时间序列数据库详解
在这篇技术论文中,InfluxData 首席技术官 Paul Dix 将带您了解什么是时间序列(以及不是什么)、它与流处理、全文搜索和其他解决方案的不同之处。

通过阅读这篇技术论文,您将
- 了解时间序列数据如何在我们周围存在,
- 了解为什么专用的 TSDB 很重要。
- 阅读有关时间序列数据库如何针对带时间戳的数据进行优化的信息。
- 了解指标、事件和追踪之间的差异,以及时间序列数据的一些关键特征。
目录
什么是时间序列数据库?
时间序列数据库 (TSDB) 是一个为带时间戳或时间序列数据优化的数据库。时间序列数据只是随时间跟踪、监控、降采样和聚合的测量值或事件。这可能是服务器指标、应用程序性能监控、网络数据、传感器数据、事件、点击、市场交易以及许多其他类型的分析数据。
时间序列数据库专门用于处理带时间戳的指标和事件或测量值。TSDB 针对测量随时间的变化进行了优化。使时间序列数据与其他数据工作负载非常不同的属性是数据生命周期管理、汇总以及大量记录的大范围扫描。
为什么时间序列数据库现在如此重要?
时间序列数据库并非新生事物,但第一代时间序列数据库主要侧重于查看金融数据、股票交易的波动性以及为解决交易而构建的系统。但金融数据几乎不再是时间序列数据的应用的唯一领域——事实上,它只是各个行业众多应用之一。在过去十年中,计算的基本条件发生了巨大变化。一切都变得模块化。单体大型机已经消失,取而代之的是无服务器服务器、微服务器和容器。
