时间序列,InfluxDB 和向量数据库
作者:Anais Dotis-Georgiou / 开发者
2024年3月26日
导航至
将时间序列数据与向量数据库的强大功能相结合,为分析和机器学习应用开辟了新的领域。时间序列数据以其顺序和时间戳为特征,在从金融市场到物联网设备的各个领域的监控和预测中至关重要。InfluxDB 作为一个领先的时间序列数据库,擅长高效且可扩展地处理此类数据。
另一方面是 Milvus,一个高度通用的向量数据库,旨在管理和查询高维向量数据,从而实现对 AI 驱动的洞察至关重要的高级相似性搜索。
这篇博文探讨了 InfluxDB 和 Milvus 之间的无缝协同作用,指导您完成从 InfluxDB 查询数据、规范化数据、将其转换为向量并写入 Milvus 的过程。
最后,我们对时间序列执行相似性搜索,以识别监控条件是否熟悉。通过利用这两个数据库的优势,我们解锁了一种全面的方法来管理和利用复杂数据集,以用于前沿应用。
要求
要运行此示例,您需要以下内容
- Docker
- Jupyter Notebooks
- 一个免费级别的 InfluxDB Cloud 实例
您需要从 InfluxDB 实例收集以下凭据
- Bucket/数据库
- 令牌
- URL
要运行此示例,请克隆以下 repo 并按照 README.md 中的说明进行操作。在此步骤中,您将构建和启动 Milvus 容器并运行 Jupyter Notebook。
什么是向量数据库?
向量数据库是专门的存储系统,旨在高效处理向量数据(表示复杂数据点的数字数组,例如图像、文本或音频特征)。这些数据库擅长存储、索引和查询高维向量,这些向量通常由机器学习模型或算法生成。它们受欢迎的核心原因是其执行相似性搜索的卓越能力;它们可以快速识别与查询向量最相似的向量,这使得它们对于推荐系统、图像和语音识别以及自然语言处理等应用不可或缺。
人工智能和机器学习的兴起推动了对高效相似性搜索机制的需求,从而将向量数据库推向了聚光灯下。它们使用先进的索引技术来管理维度灾难——这是高维空间中的一个挑战,传统数据库方法在性能方面会遇到困难。这种效率允许即使在海量数据集中也能进行实时查询,从而增强用户体验和机器学习模型的有效性。
此外,向量数据库有助于细致地理解和处理数据,超越简单的关键字搜索,拥抱现实世界数据的复杂性。这种能力使应用程序能够交付更准确和相关的结果,从而推动向量数据库在各个行业中日益普及,这些行业旨在利用人工智能和机器学习创新来获得竞争优势。
TSDB 和向量数据库应用场景
为了更好地理解时间序列数据库 (TSDB) 和向量数据库之间的关系,将它们的应用放在示例场景中进行理解会很有帮助。假设您正在开发一个平台,该平台提供实时交通监控和模式识别,以改善城市交通管理。具体来说,您想创建一个解决方案,用于识别交通状况何时异常运行,并确定存在的交通异常类型,例如事故、交通拥堵或施工。InfluxDB 将存储来自传感器的时间序列数据,而 Zilliz 将存储图像数据并管理复杂查询的搜索索引。在这种情况下,您可以持续监控 InfluxDB 中的交通数据,例如平均速度和车辆计数。您可能还在 Milvus 中收集交通图像数据。当交通状况超出正常范围时,您会将此异常交通数据发送到 Milvus。然后,您在 Milvus 中执行相似性搜索以识别异常类型。
本文将重点介绍如何
- 生成虚拟交通数据
- 将其写入 InfluxDB v3
- 从 InfluxDB v3 中查询
- 规范化和向量化数据(本节的许多代码来自以下教程)
- 将其插入 Milvus
- 使用新的时间序列执行相似性搜索,以尝试识别它是否与过去的时间序列相似
开始步骤
首先,我们将从生成一些虚拟时间序列交通数据开始
def generate_sensor_data(anomaly_type, speed_limit, vehicle_count_range, avg_speed_range, rows=500):
"""
Generate a DataFrame with sensor data including vehicle count, avg speed, anomaly type, and timestamp.
