使用 InfluxDB 和降采样分析趋势聚合值
作者:Kristina Robinson / 产品, 用例, 开发者
2021 年 1 月 25 日
导航至
(更新:InfluxDB 3.0 放弃了 Flux 和内置任务引擎。用户可以使用外部工具,例如基于 Python 的 Quix,在 InfluxDB 3.0 中创建任务。)
InfluxDB 非常擅长捕获各种指标,并允许最终用户将这些指标聚合到自定义时间分组中,无论您是每 10 分钟监控一次物联网设备的性能,还是每周监控 GitHub 存储库的问题关闭情况,还是每秒监控 Web 性能指标。仪表板以您确定的精确间隔一目了然地提供该信息。但更深一层呢?当您微调了仪表板并捕获了想要的数字后会发生什么?您如何观察它们随时间的变化? 这就是降采样和趋势分析变得至关重要的地方,并且可以将您的目标提升到新的水平。 InfluxDB 使识别要分析趋势的内容、跟踪它并绘制成图变得容易。
为了演示如何分析值随时间变化的趋势,这篇博文将介绍如何使用 SpeedTest Community Template,将互联网连接速度每分钟下载到 InfluxDB 中。社区模板有一个仪表板,显示当前的上传和下载速度。然后,我们将计算 5 分钟间隔内的最小、平均和最大速度。 它需要在本地计算机上安装 SpeedTest-CLI 可执行文件。
将 SpeedTest Community Template 与 InfluxDB 结合使用
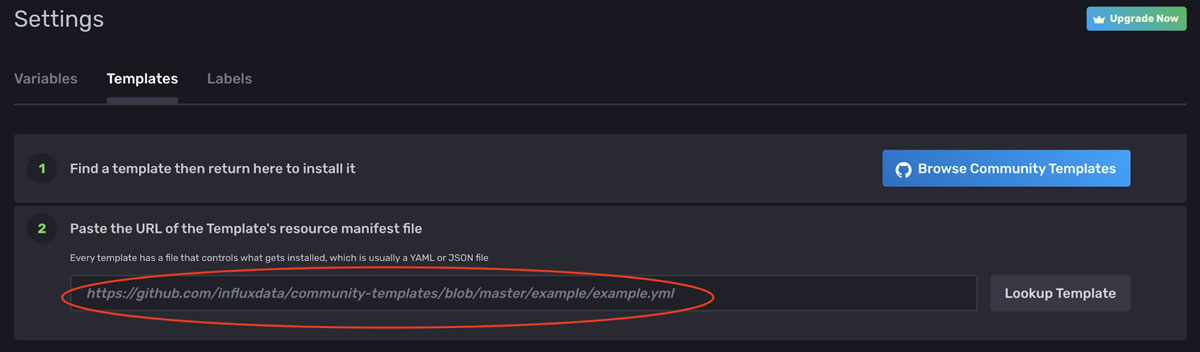
要在 InfluxDB 中安装 SpeedTest Community Template,请单击Settings(设置)、Templates(模板),然后在第 2 行中输入以下 URL 作为资源清单文件
