WP Engine 使用 InfluxDB 为全球可观测性提供支持
作者:Jason Myers / 产品、 用例、 开发者
2022 年 4 月 7 日
导航到
WP Engine 平台为品牌提供所需的解决方案,以便在 WordPress 上创建卓越的网站和应用程序,从而更快地推动业务发展。它托管超过 150 万个网站,为 150 多个不同国家的超过 175,000 个客户提供服务,并且每天处理 52 亿个请求。总而言之,WP Engine 的足迹约占整个网络的 8%。
寻求可靠性
考虑到这些统计数据,您可以想象当公司发生中断并且其监控解决方案同时宕机时会发生什么。WP Engine 过去常常以运行生产中最大的 Zabbix 监控实例之一而自豪,该实例监控由单个 Zabbix 数据库支持的 15,000 台主机。在中断期间,单个数据库服务器是其监控的关键故障点。
为了解决这个问题,WP Engine 开发者开始寻找替代方案。他们需要能够处理其全球范围内数据需求规模的产品。这意味着一个至少支持每分钟 500 万次查询并在每六分钟触发警报的解决方案。他们考虑过 Datadog 作为一种统包解决方案,但对于他们的业务来说成本过高。
构建自定义可观测性平台
WP Engine 构建了一个多层指标平台。最外层,即 Fleet 层,是 WP Engine 的 15,000 台主机所在的位置,分布在各种服务和云提供商之间。WP Engine 考虑过 Fluentd 用于此层中的数据收集,但选择了 Telegraf,因为它使用的资源更少并且拥有大型插件库。WP Engine 收集服务器和容器级别的 CPU 和内存利用率、服务器响应时间、磁盘利用率等指标。
收集的数据然后进入 Kubernetes 上运行的聚合层,在该层中,数据被清理和过滤。清理后的数据然后进入警报层,其中 Kapacitor 和 InfluxDB OSS 的组合处理警报。此层将警报发送到各种端点,例如 Slack、PagerDuty 和 Amazon SNS。Kapacitor 还配置为将信号发送回 Fleet 层,以执行不需要人工干预的自动任务。
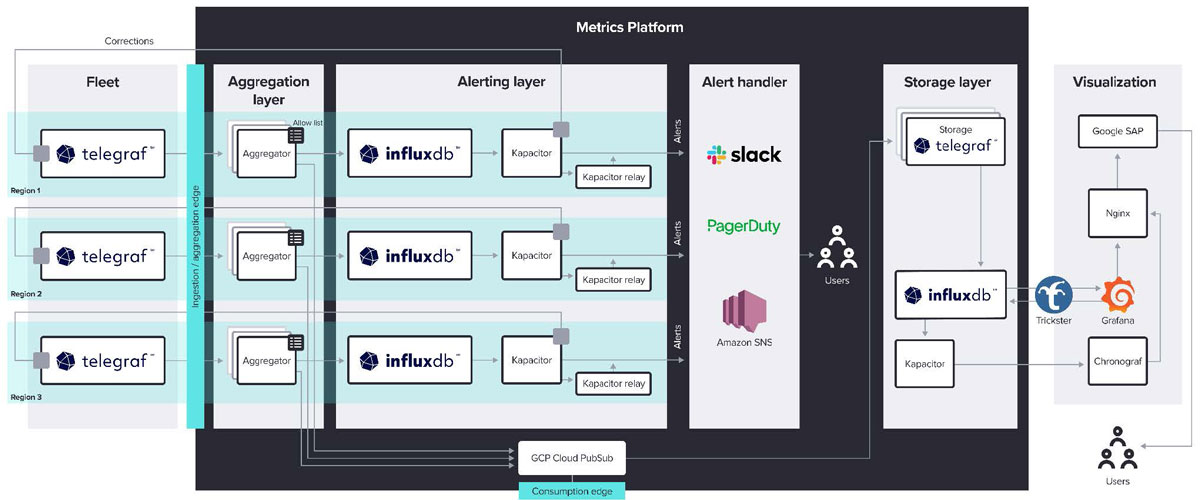
从聚合层开始,指标通过 Google Pub/Sub 移动到存储层,WP Engine 在存储层中运行六个 InfluxDB Enterprise 节点。来自此中央时间序列存储库的数据也为可视化层提供数据。WP Engine 使用 Chronograf 和 Grafana 为内部用户构建仪表板。
结果
使用这个新系统,WP Engine 创建了一个满足当前需求并有能力与公司一同成长的解决方案。该公司消除了旧解决方案中存在的单点故障问题。它还在 InfluxDB Enterprise 的互连性和冗余方面进行了投资。WP Engine 指标平台每分钟摄取 500 万个点,是旧系统指标的 20 倍,并将这些数据存储在多个位置。WP Engine 周到地迁移到他们的新警报系统,并将人工认知负担减少了一半。