今天,任何可以成为组件的东西都是组件。此外,我们正在目睹物质世界中每个可用表面的仪器化——街道、汽车、工厂、电网、冰盖、卫星、服装、电话、微波炉、牛奶容器、行星、人体。一切都有或将有传感器。因此,现在公司内外的一切都在不断发出指标和事件流或时间序列数据。
想了解更多?
下载论文
这意味着底层平台需要发展以支持这些新的工作负载——更多数据点、更多数据源、更多监控、更多控制。我们正在目睹的以及时代的需求是对我们如何处理数据基础设施以及如何构建、监控、控制和管理系统进行范式转变。我们需要的是一个高性能、可扩展、专用的时间序列数据库。
时间序列工作负载的特点是什么?
时间序列数据库具有关键的架构设计属性,使其与其他数据库截然不同。这些属性包括时间戳数据存储和压缩、数据生命周期管理、数据汇总、处理许多记录的大型时间序列相关扫描的能力以及时间序列感知查询。
例如: 使用时间序列数据库,通常需要请求较长时间段内的数据摘要。这需要遍历一系列数据点以执行一些计算,例如本月指标相对于过去六个月同一时期的百分位数增长,按月汇总。这种类型的工作负载很难使用分布式键值存储进行优化。TSDB 针对此用例进行了优化,可在数月的数据中提供毫秒级的查询时间。