https://github.com/influxdata/community-templates/blob/master/speedtest/speedtest.yml
配置以下环境变量:INFLUX_HOST(设置为您的云 URL)、INFLUX_ORG(单击人物图标即可获得),以及 INFLUX_TOKEN (可以在 Settings(设置)、Tokens(令牌)下生成,必须至少是 speedtest 存储桶的 WRITE 令牌)。 环境变量可以在 shell 资源文件中设置,直接导出 (export INFLUX_ORG=InfluxData) 或使用用户环境变量 (Windows OS) 设置。
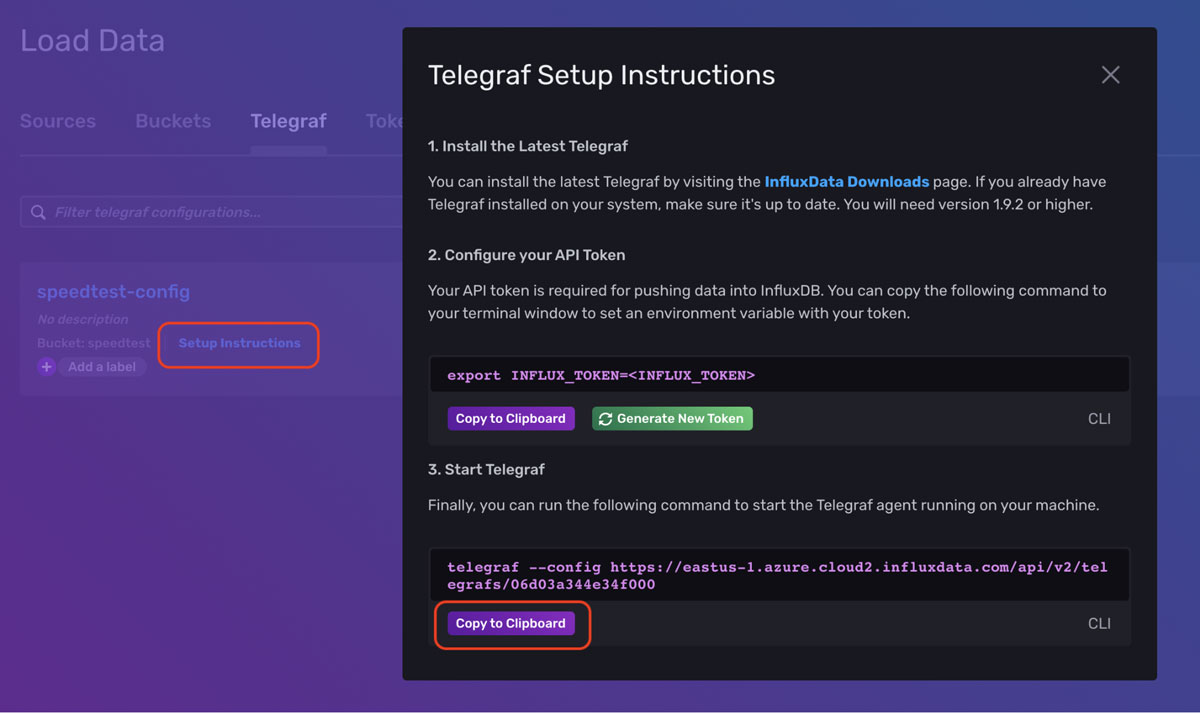
按照 Setup Instructions(设置说明)弹出窗口中提供的说明(单击 Data(数据)、Telegraf、Setup Instructions(设置说明))在本地计算机上启动 Telegraf。
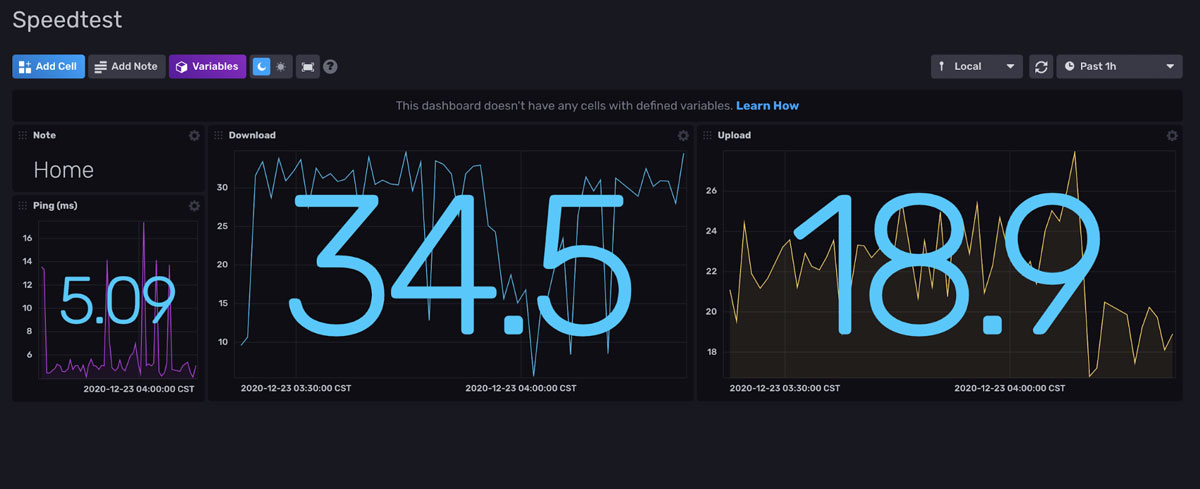
您应该有一个看起来与此类似的面板
访问生成仪表板单元格的 Flux 查询
我们想要选择您感兴趣的趋势值背后的查询。 在此示例中,它是下载速度。
打开标记为“Speedtest”的仪表板。
配置标记为“Download”(下载)的单元格。
Query Editor(查询编辑器)打开,以便您可以选择并复制整个查询
from(bucket: "speedtest")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "exec_speedtest")
