教程:修改 Grafana 的源代码
作者:Jay Clifford / 开发者
2023 年 8 月 25 日
导航至
本文最初发布于 dev.to,并经许可在此处转载。
一次探索和猜测的故事
所以这篇博客与我通常的教程有点不同…
一点背景:我一直在与 Jacob Marble 合作,测试并“演示”他使用 InfluxDB 3.0 和 OpenTelemetry 生态系统的工作(如果您想了解更多信息,我强烈建议查看这篇 博客)。
在项目中,我们确定需要为 InfluxDB 数据源启用特定的 Grafana 功能,特别是从追踪到日志的功能。Grafana 是一个开源平台,其主要优势之一是能够修改其源代码以适应我们的独特需求。然而,即使对于经验最丰富的开发人员来说,深入研究如此强大的工具的代码库也可能令人望而生畏。
尽管存在复杂性,我们还是迎接了挑战,并一头扎进了 Grafana 的源代码。我们跌跌撞撞,一路学习了很多东西。现在,我们已经成功修改了 Grafana 以满足我们特定的项目需求,我认为是时候与大家分享这些获得的知识了。
本博客的目的不仅是为您提供调整 Grafana 源代码的逐步指南,还在于激发您探索和调整开源项目以满足您的需求。它是关于传授一种方法和一种心态,培养一种好奇心文化,并鼓励更多动手学习和解决问题。
我希望本指南能够启发您为您的项目修改 Grafana 的源代码,从而扩展开源平台可能实现的范围。现在是时候卷起袖子,深入 Grafana 代码的深处了。
问题
因此,我们的问题在于 Grafana 的 Trace 可视化。
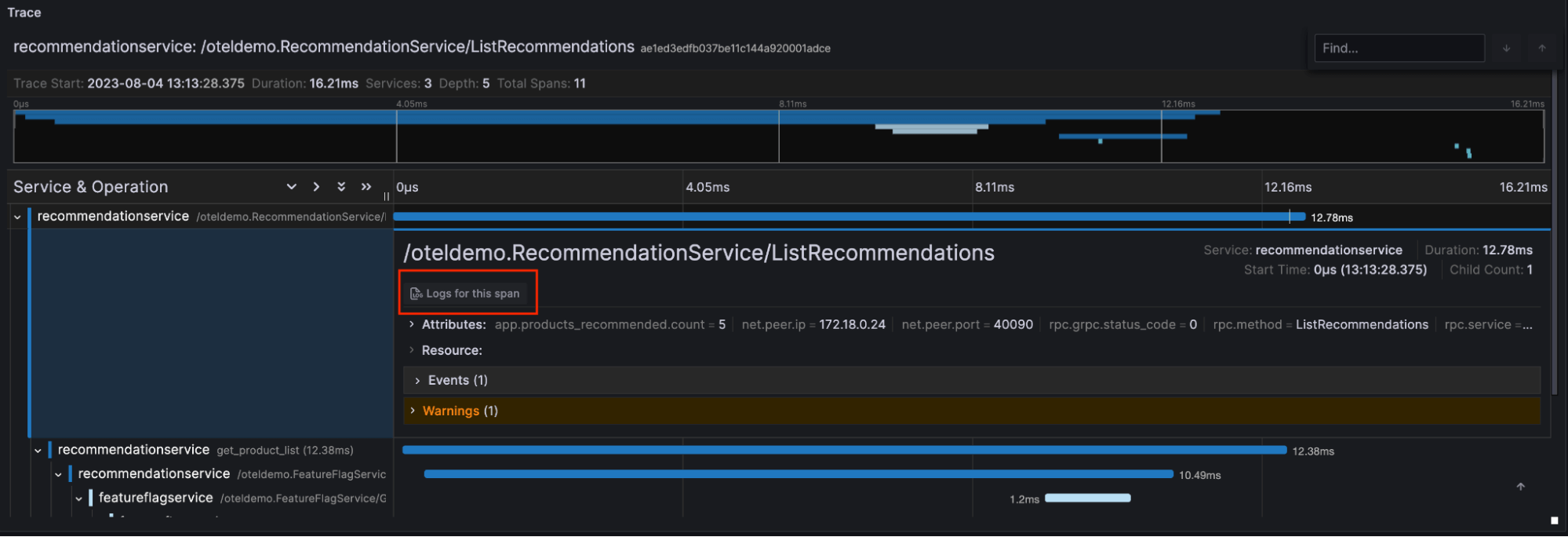
正如您所见,除了一个禁用的按钮:此 span 的日志,可视化效果在 InfluxDB 中表现相当好。如果我们不使用追踪数据源(在本例中,Jaeger 与 InfluxDB 3.0 作为 gRPC 存储引擎)配置日志数据源,则 Grafana 会自动禁用此按钮。