另一个例子:使用时间序列数据库,通常会将高精度数据保留一小段时间。此数据被聚合和降采样为长期趋势数据。这意味着对于进入数据库的每个数据点,都必须在其时间段结束后删除。这种数据生命周期管理对于应用程序开发人员来说很难在常规数据库之上实现。他们必须设计廉价地清除大量数据并不断大规模汇总数据的方案。使用时间序列数据库,此功能是开箱即用的。
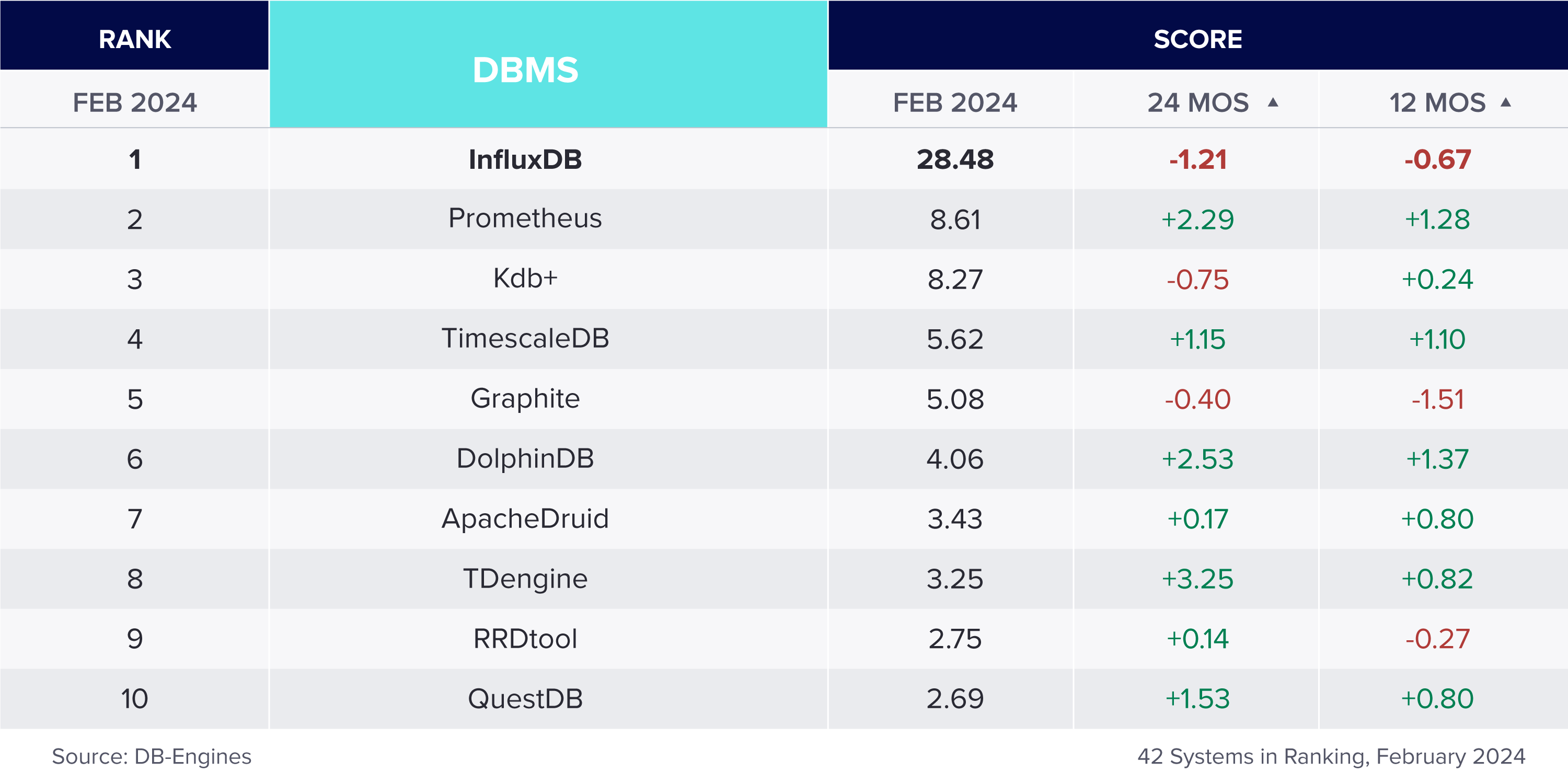
排名前 15 位的时间序列数据库的独立排名
时间序列数据库是数据库行业中增长最快的部分。但哪个时间序列数据库是最好和最受欢迎的?有许多方法可以确定受欢迎程度,但一个独立的网站 DB-Engines 根据搜索引擎受欢迎程度、社交媒体提及、职位发布和技术讨论量对数据库进行排名。(阅读他们的完整方法)。以下是当前结果
为了查看随时间变化的趋势,下图显示了前 10 名时间序列数据库及其历史变化
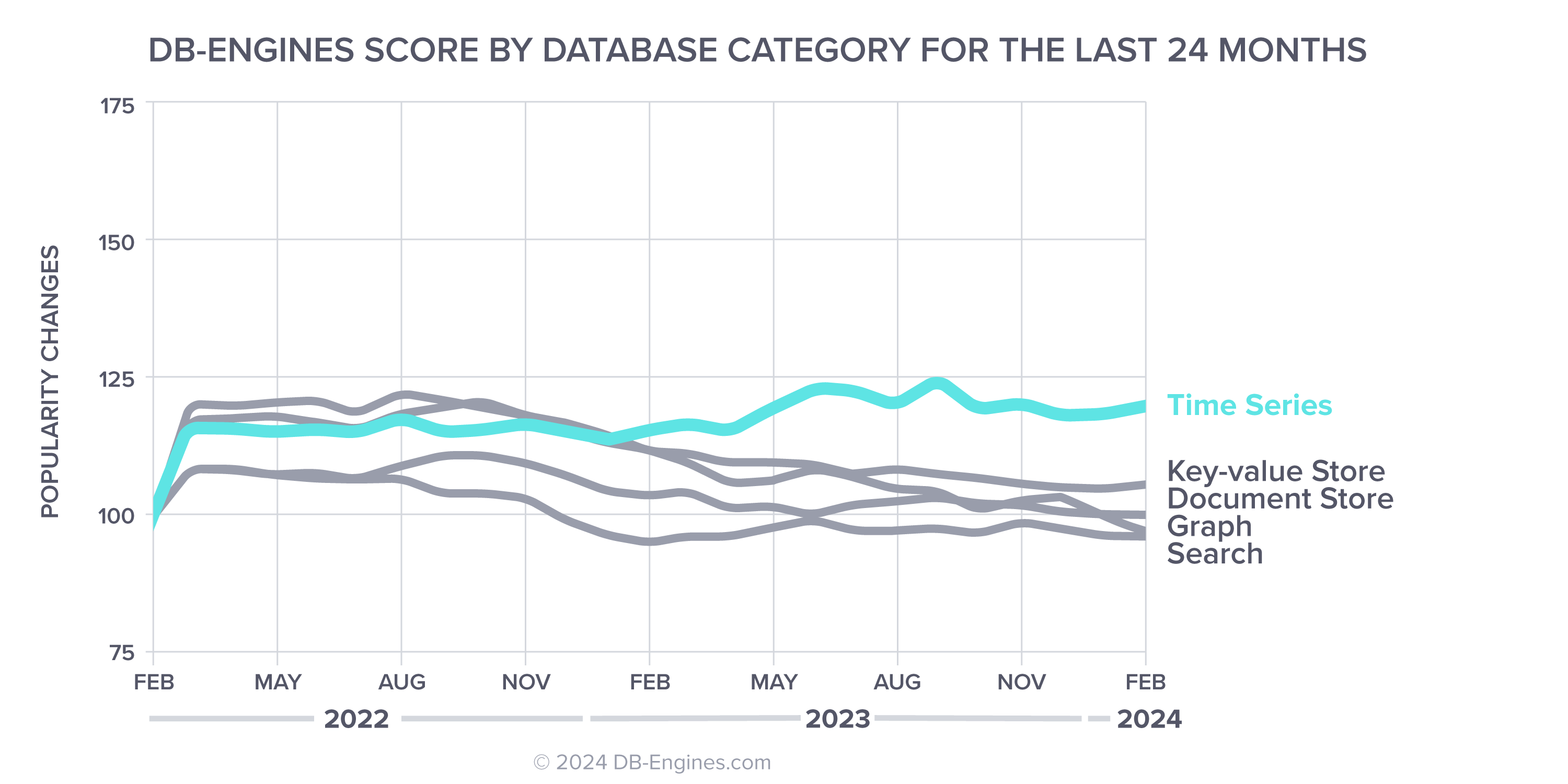
时间序列——增长最快的数据库类别
DB-Engines 还根据时间序列数据库管理系统(Time Series DBMS)的受欢迎程度对其进行排名。时间序列数据库是过去一年数据库行业中增长最快的部分。
是什么让 InfluxDB 时间序列数据库如此独特?
