使用 InfluxDB IOx 进行追踪
作者:Jason Myers / Jacob Marble / 产品, 用例
2022 年 11 月 30 日
导航至
追踪一直是时间序列数据的关键用例。但坦率地说,这也是 InfluxDB 过去的版本未能如我们所愿处理好的用例之一。其中一个障碍是基数问题。追踪数据几乎从定义上来说就是高基数数据,而在 InfluxDB IOx 之前,高基数数据可能会影响查询性能。
InfluxDB IOx 消除了基数限制,从而使 InfluxDB 平台能够以高性能的方式处理更广泛的用例,例如追踪和日志。因此,让我们回答一些关于追踪的基本问题,并探讨 InfluxDB IOx 如何使其成为可能。
什么是追踪?
当您拥有分布式系统时,通常您想知道所有不同的组件是如何相互关联地运行的。某些进程和服务可能依赖于其他进程和服务,因此错误、延迟和瓶颈可能会影响整体系统性能。
为了理解所有这些不同的部分是如何协同工作的,我们使用一种称为追踪的可观测性形式。追踪提供了请求、任务、操作、作业或其他有用的工作单元在分布式系统中运行过程的视图。任意数量的子任务(算法、网络调用、数据库事务、缓存查询等)协同工作以满足请求。每个子任务都是一个 span。
因此,trace 是 span 的集合,它提供了关于请求更精细细节的计时信息。
追踪是如何工作的?
Span 可以有零个或多个子 span,称为子 span 或子项。子 span 可以有自己的子项,依此类推。
Trace 从根 span 开始,并且没有父 span。由于根 span 是 trace 中所有其他 span 的递归父 span,因此根 span 的持续时间表示 trace 的总时间。
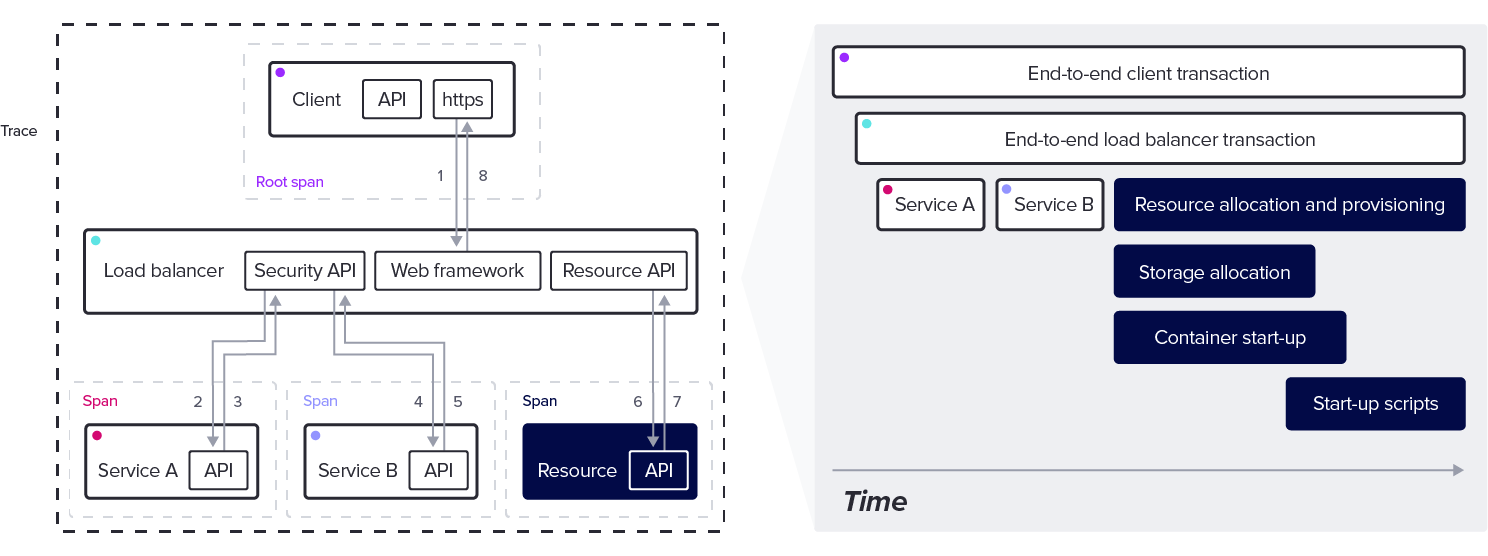
如图所示,单个 trace 中可能存在许多 span。
为了从所有这些 span 构建 trace,并确保一切正确地组合在一起,每个 span 都需要识别信息。为此,每个 span 都有一个 trace ID、一个 span ID,以及在适用时,一个父 span ID。
这些构建块创建了一个子任务的层次树,为构建 trace 提供了关键结构。
这与基数有什么关系?
在 IOx 之前,InfluxDB 的时间序列合并树 (TSM) 将数据存储在 series 列中。Series 是 measurement、tags 和一个 field 的唯一组合。在此模型中,基数是 series 的总数,即存储在磁盘上的列数。因此,如果您有两个 series,则您的基数为二。高基数通常会变得麻烦,因为它与较慢的查询性能相关。
为了避免在 IOx 之前的 InfluxDB 中出现失控的基数,series 的数量必须受到限制。追踪的挑战在于,每个 trace 和 span 都会生成唯一的 ID(对于追踪,大多数数据库模式都将这些 ID 视为 tags),从而创建无界的 tag 值。将此与追踪数据的量和速度相结合,您将得到失控的基数。
IOx:解决基数问题
以前版本的 InfluxDB 将每个 series 存储为一列,这可能导致大量的列。随着 InfluxDB IOx 的引入,measurement 时间戳、tags 和 fields 都被保存到各自的列中,因此具有两个 tag 键和三个 fields 的 measurement 由六列表示。这种设计大大减少了数据库需要处理的列数。
IOx 将表的列存储在 Parquet 文件中。当更多数据到达时,IOx 会将表的这些列写入新的 Parquet 文件。Parquet 文件可以很好地压缩数据列,并且 IOx 将这些文件存储在对象存储 (S3) 中,这具有极高的可扩展性。InfluxDB Cloud 查询层会根据您的查询工作负载自动扩展。
Parquet 文件格式还提供了出色的查询性能。例如,当 IOx 将数据列写入 Parquet 时,它会在 Parquet 元数据中包含提示以描述列内容。这样,查询引擎可以在查询时跳过整个 Parquet 文件和/或 Parquet 文件中无用的部分。
这些对 InfluxDB 存储引擎、持久化格式以及存储和查询层的更新结合在一起,提供了无限的基数,并解锁了诸如追踪之类的用例。
要开始使用 InfluxDB IOx 并了解无限基数可以为您解锁什么,请注册 InfluxDB IOx 测试计划。