Grafana 通常默认使用 日志浏览器界面 表示日志数据源。常见的日志数据源包括 Loki、OpenSearch 和 Elasticsearch。因此,让我们前往 Jaeger 数据源并进行配置…
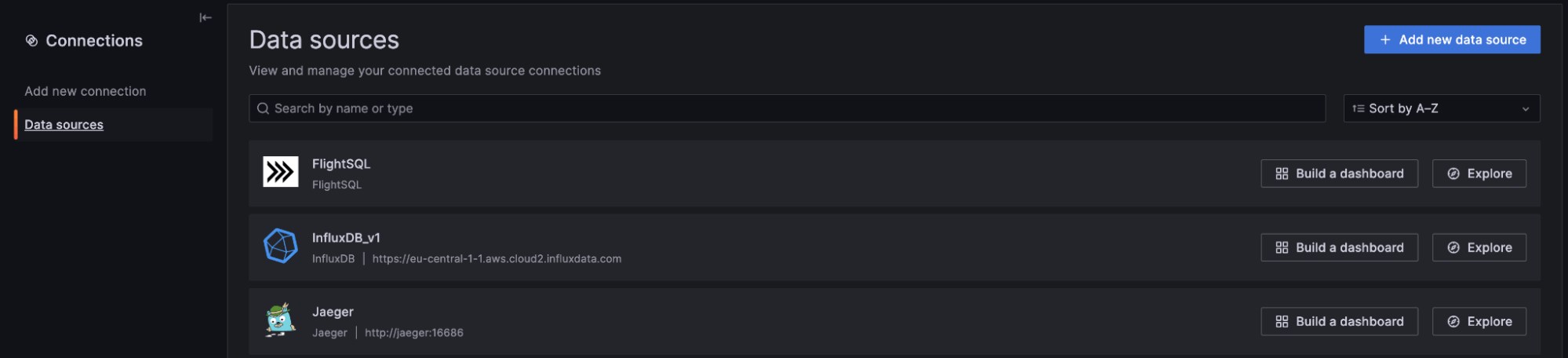
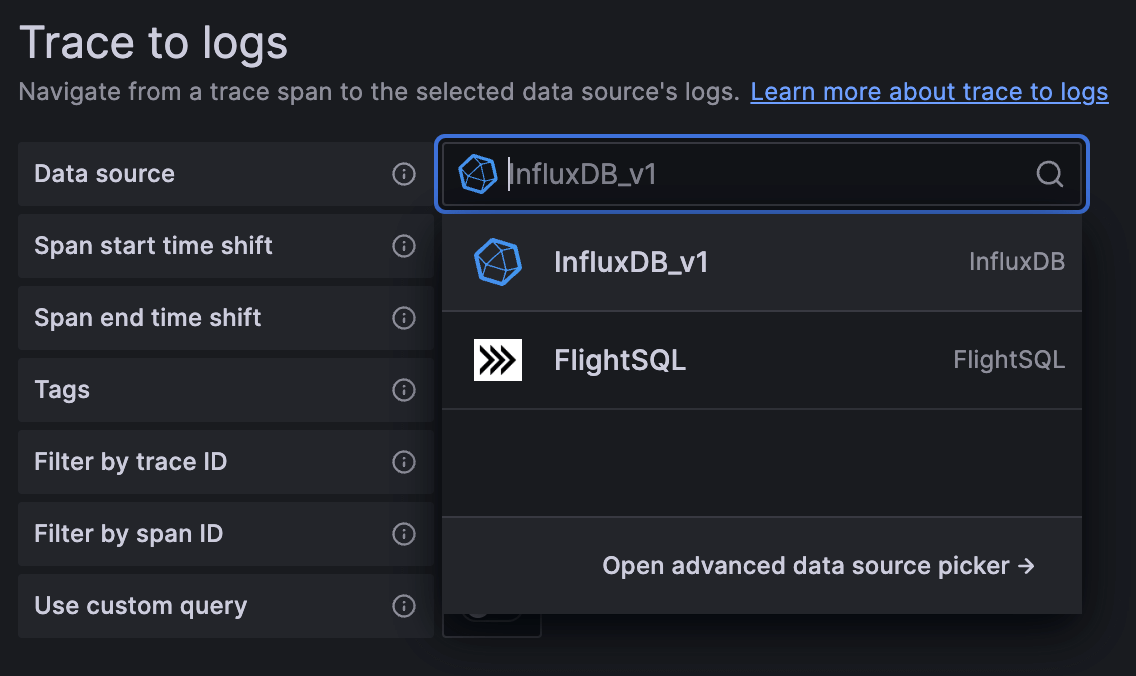
您可以通过 连接 -> 数据源 导航数据源。我们目前配置了三个数据源:FlightSQL、InfluxDB 和 Jaeger。如果我们打开 Jaeger 配置并导航到 Trace to Logs 部分,我们希望能够选择 InfluxDB 或 FlightSQL 作为我们的数据源。
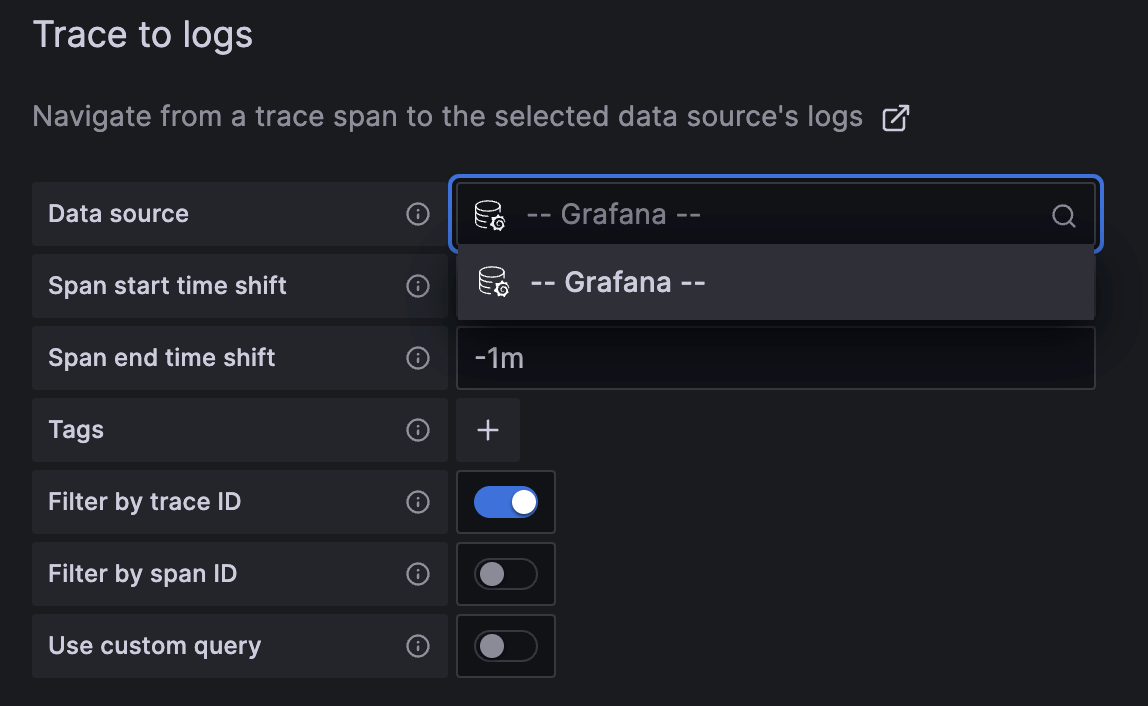
休斯顿,我们遇到问题了。Grafana 似乎不承认 InfluxDB 是日志数据源。这很合理。InfluxDB 最近才成为日志的可行选项。那么,我们有哪些选择呢?
