我们是如何做到的:InfluxDB 3.0 中的数据摄取和压缩增益
作者:Rick Spencer / 产品, 公司
2023 年 10 月 04 日
导航至
几周前,我们发布了一些基准测试,显示 InfluxDB 3.0 的性能增益比以前版本的 InfluxDB 提高了几个数量级——并且扩展到其他数据库也是如此。 有两个关键因素影响这些增益:1. 数据摄取,以及 2. 数据压缩。 这就引出了一个问题,我们究竟是如何在核心数据库中实现如此巨大的改进的?
这篇文章旨在解释我们如何为任何感兴趣的人实现这些改进。
TSM 回顾
为了理解我们最终的结果,重要的是要理解我们从哪里来。 为 InfluxDB 1.x 和 2.x 提供支持的存储引擎是我们称之为 InfluxDB 时间结构化合并树 (TSM) 的东西。 让我们简要了解一下 TSM 中的数据摄取和压缩。
TSM 数据模型
关于 TSM 数据模型有很多信息,但如果您想要快速概览,请查看 TSM 文档 此处 中的信息。 以此作为入门,让我们将注意力转向数据摄取。
TSM 摄取
TSM 使用倒排索引将元数据映射到磁盘上的特定序列。 如果写入操作添加了新的测量或标签键/值对,则 TSM 会更新倒排索引。 TSM 需要将此数据写入磁盘上的正确位置,本质上是在写入时对其进行索引。 整个过程需要大量的 CPU 和 RAM。
TSM 引擎按时间对文件进行分片,这允许数据库强制执行保留策略,逐出过期数据。
TSI 介绍
在 2017 年之前,InfluxDB 在启动时计算倒排索引,在写入期间维护它,并将其保存在内存中。 这导致启动时间非常长,因此在 2017 年秋季,我们引入了时间序列索引 (TSI),它本质上是持久化到磁盘的倒排索引。 然而,这带来了另一个挑战,因为磁盘上 TSI 的大小可能会变得非常大,特别是对于高基数用例。
TSM 压缩
TSM 使用游程编码进行压缩。 这种方法对于数据时间戳以规则间隔发生的指标用例非常有效。 InfluxDB 能够存储开始时间和时间间隔,然后仅根据行数在查询时计算每个时间戳。 此外,TSM 引擎可以在实际字段数据上使用游程编码。 因此,在数据不经常更改且时间戳规则的情况下,InfluxDB 可以非常有效地压缩数据。
但是,时间戳间隔不规则或数据几乎每次读取都发生变化的用例降低了压缩的有效性。 TSI 使情况进一步复杂化,因为它在高基数用例中可能会变得非常大。 这意味着 InfluxDB 达到了实际的压缩限制。
InfluxDB 3.0 介绍
