Quix
Quix 由一级方程式工程师创立,使 Python 流处理时间序列数据变得简单。它允许开发人员从任何来源摄取数据并写入任何目标,利用 Python 生态系统来减少、丰富和转换他们的数据。
用于时间序列数据的数据处理引擎
Quix 和 InfluxData
Quix 直接与 Influx 集成,作为源或接收器—为希望利用流处理来满足其用例的 InfluxDB 3.x 或 2.x 用户充当 ETL 引擎。Quix 以 Kafka 作为平台的数据骨干,使用户能够将数据直接流式传输到 InfluxDB 作为其时间序列数据存储,通过为实时应用程序提供支持或在存储数据之前对其进行预处理,从而利用其规模和性能。
源、转换和接收器。Quix Streams DataFrame 接口使用户能够使用 Python 处理其数据。通过结合这两种技术,数据团队可以构建基于任务的引擎、降采样功能、可扩展的时间序列数据警报管道以及用于时间序列预测的 ML 部署。
在 Quix 中,您可以在 InfluxDB 的版本之间迁移(2.x -> 3.x)。Quix 类似于 2.x 中的 Flux 任务,这使得 InfluxDB 客户可以更轻松地迁移到 3.x 并将其 Flux 任务转换为 Quix 中的 Python 服务。
