使用 Flux 对您的时间序列数据进行分组、塑形和分析
作者:Nate Isley / 产品, 开发者
2019 年 7 月 29 日
导航至
Flux 是一种编程语言,从头开始为时间序列分析而设计。传统上,对大型动态时间序列数据集进行分组、塑形和执行数学运算非常繁琐。Flux 的目标是使处理这些数据集更加优雅。
InfluxDB 2 OSS Alpha 添加了几个令人兴奋的 Flux 新功能,这促使我全身心投入,看看它们在实践中如何运作。我最初的尝试很有希望,但总感觉有些不对劲。
我理解 Flux 的关键洞察
当我研究如何跨多个数据存储压缩数据时,我很快意识到我遗漏了一些基本的东西。我一直得到意想不到的答案,而且我的许多图表看起来都不对劲。
为了寻找答案,我联系了 Flux 团队的 Adam Anthony,他一步一步地引导我完成了一个更复杂的用例。几步之后,我突然明白了——我必须密切关注的关键部分是表格结果。
表格作为数据
您在 Flux 中遇到的前几个示例似乎非常简单直接。这是一个您可能会在本地 Telegraf 代理收集的系统指标上看到的典型初始查询
from(bucket:"my-bucket")
|> range(start: -10m)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_system" and r.cpu != "cpu-total" )这个 Flux 查询提取了 Telegraf 代理在过去十分钟内写入 my-bucket 的所有数据,并将其过滤为 CPU 系统使用率指标,排除 cpu-total 值。
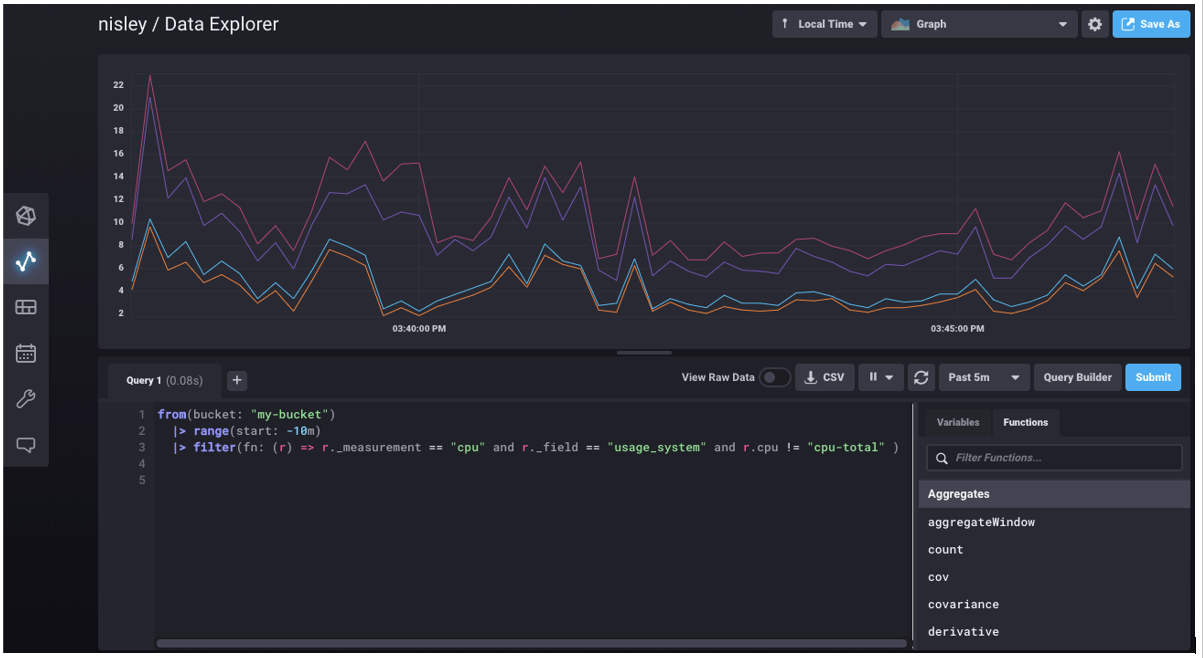
当我第一次在我的 InfluxDB Cloud 2 UI 中看到这个查询的结果时,我立即得出结论,Flux 只是返回了四个数组——每个数组都包含大量的数字。事实证明,最初的印象大错特错,并且是我在尝试解决更复杂场景时犯错的根源。
