Flight、DataFusion、Arrow 和 Parquet:使用 FDAP 架构构建 InfluxDB 3.0
作者:Andrew Lamb / 开发者
2023 年 10 月 25 日
导航至
本文创造了“FDAP 堆栈”一词,解释了我们为什么使用它来构建 InfluxDB 3.0,并论证了它将以 LAMP 堆栈启用和驱动一代交互式网站相同的方式,启用和驱动一代分析应用程序(顺便说一句,我们正在招聘!)。
背景
当 InfluxData 创始人 Paul Dix 宣布 InfluxDB IOx 项目时,他实际上押注 FDAP 堆栈将构成分析系统的未来基础。几年后,这一预测正变得越来越有先见之明。
随着要管理的数据呈指数级增长(预计到 2025 年每天将产生 463 艾字节),对数据库、数据准备管道和 ETL/ELT 工具等新型分析系统的需求也在增长。一种尺寸并不适合所有数据系统设计,专注于特定数据类型(如时间序列、机器人日志或金融交易)的系统可能比单体数据平台快 10-100 倍且更高效(因此成本更低)。
然而,直到最近五年,构建以数据为中心的系统还明显缺乏可重用组件。这迫使系统设计人员不断地重新实现(并重新测试和维护)许多复杂但现在已被充分理解的系统技术。Flight、DataFusion、Arrow 和 Parquet,(FDAP) 堆栈,最终使我们能够在不进行此类重复发明的情况下构建新系统,从而实现比传统设计更多的功能和更好的性能。

图 1:构建分析系统的相对投入,其中每个彩色框的大小代表相对投入的精力。一个紧密集成的系统(左)具有较少的特定领域功能(较小的粉色框),因为它必须在相同的预算下重新实现许多复杂的、低级别但无差异的组件(橙色框)。使用基于 FDAP 的系统(右),FDAP 组件(蓝色)是免费的,这导致更多的功能(更大的粉色框),并且每个单独的组件都比自定义重新实现更好。
FDAP 堆栈
本节介绍 FDAP 堆栈的技术,以及我们为什么选择它们用于 InfluxDB 3.0。
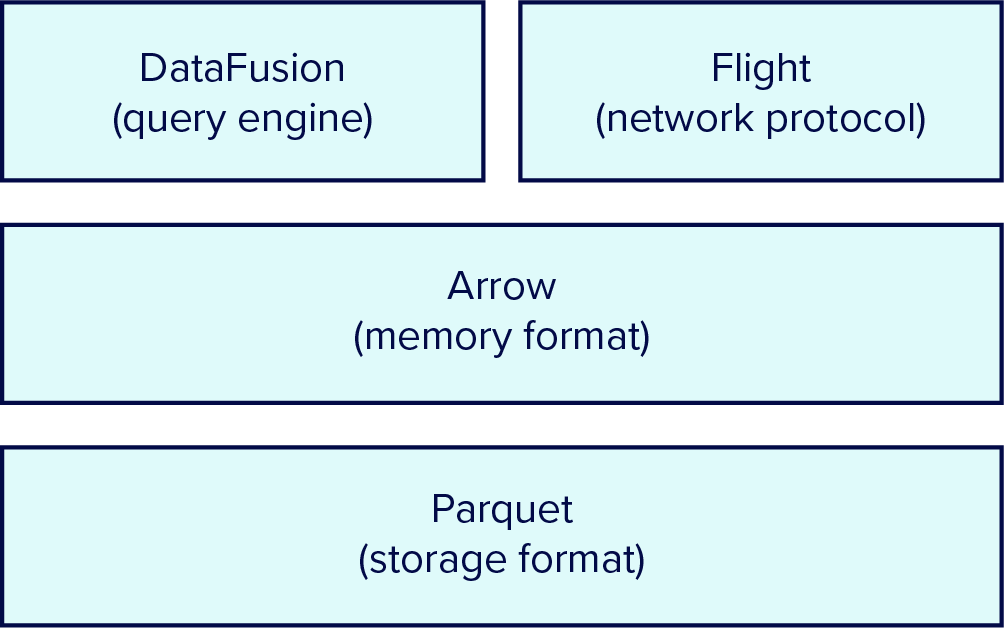
图 2:FDAP 堆栈:Flight 提供高效且可互操作的网络数据传输。DataFusion 通过查询和执行运算符提供数据访问。Arrow 提供高效的内存表示和快速计算。Parquet 提供良好压缩、高性能的存储。
Arrow
为了处理数据,系统必须以适合处理的格式在主内存中表示数据。在实施 InfluxDB 3.0 时,我们选择使用 Apache Arrow 来实现此目的,因为它具有效率、性能、开放库和广泛的开放生态系统。
通过使用 Arrow,我们
- 避开了定义、实施和维护诸如内存布局、有效性/空值表示、字节序、可变长度数据存储、时间戳/持续时间表示、字典和分层数据类型等细节的繁琐(但重要)的工作。
- 避免了将内部内存表示转换为适合其他库和系统的格式的运行时开销,例如写入 Parquet 文件或向 Python 脚本提供数据。
Arrow 的核心只是使用最佳实践、缓存高效的列式布局标准化内存中的数据表示。如果您发现自己担心如何表示空值(作为位掩码?1 表示空值还是有效值?)、如何有效地比较多个列或如何最好地向量化不同选择性的低级别过滤操作等细节,您可能应该使用 Arrow 及其库。
当我们开始使用 Arrow 的 Rust 实现 arrow-rs 时,它还相对较新。随着时间的推移,InfluxData 和许多其他贡献者投入了大量时间和专业知识,使其成为最佳 Arrow 实现之一,包括许多高度优化的计算内核、通过标准化键实现的快速比较以及完整的类型支持。如果我们尝试自己重新实现所有这些,InfluxDB 3.0 不太可能具有这些功能。
Flight