- 我们躺平,接受问题,并希望将来此功能变得足够通用,以支持更多数据源。
- 采取行动,自己做出改变。
嗯,到现在您已经知道我们选择了哪个选项。
解决方案
本节总结了我为发现需要进行的更改、如何为自己的数据源实施更改以及最终如何构建自己的 Grafana OSS 自定义版本而采取的步骤。
发现
因此,第一步是了解从哪里开始。Grafana 是一个庞大的开源平台,包含许多组件,因此我需要缩小搜索范围。因此,我做的第一件事是在 Grafana 存储库中搜索生命迹象。
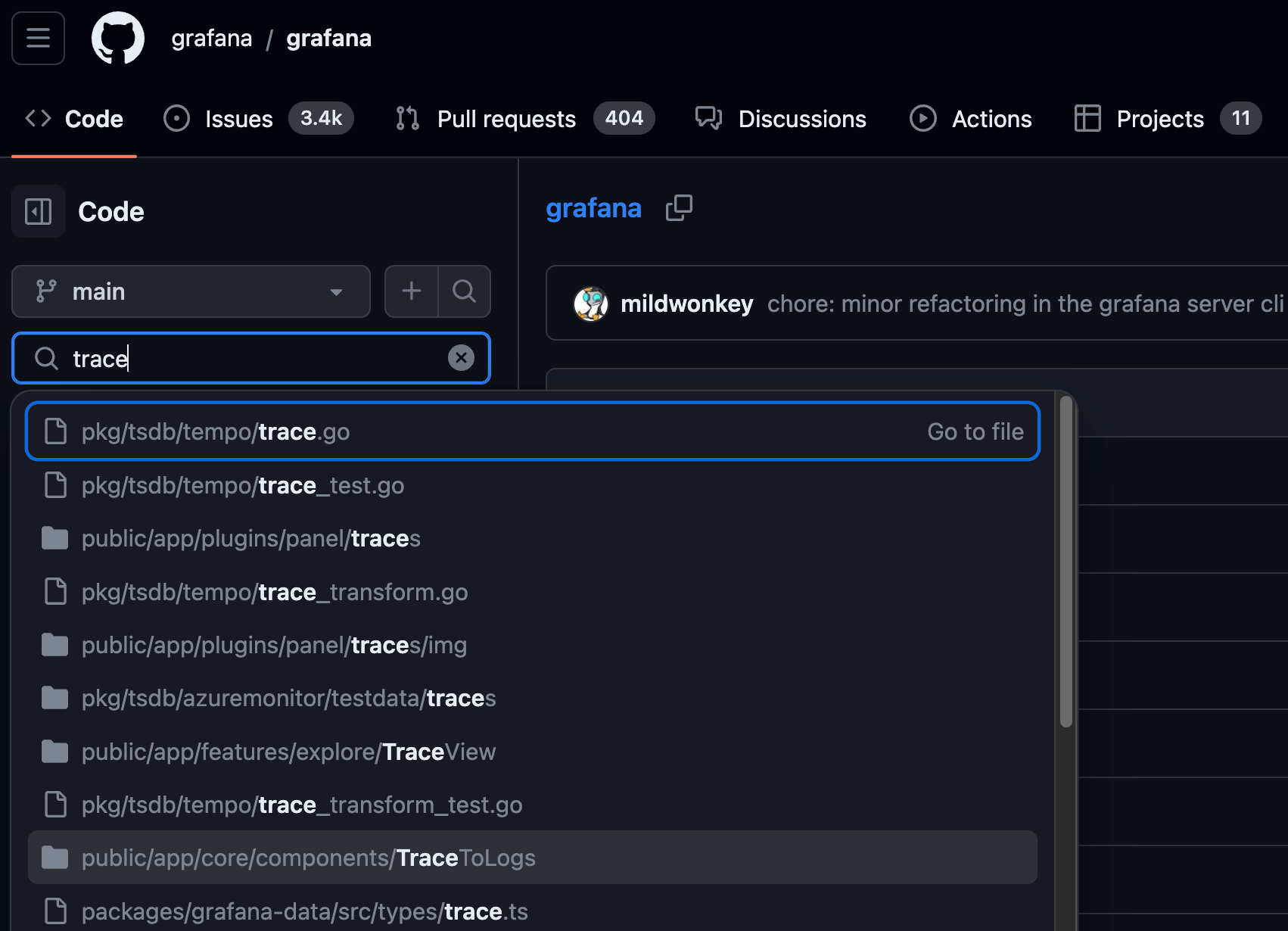
正如您所见,我通过使用关键字 trace 进行了这个小发现,这让我找到了 TraceToLogs 目录。这让我找到了 TraceToLogsSettings.tsx 中的这段代码
export function TraceToLogsSettings({ options, onOptionsChange }: Props) {
const supportedDataSourceTypes = [
'loki',
'elasticsearch',
'grafana-splunk-datasource', // external
'grafana-opensearch-datasource', // external
'grafana-falconlogscale-datasource', // external
'googlecloud-logging-datasource', // external
];这段代码似乎创建了 Trace to Logs 功能支持的数据源的静态列表。我们可以通过列表中的一些常见嫌疑对象(Loki、Elasticsearch 等)来确认这一点。基于这一发现,我们对 Grafana 源代码的第一个修改是将我们的数据源添加到此列表中。