在 Adam 的指导后,我意识到使用和理解 Flux 取决于理解 Flux 结果的每个部分。Flux 结果是表格,有时,结果是一组相当广泛的表格。我了解到,在逐步进行 Flux 分析时,最有用的工具不是图形工具,而是 UI 中切换到“查看原始数据”的按钮。
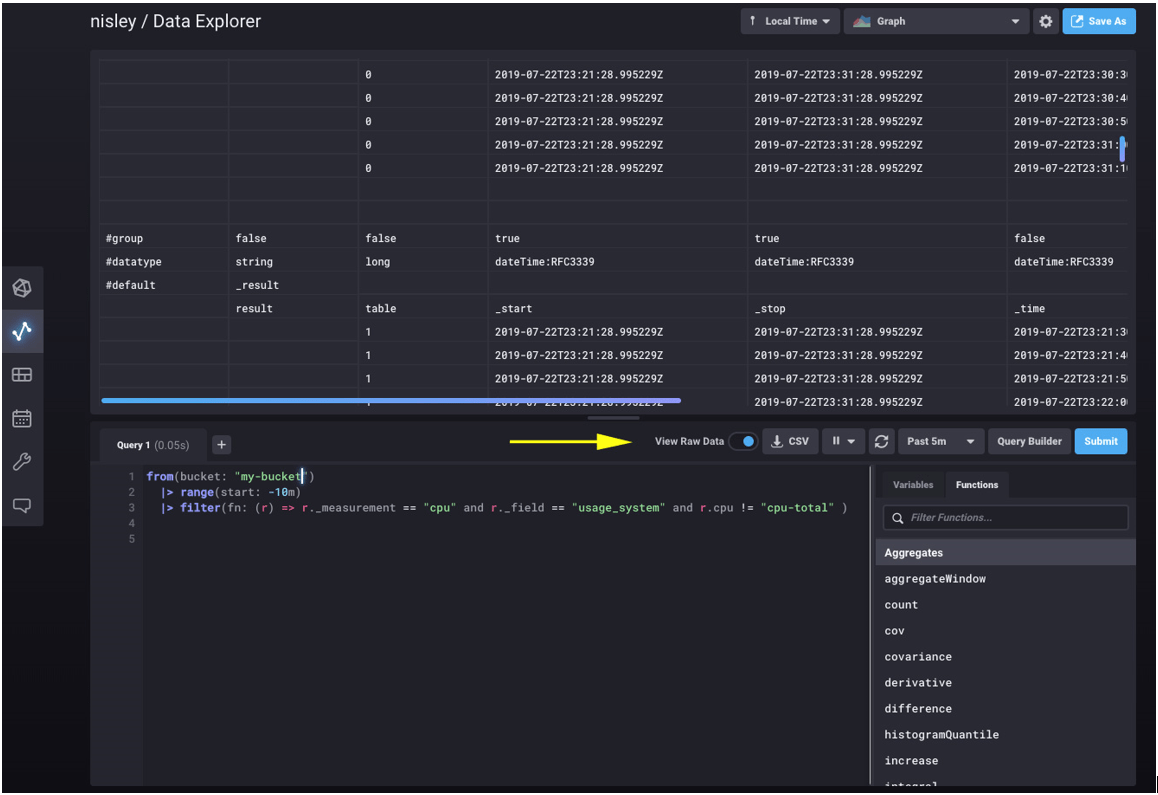
“原始视图”正是如此——来自 Flux 的完整原始输出。当我第一次查看原始视图时,我以为 UI 可能添加了标签、时间戳或扩展描述之类的东西。事实上,UI 没有对结果添加任何内容——这里的每个标签、行和列都直接来自 Flux 响应。
深入研究响应,最容易被忽略的是表格列——本例中的第 3 列。上面的 UI 滚动显示来自两个表格的数据(表格 0 和表格 1)。我们可以看到,上面的系统 CPU Flux 查询根本没有返回四个数组,而是返回了四个表格——Telegraf 正在监控的四个 CPU 中的每一个 CPU 对应一个表格。
当您操作、分析和塑造数据时,如果您始终牢记每个中间计算和结果都是表格这一事实,您会发现自己离您寻求的答案更近一步。下面的最后一个示例将通过一个更复杂的用例,演示如何通过关注表格来逐步找到答案。
重访鱼缸健康供应商
让我们继续使用鱼缸健康供应商的用例,该供应商将 IoT 元数据存储在 Postgres 中,并将传感器数据存储在 InfluxDB 中。在该示例中,供应商希望他们的客户成功代表了解所有客户鱼缸的 pH 值平衡。连接后,表格结果如下所示

这个结果对于客户成功代表来说足够简单易读,但如果添加几十个鱼缸和传感器,代表们就会被数据淹没。为了简化操作,管理层意识到代表们真正需要知道的是 pH 值高于 8 的鱼缸的位置。
幸运的是,他们正在使用 Flux,并且可以使用强大的内置管道前向运算符,简单地将上面的初始表格结果推送到其他计算中,以找到最高的平均 pH 值。