InfluxDB 3.0 像许多为云操作设计的数据库一样,由多个服务组成,这些服务通过网络链接相互通信以及与客户端通信。我们选择 Apache Arrow Flight 用于大部分这种通信,包括集群内部以及与客户端之间的通信。Flight 是一种使用基于 gRPC 的 API 在网络上快速发送 Arrow 数组的协议。
使用 Flight 使我们不必
- 定义我们自己的高效网络协议(我为此感到高兴,因为有充分的证据表明创建此类高效协议并非易事)
- 在多种语言中实现该协议:服务器端的 Rust,以及每种客户端语言的单独实现(在撰写本文时为 Rust、Golang、Python 和 Java)。
向 InfluxDB 3.0 添加新的语言客户端非常简单:我们只需在现有 Flight 客户端之上为该语言构建新的客户端(至少有十三个!),这负责繁重的工作。

图 2.5:Arrow Flight 以流式方式、高效快速地处理通过网络发送 Arrow 数组的所有底层细节,而无需转码开销。InfluxDB 3.0 服务器提供 Arrow 数组,客户端获取 Arrow 数组。
此外,我们在 Flight 之上实现了 Arrow FlightSQL 协议,这使 InfluxDB 3.0 可以在基于 SQL 的生态系统中工作。有 FlightSQL 的客户端实现了 JDBC、ODBC 和 Python DBI 等流行的接口,我们可以直接使用它们而无需修改。与我使用过的其他系统不同,InfluxDB 3.0 没有客户端驱动程序团队,并且可能不需要,这要归功于 Flight 和 FlightSQL。(顺便说一句,如果您不明白为什么实现 JDBC 或 ODBC 驱动程序如此复杂和细致,通常需要整个开发团队,那么您应该感到幸运。)

图 2.6:通过实现 Arrow FlightSQL API,InfluxDB 3.0 可以访问预先存在的客户端接口,例如 JDBC,而无需创建和维护这些驱动程序。
Parquet
除了 Arrow 用于快速随机访问以进行内存处理外,InfluxDB 3.0 还需要以节省空间(经济)的方式存储大量时间序列数据。存储格式还必须支持非常快速的查询。虽然第一代时间序列数据库(如 Gorilla、Monarch 和 InfluxDB 1.x)以专门为时间序列定制的格式存储时间序列数据,但 InfluxDB 3.0 而是使用更通用的 Apache Parquet。在我们的测试中,Parquet 实际上提供了比更专业的时间序列文件格式高 5 倍的压缩率1(一旦考虑到所有索引结构),非常快的查询性能,以及与大量支持 Parquet 文件的工具(如 Pandas、DuckDB、Spark 和 Snowflake)的即时互操作性。
Parquet 是一种开放的、面向列的数据文件格式,深受列式存储学术研究的影响。该格式通过 Dremel 风格的记录切分、嵌入式模式描述和区域地图式元数据(统计信息和 Bloom 过滤器)提供了出色的数据编码和压缩、高效的结构化类型。如果您不知道这些术语的含义,这既没关系,也是关键点之一。通过使用 Parquet,您可以获得这些功能的好处,而无需数据库博士学位或多年的学习来重新发现和重新实施所需的技术。
我确信,通过足够的聪明才智和工程投入,用于时间序列(和其他数据类型)的专用格式可以实现比 Parquet 稍好的压缩和性能。然而,在实践中,我预测高度优化的 Parquet 实现的存在和 Parquet 文件的广泛采用将使专用格式降级为小众应用程序,就像 JPEG2000 的遭遇一样。
DataFusion
