基础设施监控基础知识:使用 Telegraf、InfluxDB 和 Grafana
作者:Jay Clifford / 产品
2023 年 8 月 29 日
导航至
今年早些时候,我有幸在 北美开源峰会 上发表演讲。在选择主题时,我觉得是时候回归本源,讨论最初让 InfluxDB 声名鹊起的主题:基础设施监控。
尤其令人兴奋的是,有机会向开源社区展示 InfluxDB 3.0 的新功能,并解释它们对未来基础设施监控用例的重要性。
这篇博客分解了演讲中的要点,并深入探讨了这些主题,提供了更深入的见解和讨论。
监控与可观测性
InfluxDB 能够处理监控和可观测性用例。3.0 不仅提高了两者的性能,还使大规模的可观测性用例成为可能。在我们深入细节之前,让我们先设定基调,讨论一下 监控和可观测性 之间的确切区别是什么
监控
监控包括收集和分析指标、日志和事件,以跟踪系统性能。监控过程使用预定义的规则和阈值,检测潜在问题,并在发生阈值违反时生成警报,从而帮助维护系统健康。您可以将这种方法应用于各种类型的基础设施,无论是在物理领域还是数字领域。
可观测性
可观测性在监控的基础上更进一步,包括对代码和基础设施进行检测,以暴露相关数据。这使团队能够深入了解其系统的行为。通过关联来自不同来源的数据,它有助于诊断问题和识别根本原因。反过来,这为有效的问题解决提供了可操作的见解。追踪是映射请求或事务在系统组件中 journey 的过程,是典型的可观测性工具。