// group by location so that we can analyze each location independently of the others. (creates 3 tables out of 1)
|> group(columns: ["customer_location"])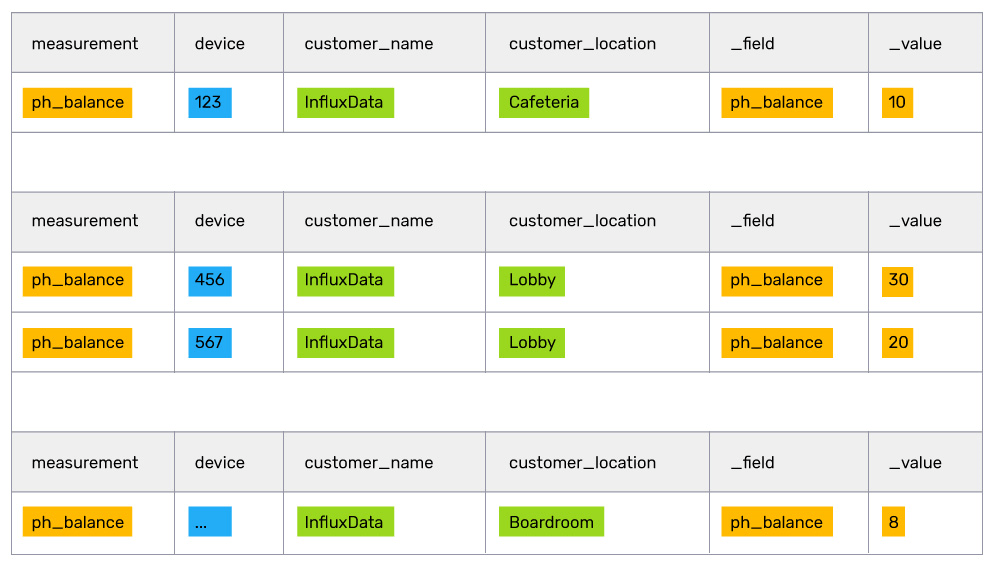
// find the mean value inside of each table
|> mean(column: "_value")
// grouping by no columns puts all of the tables together into one table
|> group(columns: [])
// filter out all rows of data below a value of 8
|> filter(fn: (r) => r._value > 8)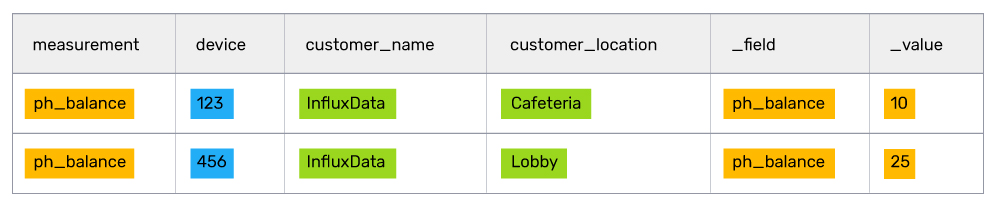
// sort the list to ensure the highest priority fish tanks are at the top of the list
|> sort(columns: ["_value"], desc: true)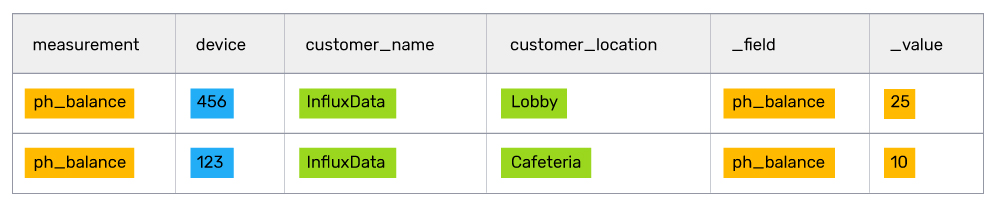
在处理和过滤所有数据后,客户成功代表应该有一个可管理的鱼缸列表来重点关注。 在本例中,列表的顶部是 Lobby 鱼缸,它看起来需要认真关注。
Flux 的未来一片光明
随着条件语句和多数据存储等许多强大功能的发布,Flux 正开始步入正轨。如果您正在处理任何时间序列分析用例,那么现在是深入了解 Flux 的绝佳时机。通过注册 InfluxDB Cloud 2 或下载最新的 OSS alpha 版本,即可轻松开始使用。
与往常一样,如果您对 Flux 有任何疑问或功能请求,请访问 Flux 的社区论坛并告知我们。