|> filter(fn: (r) => r["_field"] == "download_bandwidth")
|> map(fn: (r) => ({r with _value: r._value / 1000000.0}))
|> yield(name: "last")在 InfluxDB 中使用 Flux 同时可视化多个聚合
下一步涉及使用获取现有指标的查询,但将其写入另一个存储桶。 或者,聚合,然后写入。 为什么要这样做? 原因有两个
- 存储桶可能具有有限的保留策略。 例如,源数据可能仅可用 30 天。 我们想要分析超过 30 天的趋势,因此写入具有更长保留策略的不同、更小的存储桶允许我们更长时间地保留趋势数据。
- 我们可以写入原始存储桶中不可用但从源数据派生的聚合数据。 这允许我们对聚合数据进行一些有趣的工作。
作为这里的旁注,您可以直接从仪表板可视化聚合数据。 但是,这篇博文旨在解决聚合数据本身就很有趣以进行操作,并且可能需要比初始源存在更长时间可用的问题。
让我们跟踪三个聚合:下载速度的最小值、最大值和平均值。
单击 Explore(探索)(Data Explorer(数据资源管理器))。
单击右手边的 Script Editor(脚本编辑器)按钮。
粘贴从上面复制的查询。
从此查询中计算三个新值:最小值、最大值和平均值。 您可以使用 InfluxDB 提供的任何聚合函数,但为了示例目的,让我们保持简单。 首先,将复制的查询分配给 DATA 标签。 这将保存返回的数据集以供以后使用。 接下来,使用该 DATA 并使用管道前向运算符将该数据集发送到三个函数中的每一个,并使用 yield() 函数来显示结果。 在 yield() 函数中使用不同的名称将允许每个提交显示多个值。
