Apache Arrow 简介
作者:Anais Dotis-Georgiou / 用例, 开发者
2023 年 9 月 15 日
导航至
这篇文章最初发表在 The New Stack 上,并经许可在此处转载。
了解 Arrow 是什么、它的优势以及一些公司和项目如何使用它。
在过去的几十年中,使用大数据集需要企业执行越来越复杂的分析。查询性能、分析和数据存储的进步很大程度上是内存访问增加的结果。需求、制造工艺改进和 技术进步 都促成了更便宜的内存。
较低的内存成本刺激了支持内存中查询处理的技术的创建,用于 OLAP(在线分析处理)和数据仓库系统。OLAP 是任何对大量数据执行快速多维分析的软件。
一个示例这些技术的项目是 Apache Arrow。在本文中,您将了解 Arrow 是什么、它的优势以及一些公司和项目如何使用 Arrow。
什么是 Apache Arrow?
Apache Arrow 是一个用于定义内存中列式数据的框架,每个处理引擎都可以使用它。它旨在成为列式内存表示的语言无关标准,以促进互操作性。来自也在 Impala、Spark 和 Calcite 上工作的公司的几位开源领导者开发了它。联合创建者之一是 Pandas 的创建者 Wes McKinney,Pandas 是一个流行的 Python 库,用于数据分析。他希望使 Pandas 与数据处理系统互操作,而 Arrow 解决了这个问题。
Apache Arrow 技术分解
Apache Arrow 实现了广泛采用,因为它提供了高效的列式内存交换。它提供零拷贝读取(CPU 不会将数据从一个内存区域复制到第二个内存区域),这减少了内存需求和 CPU 周期。
