InfluxDB 3.0:系统架构
作者:Nga Tran / Paul Dix / Andrew Lamb / Marko Mikulicic / 产品
2023 年 6 月 27 日
导航至
InfluxDB 3.0(以前称为 InfluxDB IOx)是一个(云)可扩展数据库,为数据加载和查询提供高性能,并专注于时间序列用例。本文介绍了数据库的系统架构。
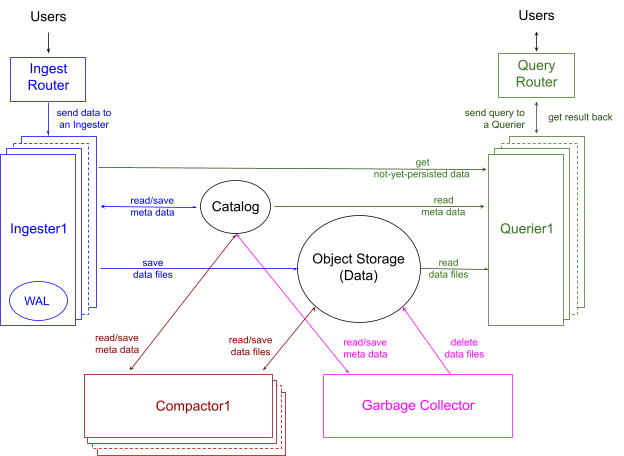
图 1 显示了 InfluxDB 3.0 的架构,其中包括四个主要组件和两个主要存储。
这四个组件几乎独立运行,分别负责:
-
数据摄取(蓝色部分所示),
-
数据查询(绿色部分所示),
-
数据压缩(红色部分所示),以及
-
垃圾回收(粉色部分所示)。
对于两种存储类型,一种专用于集群元数据,名为 Catalog(目录),另一种更大,用于存储实际数据,名为 Object Storage(对象存储),例如 Amazon AWS S3。除了这些主要存储位置之外,还有更小的数据存储,称为 Write Ahead Log(预写日志) (WAL),仅供摄取组件在数据加载期间进行崩溃恢复使用。
图表中的箭头显示了数据流方向;如何通信以拉取或推送数据超出了本文的范围。对于已持久化的数据,我们将系统设计为仅将 Catalog 和 Object Storage 作为状态,并使每个组件仅读取这些存储,而无需与其他组件通信。对于尚未持久化的数据,数据摄取组件管理状态,以便在查询到达时发送到数据查询组件。让我们通过逐个了解每个组件来深入研究这种架构。
数据摄取
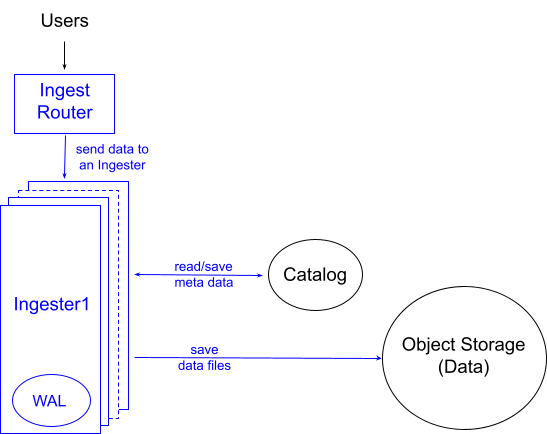
图 2 展示了 InfluxDB 3.0 中数据摄取的设计。用户将数据写入 Ingest Router(摄取路由器),后者将数据分片到一个 Ingesters(摄取器) 中。集群中摄取器的数量可以根据数据工作负载进行横向和纵向扩展。我们使用 这些扩展原则 来分片数据。每个摄取器都有一个附加存储,例如 Amazon EBS,用作预写日志 (WAL) 以进行崩溃恢复。
每个摄取器执行以下主要步骤:
-
识别数据表:与许多其他数据库不同,用户无需在将数据加载到 InfluxDB 之前定义其表及其列模式。它们将由摄取器发现并隐式添加。
-
验证数据模式:用户写入中提供的数据类型会与写入请求同步进行严格验证。这可以防止类型冲突传播到系统的其余部分,并为用户提供即时反馈。
-
对数据进行分区:在像 InfluxDB 这样的大规模数据库中,数据分区有很多好处。摄取器负责分区工作,目前它按“时间”列按天对数据进行分区。如果摄取的数据没有时间列,Ingest Router 会隐式添加它并将其值设置为数据加载时间。
-
数据去重:在时间序列用例中,常见的是相同的数据被多次摄取,因此 InfluxDB 3.0 执行 去重过程。摄取器为去重工作构建高效的多列排序合并计划。由于 InfluxDB 使用 DataFusion 进行查询执行,并使用 Arrow 作为其内部数据表示,因此构建排序合并计划只需将 DataFusion 的排序和合并运算符放在一起即可。有效运行该排序合并计划 在多列上 是 InfluxDB 团队为 DataFusion 贡献的工作的一部分。
-
持久化数据:然后,处理和排序后的数据将持久化为 Parquet 文件。由于如果数据按基数最小的列排序,则可以非常有效地进行编码/压缩,因此摄取器会查找并选择基数最小的列作为上述排序的排序顺序。因此,文件的大小通常比其原始形式小 10-100 倍。
-
更新 Catalog(目录):然后,摄取器更新 Catalog,告知新创建文件的存在。这是一个信号,告知其他两个组件 Querier(查询器) 和 Compactor(压缩器),新数据已到达。
即使摄取器执行许多步骤,InfluxDB 3.0 也会优化写入路径,使写入延迟保持在毫秒级最小值。这可能会导致系统中出现许多小文件。但是,我们不会长期保留它们。压缩器(将在后面的章节中描述)在后台压缩这些文件。