现在,作为编码悲观主义者,我知道这可能不是我们唯一需要做的更改,但这是一个很好的起点。所以,我做了以下事情
- 我 fork 了 Grafana 存储库
- 克隆了存储库
git clone https://github.com/InfluxCommunity/grafana在我进行这些修改之前,我想做更多的搜索,看看是否还有其他更改应该进行。TraceToLogsSettings 文件中有一行引起了我的注意
const updateTracesToLogs = useCallback(
(value: Partial<TraceToLogsOptionsV2>) => {
// Cannot use updateDatasourcePluginJsonDataOption here as we need to update 2 keys, and they would overwrite each
// other as updateDatasourcePluginJsonDataOption isn't synchronized
onOptionsChange({
...options,
jsonData: {
...options.jsonData,
tracesToLogsV2: {
...traceToLogs,
...value,
},
tracesToLogs: undefined,
},
});
},
[onOptionsChange, options, traceToLogs]
);它是 TraceToLogsOptionsV2。当我搜索 Grafana 使用此接口的位置时,我找到了以下条目。
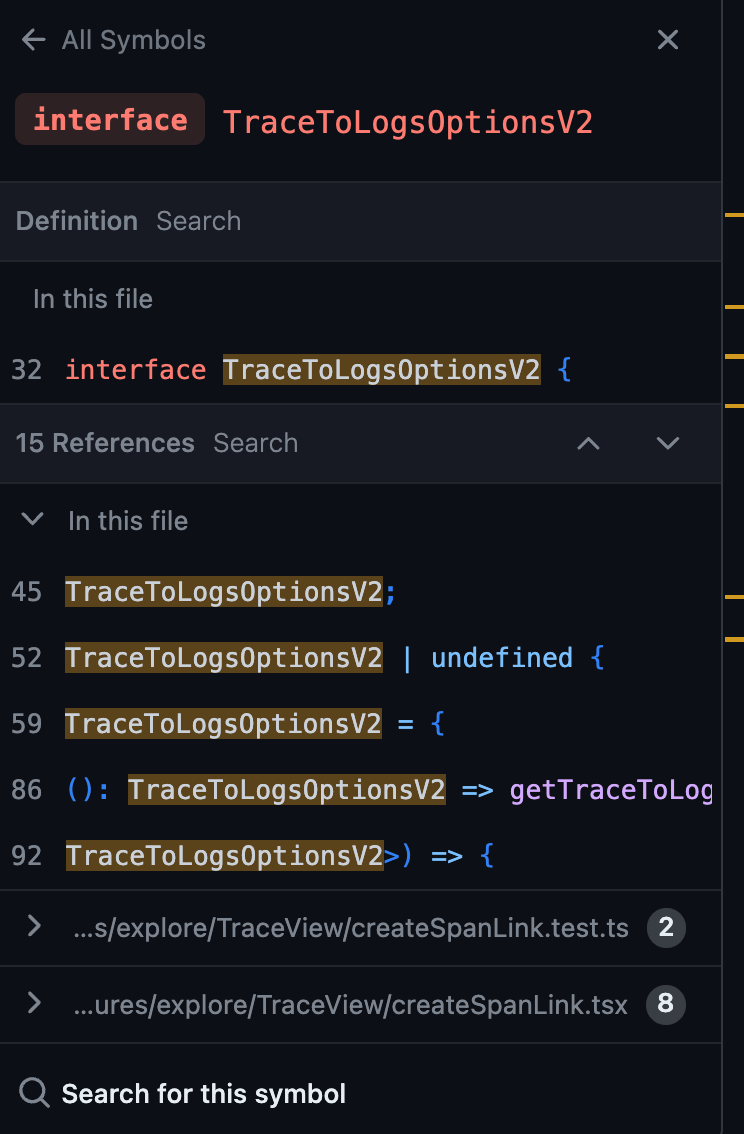
看来我们可能还需要在 createSpanLink.tsx 文件中做一些工作。在本节中,我找到了以下代码片段。此时,我的问题是“这段代码到底在做什么?”