如何开始使用 Quix 和 InfluxDB
Quix 打包可在任何云或本地环境运行,无服务器云可用于免费试用。只需创建一个帐户并设置您的 InfluxDB 版本所需的源或接收器连接器。从那里,您可以创建一个实时数据处理引擎。
步骤
- 创建一个免费的 Quix 帐户。
- 配置和部署 InfluxDB 源连接器以摄取数据,或使用 Telegraf 将数据导入 Quix。
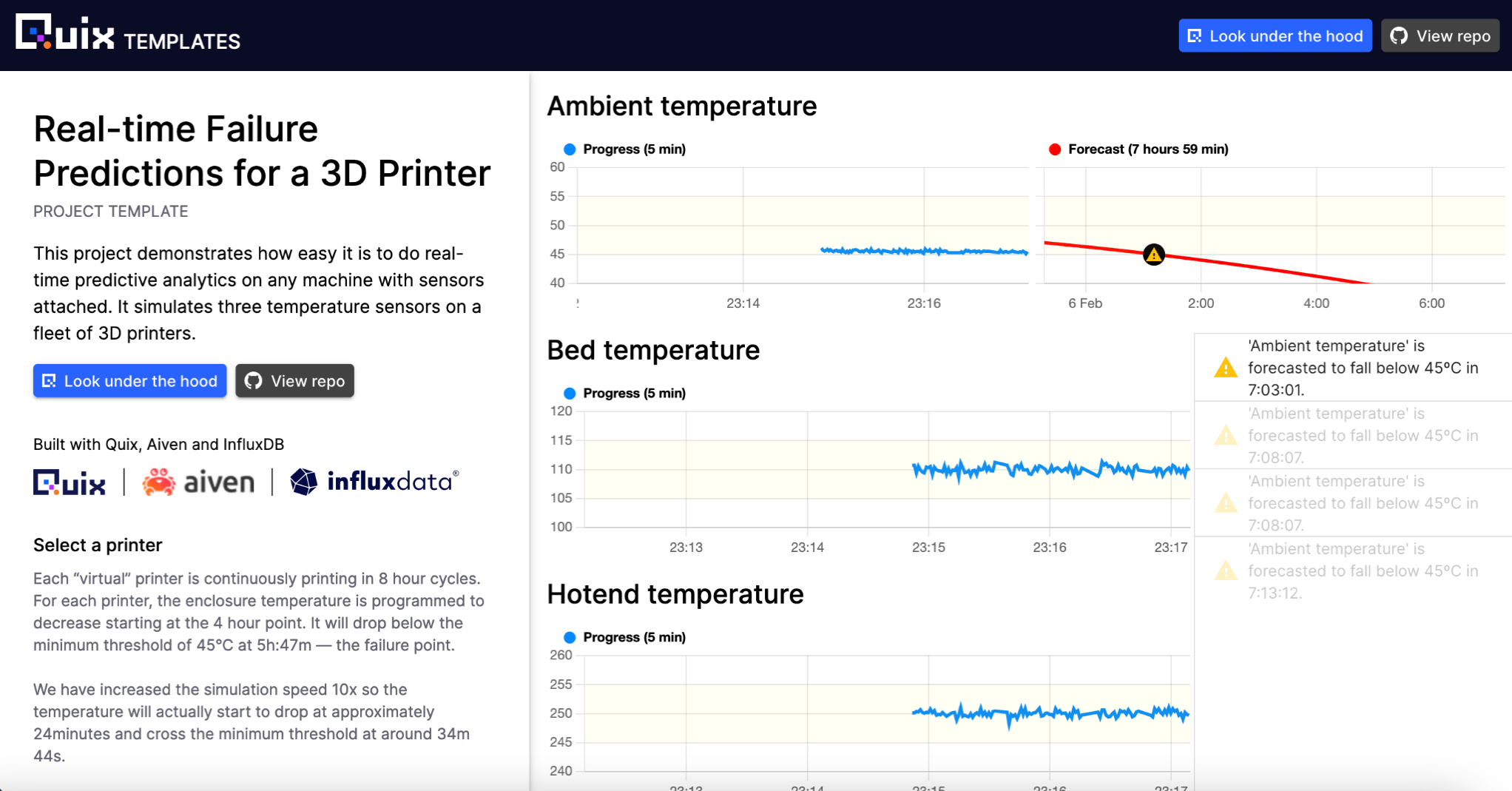
- 从 Quix 示例库添加转换,开始使用您的代码处理数据。查看此预测性维护项目以获取灵感。
主要资源
- 网络研讨会:使用 Python、Quix 和 InfluxDB 简化流处理
- 文档:Quix 和 InfluxDB 入门指南
- 联系 Quix 讨论您的项目:联系表单
- InfluxDB 博客:使用 Quix 构建您自己的流任务引擎
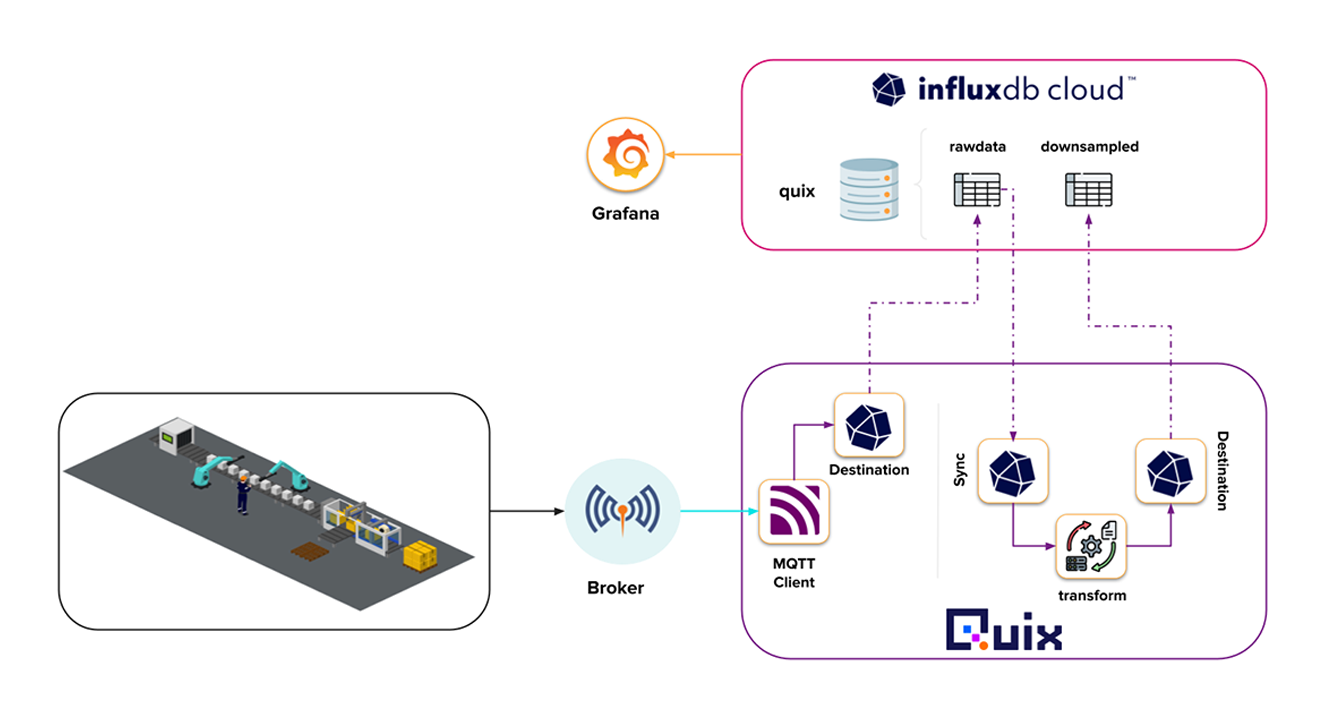
Quix 和 Influx 架构示例图
下一步是什么?
有问题?获取答案