乍一看,监控和可观测性似乎服务于相同的目的,但它们从不同的角度处理系统健康。监控是主动的,设置预定义的规则和阈值,以确保系统在所需的参数范围内运行。它是关于确保一切都“在轨道上”,并在情况并非如此时发出警报。另一方面,可观测性在性质上更具诊断性。它是关于理解“为什么”会发生某些事情,并深入研究系统行为。虽然两者都旨在维护系统健康和性能,但监控更多的是检测已知问题,而可观测性则侧重于探索未知问题。然而,在现代系统管理的格局中,它们是互补的。它们共同提供了系统健康、性能和行为的整体视图,确保了稳健性和弹性。
监控和可观测性领域
我们可以将这些概念进一步分类为几个不同的领域,每个领域都有其特定的重点和应用
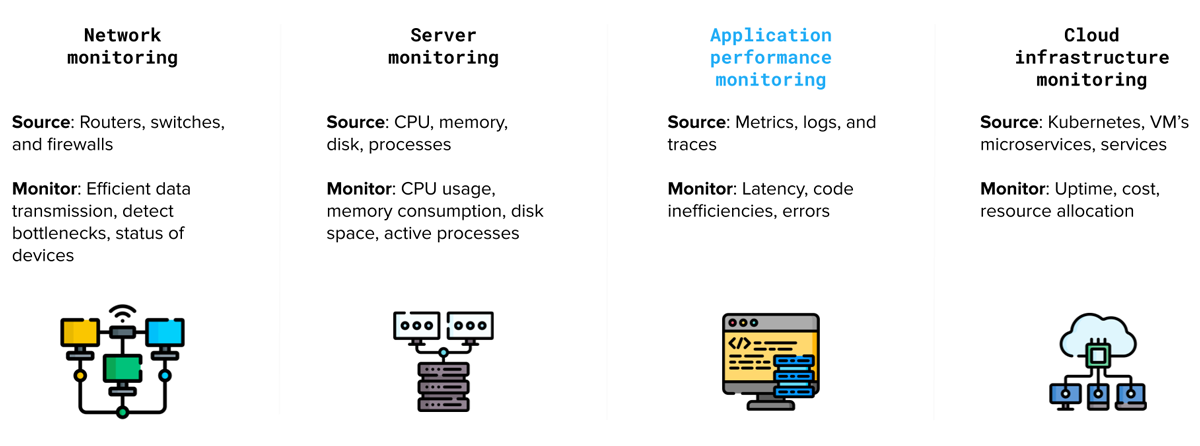
网络监控:观察网络组件(如路由器、交换机和防火墙)的性能,以确保高效的数据传输,检测瓶颈,并识别安全威胁。
服务器监控:跟踪物理或虚拟服务器的性能和可用性,包括 CPU 使用率、内存消耗、磁盘空间和响应时间,以确保最佳性能并减少停机时间。
应用程序性能监控 (APM):监控软件应用程序的性能,以识别代码、数据库或基础设施组件中的问题、瓶颈和低效率。(应用程序性能监控已以蓝色突出显示,因为它也可能属于可观测性领域,我们将在后面介绍)。
