我的点发生了什么?
作者:Roger Peppe / 产品, 用例, 开发者
2022年1月27日
导航至
本文探讨了在写入 InfluxDB 时可能拒绝无效数据的一些方法,并介绍了一项新功能,该功能可以更轻松地了解何时以及为何发生这种情况。
语法出错
让我们使用命令行 influx 工具向 InfluxDB Cloud 写入一些数据
% echo '
humidity,location=greenhouse value=85
temperature, location=house value=23
temperature, location=greenhouse value=10
' | influx write
Error: failed to write data: 400 Bad Request: partial write error (1 accepted): 2/3 points rejected; first error: at line 3:13: expected tag key after comma; got white space instead (check rejected_points in your _monitoring bucket for further information)糟糕,看起来我们出错了!幸运的是,尽管错误消息有点吓人地长,但它告诉了我们很多关于发生了什么的信息。让我们把它分成几个部分
错误:写入数据失败:400 Bad Request
这告诉我们,该错误是从服务器返回的,作为对发送到写入数据的 HTTP 请求的响应,并且问题是客户端的错误,而不是服务器端出现的问题。
部分写入错误(1 个已接受):2/3 个点被拒绝
这告诉我们,并非*所有*数据都是错误的。InfluxDB Cloud 尝试尽可能多地接受您的数据。这里,其中一个点是正常的,但另外两个点有问题。
首个错误
可以在单个写入操作中发送数千个点。与其可能返回数千个错误消息,它只返回第一个错误消息。
在第 3:13 行
这告诉我们问题在输入中的位置:第 3 行第 13 列。这指向 `my_point` 后逗号后的空格。
逗号后应为标签键;但得到的是空格
我们在第一个逗号后有一个空格,因此它不是有效的语法。(如果您问自己,到底什么是有效的行协议语法,那么您来对地方了:请参阅本文后面的详细信息)。
(查看您的 _monitoring bucket 中的 rejected_points 以获取更多信息)
错误消息的最后一部分引起您对一项新功能的注意:当点被拒绝时,有关拒绝的信息将写入您组织的 `_monitoring` bucket 中的 `rejected_points` measurement 下。写入的信息将包括有关*所有*被拒绝点的信息,而不仅仅是第一个。
在下一节中,我们将更详细地研究这一点。
监控被拒绝的点
在上一节中,我们看到了 `write` 端点如何返回它遇到的第一个语法错误的信息。它还会将一些信息写入您的 `_monitoring` bucket,描述遇到的所有错误。
在上面的示例中,它写入了以下数据
rejected_points,bucket=6355a1b5287f84c2,reason=parse\ error count=1,error="at line 3:13: expected tag key after comma; got white space instead"
rejected_points,bucket=6355a1b5287f84c2,reason=parse\ error count=1,error="at line 4:13: expected tag key after comma; got white space instead"bucket 是正在写入的 bucket 的十六进制 ID(您可以通过在 Cloud 2 UI 中的“加载数据”选项卡中查找您的 bucket 来找到它)。`reason` 标签提供了点被拒绝的一般原因。`error` 字段提供了您之前看到的语法错误——我们可以看到现在有两个错误,每行一个。`count` 字段可用于轻松地跨时间汇总被拒绝点的数量。
与写入 `_monitoring` bucket 的所有数据一样,此数据将[保留七天](https://docs.influxdb.org.cn/influxdb/cloud/reference/internals/system-buckets/)。
将拒绝点信息存储在普通 bucket 中,可以轻松使用所有常用的 Influx 工具来跟踪这种情况发生的频率。如果存在错误的客户端,您将可以在那里看到它。
传输中丢失
当写入行协议数据时,API 会检查语法有效性,这就是为什么 influx 客户端能够打印上面的语法错误,但并非所有错误都会立即检查。当一个点进入 InfluxDB Cloud 时,它会被添加到持久队列中,但不会立即与数据库的其余部分集成。这是它如此高效的原因之一,但也意味着如果写入的字段具有冲突类型(例如,写入了字符串而不是浮点数),则无法将结果错误返回给客户端,因为客户端已被响应。
直到最近,这还是一个静默错误。具有冲突字段类型的点会被删除,而不会向用户发出任何指示。
但现在您*可以*像语法错误一样,通过查看 `_monitoring` bucket 来了解这些错误。
让我们试试看。在这里,我们将写入几个点,它们的字符串字段 `value` 是我们之前写入浮点数的地方
% echo '
humidity,location=greenhouse value="bad1"
humidity,location=greenhouse value="bad2"
humidity,location=greenhouse value=94
' | influx write
%写入似乎成功了。但是,如果我们查看 `_monitoring` bucket,我们会看到出现了以下条目
rejected_points,bucket=6355a1b5287f84c2,field=value,gotType=String,measurement=humidity,reason=type\ conflict\ with\ existing\ data,wantType=Float count=2
rejected_points,bucket=6355a1b5287f84c2,field=value,gotType=Float,measurement=humidity,reason=type\ conflict\ in\ batch\ write,wantType=String count=1这告诉我们,由于 `value` 字段的现有数据存在类型冲突,因此从具有 humidity measurement 的 bucket 中拒绝了两个点(`count=2`)。另一个点被拒绝是因为其字段类型与同一批次中的其他点冲突——即使该点(写入中的第三个点)在技术上对于 bucket 具有正确的类型,但单个写入中点的类型必须与当前存储的内容无关地保持一致,因此在最终类型检查之前被拒绝。
请注意,`location=greenhouse` 标签未出现在被拒绝的点信息中。只有字段和 measurement 出现。这样做的原因是控制 `rejected_point` measurement 的基数——我们不希望被拒绝的点最终使用的基数与数据已存储时一样多!