当我们着手构建 InfluxDB 3.0 时,我们决心解决与摄取效率和压缩相关的这些限制,并消除基数限制,使 InfluxDB 能够有效地用于更广泛的时间序列用例。
3.0 数据模型
我们从头开始重新思考数据模型。 虽然我们保留了将数据分离到数据库中的概念,而不是持久化时间序列,但 InfluxDB 3.0 按表持久化数据。 在 3.0 世界中,“表”类似于 InfluxDB 1.x 和 2.x 中的“measurement”。
InfluxDB 3.0 按天对磁盘上的每个表进行分片,并将数据以 Parquet 文件格式持久化。 将磁盘上的数据可视化看起来像一组 Parquet 文件。 数据库的默认行为是每十五分钟生成一个新的 Parquet 文件。 稍后,压缩过程可以获取这些文件并将它们合并为更大的文件,其中每个文件代表单个 measurement 的一天数据。 这里的注意事项是我们限制每个 Parquet 文件的大小为 100 兆字节,因此重度用户每天可能有多个文件。

InfluxDB 3.0 的 Parquet 文件分区和数据模型示例
InfluxDB 3.0 保留了标签和字段的概念; 但是,它们在 3.0 中扮演着不同的角色。 一组唯一的标签值和一个时间戳标识一行,这使 InfluxDB 可以在写入时使用 UPSERT 更新它。
现在我们已经解释了一些关于新数据模型的内容,让我们转向它如何使我们能够提高数据摄取效率和压缩。
备用分区选项
我们将 InfluxDB 3.0 设计为执行分析查询(即跨大量行汇总的查询),并为此优化了默认分区方案。 但是,用户可能总是需要查询某些 measurement 的标签值子集。 例如,如果每个查询都包含特定的客户 ID 或传感器 ID。 由于 TSM 索引数据并将其持久化到磁盘的方式,TSM 可以很好地处理这种类型的查询。 InfluxDB 3.0 情况并非如此,因此使用默认分区方案的用户对于这些特定查询可能会遇到性能下降。
InfluxDB 3.0 中对此的解决方案是自定义分区。 自定义分区允许用户根据标签键和标签值定义分区方案,并为每个分区配置时间范围。 这种方法使用户能够在 InfluxDB 3.0 中为这些特定查询类型实现类似的查询性能,同时保留其摄取和压缩优势。
InfluxDB 3.0 摄取路径
