网络研讨会回顾:InfluxDB Clustered 新品发布
作者:Jessica Wachtel / 开发者, 产品
2023 年 10 月 09 日
导航至
时间序列数据几乎是所有应用程序和服务的基础。即使时间序列不是重点,例如在以物联网传感器数据为中心的应用程序中,它也会以指标、日志和追踪的形式出现在监控数据中。由于时间序列数据的独特特性,最好在时间序列数据库中进行处理。InfluxDB 专为处理时间序列数据的高容量和高速摄取而构建,并能大规模执行实时分析、警报和异常检测。
网络研讨会InfluxDB Clustered 新品发布 包含 InfluxDB Clustered 的深入演示以及 InfluxDB 自托管实例的技术介绍。产品营销副总裁 Balaji Palani 和高级产品经理 Gunnar Aasen 深入探讨了 InfluxDB 3.0 能够轻松处理高性能时间序列工作负载的原因。
InfluxDB 3.0
InfluxDB 构建于 Apache Arrow 内存列式格式之上。Arrow 为最新或最近查询的数据提供实时查询响应。Arrow 还提供低延迟的分析查询响应。除了内存数据存储之外,InfluxDB 还将数据作为 Apache Parquet 文件持久存储在云对象存储(例如 Amazon S3)上。Parquet 具有高比率数据压缩,使客户能够在更小的空间中保存更多数据。Parquet 的卓越压缩性能使数据存储量增加 10 倍以上,同时降低了成本。除了节省成本的优势外,客户还拥有更多所需数据来执行历史趋势分析和训练机器学习 (ML) 模型。
Parquet 是一种开放数据标准,可实现与 ML 工具和高级分析的互操作性。流行的工具(例如用于可视化的 Grafana 和用于分析的 Pandas DataFrame)可以直接使用 Parquet 文件。Parquet 的零拷贝数据共享意味着客户可以直接将数据读取到 Snowflake、数据湖或 ML 平台中或从中访问数据,而无需复制任何数据。
InfluxDB 3.0 使用 DataFusion 查询引擎,除了 InfluxQL 之外,还为 InfluxDB 3.0 带来了原生 SQL 支持。DataFusion 查询引擎的优势包括向量化执行、优化的 I/O 下推策略、优化的数据分区以及最先进的并行技术。DataFusion 针对列式分析进行了性能优化。即使跨更长的时间范围进行查询,DataFusion 也能提供快速结果。
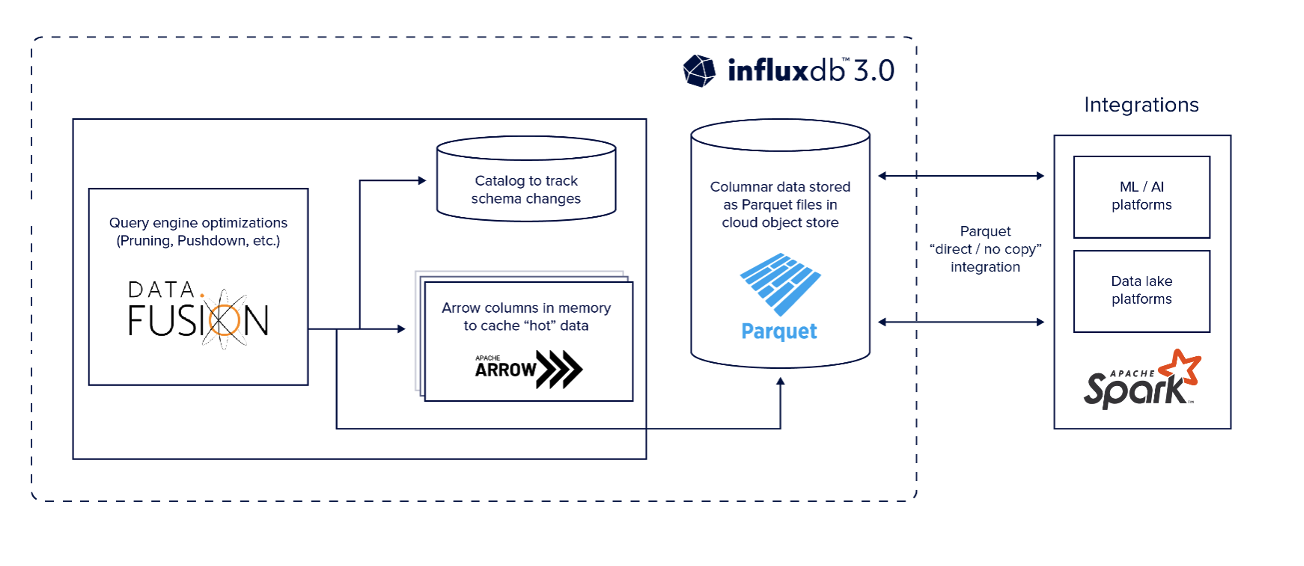 InfluxDB 3.0 架构图
InfluxDB 3.0 架构图
InfluxDB 3.0 通过支持无限基数来解锁新的用例,例如存储指标、事件和追踪。客户可以在具有大量基数(数千万甚至数亿以上)的系统上运行,而不会面临限制。查询速度提高 100 倍,包括高基数数据的查询速度提高 5 倍到 45 倍。查看我们的基准测试了解更多详情。
InfluxDB Clustered
InfluxDB Clustered 是 InfluxDB Enterprise 的下一代演进产品。Clustered 是 InfluxDB 的自托管实例,客户可以将其部署在自己的基础设施上。Clustered 是一种基于 Kubernetes 的解决方案,利用了底层的 Kubernetes 基础。我们在创建 Clustered 时考虑到了大型企业。这些组织通常寻求大规模的性能、需要更好地控制其数据和底层基础设施,并需要企业级安全性。
Clustered 客户可以微调其数据库控件,以满足其数据存储和处理的特定性能、监管或业务要求。自定义还包括环境——Clustered 将在 Kubernetes 可运行的任何地方运行。每个工作负载都可以根据其各自的标准进行调整,并针对性能、规模和/或成本进行优化。
观看网络研讨会!
InfluxDB Clustered 新品发布 对压缩和查询进行了深入的技术探讨,包括从 28:43 开始的 Clustered 产品演示以及从 52:13 开始的问答环节。问答环节包含有关压缩优化、在考虑无限基数时模式设计的最佳实践以及 Edge Data Replication 的未来等详细问题。
如果您有任何问题或想与我们的销售团队人员交谈,可以在此处联系人员。有关 InfluxDB 的更多信息,请查看我们的博客或注册免费云账户。