DATA = from(bucket: "speedtest")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "exec_speedtest")
|> filter(fn: (r) => r["_field"] == "download_bandwidth")
|> map(fn: (r) => ({r with _value: r._value / 1000000.0}))
DATA
|> mean()
|> yield(name: "mean")
DATA
|> min()
|> yield(name:"min")
DATA
|> max()
|> yield(name:"max")此时单击 Submit(提交)将在 Graph(图表)上显示三条数据线,或者使用 Table(表格)显示三组数据。 您还可以查看 Raw Data(原始数据)并查看生成的数据。 您还可以通过删除新表中不需要的长期标记值来进一步清理此数据。 您可以将“drop”函数添加到顶部部分,并删除您不希望保留的任何字段。
编写降采样任务以使用 InfluxDB 计算最小、最大和平均下载速度
现在我们已经查询了我们想要分析趋势的值,我们准备将它们写入新存储桶。 让我们创建一个名为“speedtest-downsampled”的新存储桶。
将上面的 yield() 函数更改为 write 语句,使用 to() 函数。 此外,使用 set() 函数在 “_field” 条目中为 min()、mean() 和 max() 函数计算的每个值创建匹配的名称(“min”、“mean”、“max”)。 这些硬编码的 “_field” 条目将是在最后过滤和显示图表时查找值(存储在 _value 中)的键(存储在 _field 中)。