云基础设施监控:跟踪基于云的服务的性能和可用性,例如虚拟机、存储和数据库,以优化资源分配并最大限度地降低成本。
要解决的问题
现在,进入有趣的部分!我总是发现,当您有一个问题要解决时,如果您首先了解您希望采用的解决方案,解决起来会更容易。让我们请 ChatGPT 创建一个基础设施问题,其中涉及创建一个解决方案来监控我们之前讨论的每个领域。
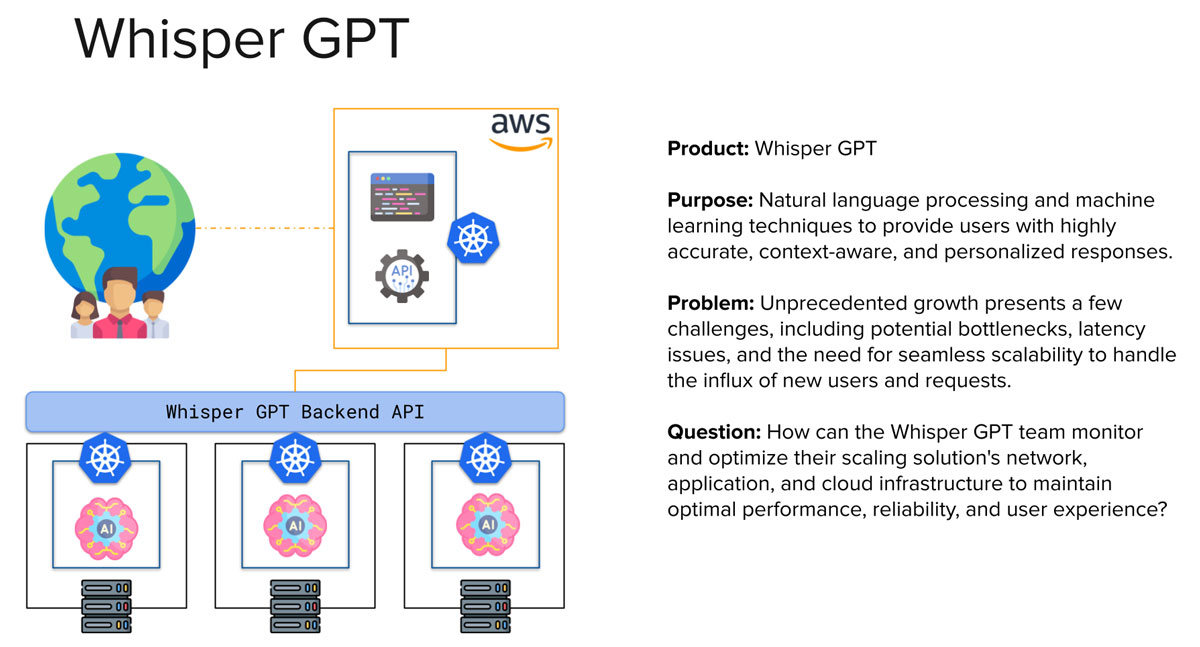
因此,基于这个问题,我们可以将架构分解为我们的监控和可观测性子领域
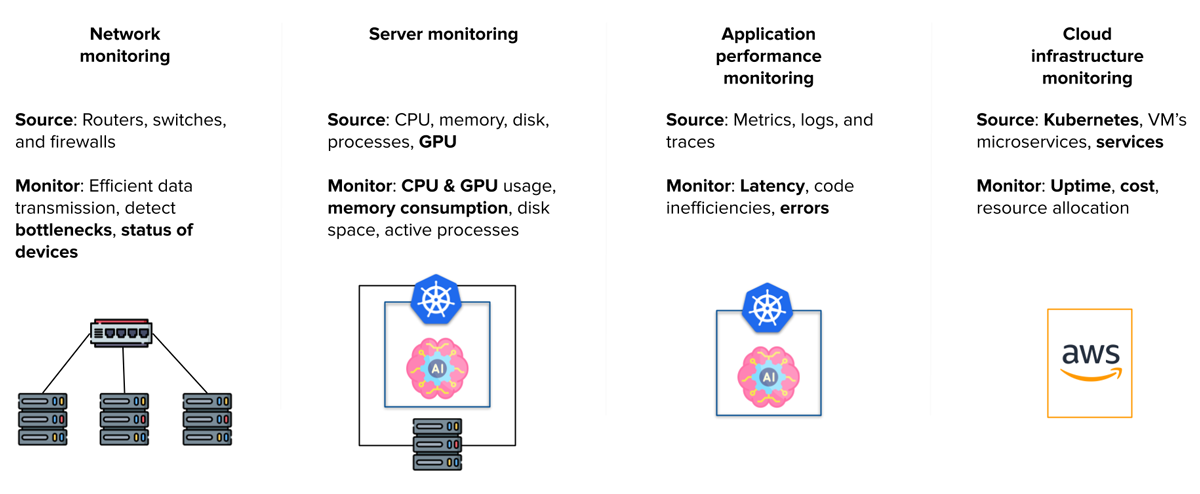
网络监控:监控网络流量,尤其是对模型的请求。
服务器监控:跟踪托管其主要模型的 Whisper GPT 服务器的性能,重点关注 CPU 和 GPU 指标。
应用程序性能监控 (APM):这包括两个方面
-
监控我们在裸机基础设施上的 Kubernetes 集群。
-
为开发人员提供工具,以主动分析 Whisper 平台内的代码。
云基础设施监控:利用 App Runner 或 Amazon EKS 等服务进行前端管理。
解决问题
现在,我将向您展示如何使用 TIG 堆栈(Telegraf、InfluxDB 3.0 和 Grafana)和 OpenTelemetry 来解决这些问题。在我们超前之前,让我们首先创建一个架构蓝图。