InfluxDB 3.0 的数据模型比以前的版本更简单,因为每个 measurement 将其所有数据组合在一起,而不是按序列将其分隔开。 这简化了数据摄取过程。 当 InfluxDB 3.0 处理写入时,它会验证模式,然后查找内存中该 measurement 的任何其他数据的结构。 然后,数据库将数据附加到 measurement 并向用户返回成功或失败。 同时,它将数据附加到预写日志 (WAL)。 我们将这些内存结构称为“可变批次”或“缓冲区”,原因将在下文中明确说明。
与其他数据库(包括 InfluxDB 1.x 和 2.x)相比,此过程需要的计算资源更少,因为与其他数据库不同
- 摄取过程不对数据进行排序或以其他方式排序; 它只是附加它。
- 摄取过程将数据重复数据删除延迟到持久化。
- 摄取过程使用缓冲区树作为索引。 此索引位于每个特定的摄取器实例中,并标识特定查询所需的数据。 我们能够通过使用分层/分片锁定和引用计数来消除争用,从而使此缓冲区树具有极高的性能。
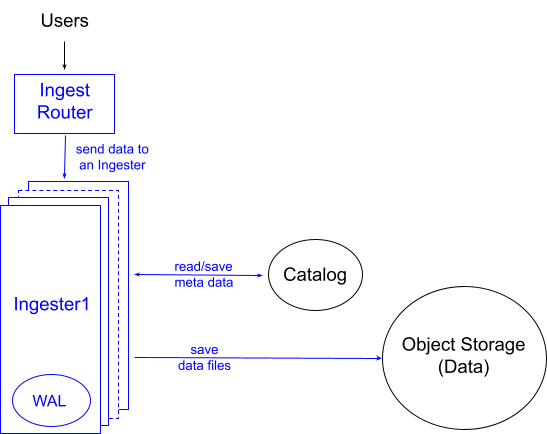
当可变批次内存不足时,InfluxDB 会将缓冲区中的数据持久化为对象存储中的 Parquet 文件。 默认情况下,如果内存缓冲区尚未填满,InfluxDB 将每 15 分钟将所有数据持久化到 Parquet 中。 这是 InfluxDB 3.0 对数据进行排序和重复数据删除的点。 将此工作从“热/写入路径”中延迟可以保持低延迟和低差异。
以这种方式简化摄取过程意味着数据库在热/写入路径上做的工作更少。 结果是一个将执行成本高昂的操作转移到持久化时间的过程,从而即使对于重要的写入工作负载,总体上只需要最少的 CPU 和 RAM。
从完整性来看,还有一个预写日志会定期刷新,确保所有写入都立即持久,并用于在容器发生故障时重建可变批次。 InfluxDB 3.0 仅在不干净的关机或崩溃情况下重放 WAL 文件。 在“happy path”(例如,升级)中,系统会优雅地停止,刷新(即持久化)所有缓冲数据到对象存储并删除所有 WAL 条目。 因此,启动速度很快,因为 InfluxDB 不必重放 WAL。 此外,在非复制部署中,否则会位于脱机节点上的 WAL 磁盘上的数据实际上位于对象存储中并且可读,从而保留了读取可用性。
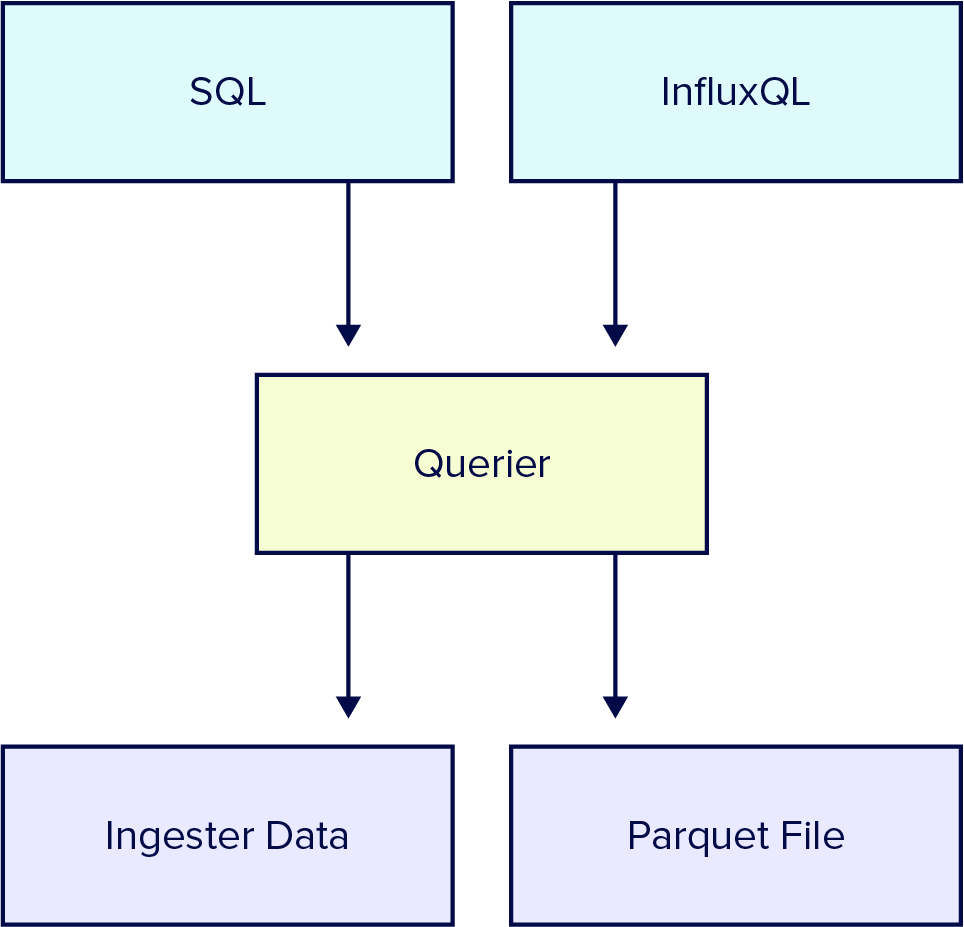
前沿查询
我们还优化了 InfluxDB 3.0,以查询数据的前沿。 大多数查询,特别是时间敏感的查询,都会查询最近写入的数据。 我们将这些查询称为“前沿”查询。
当查询进入时,InfluxDB 将数据转换为 Arrow,然后由 DataFusion 查询引擎查询。 如果被查询的所有数据都已存在于可变批次中,则摄取器以 Arrow 格式向查询器提供数据,然后 DataFusion 在将数据返回给用户之前快速执行任何必要的排序和重复数据删除。