长话短说,case 语句本质上是告诉 trace 可视化检查定义的日志数据源(如果有),并定义与该数据源相关的查询界面。如果在 case 语句中未找到指定的数据源,则 Grafana 只会禁用该按钮。这意味着正如我们所怀疑的那样,仅更改原始文件是不够的。
好的,我们的调查已完成,让我们继续进行代码更改。
修改
我们需要修改两个文件
让我们从最容易解决的文件开始,然后从那里开始。
TraceToLogsSettings
此文件相对容易更改。我们所需要做的就是修改受支持的日志输入源的静态列表,如下所示
export function TraceToLogsSettings({ options, onOptionsChange }: Props) {
const supportedDataSourceTypes = [
'loki',
'elasticsearch',
'grafana-splunk-datasource', // external
'grafana-opensearch-datasource', // external
'grafana-falconlogscale-datasource', // external
'googlecloud-logging-datasource', // external
'influxdata-flightsql-datasource', // external
'influxdb', // external
];正如您所见,我添加了两个数据源。我快速构建了 Grafana 项目,以查看这对我们的数据源配置有何影响(我们将在最后讨论如何构建)。
太棒了!我们得到了结果。现在,这仍然没有启用 Trace View 中的按钮,但我们已经知道这将需要更多的工作。
createSpanLink
现在,让我们继续进行我们修改的核心部分。郑重声明,我不是 TypeScript 开发人员。我所知道的是,该文件包含大量示例,我们可以使用这些示例尝试盲目复制粘贴,并进行一些修改。我最终对两个插件都这样做了,但为了使博客简洁,我们将重点关注 InfluxDB 官方插件。
我的假设是使用 Grafana Loki 界面作为 InfluxDB 界面的基础。首先包括添加数据源类型
import { LokiQuery } from '../../../plugins/datasource/loki/types';
import { InfluxQuery } from '../../../plugins/datasource/influxdb/types';当 Grafana 拥有数据源的官方插件时,这些很容易找到,因为它嵌入在官方存储库中。对于我们的社区插件,我有两个选择:在文件中定义静态接口或提供更多查询参数。我选择了后者。
下一步是修改 case 语句
// TODO: This should eventually move into specific data sources and added to the data frame as we no longer use the
// deprecated blob format and we can map the link easily in data frame.
if (logsDataSourceSettings && traceToLogsOptions) {
const customQuery = traceToLogsOptions.customQuery ? traceToLogsOptions.query : undefined;
const tagsToUse =
traceToLogsOptions.tags && traceToLogsOptions.tags.length > 0 ? traceToLogsOptions.tags : defaultKeys;
switch (logsDataSourceSettings?.type) {
case 'loki':
tags = getFormattedTags(span, tagsToUse);
query = getQueryForLoki(span, traceToLogsOptions, tags, customQuery);
break;
case 'grafana-splunk-datasource':
tags = getFormattedTags(span, tagsToUse, { joinBy: ' ' });
query = getQueryForSplunk(span, traceToLogsOptions, tags, customQuery);
break;
case 'influxdata-flightsql-datasource':
tags = getFormattedTags(span, tagsToUse, { joinBy: ' OR ' });