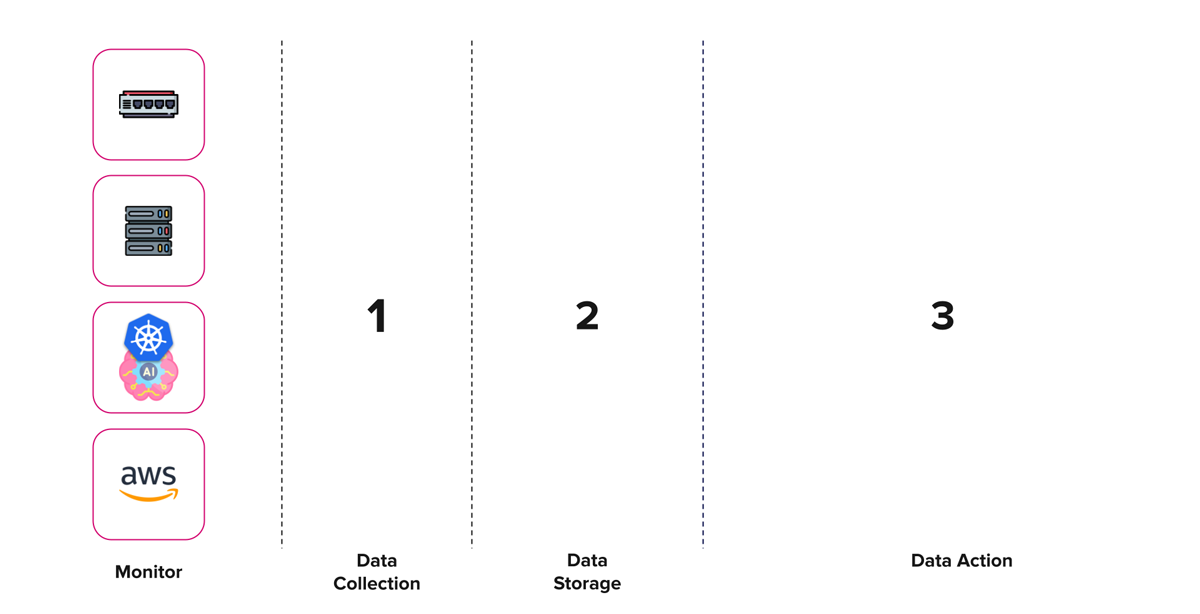
数据收集
Telegraf 是我们首选的开源数据收集代理,专门设计用于收集指标和事件。配备了超过 300 个插件,用于摄取、转换和输出数据,它是一个用于时间序列数据的通用代理。社区将其称为监控和可观测性数据收集的瑞士军刀,因为它能够根据插件的用途部署拉取和推送收集方法。它还配备了处理大量数据格式的解析,包括 Prometheus、JSON、XML、CSV 和 更多。
让我们看一下我们可能用来解决 Whisper GPT 问题的一些插件
| 领域 | 插件 |
| 网络监控 | gNMI Net SNMP |
| 服务器监控 | CPU 磁盘 Diskio 内存 进程 Nvidia SMI 系统 |
| APM | Kubernetes 清单 Kubernetes OpenTelemetry Prometheus |
| 云基础设施监控 | CloudWatch Kubernetes 清单 Kubernetes |
按照设计,Telegraf 就像一个数据管道,您可以将其路由到不同的插件来处理和聚合数据,然后再到达最终输出。以下架构图很好地可视化了这一点。
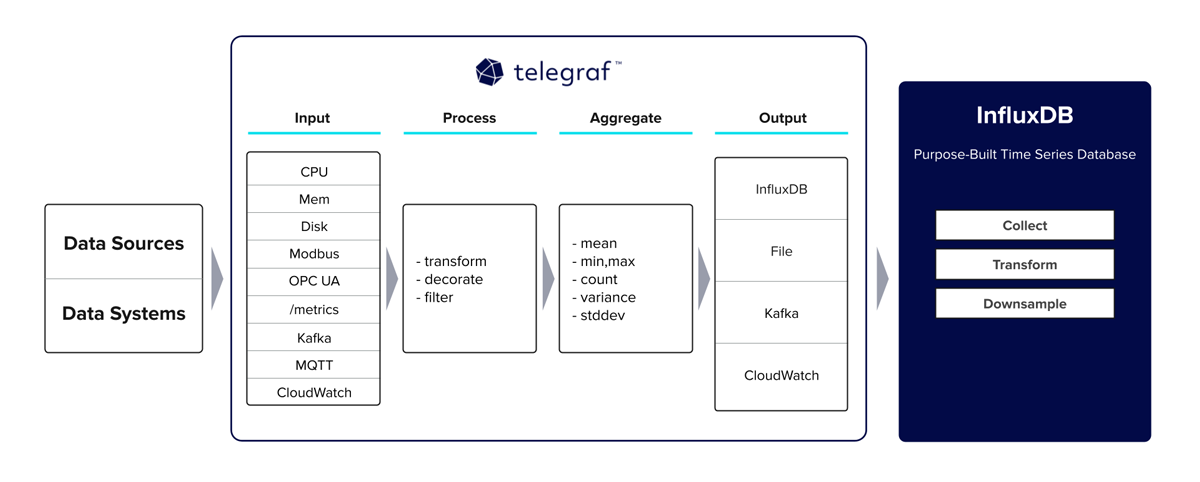