列式存储的优势
由于 Arrow 具有基于列的格式,因此处理和操作数据也更快。想象一下,我们将以下数据写入数据存储
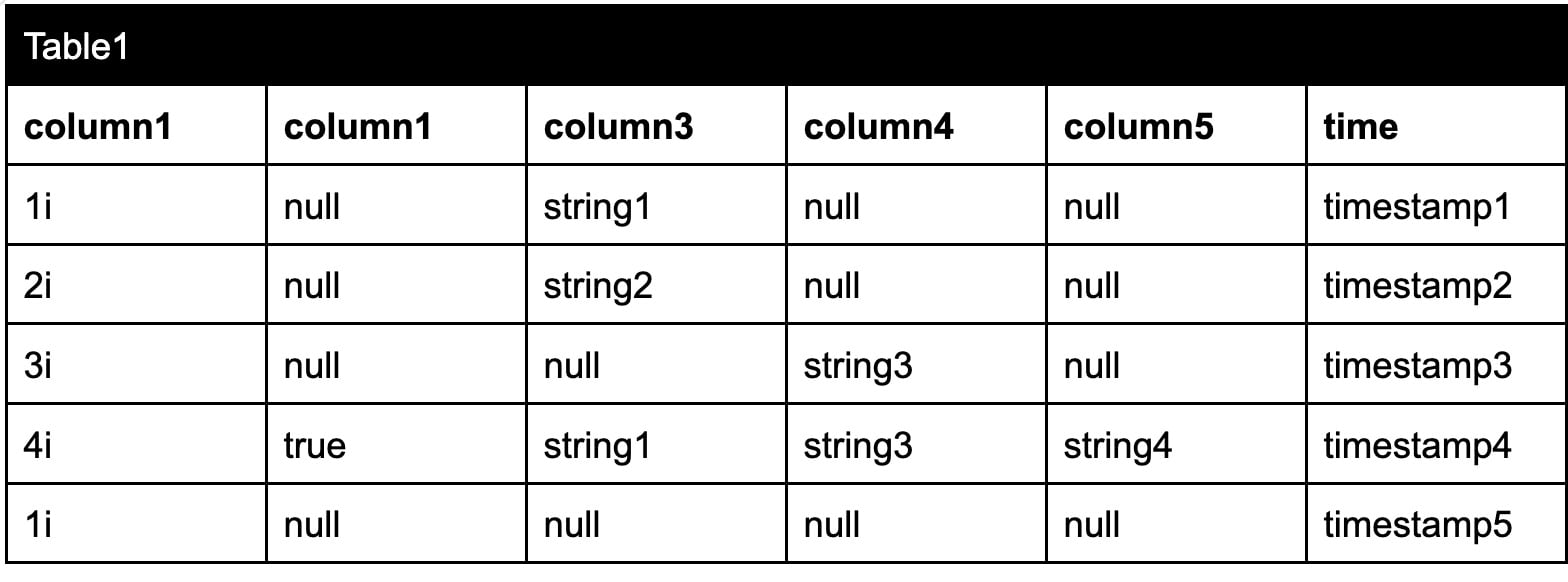
但是,引擎以列式格式存储数据,如下所示
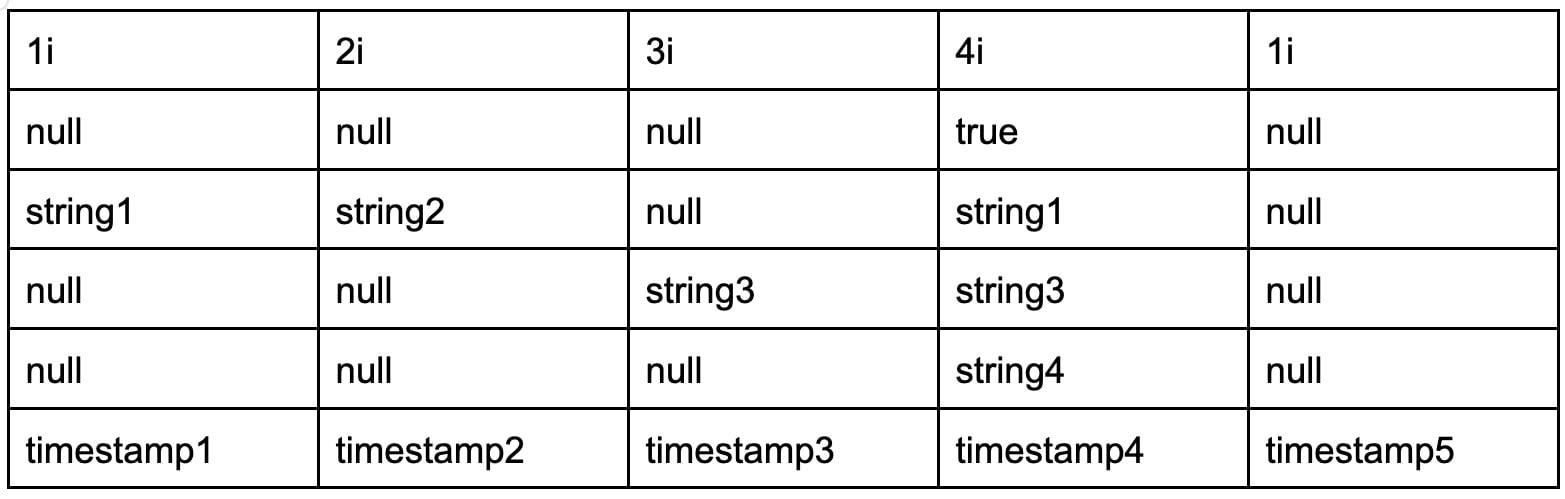
换句话说,Arrow 内存缓冲区按列而不是按行对数据进行分组。以列式格式存储数据允许数据库将类似数据分组在一起,以实现更有效的压缩。具体来说,Apache Arrow 定义了一种进程间通信机制,用于传输 Arrow 列式数组的集合(称为“记录批次”),如本 FAQ 中所述。
Apache Arrow 开发人员为现代 CPU 和 GPU 设计了 Arrow,因此它可以并行处理数据,并利用单指令/多数据 (SIMD)、向量化处理和向量化查询等技术。
存储标准化的优势
Arrow 旨在成为数据库和语言的标准 数据格式。标准化数据格式消除了代价高昂的数据序列化和反序列化。任何支持 Arrow 的系统都可以在它们之间传输数据,几乎没有开销,尤其是在 Apache Arrow Flight SQL(稍后详细介绍)的帮助下。
多语言支持的优势
Arrow 项目包含库,这些库使在许多语言中更容易使用 Arrow 列式格式,包括:C++、C#、Go、Java、JavaScript、Julia、Rust、C (GLib)、MATLAB、Python、R 和 Ruby。这些库使开发人员能够使用 Arrow 格式,而无需自己实现 Arrow 列式格式。
什么是 Apache Arrow Flight SQL?
