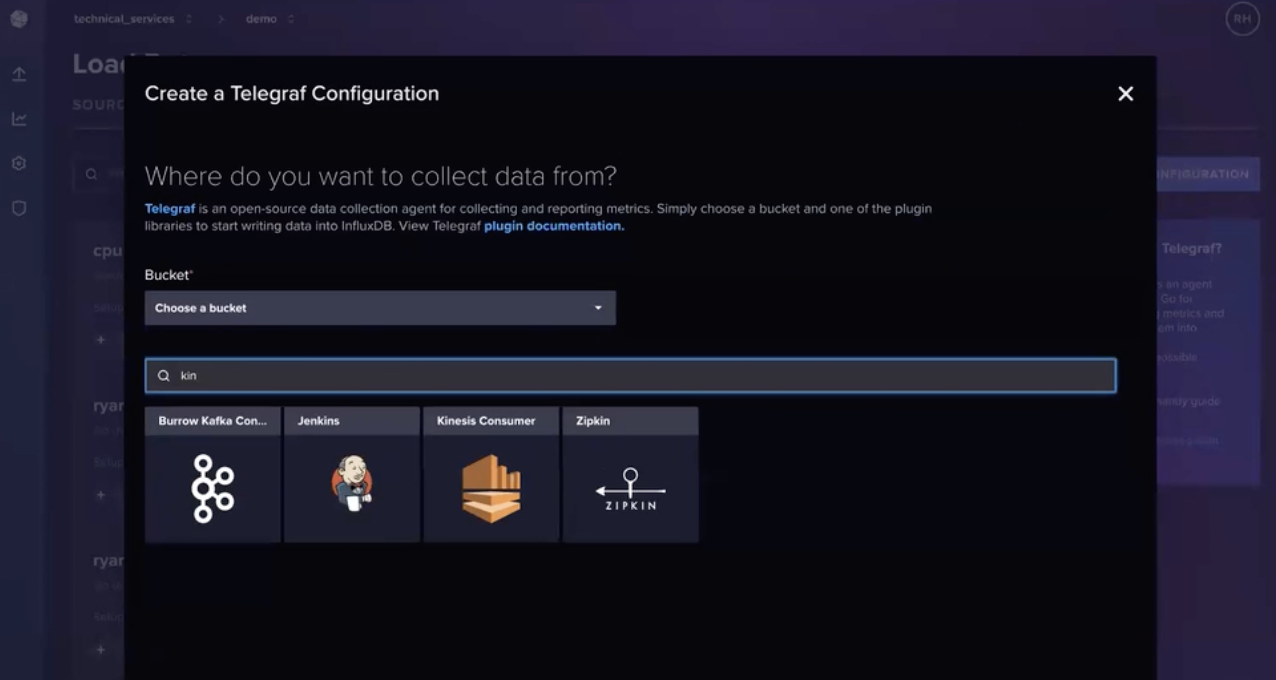
您可以使用 InfluxDB Cloud Serverless UI 创建和托管 Telegraf 配置。上面的屏幕截图显示在 InfluxDB UI 中搜索 Kinesis Consumer Input Telegraf 插件。选择该插件后,您也可以直接在 UI 中编辑配置。

要配置 Kinesis 插件,请包含托管 Kinesis 流的区域、访问密钥、密钥、流名称和分片迭代器类型。最后,指定数据格式类型。由于流中的数据采用 Line Protocol,这是 InfluxDB 的原生输入格式,我们可以简单地选择 data_format=influx。
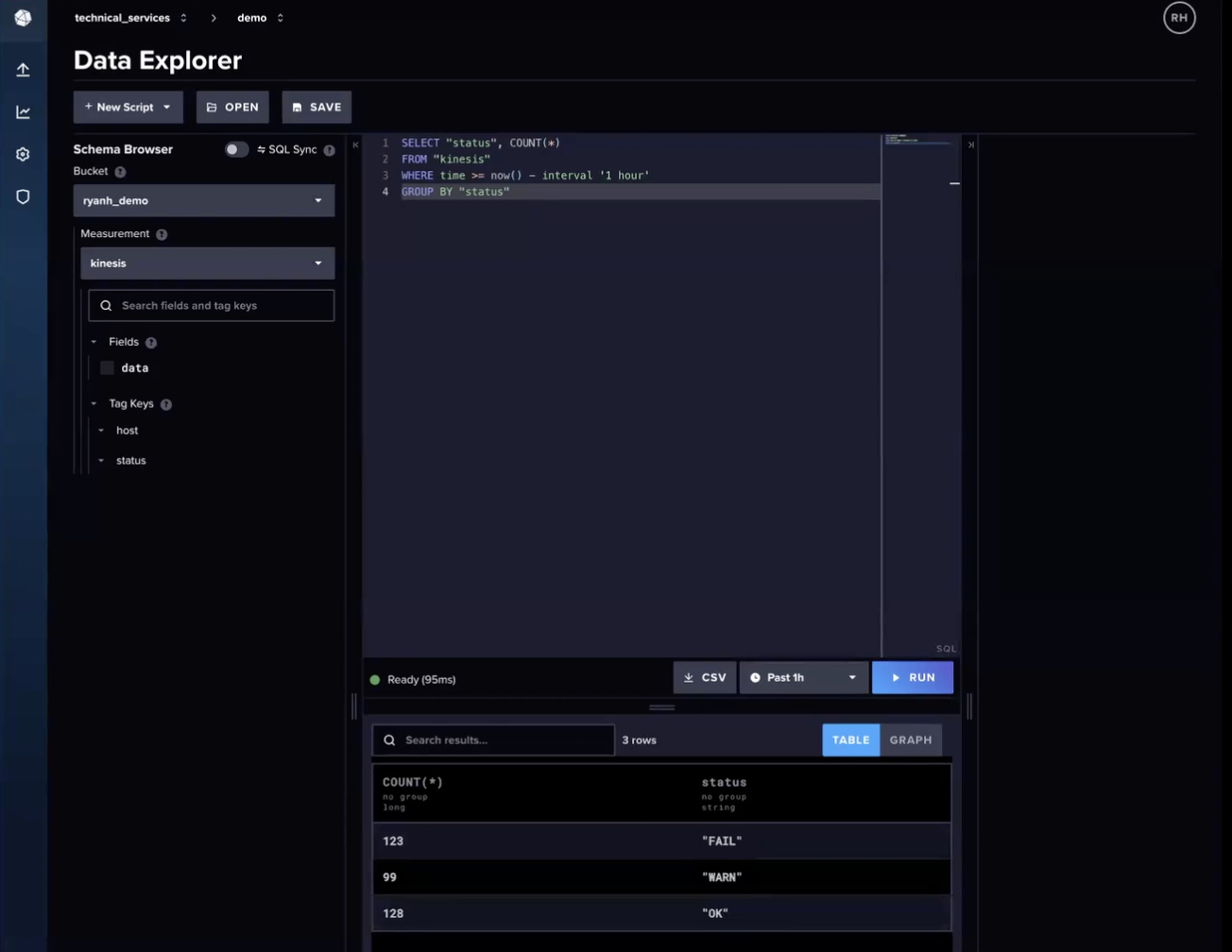
最后,我们可以在 InfluxDB Cloud Serverless UI 中的 Data Explorer 中使用 SQL 查询我们的数据。上面的图片显示了一个使用以下 SQL 查询查询我们的数据以获取状态计数的示例。
sql
SELECT “status”, COUNT(*)
FROM “kinesis”
WHERE time >= now() - intergral ‘1 hour’
GROUP BY “status”
额外资源
如果这篇博客引起了您的兴趣,您可能还会喜欢了解如何将 AWS Fargate 与 InfluxDB 结合使用。AWS Fargate 是一种“您可以与 Amazon ECS 结合使用的技术,用于运行容器,而无需管理服务器或 Amazon EC2 实例集群。” 我鼓励您查看这个 repo,其中包含一个容器化解决方案,用于使用 InfluxDB 创建降采样任务。您可以轻松地在 AWS Fargate 上运行容器,并以这种方式安排您的任务以节省成本。
从这里开始使用 InfluxDB Cloud 3.0。如果您需要任何帮助,请通过我们的社区网站或 Slack 频道联系我们。
喜欢观看视频?请在此处观看我们的 InfluxDB 和 AWS 点播演示。