在演示的这一点上,我深入探讨了 Telegraf 的最佳实践和初始部署。我强烈建议您查看我们的 InfluxDB 大学关于 Telegraf 的课程,以了解有关这部分的更多信息。
数据存储
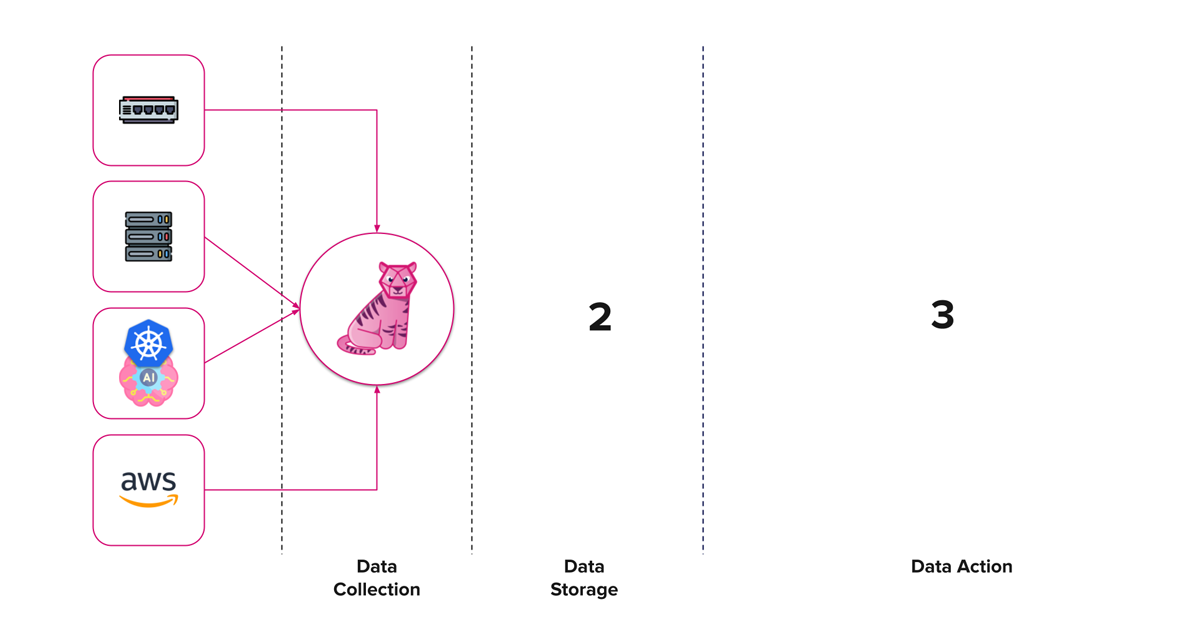
在我们的列表中检查了数据收集之后,现在让我们继续建立基础设施监控架构中的基石...数据存储。
InfluxDB 3.0 是一个专门构建的时间序列数据库,旨在处理大规模的指标、跟踪和日志,以进行实时分析。这由我们用来创建数据库引擎的三种核心开源技术驱动:Apache Arrow、Parquet 和 DataFusion。如果您想了解更多关于我们如何部署这些技术的信息,我强烈建议您查看这篇 博客。
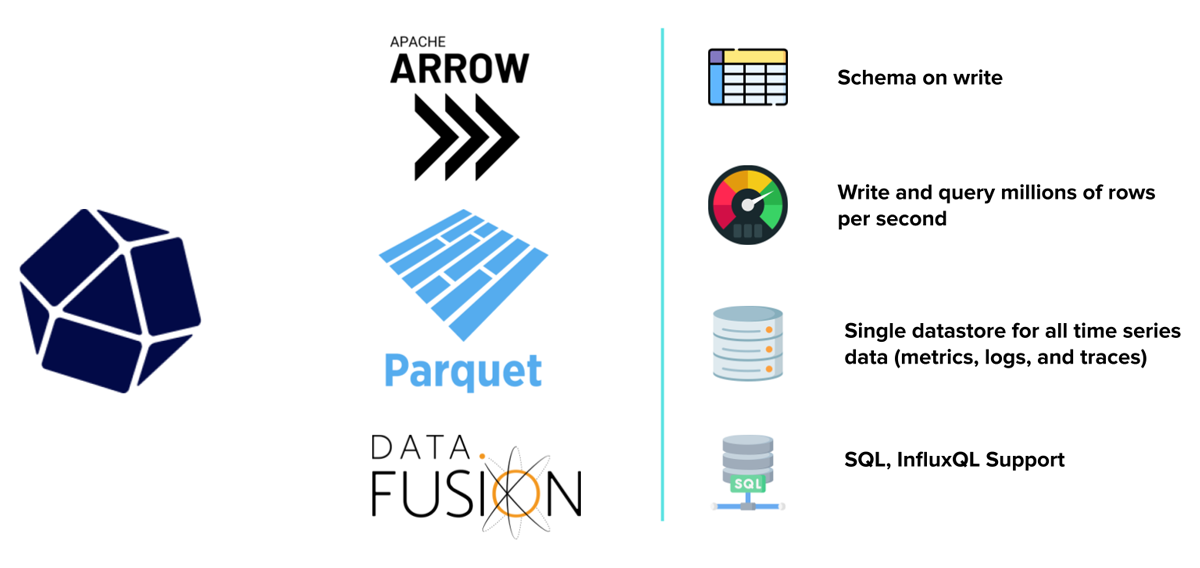
在其核心,InfluxDB 在我们的用例中为我们提供了一些可观的好处
| 优势 | 描述 |
| 写入时模式 | 当涉及到监控用例时,这是一个无需动脑筋的选择。模式设计是开发人员在使用传统数据库时需要关注的最昂贵和耗时的任务之一。这也是一个不会消失的问题,因为根据 Whisper GPT 的发展方式,模式也会随之发展。InfluxDB 在初始数据摄取时构建模式,从而无需从头开始构建模式。此功能允许模式随我们的解决方案一起发展。 |
