InfluxDB IOx 简介
作者:Susannah Brodnitz / 用例, 产品
2022 年 11 月 03 日
导航至
上周 InfluxData 发布了 IOx,这是 InfluxDB 的全新时间序列引擎。我们重新审视了数据库的核心,以利用底层技术实现重大突破。用户可以期待更高的性能和更多的数据查询选项。以下是 InfluxDB IOx 一些最令人兴奋的功能的快速介绍。
无界基数
在 InfluxDB 中,当我们说基数时,我们指的是存储桶中唯一 measurement、标签集和字段键组合的数量。过去,我们不鼓励在 InfluxDB 中使用大量标签或包含无界数据的标签,因为它会降低性能。这限制了用例,例如可观测性和跟踪,这些用例依赖于高基数数据,例如日志和跟踪。 InfluxDB IOx 消除了基数限制。现在,用户可以写入具有无限基数的数据,并沿着他们想要的任何维度监控和查询其时间序列数据,而不会影响性能。
实时分析
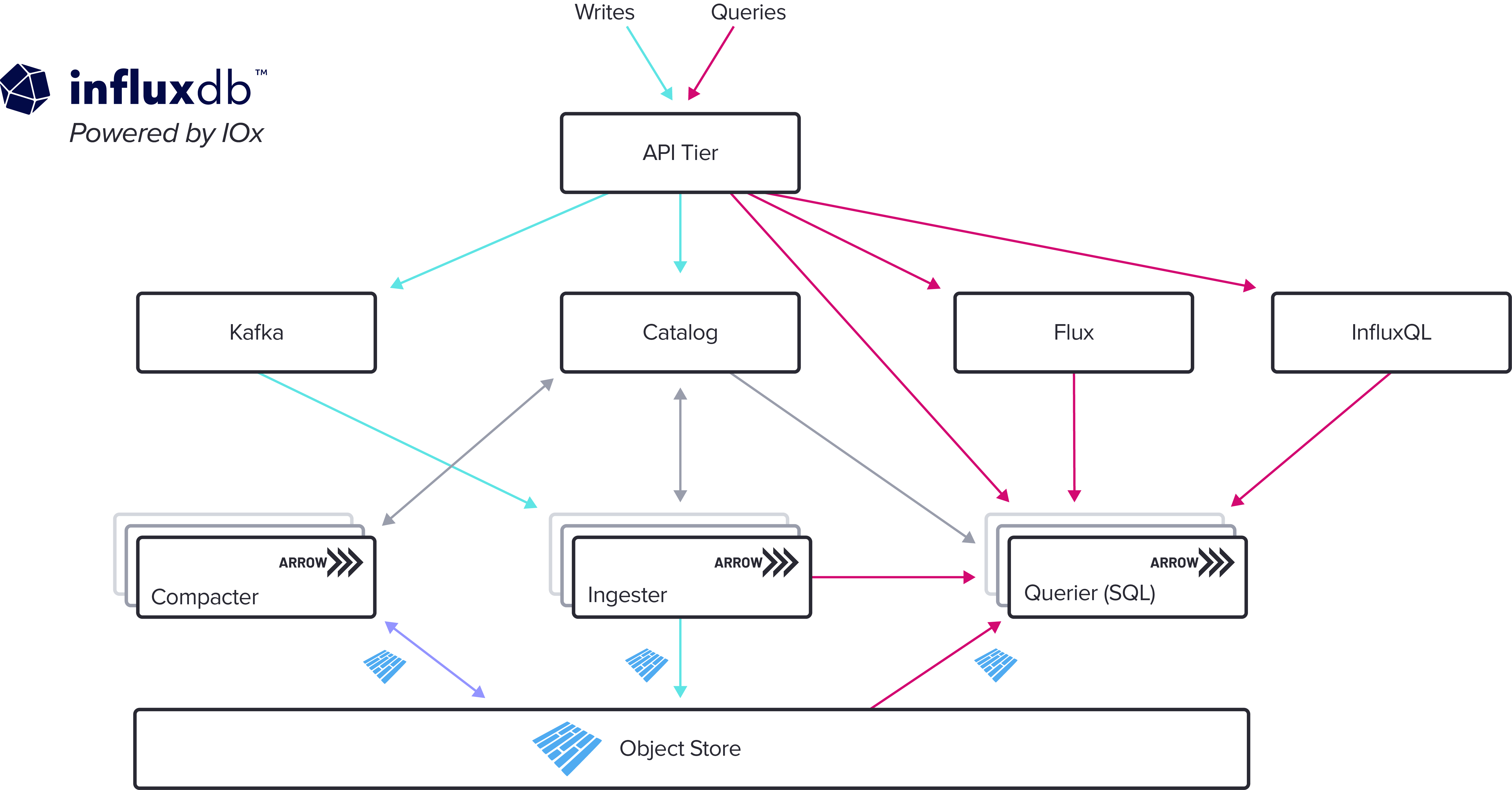
InfluxDB IOx 是一个列式时间序列数据库。列式数据库将其数据表示为表,并允许您快速且大规模地执行查询。我们基于列式数据库的新引擎从几个方面解决了性能问题。按列压缩有助于节省磁盘空间。字典确保您在标签值应用于多个时间戳时不会重复存储字符串,而游程编码有助于高效存储合法的重复值。向量化执行使您可以组织数据,以便 CPU 可以非常快速地遍历它。并且查询是并行化的,以更快地运行。
新引擎最重要的部分之一是分区。使用 IOx,时间序列数据根据时间(例如按天)以及标签(例如区域)划分为分区。这使您可以轻松过滤掉不属于查询时间范围或其他规范的数据部分。查询逐个操作来自包含分区的所有行,并且由于向量化执行,IOx 允许您每个核心每秒查询约 10 亿行。这种分区和令人难以置信的快速查询响应意味着您可以拥有大量标签,并且仍然可以获得实时的结果来构建仪表板以及监控和警报系统。
SQL 支持
InfluxDB IOx 使用 Rust 编程语言编写,并使用 Apache Parquet 文件进行磁盘存储,并使用 Apache Arrow 进行组件之间的操作。 Apache Arrow 是一种用于列式数据的内存规范,可使分析查询非常快。 IOx 还使用 DataFusion 库,一个原生 SQL 查询引擎,作为其解析器、规划器、优化器和执行引擎。这意味着 InfluxDB 首次支持 PostgreSQL 方言和线路协议,允许您连接到第三方库和 BI 工具,如 PSQL、Grafana、Tableau 和 Apache Superset。兼容性是 InfluxData 的一个关键重点,这个新引擎支持许多查询选项。除了新的 SQL 支持外,InfluxDB IOx 继续支持 API 版本以及我们自己的查询和脚本语言。在 API 层,您可以使用 1.x 或 2.0 API 与新引擎通信,并且您可以使用 Flux、InfluxQL、SQL 或我们提供的 12+ 个客户端库中的任何一个来查询数据库。
注册 InfluxDB IOx Beta 计划
您可以注册成为 InfluxDB IOx Beta 计划的一部分。您将在 InfluxDB Cloud 中获得 SQL 兼容性、无界基数和更快的性能。如果您使用 OSS 或 InfluxDB 企业版,您可以期待明年推出带有新引擎、这些兼容性层和迁移工具的版本。