摄取器还支持容错,这超出了本文的范围。摄取器的详细设计和实现值得单独撰写博客文章。
数据查询
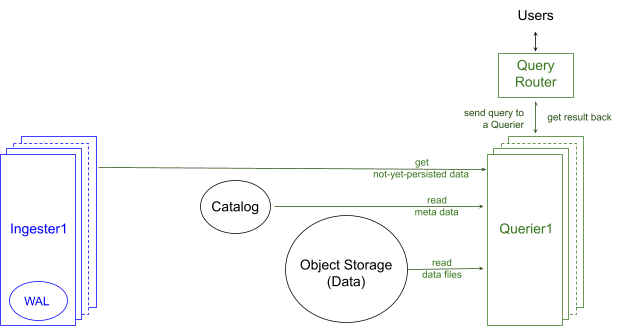
图 3 显示了 InfluxDB 3.0 如何查询数据。用户将 SQL 或 InfluxQL 查询发送到 Query Router(查询路由器),后者将其转发到 Querier(查询器),查询器读取所需数据,构建查询计划,运行该计划,并将结果返回给用户。查询器的数量可以根据查询工作负载进行横向和纵向扩展,使用与摄取器设计中相同的 扩展原则。
每个查询器执行以下主要任务:
-
缓存元数据:为了有效地支持高查询工作负载,查询器会使其元数据缓存与中央目录同步,以保持最新的表及其摄取的元数据。
-
读取和缓存数据:当查询到达时,如果其数据在查询器的数据缓存中不可用,则查询器首先将数据读取到缓存中,因为我们从统计数据中得知,相同的文件将被多次读取。查询器仅缓存回答查询所需的文件内容;查询器根据其剪枝策略不需要的文件的其他部分永远不会被缓存。
-
从摄取器获取尚未持久化的数据:由于摄取器中可能存在尚未持久化到对象存储中的数据,因此查询器必须与相应的摄取器通信以获取该数据。通过这种通信,查询器还从摄取器了解到是否有更新的表和数据来使缓存失效并更新其缓存,从而获得整个系统的最新视图。
-
构建和执行最佳查询计划:与许多其他数据库一样,InfluxDB 3.0 查询器包含一个查询优化器。查询器构建最合适的查询计划(又名最佳计划),该计划在来自缓存和摄取器的数据上执行,并在最短的时间内完成。与摄取器的设计类似,查询器使用 DataFusion 和 Arrow 来构建和执行 SQL(以及即将推出的 InfluxQL)的自定义查询计划。查询器利用摄取器中完成的 数据分区 来并行化其查询计划,并在执行计划之前剪枝不必要的数据。查询器还应用 谓词和投影下推 的常用技术,以便尽快进一步剪枝数据。
即使每个文件中的数据本身不包含重复项,但不同文件中的数据以及从摄取器发送到查询器的尚未持久化的数据可能包含重复项。因此,在查询时进行去重过程也是必要的。与摄取器类似,查询器使用上述相同的多列排序合并运算符进行去重工作。与为摄取器构建的计划不同,这些运算符只是为执行查询而构建的更大、更复杂的查询计划的一部分。这确保了数据在去重后流经计划的其余部分。
值得注意的是,即使使用高级多列排序合并运算符,其执行成本也不小。查询器进一步优化计划,仅对可能发生重复项的重叠文件进行去重。此外,为了在查询器中提供高查询性能,InfluxDB 3.0 通过预先压缩数据,尽可能避免在查询时进行去重。下一节将介绍压缩过程。
上面简要描述的查询器任务的详细设计和实现值得单独撰写博客文章。
数据压缩
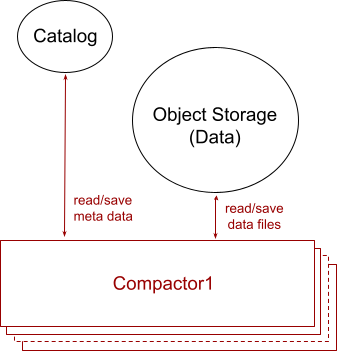
如“数据摄取”部分所述,为了减少摄取延迟,摄取器处理并持久化到每个文件中的数据量非常少。这会在对象存储中留下许多小文件,从而在查询时产生大量的 I/O 并降低查询性能。此外,如“数据查询”部分所述,重叠的文件可能包含需要在查询时进行去重的重复项,这会降低查询性能。数据压缩的工作是将摄取器摄取的许多小文件压缩为更少、更大且非重叠的文件,以提高查询性能。
图 4 说明了数据压缩的架构,其中包括一个或多个 Compactors(压缩器)。每个压缩器运行一个后台作业,该作业读取新摄取的文件并将它们压缩在一起,形成更少、更大且非重叠的文件。压缩器的数量可以根据压缩工作负载进行横向和纵向扩展,压缩工作负载是具有新数据文件的表数量、每个表的新文件数量、文件的大小、新文件与现有文件重叠的程度以及表的宽度(又名表中有多少列)的函数。
在文章 Compactor: A hidden engine of database performance(压缩器:数据库性能的隐藏引擎) 中,我们详细描述了压缩器的任务:它如何构建优化的去重计划来合并数据文件,不同列文件的排序顺序,这有助于去重,使用压缩级别来实现非重叠文件,同时最大限度地减少重新压缩,以及在查询器中构建针对非重叠和重叠文件混合的优化去重计划。