| 写入和查询性能 | 在大多数监控用例中,用户需要近乎实时地查看他们正在摄取的数据,这可能来自每天生成千兆字节时间序列数据的数百个数据源。InfluxDB 可以每秒摄取超过 400 万个值,同时提供毫秒级的查询返回时间。我强烈建议您查看这篇 博客,以了解我们的一些性能统计数据。 |
| 单一数据存储 | 在监控和可观测性领域中,最有趣的待解决问题之一是存储不同类型的时间序列数据:跟踪、指标和日志。大多数经验丰富的提供商为每种类型使用不同的数据存储技术,然后提供一个接口,用于在查询时加入这些结果。InfluxDB 3.0 允许我们将所有内容保存在单个存储中,从而降低总体拥有成本。 |
| 查询支持 | 借助 InfluxDB 3.0,我们希望强调在开发人员所在之处满足他们的需求。这意味着提供大多数用户(无论是当前用户还是新用户)都可以使用的查询语言。InfluxQL 和 SQL 为开发人员提供了高性能的选项来与其数据进行交互。它们还为利用这两种语言的第三方解决方案提供了丰富的生态系统。 |
在这一点上,我再次讨论了最佳实践和 InfluxDB 3.0 的入门。我强烈建议您查看 InfluxDB 3.0 Essentials 课程,以赶上这部分内容。
数据在行动
我们已经达到了第二个里程碑。在这一点上,我们的 Whisper GPT 基础设施监控流程正在收集和存储数据。