InfluxDB 从头开始构建,成为一个专用的时间序列数据库;即,它不是被重新用于时间序列。时间从一开始就内置在其中。InfluxDB 是一个综合平台的一部分,该平台支持时间序列数据的收集、存储、监控、可视化和警报。它不仅仅是一个时间序列数据库。
整个 InfluxData 平台都构建于一个开源数据库核心之上。InfluxData 是 Telegraf、 InfluxDB、 Chronograf 和 Kapacitor (TICK) 项目 的积极贡献者——TICK Stack 中的 “I,C,K” 正在 InfluxDB 2.0 中被折叠成一个二进制文件——以及销售基于此开源核心的 InfluxDB Enterprise 和 InfluxDB Cloud。InfluxDB 数据模型与其他时间序列解决方案(如 Graphite、RRD 或 OpenTSDB)截然不同。InfluxDB 具有用于发送时间序列数据的行协议,其格式如下:measurement-name tag-set field-set timestamp。测量名称是一个字符串,标签集是键/值对的集合,其中所有值都是字符串,字段集是键/值对的集合,其中值可以是 int64、float64、bool 或字符串。测量名称和标签集保存在倒排索引中,这使得特定系列的查找非常快速。例如,如果我们有 CPU 指标
cpu,host=serverA,region=uswest idle=23,user=42,system=12 1464623548sInfluxDB 中的时间戳可以是秒、毫秒、微秒或纳秒精度。微秒和纳秒级精度使 InfluxDB 成为金融和科学计算用例的不错选择,而其他解决方案将被排除在外。压缩是可变的,具体取决于用户需要的精度级别。在磁盘上,数据以列式格式组织,其中为测量、标签集、字段设置了连续的时间块。因此,每个字段在磁盘上按时间块顺序组织,这使得对单个字段计算聚合非常快速。可以使用的标签和字段数量没有限制。
其他时间序列解决方案不支持多个字段,这会在传输具有共享标签集的数据时使它们的网络协议变得臃肿。大多数其他时间序列解决方案仅支持 float64 值,这意味着用户无法在时间序列中编码额外的元数据。即使是支持标签的 OpenTSDB 和 KairosDB(与 Graphite 和 RRD 不同),也对可以使用的标签数量有限制。在大约 5 到 6 个标签时,用户将开始在其 HBase 或 Cassandra 机器集群中看到热点。
InfluxDB 没有此限制,因为 InfluxDB 数据模型专为时间序列而设计。它将开发人员推向正确的方向,通过索引标签并保持字段未索引来获得数据库的良好性能。它很灵活,因为它支持多种数据类型,并且用户可以拥有许多字段和标签。由于所有这些因素,像 InfluxDB 这样的专用时间序列数据库是处理时间序列数据的最佳解决方案。
时间序列数据库:常见问题解答
下面列出的是关于时间序列数据库的常见问题的简短解答,供快速参考
什么是时间序列数据库?
以下是时间序列数据库的简要定义:时间序列数据库 (TSDB) 是一个为带时间戳(时间序列)数据以及测量随时间变化而优化的数据库。
哪个时间序列数据库是最好的?
访问此页面以了解是什么使时间序列数据库功能强大,以及哪个数据库最适合存储大量时间序列数据。
时间序列数据示例有哪些?
访问什么是时间序列数据页面以查看时间序列数据示例。
InfluxDB 是开源的吗?
InfluxDB 是一个开源时间序列数据库,拥有庞大而活跃的社区。
我可以将 InfluxDB 与 Grafana 一起使用吗?
有数千个使用 InfluxDB 和 Grafana 的用例。访问我们的社区展示以了解它们。
InfluxDB 与其他数据库相比如何?
查看InfluxDB 基准测试,将其性能与其他数据库(如 Cassandra、Elasticsearch、MongoDB、OpenTSDB、Graphite 和 Splunk)进行比较,基于写入吞吐量、查询吞吐量和磁盘存储等参数。
对于处理时间序列数据,时间序列数据库是否比关系数据库更好?
如果您正在争论时间序列数据库与关系数据库,则时间序列数据库 (TSDB) 专门用于排序和查询时间序列数据,并且往往比更通用的关系数据库更有效。
我可以使用时间序列数据库进行边缘计算吗?
以可靠的方式将数据从边缘传输到云端仍然是许多企业面临的挑战。阅读InfluxDB 边缘计算和数据复制电子书,了解什么是“边缘”,边缘计算用例和优势,以及如何将 InfluxDB 时间序列数据库用于边缘计算。
时间序列数据库和数据仓库之间有什么区别?
虽然时间序列数据库是为带时间戳或时间序列数据优化的数据库,但数据仓库在中心位置存储和组织来自多个来源的数据。
关于其他数据库类型的资源
下载本技术论文
排名第一的时间序列数据库
根据 DB Engines
加入数百万开发者的行列,使用 InfluxDB 实时预测、响应和适应。