绘制图表
在本节中,我将描述我们发现有用的几个查询,用于跟踪被拒绝的点。您可以将这些用作您自己的仪表板的基础。
我们可以通过这样的查询来了解随着时间推移发生的被拒绝点的总数
from(bucket: "_monitoring")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "rejected_points")
|> filter(fn: (r) => r._field == "count")
|> group()
|> aggregateWindow(every: v.windowPeriod, fn: sum, createEmpty: false)
|> yield(name: "rejected points by reason")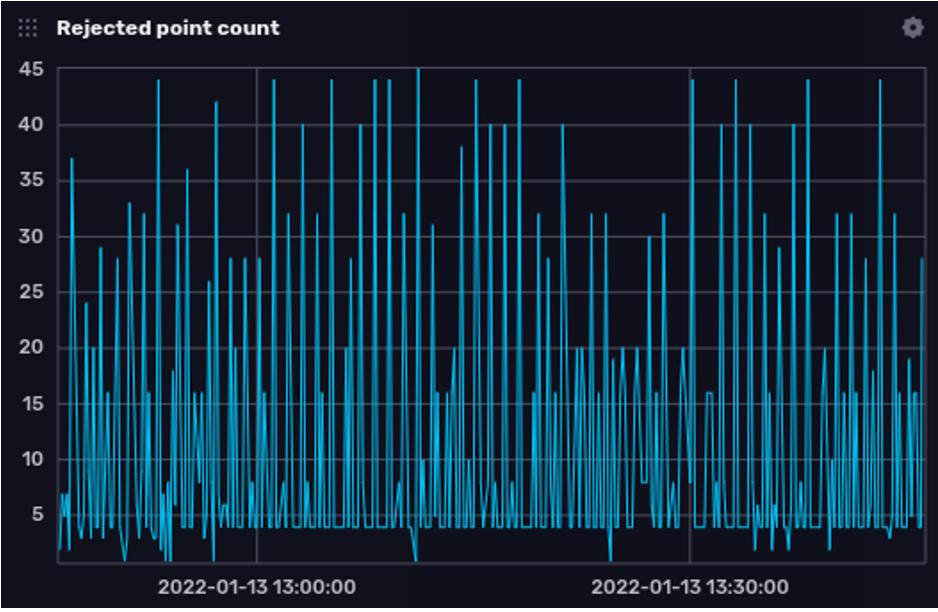
为了深入了解上面图表中突出显示的根本原因,这是一个总结点被拒绝原因的查询
from(bucket: "_monitoring")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "rejected_points")
|> filter(fn: (r) => r._field == "count")
|> keep(columns: ["reason", "_value"])
|> group(columns: ["reason"])
|> sum()
|> rename(columns: {"_value": "count"})
|> group()
|> yield(name: "reasons")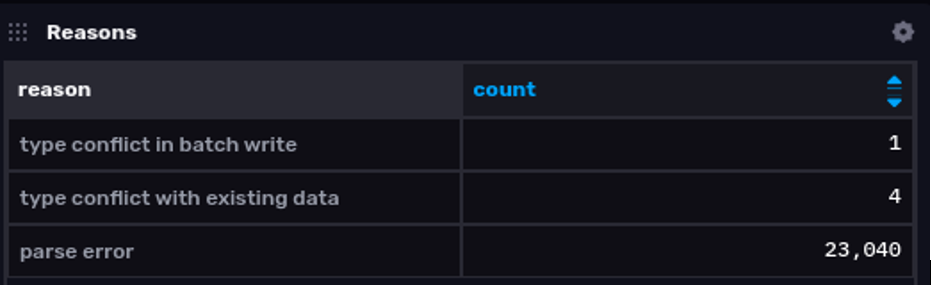
行协议语法定义
行协议格式的语法是什么?表面上看起来很简单,但细节决定成败,直到最近,答案还是“实现说了算”,因为语法没有精确定义。我们有[语法参考](https://docs.influxdb.org.cn/influxdb/cloud/reference/syntax/line-protocol/),现在我们很高兴能够分享新的、正式的[行协议定义文档](https://docs.google.com/document/d/1uS_vba0K5CVFIz-nE2j9YFlhXknGzqf0b98fFBxlQRA/edit)。我们编写此文档以及新的行协议解析代码,力求准确且尽可能消除歧义。
先前不同实现或文档存在分歧的领域的一些值得注意的澄清
- 只有 ASCII 空格字符和可选的最终回车符才算作空白。具体来说,制表符和换页符是不允许的,除非在字符串字段值中。
- 字符串字段值中允许使用文字换行符。
- 所有行协议数据必须编码为有效的 UTF-8。
- Measurements、标签键、标签值和字段键不得包含不可打印的 ASCII 字符(代码点 0-31 和 127)。
有一个新的 Go 参考实现实现了新语法:[github.com/influxdata/line-protocol/v2/lineprotocol](https://pkg.go.dev/github.com/influxdata/line-protocol/v2/lineprotocol) 以及一个 GitHub 存储库,其中包含大量示例及其预期结果:[https://github.com/influxdata/line-protocol-corpus](https://github.com/influxdata/line-protocol-corpus)