query = getQueryFlightSQL(span, traceToLogsOptions, tags, customQuery);
break;
case 'influxdb':
tags = getFormattedTags(span, tagsToUse, { joinBy: ' OR ' });
query = getQueryForInfluxQL(span, traceToLogsOptions, tags, customQuery);
break;
case 'elasticsearch':
case 'grafana-opensearch-datasource':
tags = getFormattedTags(span, tagsToUse, { labelValueSign: ':', joinBy: ' AND ' });
query = getQueryForElasticsearchOrOpensearch(span, traceToLogsOptions, tags, customQuery);
break;
case 'grafana-falconlogscale-datasource':
tags = getFormattedTags(span, tagsToUse, { joinBy: ' OR ' });
query = getQueryForFalconLogScale(span, traceToLogsOptions, tags, customQuery);
break;
case 'googlecloud-logging-datasource':
tags = getFormattedTags(span, tagsToUse, { joinBy: ' AND ' });
query = getQueryForGoogleCloudLogging(span, traceToLogsOptions, tags, customQuery);
}正如您所见,我添加了两个新 case:influxdata-flightsql-datasource 和 influxdb。然后,我从 Loki 复制了 case 中的两个函数调用:getFormattedTags 和 getQueryFor。我确定我可以单独保留 getFormattedTags,因为它似乎在大多数情况下都是相同的。但是,我仍然需要定义自己的 getQueryFor 函数。
让我们看一下在 influxdb case 语句中调用的新 getQueryForInfluxQL 函数
function getQueryForInfluxQL(
span: TraceSpan,
options: TraceToLogsOptionsV2,
tags: string,
customQuery?: string
): InfluxQuery | undefined {
const { filterByTraceID, filterBySpanID } = options;
if (customQuery) {
return {
refId: '',
rawQuery: true,
query: customQuery,
resultFormat: 'logs',
};
}
let query = 'SELECT time, "severity_text", body, attributes FROM logs WHERE time >=${__from}ms AND time <=${__to}ms';
if (filterByTraceID && span.traceID && filterBySpanID && span.spanID) {
query = 'SELECT time, "severity_text", body, attributes FROM logs WHERE "trace_id"=\'${__span.traceId}\' AND "span_id"=\'${__span.spanId}\' AND time >=${__from}ms AND time <=${__to}ms';
} else if (filterByTraceID && span.traceID) {
query = 'SELECT time, "severity_text", body, attributes FROM logs WHERE "trace_id"=\'${__span.traceId}\' AND time >=${__from}ms AND time <=${__to}ms';
} else if (filterBySpanID && span.spanID) {