最后,让我们看一下 _time 列。 Min() 和 max() 都解析为单个记录,这意味着它们都将具有自己的 _time 值(发生在不同的时间)。 但是,mean() 是许多记录的聚合,它将无法访问单行的 _time 值。 但是,为了快照这 3 个值并将它们分组在一起,我们希望在我们选择的任何间隔比较它们。 因此,让我们使用 map() 函数为所有三个聚合行的 _time 字段分配相同的值。 使用 now() 函数为 _time 值分配此查询执行时的值,并将其保存到所有三个函数。 这允许基于相同的 _time 和 _measurement 字段进行查询。 请记住,使用 to() 函数写入存储桶的所有行都需要具有以下字段的值:_measurement、_field 和 _time。 我们从第 3 行的 filter 函数中获得 _measurement。 我们使用 set() 函数分配了 _field 值。 现在我们正在分配 _time 值。
DATA = from(bucket: "speedtest")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "exec_speedtest")
|> filter(fn: (r) => r["_field"] == "download_bandwidth")
|> map(fn: (r) => ({r with _value: r._value / 1000000.0}))
|> drop(columns:["_start", "_stop", "host"])
time = now()
DATA
|> mean()
|> map(fn: (r) => ({r with _time: time}))
|> set(key:"_field", value:"mean")
|> to(bucket:"speedtest_downsampled")
DATA
|> min()
|> map(fn: (r) => ({r with _time: time}))
|> set(key:"_field", value:"min")
|> to(bucket:"speedtest_downsampled")
DATA
|> max()
|> map(fn: (r) => ({r with _time: time}))
|> set(key:"_field", value:"max")
|> to(bucket:"speedtest_downsampled")通过单击 Submit(提交)按钮测试此查询。 从 Query Builder(查询构建器)中单击 Query2,选择 FROM ‘speedtest_downsampled’,Filter ‘exec_speedtest’ 并单击 Submit(提交)。
在选中 Query1 选项卡的情况下,单击 Save As(另存为)。 输入任务的名称,任务应运行的频率,然后选择 ‘speedtest_downsampled’ 存储桶。
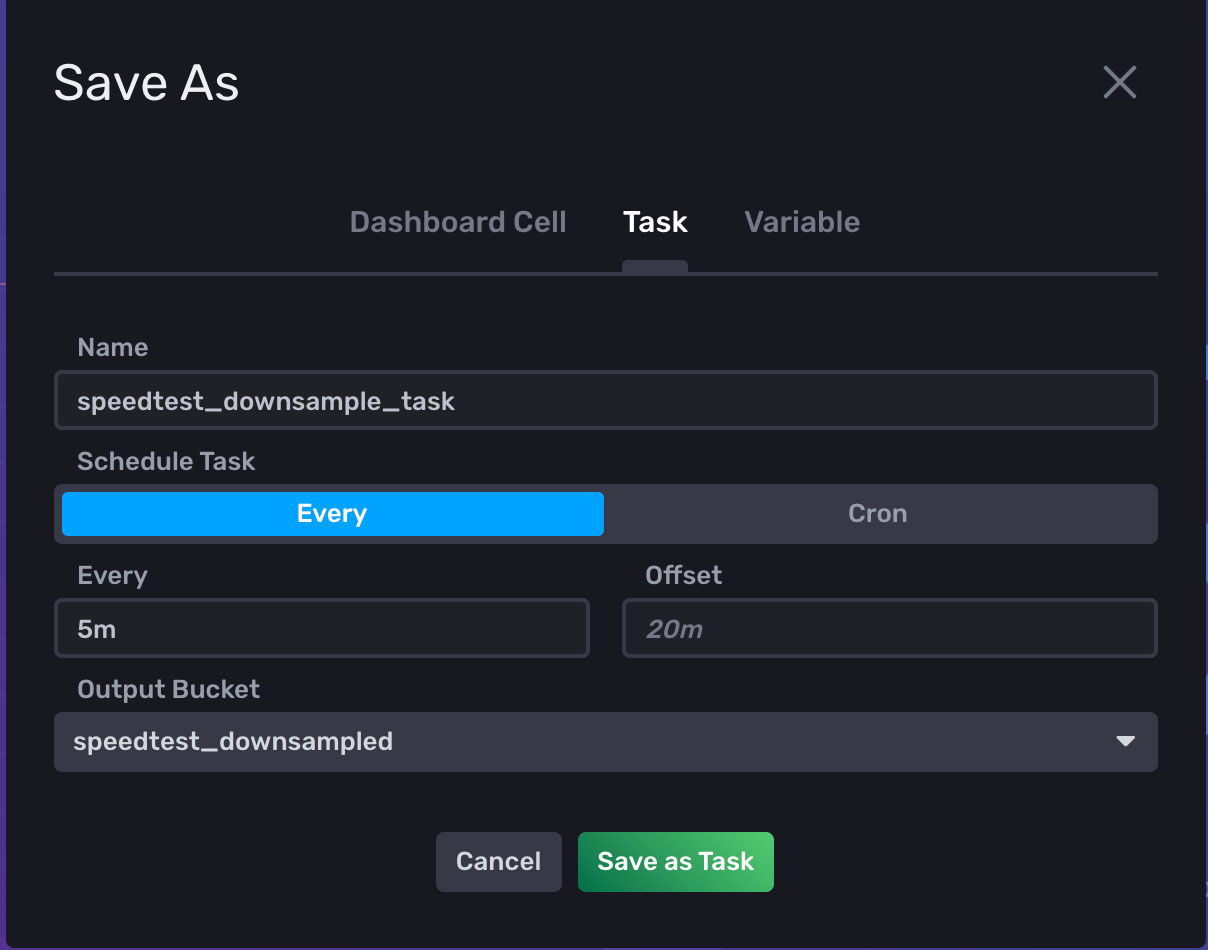
从 Tasks(任务)菜单中,现在可以编辑任务。
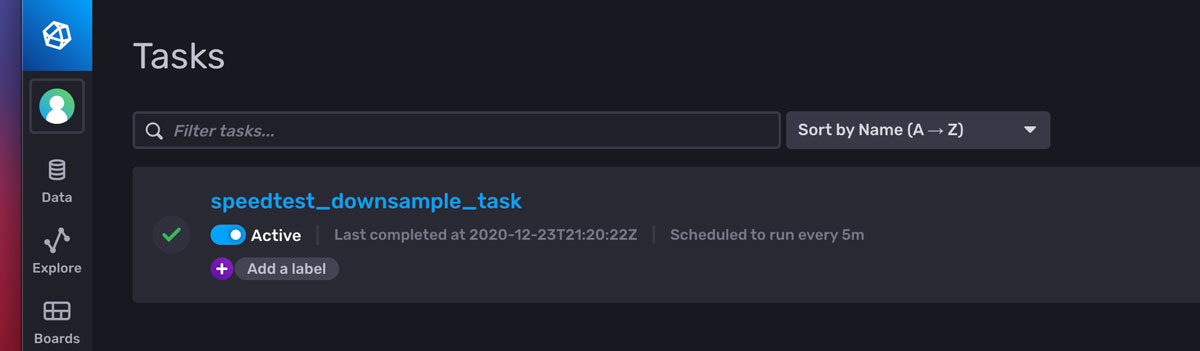