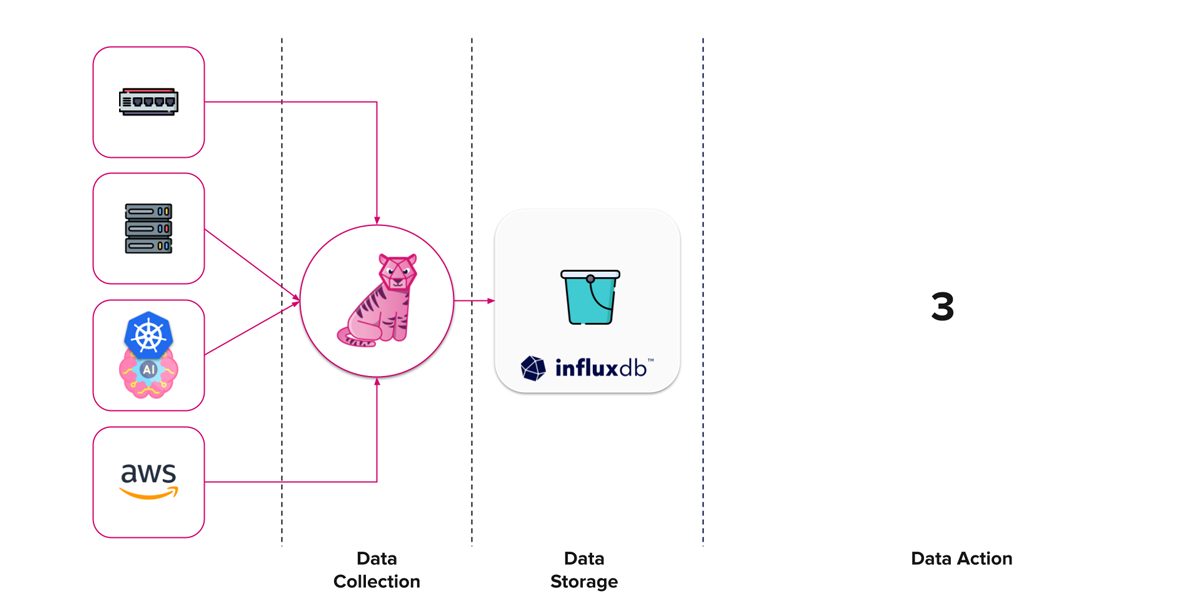
现在我们需要用这些数据做一些事情。根据您自己的计划或当前的公司基础设施,您可能对这部分将如何成形有一个很好的想法。为了完整起见,让我们讨论一些想法。
Grafana 是一个开源数据可视化和监控平台。它允许用户创建交互式仪表板,用于实时数据分析和跨各种数据源跟踪指标。它是 InfluxDB 最广泛使用的平台之一。有数百篇关于利用 Grafana 和 InfluxDB 的博客和文章,所以让我们关注 3.0 的新功能。

FlightSQL 插件提供了 InfluxDB 和 Grafana 之间的新连接方法,允许用户使用原生 SQL 构建仪表板。下表提供了一些 Grafana 中有用的 SQL 查询。
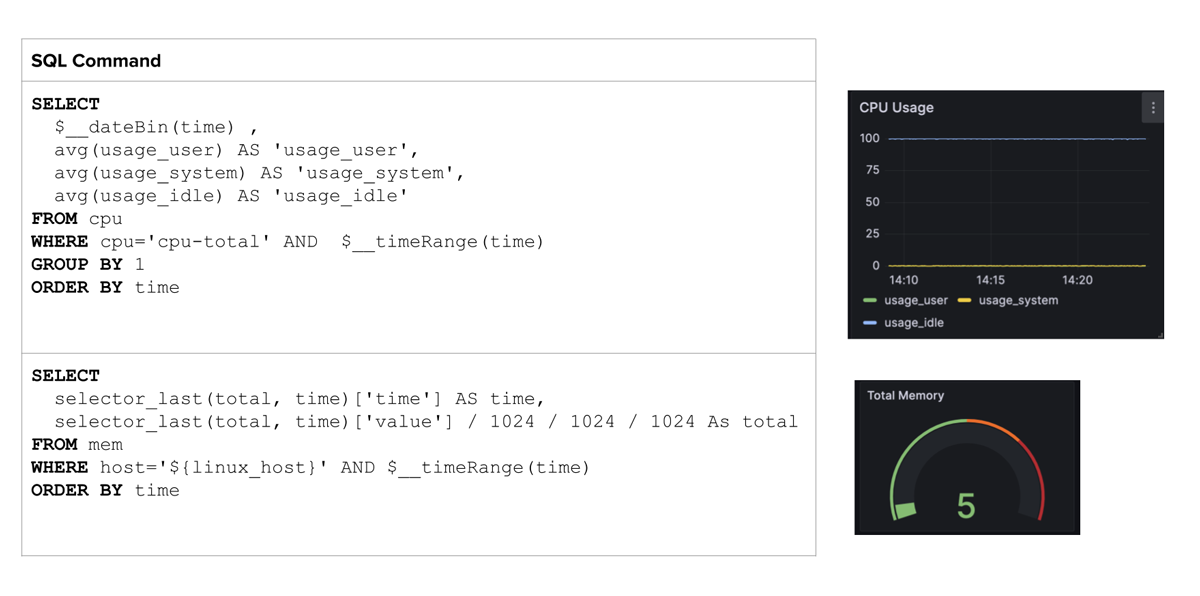
请注意我们如何部署 $__ 变量来使我们的查询动态化。上面的示例显示了监控我们的 CPU 随时间推移的使用情况和最后已知的总内存读取的方法。
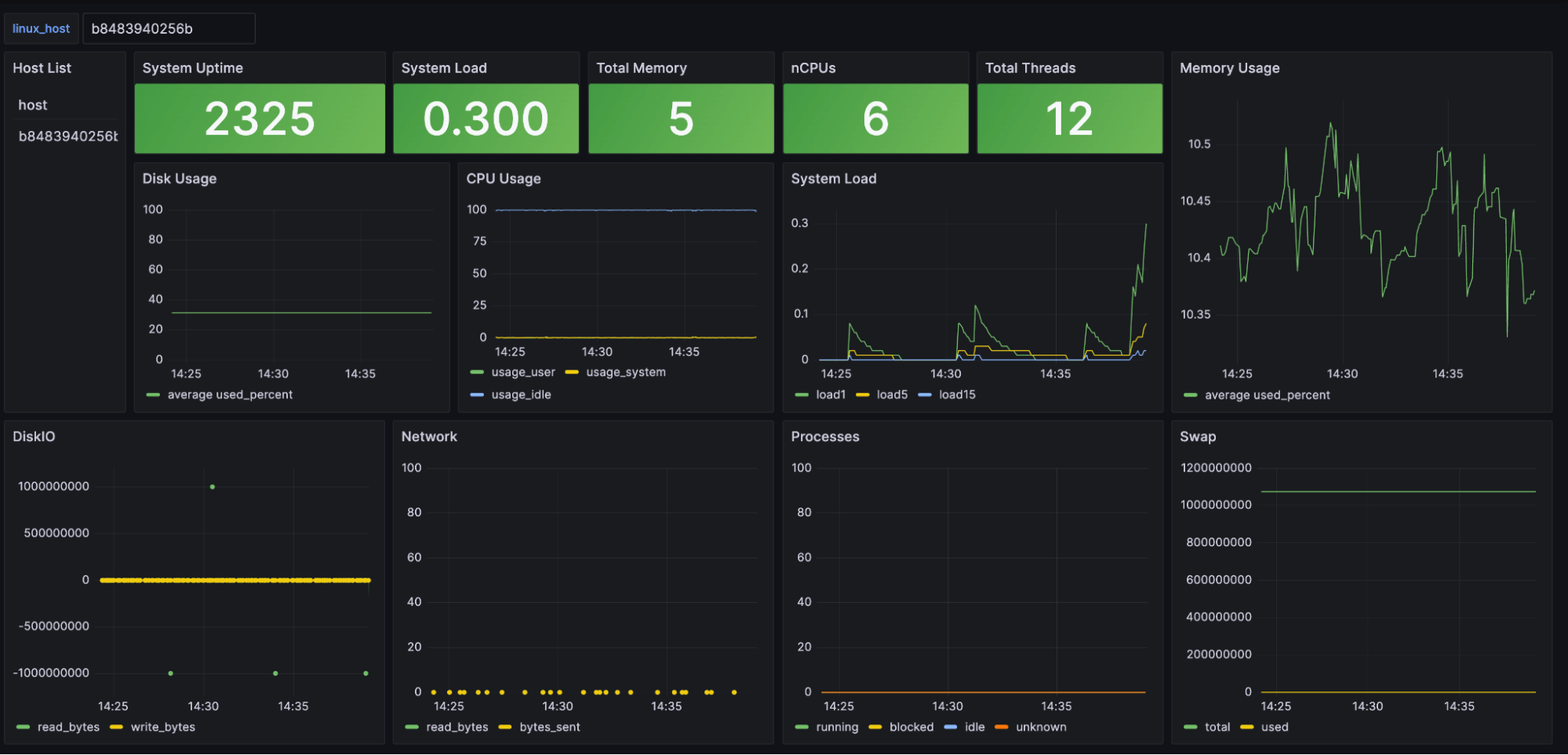
您可以在 此处 找到完整的仪表板。
OpenTelemetry