如果部分或全部数据不在读取缓冲区中,InfluxDB 3.0 会使用其 Parquet 文件目录(存储在快速关系数据库中)来查找要加载到内存中的特定文件和行(以 Arrow 格式)。 加载到内存后,DataFusion 能够快速查询此数据。
压缩
一系列压缩过程有助于维护数据目录。 这些过程通过对数据进行排序和重复数据删除来优化存储的 Parquet 文件。 这使得在磁盘上查找和读取 Parquet 文件变得高效。
数据压缩
我们选择 Apache Arrow 生态系统(包括 Parquet)用于 InfluxDB 3.0 有几个关键原因。 这些格式从一开始就设计为支持对大型数据集进行高性能分析查询。 因为它们是为列式数据结构设计的,所以它们也可以实现显着的压缩。 Apache Arrow 社区(我们很荣幸成为其中的一部分并为其做出贡献)继续改进这些技术。
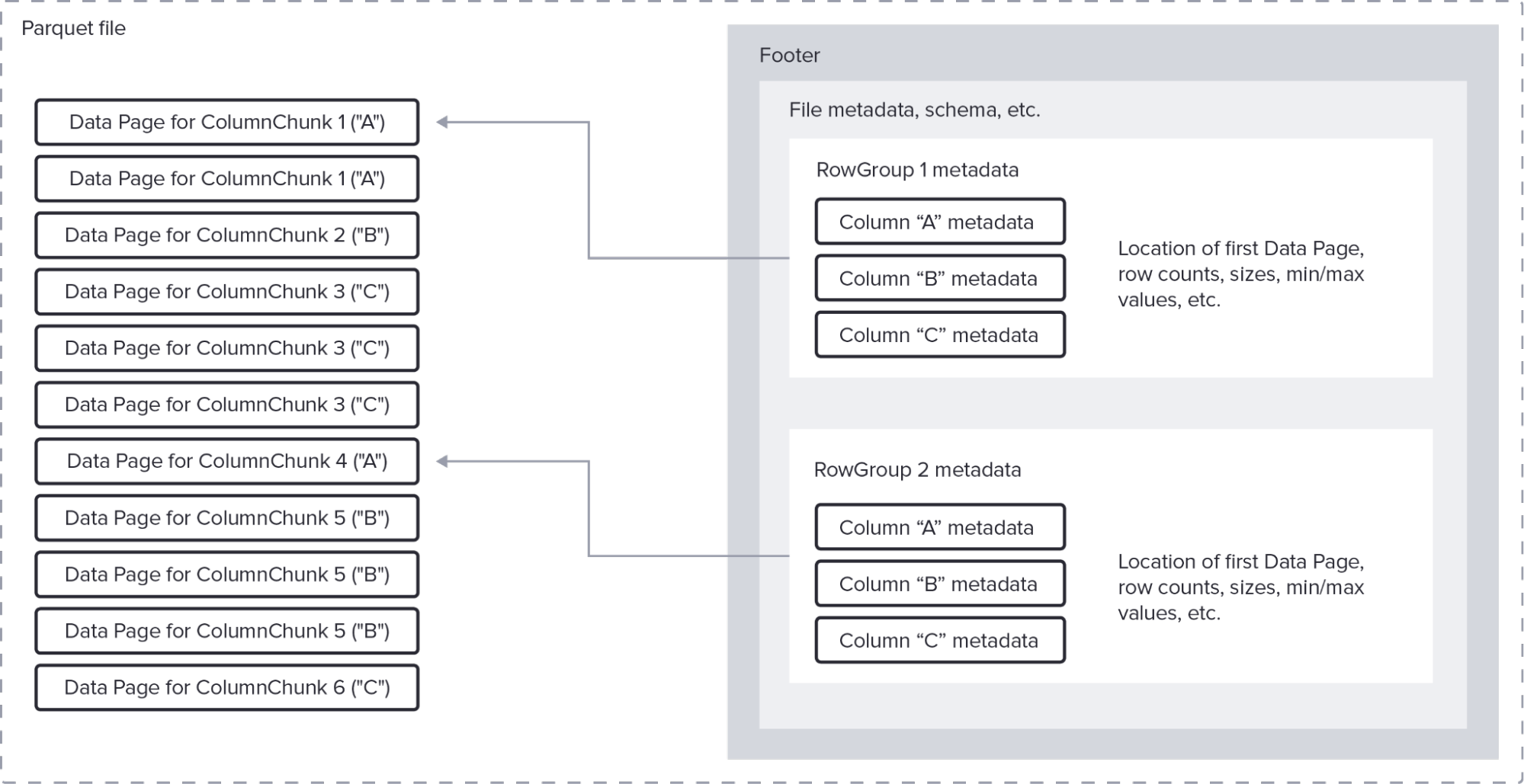 Parquet 文件格式
Parquet 文件格式
因此,由于 InfluxDB 3.0 从 Arrow 的列式结构开始,它继承了显着的压缩优势。 使用 Parquet 会加剧这些优势。 此外,由于 InfluxDB 是一个时间序列数据库,我们可以对时间序列数据做出一些假设,这使我们能够最大限度地利用这些压缩技术。
例如,假设保留 InfluxDB 3.0 中标签键/值对的概念意味着对这些列进行字典编码将产生最佳压缩效果。 在这种情况下,字典编码为每个标签值分配一个数字。 该数字在磁盘上占用少量字节。 然后,Parquet 可以为每个标签键列对这些数字进行游程编码。 在此编码方案之上,InfluxDB 可以应用通用压缩(例如,gzip、zstd)来进一步压缩数据。
Arrow 和 Parquet 的整体结合产生了显着的压缩增益。 当您将这些增益与 InfluxDB 3.0 依赖对象存储来存储历史数据这一事实结合起来时,用户可以在更小的空间中存储更多数据,而成本仅为一小部分。
总结
希望您发现对 InfluxDB 3.0 如何实现如此令人印象深刻的摄取效率和压缩的解释很有趣。 结合计算和存储的分离,客户可以实现比其他数据库(包括 InfluxDB 1.x 和 2.x)更显着的总体拥有成本优势!
试用 InfluxDB 3.0,了解这些性能和压缩增益如何影响您的应用程序。