与摄取器和查询器的设计类似,压缩器使用 DataFusion 和 Arrow 来构建和执行自定义查询计划。实际上,所有三个组件共享相同的压缩子计划,该子计划涵盖数据去重和合并。
压缩成更大且非重叠文件的小文件和/或重叠文件必须删除以回收空间。为了避免删除正在被查询器读取的文件,压缩器从不硬删除任何文件。相反,它在目录中将文件标记为软删除,另一个名为 Garbage Collector(垃圾回收器)的后台服务最终会删除软删除的文件以回收存储空间。
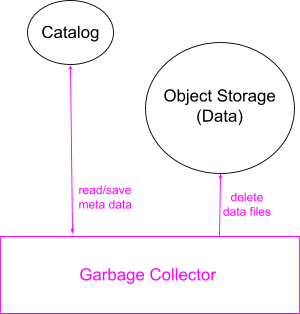
垃圾回收
图 5 说明了 InfluxDB 3.0 垃圾回收的设计,该设计负责数据保留和空间回收。Garbage Collector(垃圾回收器) 运行后台作业,这些作业计划软删除和硬删除数据。
数据保留
InfluxDB 为用户提供了一个选项来定义其数据保留策略并将其保存在目录中。垃圾回收器的计划后台作业读取目录中超出保留期的表,并在目录中将其文件标记为软删除。这向查询器和压缩器发出信号,表明这些文件不再可用于查询和压缩。
空间回收
垃圾回收器的另一个计划后台作业读取目录中一段时间前软删除的文件的元数据。然后,它从对象存储中删除相应的数据文件,并从目录中删除元数据。
请注意,软删除的文件来自不同的来源:压缩器删除的压缩文件、垃圾回收器本身删除的超出保留期的文件以及 InfluxDB 3.0 计划在未来支持的通过删除命令删除的文件。硬删除作业不需要知道软删除来自何处,并且对它们一视同仁。
软删除和硬删除是另一个庞大的主题,涉及摄取器、查询器、压缩器和垃圾回收器中的工作,值得单独撰写博客文章。
InfluxDB 3.0 集群设置
除了查询器向其相应的摄取器发出尚未持久化的数据请求外,这四个组件彼此之间不直接通信。所有通信都通过 Catalog(目录)和 Object Storage(对象存储)完成。摄取器和查询器甚至不知道压缩器和垃圾回收器的存在。但是,如上文强调的那样,InfluxDB 3.0 旨在使所有四个组件共存,以提供高性能数据库。
除了这些主要组件之外,InfluxDB 还有其他服务,例如 Billing(计费),用于根据客户的使用情况向其收费。
Catalog Storage(目录存储)
InfluxDB 3.0 Catalog(目录)包括数据的元数据,例如数据库(又名命名空间)、表、列和文件信息(例如文件位置、大小、行数等)。InfluxDB 使用与 Postgres 兼容的数据库来管理其目录。例如,本地集群设置可以使用 PostgreSQL,而 AWS 云设置可以使用 Amazon RDS。
Object Storage(对象存储)
InfluxDB 3.0 数据存储仅包含 Parquet 文件,这些文件可以存储在本地磁盘上以进行本地设置,也可以存储在 Amazon S3 中以进行 AWS 云设置。该数据库还可以在 Azure Blob Storage 和 Google Cloud Storage 上运行。
InfluxDB 3.0 集群操作
InfluxDB 3.0 客户可以设置多个专用集群,每个集群独立运行,以避免“嘈杂邻居”问题并控制潜在的可靠性问题。每个集群都利用其自己的专用计算资源,并且可以在单个或多个 Kubernetes 集群上运行。这种隔离还控制了可能因另一个集群中的活动而在一个集群内出现的可靠性问题的潜在爆炸半径。
我们创新的基础设施升级方法利用整个 Kubernetes 集群的原位更新。InfluxDB 3.0 集群中的大部分状态都存储在 Kubernetes 集群之外(例如 S3 和 RDS)这一事实有助于实现此过程。
我们的平台工程系统使我们能够协调跨数百个集群的操作,并为客户提供对其性能和成本的特定集群参数的控制。持续监控每个集群的健康状况是我们运营的一部分,使一个小团队能够在快速发展的软件环境中有效地管理大量集群。
