InfluxDB 3.0 介绍:今天在 InfluxDB Cloud Dedicated 中可用
作者:Rick Spencer / 产品, 公司
2023年4月26日
导航至
从最开始的略有接触,到后来的深入参与,我与 InfluxDB 3.0 这个项目已经有了数年的渊源。我开始使用它的时间非常早,以至于 DataFusion 上游开发人员之一甚至称我为“User0”……我对此称号暗自感到自豪。现在,经过多年的开发,我真的很高兴能在分享 InfluxData 团队以及更广泛的 Apache Arrow 社区的成果中发挥一小部分作用,随着我们推出 InfluxDB 3.0,我真诚地期望现有用户和新用户都会发现此版本非常有用。
InfluxDB 3.0 介绍:InfluxDB IOx 的演进
截至今日,InfluxDB 3.0 现在是所有 InfluxDB 产品(包括当前和未来产品)的基础,首次为 InfluxDB 平台带来了高性能、无限基数、SQL 支持和低成本对象存储。InfluxDB 3.0 以 Rust 语言开发为列式数据库,在一个数据存储中引入了对全范围时间序列数据(指标、事件和跟踪)的支持,从而为依赖于高基数时间序列数据的可观测性、实时分析和物联网/工业物联网中的用例提供强大支持。
InfluxDB 3.0 现在已在 InfluxData 的云产品中推出:InfluxDB Cloud Serverless(我们的完全托管、弹性、多租户数据库)和今天发布的 InfluxDB Cloud Dedicated(InfluxDB 的完全托管、单租户版本)。敬请期待我们今年晚些时候推出的自托管产品
- InfluxDB 3.0 Clustered: InfluxDB Enterprise 的演进。
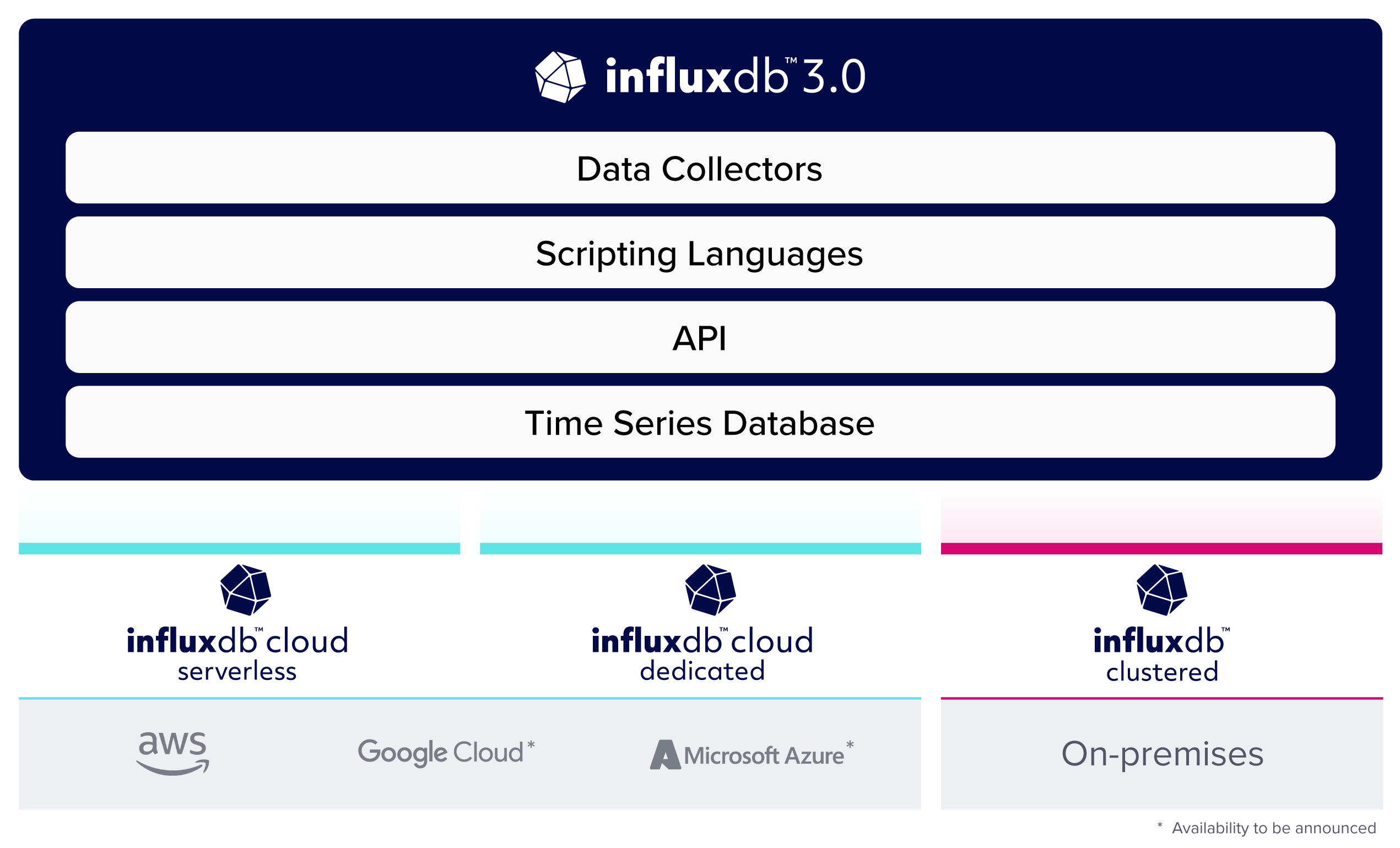
InfluxDB Cloud Dedicated 现已全面上市
InfluxDB Cloud Dedicated 是处理大型数据集、需要数据隔离在专用单租户集群中的安心感和安全性的客户的理想解决方案。它提供自定义配置和增强的安全选项(包括企业 SSO、私有连接和基于角色的访问控制)以及基于容量的定价模式。
针对以下情况优化 InfluxDB 3.0…
如果您属于以下类别之一,我们认为您会想要了解 InfluxDB 3.0
-
您是现有的 InfluxDB OSS 用户 — InfluxDB 3.0 很可能以更快的速度和更低的成本运行您现有的工作负载,并且只需进行极少的更改。此外,它还使您可以访问新功能,并能够将 InfluxDB 与更多不同类型的数据一起使用。
-
您不是现有的 InfluxDB 用户,但您需要一个具有实时功能以处理大量数据的分析数据库,或者您正在努力充分利用现有的分析数据库,那么 InfluxDB 3.0 将满足您的需求。
