欢迎来到 InfluxDB IOx:InfluxData 的全新存储引擎
作者:Paul Dix / 产品, 用例
2022 年 10 月 26 日
导航至
两年前,我 宣布 InfluxData 正在为 InfluxDB 开发一个新核心,我们将其命名为 InfluxDB IOx。InfluxDB IOx 是一个云原生、实时、列式数据库,针对时间序列数据进行了优化,基于 Rust 构建,并基于 Apache Arrow 和 DataFusion。今天,我很高兴地宣布,我们在 InfluxDB Cloud 平台中部署了基于 InfluxDB IOx 构建的下一代存储引擎。新的存储引擎是我们核心数据库技术的巨大飞跃,取消了基数限制,因此用户可以引入海量的时间序列数据,实现无限扩展、SQL 查询功能、分层数据存储和快速分析查询。在这篇文章中,我将重点介绍一些核心技术选择以及 InfluxDB 即将推出的令人兴奋的功能。
全新的 InfluxDB
今天的 公告 代表了 InfluxDB 自 2016 年推出 TSM 存储引擎以来最大的飞跃。当时,我们构建了一个针对 InfluxDB 用户最想要的功能优化的存储引擎:快速摄取和查询指标数据。然而,我们一直以来的愿景是 InfluxDB 应该对事件数据(即不规则时间序列)以及指标数据(即规则时间序列)都非常有用。新的存储引擎代表了 InfluxDB 生命的下一阶段,我们将指标数据和事件数据时间序列整合到一个数据库核心中,使用户能够从原始、高精度事件数据中动态创建时间序列。
当我们在 2020 年初首次开始考虑重建 InfluxDB 的核心时,我们也考虑了我们将使用的技术。InfluxDB 最初于 2013 年启动,此后涌现了许多令人兴奋的进展。我们决定新的核心应该用 Rust 构建,因为它在高性能系统软件方面具有许多优势。我们还决定围绕 Apache Arrow 生态系统 构建它,以便与更广泛的开发者群体进行更强的互操作性和协作。两年前半的这两个赌注都非常成功,因为 Rust 和 Arrow 项目都在此期间成熟并聚集了势头。我们很高兴为 Arrow 做出广泛贡献,以帮助推动其作为各种新型数据和分析项目的基石向前发展。
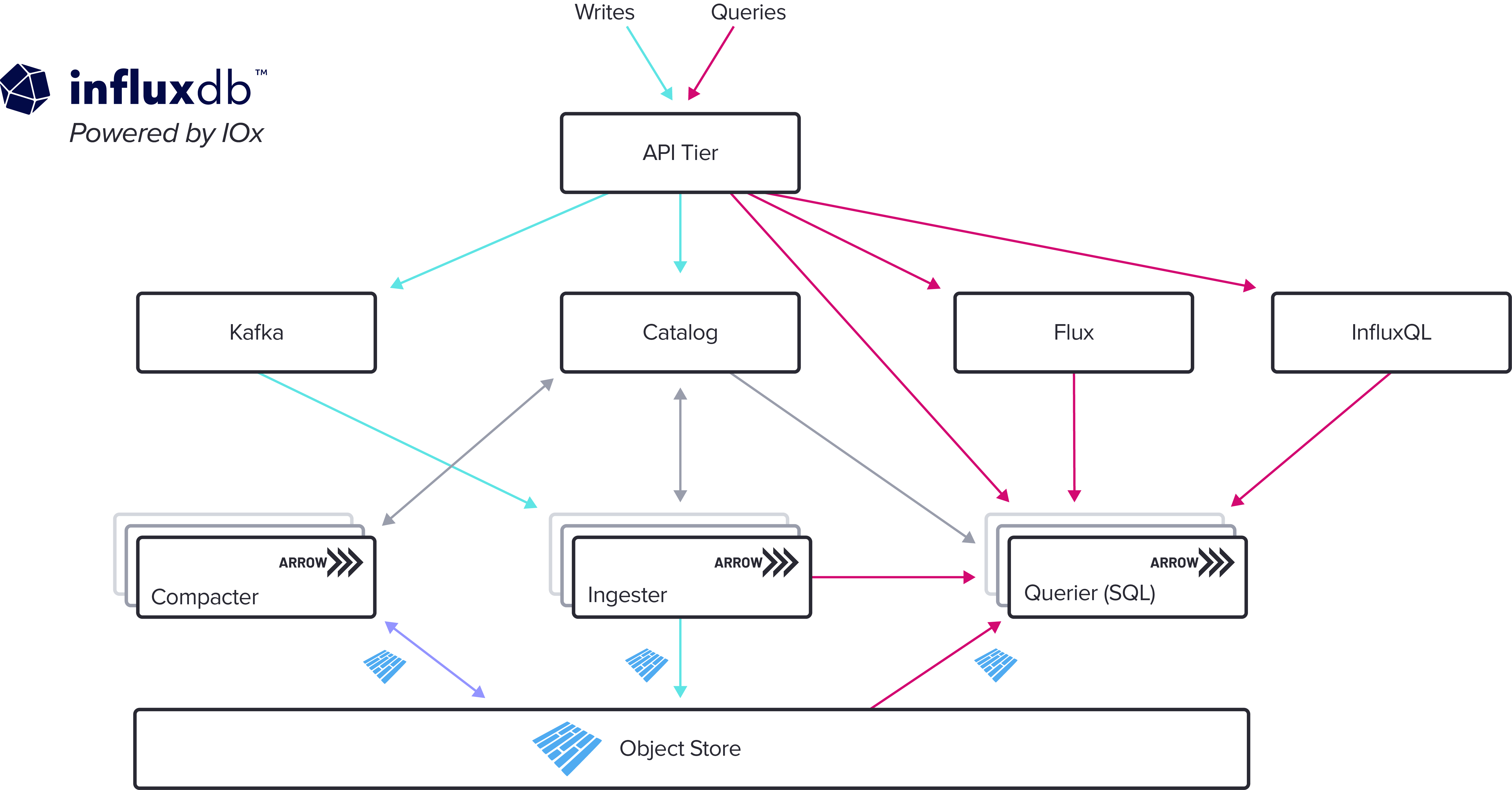
无限制基数、SQL 和实时分析
使用新存储引擎的 InfluxDB Cloud 客户完全取消了他们的 基数 限制。用户可以写入任何类型的具有无限基数的事件数据,并在任何维度上对数据进行切片和切块,而不会牺牲性能。这为事件、跟踪和各种短暂的无限制基数数据等用例打开了大门。
该引擎对高基数的支持不仅限于数据摄取。在 IOx 中,与我们以前版本的 InfluxDB 相比,涉及许多时间序列的查询速度快了几个数量级。查询 10 个系列或 100 万个系列都是一样的。这使得跨高基数数据进行分析成为可能。
IOx 原生支持 SQL,我们的云客户可以使用与 Postgres 兼容的客户端(如 psql、Grafana 的 Postgres 数据源以及 PowerBI 和 Tableau 等 BI 工具)进行连接。随着标准的成熟,我们还将推出 Apache Arrow FlightSQL,为用户提供对数百万行时间序列数据的高性能访问。
即将推出
新的存储引擎代表了一个先进的核心,我们计划在此基础上构建许多新功能。批量数据摄取、批量数据导出以及与其他第三方系统的集成都已计划在不久的将来推出。我们还将推出专用的云层以及基于 IOx 的全新本地部署企业产品。
我们对今天的发布感到非常兴奋,因为它代表了多年的辛勤工作和努力。要利用所有这些进步,请在此注册。