query = 'SELECT time, "severity_text", body, attributes FROM logs WHERE "span_id"=\'${__span.spanId}\' AND time >=${__from}ms AND time <=${__to}ms';
}
return {
refId: '',
rawQuery: true,
query: query,
resultFormat: 'logs',
};
}这里有很多内容,但让我重点介绍重要部分。首先,我从 Loki 函数的精确副本开始。然后,我进行了以下更改
- 我将返回接口从
LokiQuery | undefined更改为InfluxQuery | undefined。这是我们之前导入的数据源类型。 - 接下来,我专注于返回有效负载。在 InfluxQuery 类型文件中进行了一些挖掘之后,我想出了这个
InfluxDB 数据源有一个 resultFormat 参数,允许我定义结果格式(通常是指标)。这也告诉我数据源期望原始查询而不是表达式。return { refId: '', rawQuery: true, query: query, resultFormat: 'logs', }; - 最后,我定义了用户单击按钮时将运行的查询。这些查询取决于用户在数据源设置中切换的过滤器功能(按 traceID、spanID 或两者过滤)。我修改了 Loki 函数中定义的
if语句,并构造了静态 InfluxQL 查询。从那里,我使用了在其他数据源中找到的 Grafana 占位符变量来使查询动态化。这是一个例子
完全公开,我花了好一会儿才弄清楚if (filterByTraceID && span.traceID && filterBySpanID && span.spanID) { query = 'SELECT time, "severity_text", body, attributes FROM logs WHERE "trace_id"=\'${__span.traceId}\' AND "span_id"=\'${__span.spanId}\' AND time >=${__from}ms AND time <=${__to}ms';>=${__from}ms和<=${__to}ms。这最终成为一个暴力构建和错误案例。
构建
呼!我们已经过了困难的部分。现在开始构建过程。我在 Docker 方面有很多年的经验,所以这部分对我来说没有压力,但我认为对于新的 Docker 用户来说可能会令人生畏。幸运的是,Grafana 为此任务提供了一些易于遵循的 文档。为了解释清楚,这些是步骤
- 运行以下构建命令(这可能需要一段时间,如果使用 macOS 或 Windows,请确保您的 docker VM 有足够的内存)
make build-docker-full - 构建过程会生成一个名为:grafana/grafana-oss:dev 的 Docker 镜像。我们可以直接使用此镜像,但作为一种形式,我喜欢重新标记镜像并将其推送到我的 Docker 注册表。
这样,我在暴力强制更改时就可以设置检查点。docker tag grafana/grafana-oss:dev jaymand13/grafana-oss:dev2 docker push jaymand13/grafana-oss:dev2
我们有了!一个完全烘焙的 Grafana 开发镜像,可以尝试我们的更改。
结果和结论
因此,在调查、进行更改并构建新的 Grafana 容器之后,让我们看一下我们的结果
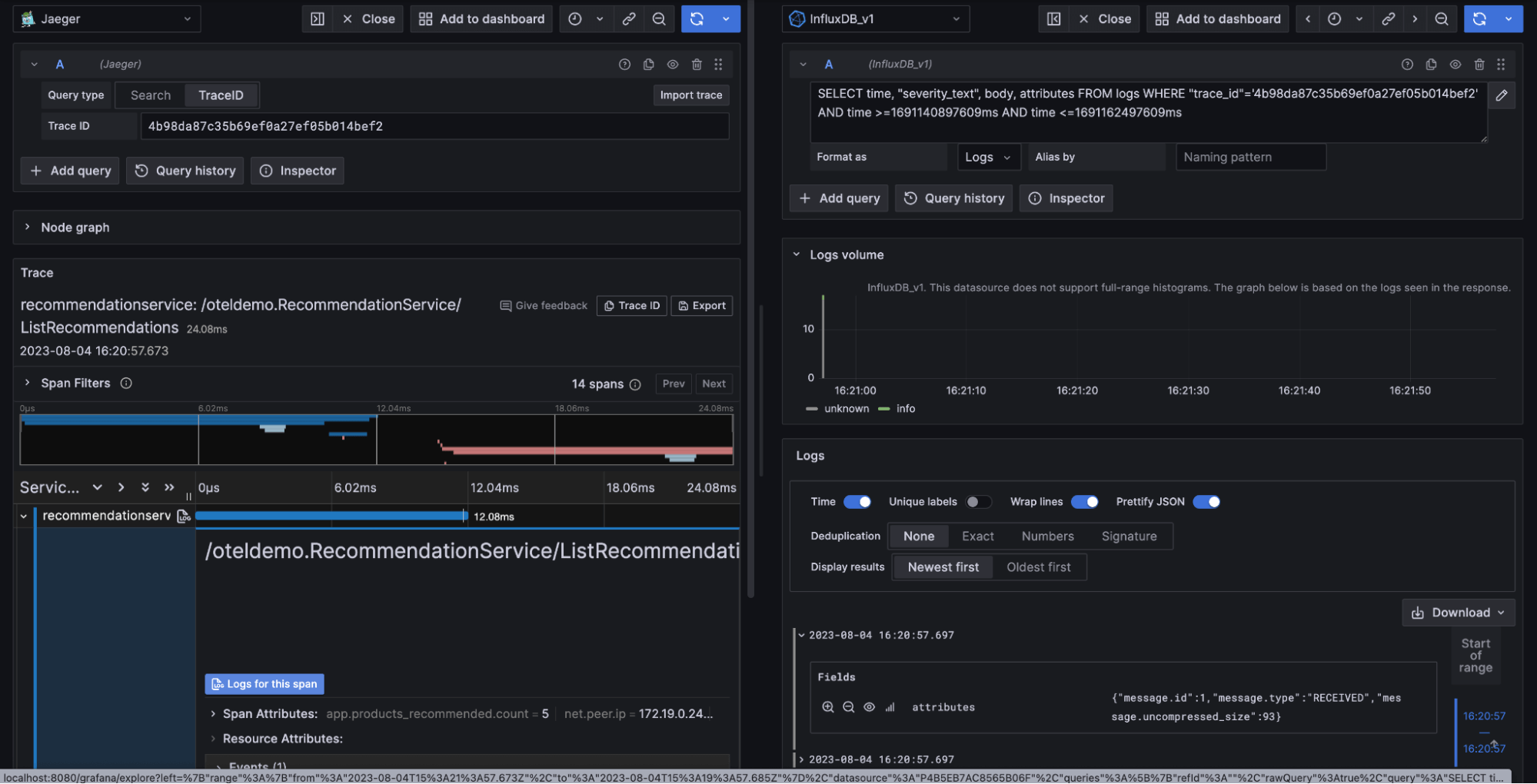
通过我们的更改,此 span 的日志 按钮现在处于活动状态。我们还在每个 span 旁边看到了这个简洁的小日志按钮。坦白说:蓝色的 此 span 的日志 按钮目前仅在 Grafana Explorer 选项卡中有效,但新的 日志 链接在我们的仪表板中有效。
为了快速解释差异,用户构建自定义 Grafana 仪表板,并且可以包含 1 个或多个数据源以及各种不同的可视化效果。另一方面,数据浏览器提供了用于向下钻取和调查活动的界面,就像您在上面的屏幕截图中看到的那样。尽管如此,与我们为达到此目的所需的更改相比,这并不是一个大问题。
至此,我们已经结束了对修改 Grafana 源代码的复杂性的深入研究。在本教程中,我希望您不仅对如何为您的特定需求自定义 Grafana 获得了实际的了解,而且还对开源平台的灵活性和潜力有了更高的认识。
请记住,在开源领域,我们可以根据自己的需要进行调整、修改和重新构想的程度没有限制。我希望本指南能为您深入研究自己的项目提供良好的服务,并使您更接近掌握 Grafana 这个强大的工具。对我而言,我的旅程还在继续,因为我现在计划为这个 OSS 版本添加示例支持。如果您想自己尝试一下,可以在 此处 找到 OpenTelemetry 示例。