InfluxDB 3.0 需要快速接受数据并使其可读,并允许通过查询访问该数据。摄取路径对时间序列用例有高度专业化的要求,但查询路径看起来更像其他 OLAP 系统,需要支持 SQL 和受 SQL 启发的 InfluxQL(我们为时间序列构建的语言)、谓词分析以识别每个查询所需的时间范围,以及流式向量化执行引擎。根据我个人在其他几个数据库上工作的经验,完全理解此类引擎所需的功能范围,更不用说实施和维护,需要以 10 人年为单位来衡量的精力。在投入类似数量级的人力来实施 InfluxDB 1.x 和 Flux 语言之后,InfluxData 也意识到了这一点。
我们没有自己构建另一个引擎,而是选择基于 Apache Arrow DataFusion 构建,这是一个用 Rust 编写的模块化、最先进的分析查询引擎,它使用 Apache Arrow 作为其内存模型。仅需几行代码,Paul 就验证了 DataFusion 可以使用 SQL 快速查询时间序列数据。然后,我们构建了一个 InfluxQL 前端、用于后期到达解决(“去重”)的自定义运算符、时间序列间隙填充,最初编写 Parquet 文件,并在 DataFusion 之上使用其扩展点将多个文件合并在一起。在我们的云环境中,我们还能够使用相同的引擎为 Flux 语言提供支持。

图 3:InfluxDB 3.0 中的查询处理使用 DataFusion 通过三个不同的语言前端(内部 gRPC API、SQL 和 InfluxQL)查询数据,以及写入和合并 Parquet 文件(“重组”)。
就像 Arrow 一样,随着 InfluxData 和社区中的其他人对 DataFusion 的投入,其能力也在增长,远远超过我们任何一个人独自希望实现的水平。DataFusion 现在几乎具有您可能希望在现代 OLAP 引擎中看到的所有流行语,例如流式向量化执行、投影和选择/过滤器下推、自动并行化、资源管理、查询优化、子查询、连接、多阶段分组、Python 绑定等等。DataFusion 中的任何特定功能都不是“新的”;相反,创新在于如何将它们打包以进行重用,我们希望在未来的论文中更全面地解释这一点。
FDAP 堆栈的优势
冒着听起来重复的风险,以下是 InfluxDB 3.0 通过使用 FDAP 堆栈构建获得的优势。我坚信其他系统设计人员可以使用相同的堆栈来实现这些优势。
专注于重要事项:通过基于 FDAP 构建,InfluxData 3.0 团队可以将精力集中在特定于时间序列的功能上,例如摄取性能、InfluxQL、分布式操作和部署以及极低延迟的最新数据查询,而不是低级别、复杂的必备 OLAP 技术。
集成和互操作性:由于 InfluxDB 3.0 使用开放标准作为其本机数据表示,因此集成几乎变得微不足道。InfluxDB 3.0 没有系统到系统集成的 N 对 N 爆炸式增长,而是通过使用 Arrow FlightSQL “免费”获得 JDBC 支持,具有非常简单但功能齐全的本机 Python 和 Golang 客户端,以及可以立即被任何接受 Arrow 的东西(如 Pandas 或 Spark)使用的查询结果。由于 InfluxDB 以本机方式将数据存储为 Parquet 文件,因此其他系统(如 Snowflake 或 Presto)无需创建或维护复杂的 ETL/数据管道即可查询它。

图 4:FDAP 的开放数据格式提供了与各种现有产品和技术的即时互操作性。
放大的投资:FDAP 堆栈背后的技术非常复杂,只有少数人具备开发和维护它的技能和时间。通过与 Apache 软件基金会下具有相同需求的其他项目联合起来,开源开发模型允许来自世界各地的大量开发人员共同致力于 Flight、Arrow、DataFusion 和 Parquet。有趣的是,我花了将近四年的时间研究 SQL JOIN 的细微之处,以便 Vertica 能够有效地计划和运行它们。通过基于 FDAP 堆栈构建,InfluxDB 3.0 几乎“免费”获得了 SQL JOIN2。