Apache Arrow 的另一个好处是它与 Apache Arrow Flight SQL 的集成。拥有高效的内存中数据表示对于减少内存需求以及 CPU 和 GPU 负载非常重要。但是,如果没有有效地跨联网服务传输此数据的能力,Apache Arrow 就不会那么有吸引力。幸运的是,Apache Arrow Flight SQL 解决了这个问题。Apache Arrow Flight SQL 是“Apache Arrow 社区开发的一种新的客户端-服务器协议,用于与 SQL 数据库交互,该协议利用 Arrow 内存中列式格式和 Flight RPC 框架。”
背景
要理解 Arrow 和 Arrow Flight SQL 的优势,了解之前的情况很有帮助。ODBC(开放数据库连接)和 JDBC(Java 数据库连接)是用于访问数据库的 API。JDBC 可以被认为是 ODBC 的 Java 版本,ODBC 是基于 C 的。这些 API 提供了一组用于与数据库交互的标准方法。它们定义了如何制定 SQL 查询、如何处理结果、错误处理等等。具体来说,JDBC 和 ODBC 已使用了几十年,用于执行以下任务,例如
- 执行查询
- 创建预处理语句
- 获取有关受支持 SQL 方言的元数据
- 可用类型
但是,它们没有定义线路格式。线路格式是指 数据结构化 或序列化以在网络上高效传输的方式。示例包括 JSON、XML 和 Protobuf,数据库驱动程序必须定义这些格式。
Arrow Flight SQL 的优势
幸运的是,数据库开发人员不必使用 Arrow Flight SQL 定义线路协议。相反,他们可以直接使用 Arrow 列式格式。ODBC 和 JDBC 使用基于行的格式,并且在像 Arrow 这样的基于列的格式方面存在不足。Arrow 消除了使用基于行的 API 进行数据转置的需要。它还使客户端能够与 Arrow 原生数据库通信,而无需数据转换或昂贵的序列化和反序列化。
Arrow Flight SQL 还提供了开箱即用的加密和身份验证等功能,进一步减少了开发工作。这很大程度上是 Flight RPC 框架的结果,该框架构建在 gRPC 之上。最后,Arrow Flight SQL 实现了进一步的优化,例如并行数据访问。并行数据访问是指这些系统将涉及读取或写入大量数据的任务划分为可以同时执行的较小子任务的能力。数据可能跨多个磁盘、节点或数据库分区进行分区,并且单个查询或操作可以同时访问多个分区,从而大大提高性能。
使用 Apache Arrow 的公司和项目
Apache Arrow 为 各种数据分析和存储解决方案项目提供支持,包括以下内容
- Apache Spark 是一个大规模并行处理数据引擎,它使用 Arrow 将 Pandas DataFrames 转换为 Spark DataFrames。这使数据科学家能够将基于小型数据集开发的概念验证模型移植到大型数据集。
- Apache Parquet 是一种极其高效的列式存储格式。Parquet 使用 Arrow 进行向量化读取。向量化读取器通过批量处理列式格式中的多行,使 列式存储 更加高效。
- InfluxDB 是一个时间序列数据平台。它的新存储引擎使用 Arrow 来支持近乎无限的基数用例,以多种查询语言(包括 InfluxQL 和 SQL 以及更多即将推出的语言)进行查询,并提供与商业智能和数据分析工具的互操作性。
- Pandas 是一个构建在 Python 之上的数据分析工具包。Pandas 使用 Arrow 为 Parquet 提供读写支持。
使用工具集或成为拥有庞大且运行良好的社区的生态系统的一部分,对技术的采用者来说是一个巨大的好处。跨组织协作可以加快问题解决时间,激发创新并促进互操作性。
推荐资源
Apache Arrow 是一个列式格式框架,可减少内存和 CPU 负载。它还在 Apache Arrow Flight SQL 的帮助下实现了更快的数据传输。
要在 InfluxDB 的上下文中利用 Apache Arrow,请在此处注册。如果您想联系为 Apache 生态系统贡献了大量工作的 InfluxDB 3.0 开发人员,请加入 InfluxData 社区 Slack 并查找 #influxdb_iox 频道。