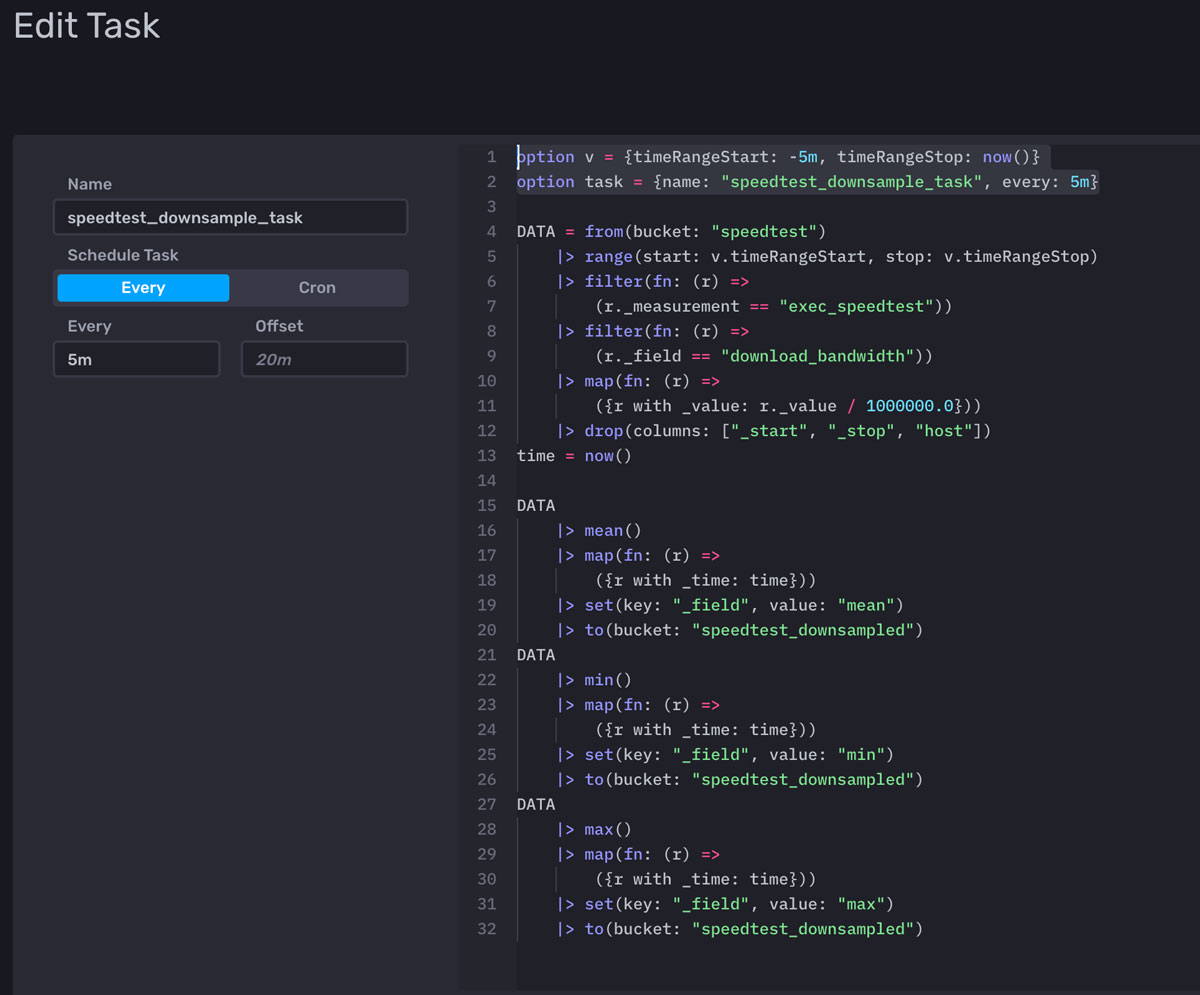
- 删除任务底部的额外 to() 函数。 这是一个已知问题,创建的每个任务都会写入上一个屏幕上指定的存储桶。 由于保存在查询中的 flux 已经包含 to() 函数,因此可以删除此添加的语句。
- 验证任务顶部的 timeRangeStart,上面的第 1 行。 使用 ms、s、m、h、d 或 y 来指定时间间隔,或选择特定日期。 在此示例中,-5m 用于开始时间,以使任务收集过去 5 分钟的数据。
- 通过确认任务声明(上面的第 2 行)中 “every:” 后的值来验证任务的运行频率。
- 单击 Save(保存)。
在 InfluxDB 仪表板中合并任务输出
我们快完成了! 新存储桶 (speedtest_downsampled) 将开始累积 3 个聚合数据值的快照。 随时间查询它们并将其添加到仪表板。 返回 Data Explorer(数据资源管理器)。
打开一个新的 Query(查询)选项卡,然后单击 Script Editor(脚本编辑器)。 粘贴此简单查询以查看按 _time 字段分组的 ‘speedtest_downsampled’ 存储桶,由于聚合字段具有相同的时间戳,因此效果很好。
from(bucket: "speedtest_downsampled")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "exec_speedtest")
|> group(columns : ["_time"])单击 Submit(提交),然后使用 Table Graph(表格图表)或 Raw Data View(原始数据视图)查看每个时间戳的三条记录