可预测的开放标准:除了共享投资的好处外,在 Apache 软件基金会内工作意味着 InfluxDB 3.0 是基于具有良好理解、可预测的决策的项目构建的,不受中期 许可证更改、单个维护者倦怠或其他可能困扰其他类似开源项目的不确定性来源的影响。
FDAP 的实际应用
除了 InfluxDB 3.0 之外,我们还知道有几个其他系统在生产中使用了此架构,包括
- CeresDB:分布式、云原生时间序列数据库。
- Coralogix:全栈可观测性平台
- Greptime:云原生时间序列数据库
- Synnada:统一的流式处理和分析平台
- OpenObserve:专门为日志、指标和跟踪构建的可观测性平台
- Dremio:数据即服务平台
(旁注:如果这些其他项目能够更详细地描述他们如何使用 FDAP 堆栈的组件以及他们对这样做的好处的看法,那将非常有趣。)
相关工作
FDAP 技术的出现归功于数据库系统研究中首次发表的思想,以及实施多波商业和开源系统的集体经验。第一波浪潮始于 2000 年代初期,以 Vertica 和 Vectorwise 等系统为例。这些概念随后被 Hadoop 基础系统(如 Impala 和 Hive)改进、重新实施和部分标准化。最后,它们在当代系统(如 Spark、Snowflake 和 DuckDB)中再次重新实施,巩固了对通用结构的理解。
我相信 FDAP 堆栈将在支撑下一代数据系统中发挥与 LAMP 堆栈在支撑第一代 Web 应用程序开发中发挥的相同作用。LAMP 堆栈易于组合、性能快速和共享的开放式开发的结合,使早期的 Web 应用程序开发人员能够专注于应用程序逻辑,而不是后端服务器、状态管理和处理 http 请求的细节(还有人记得实现 cgi-bin 接口有多有趣吗?)。
展望未来
Paul 和我并不是唯一撰写关于数据系统可组合性转变的文章的人。值得注意的最新著作包括 Voltron Data 的 Composable Codex 和 The Composable Data Management System Manifesto,这两者都雄辩地表达了可组合性的价值,并且更加详细。
虽然 DataFusion 是用 Rust 编写的,因此最容易集成到也用 Rust 编写的项目中,但其他语言也存在类似的工具。Apache Calcite 是一个基于 Java 的项目,用于 SQL 规划和优化,而 Velox Execution 引擎提供了一个原生的流式处理、向量化 C/C++ 引擎。我们预测,对于不同的语言,将会出现类似于 DataFusion 的其他项目,尽管也许 DataFusion 语言绑定就足够了。此外,DataFusion 和类似的项目本身也可能在内部进行组件化,因为新的开放标准(如 Substrait)日趋成熟,并为互操作性定义了新的边界。
结论
除非您拥有无限的资源和/或极其专业的用例,否则我认为您很难实现任何接近 FDAP 提供的水平的东西。我预测,随着越来越多的人也得出这个结论,我们将看到基于 FDAP 堆栈构建的新一波系统,我个人迫不及待地想看看会出现什么。
要参与各种 FDAP 技术,请访问:https://arrow.apache.ac.cn/ https://parquet.apache.org/ https://arrow.apache.ac.cn/datafusion/
想看看这些技术组合起来能做什么?查看新的 InfluxDB。
致谢
感谢 Evan Kaplan 提议这篇文章并鼓励我撰写它。还要非常感谢 Jason Myers 和 Charles Mahler 帮助起草和完善本文,以及 Paul Dix 和 Nga Tran 审阅了早期草稿并提供了宝贵的反馈。