我想谈的最后一点是 OpenTelemetry。InfluxDB 3.0 为指标、日志和跟踪提供了一个数据存储。我们正在努力提供使 InfluxDB 成为您的 OpenTelemetry 堆栈的即插即用解决方案所需的集成。最终目标是提供通过 Grafana 使用单窗格玻璃可视化和检查跟踪以及指标的能力。
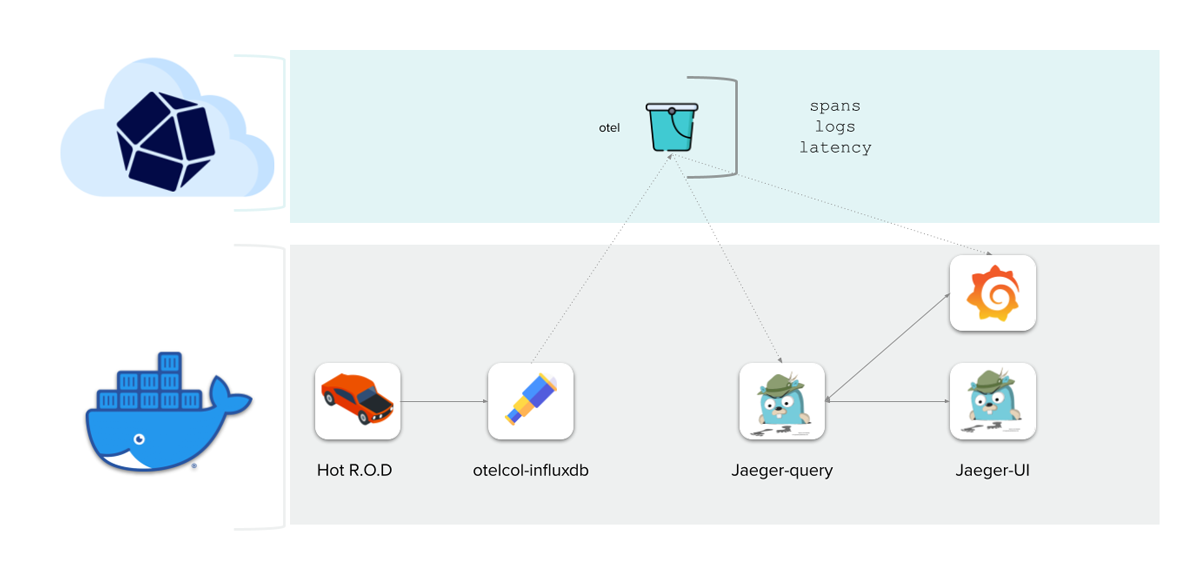
我们使用 Killercoda 提供在线交互式演示,您可以在 此处 试用。
最后的润色
我们构建基础设施监控平台的三步里程碑。
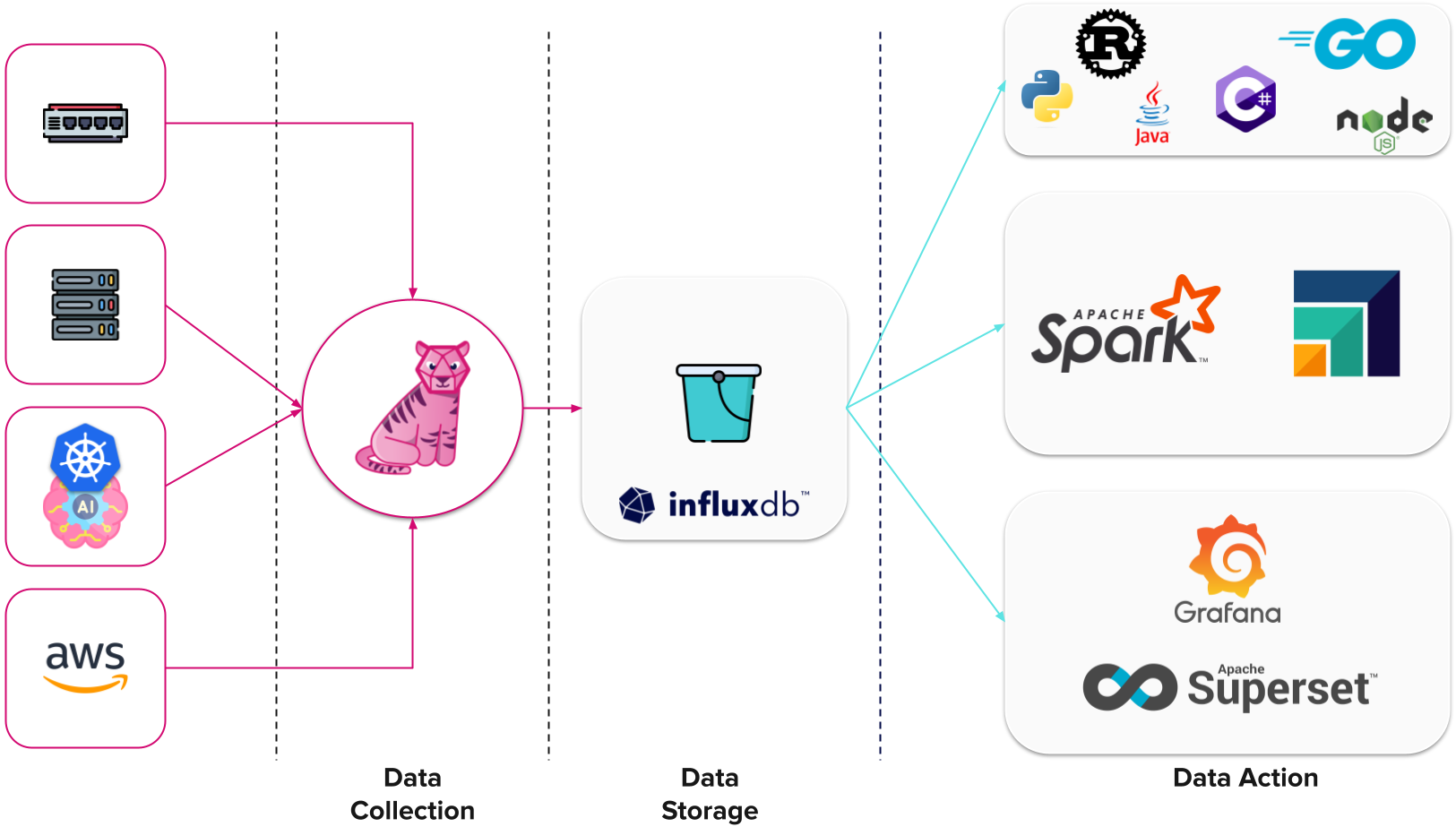
我擅自向数据行动列表添加了一些进一步的集成。让我们通过将其应用于我们的 Whisper GPT 平台来结束。
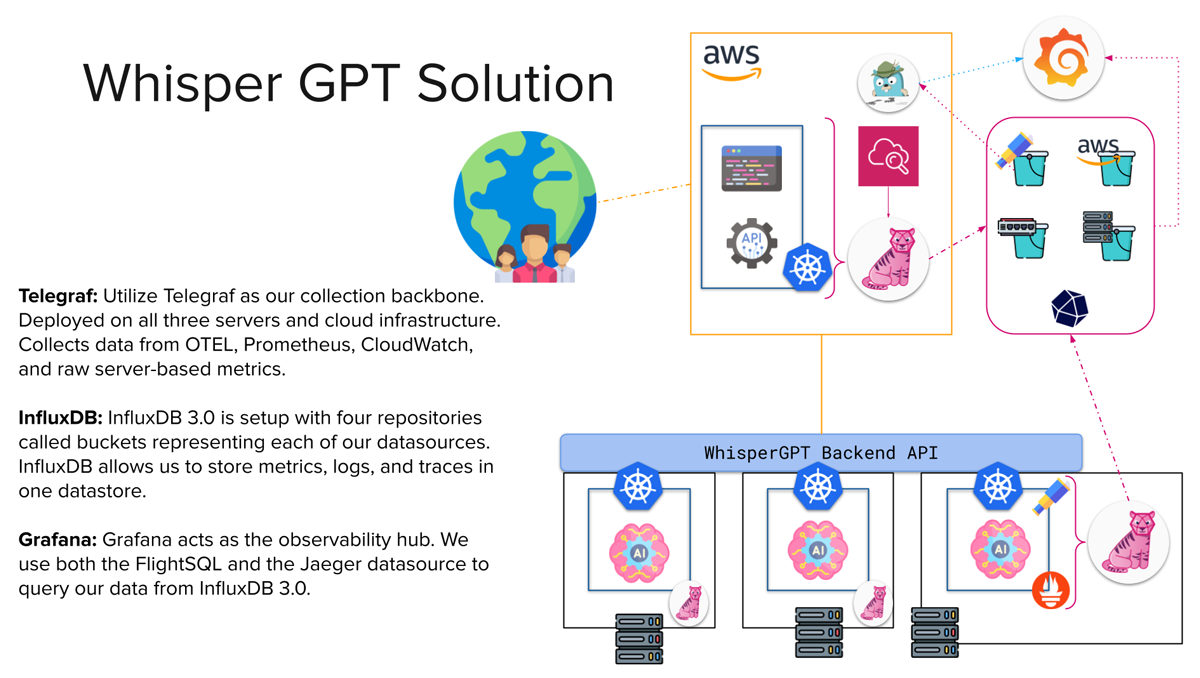
通过集成 Telegraf、InfluxDB 和 Grafana(又名 TIG 堆栈),我们构建了一个可扩展的解决方案,擅长收集、存储和处理跨不同领域的基础设施数据。
我希望这篇博客不仅能启发您了解 InfluxDB 3.0 和基础设施监控的历程,还能激发您对广阔的开源世界的兴趣。开放式架构提供了丰富的优势,您越深入,发现的就越多。如果您对 InfluxDB、Telegraf 或一般基础设施监控有任何问题或意见,请随时通过 Slack 与我联系。我很乐意听到您的声音。