具有无限扩展的性能
InfluxDB 3.0 在某些重要方面超越了 InfluxDB 1.x 和 2.x。InfluxDB 3.0 的增强功能使 InfluxDB 处于分析数据库的前沿,使开发人员能够实时、大规模且毫不妥协地摄取和查询所有类型的全保真时间序列数据。
InfluxDB 3.0 现在支持无限基数,这扩展了 InfluxDB 的用例,使其适用于任何带时间戳的数据。与其他分析数据库不同,即使数据复杂性和基数增加,InfluxDB 3.0 也具有摄取性能、可扩展性、弹性和效率方面的巨大提升。
例如,与以前版本的 InfluxDB 相比,新的 InfluxDB 3.0 在以下领域实现了性能提升
-
高基数数据查询速度提高 100 倍,提供实时查询响应
-
摄取性能提高 10 倍,每秒可摄取、存储和分析数十亿个时间序列数据点,没有限制或上限
-
数据压缩率提高 10 倍,这得益于使用专为高效数据存储和检索而设计的 Apache Parquet 文件格式
Arrow 生态系统中的 InfluxDB
我们围绕 Apache Arrow 项目(一种用于列式数据的开源内存规范,是分析用例高性能计算的黄金标准)开发了 InfluxDB IOx – 以及扩展的 InfluxDB 3.0。我们在 Arrow 上构建了 InfluxDB IOx 引擎,以利用其性能和生态系统。
InfluxDB 3.0 现在使用 Apache Parquet 文件格式存储数据。Parquet 的压缩在高效利用磁盘空间方面实现了数量级的提升。能够在更少的空间中存储更多数据对于控制成本以及大型分析工作负载的整体效率非常重要。
InfluxDB 3.0 利用 Apache DataFusion,具有现代且极速的 SQL 实现。由于它基于开放标准,因此您可以将现有的 SQL 知识和工具带到您的 InfluxDB 体验中。我们甚至增强了 DataFusion 的 SQL 方言,以包括关键的时间序列函数。
我们还将 InfluxData 的时间序列查询语言 InfluxQL 引入了 DataFusion。现在,InfluxQL 的运行速度比以往任何时候都更快。
在 InfluxData,我们相信 Apache Arrow 生态系统。秉承我们的开源精神,我们的工程师为上游 Arrow 项目做出了重大贡献,以确保性能和功能满足 InfluxDB 及其忠实用户群的标准。InfluxDB 3.0 的推出首次将时间序列数据引入 Arrow 生态系统,使分析工作负载能够更轻松地集成时间序列数据。这确保了 OSS 贡献更易于构建和集成。
立即开始使用 InfluxDB 3.0
要开始使用 InfluxDB 3.0,请试用 InfluxDB Cloud Serverless,或立即请求 InfluxDB Cloud Dedicated 的概念验证。