查看最多三条记录的最佳图表类型是 Graph(折线)可视化。 它需要命名的 yield() 函数来显示多个序列。 如前所述,使用 Script Editor(脚本编辑器)添加命名的 yield() 函数
DATA = from(bucket: "speedtest_downsampled")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "exec_speedtest")
|> filter(fn: (r) => r._field == "mean" or r._field == "min" or
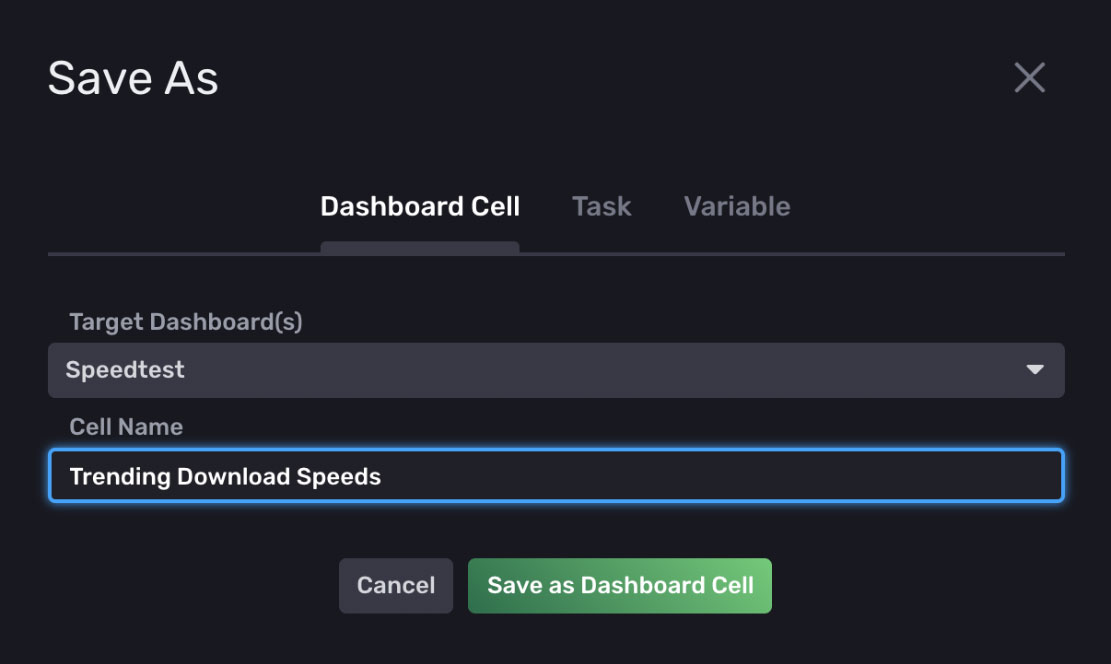
r._field == "max")单击 Save As(另存为)、Dashboard Cell(仪表板单元格),选择 Speedtest Dashboard(Speedtest 仪表板),并将单元格命名为 “Trending Download Speeds”(趋势下载速度),以使新的 Graph(图表)可视化显示在现有仪表板上。
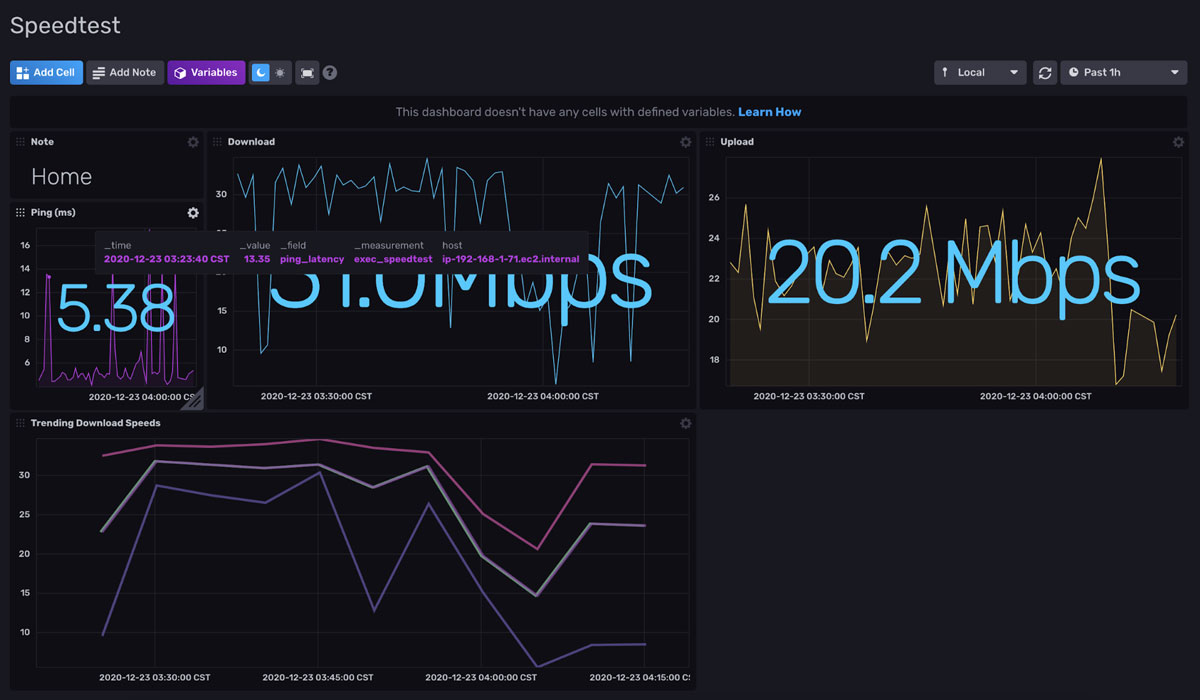
调整仪表板上单元格的位置,我们就完成了。
关于趋势分析、在一个任务中执行多个聚合以及使用 InfluxDB 可视化输出的最终思考
我希望本教程能帮助您进行降采样和可视化工作。 与往常一样,如果您遇到障碍,请在我们的 社区网站 或 Slack 频道 上分享它们。 我们很乐意获得您的反馈并帮助您解决任何问题。
鸣谢: Ignacio Van Droogenbroeck Anais Dotis-Georgiou