Parameters:
- anomaly_type: string, the type of traffic anomaly (traffic, accident, road work)
- vehicle_count_range: tuple, the range (min, max) of vehicle count
- avg_speed_range: tuple, the range (min, max) of average speed
- rows: int, number of rows to generate
Returns:
- df: pandas DataFrame
# Generate data
np.random.seed(42) # For reproducible results
vehicle_counts = np.random.randint(vehicle_count_range[0], vehicle_count_range[1], size=rows)
avg_speeds = np.random.uniform(avg_speed_range[0], avg_speed_range[1], size=rows)
# Generate timestamps
start_time = datetime.now()
timestamps = [start_time + timedelta(seconds=5*i) for i in range(rows)]
# Create DataFrame
df = pd.DataFrame({
'Timestamp': timestamps,
'Vehicle Count': vehicle_counts,
'Average Speed': avg_speeds,
'Anomaly Type': anomaly_type,
'Speed Limit': speed_limit
})
return df
# Example usage
vehicle_count_range = (20, 40) # Configure the min and max vehicle count here
avg_speed_range = (20.0, 45.0) # Configure the min and max average speed here
df = generate_sensor_data("accident", 45, vehicle_count_range, avg_speed_range)
# Display the DataFrame
df.head() # Showing the first 5 rows for brevity
我们的数据看起来像这样: 

接下来,我们可以使用 InfluxDB v3 Python 客户端库将该 DataFrame 写入 InfluxDB 并进行查询。请参阅此示例了解如何操作。在真实世界的示例中,我们可能会从 MQTT 代理收集数据并订阅主题以将数据写入 InfluxDB。然后我们可以使用批处理任务来识别数据是否超出正常范围。
从 InfluxDB 写入和查询 Pandas DataFrames
本教程的目标不是强调如何从 InfluxDB 查询 Pandas DataFrames。假设您已经在 InfluxDB 实例中拥有一些数据,您偶尔会查询这些数据、将其插入 Milvus 并执行相似性搜索以帮助对其进行分类。
但是,您可以使用以下代码将 df 查询和写入 InfluxDB
from influxdb_client_3 import InfluxDBClient3
client = InfluxDBClient3(token="DATABASE_TOKEN",
host="HOST",
database="DATABASE_NAME")
client.write(bucket="DATABASE_NA<E", record=df, data_frame_measurement_name='generated_data', data_frame_tag_columns=['Anomaly Type', 'Speed Limit'], data_frame_timestamp_column='Timestamp')
query = "SELECT * FROM generated_data WHERE time >= now() - INTERVAL '90 days'"
pd = client.query(query=query, mode="pandas")
有关更多详细信息,请参阅 InfluxDB v3 Python 客户端库。
窗口化、规范化和向量化时间序列数据
规范化时间序列数据是数据分析中至关重要的预处理步骤,尤其是在处理来自不同来源和规模的时间序列数据或为机器学习模型准备数据时。规范化将不同的时间序列数据集带到共同的尺度,而不会扭曲值范围的差异或丢失信息。从本质上讲,它使您能够在相似性搜索中保留和比较时间序列数据的形状,而无需将比较限制在某个范围内。有几种规范化方法,例如 Min-Max 规范化、Z-Score 规范化(标准化)、十进制缩放等。在本示例中,我们将使用 Z-Score 规范化,它涉及重新缩放数据,使其平均值为 0,标准差为 1。
规范化的目标包括
- 统一性:规范化将数据带到共同的尺度,使其更容易比较和组合来自不同来源或具有不同单位的时间序列数据。当您想在向量中包含多个相关的时间序列时,这尤其有用。例如,如果监控天气模式,您可能希望使用湿度和温度时间序列数据创建一个多维向量。
- 提高模型性能:规范化的数据通常可以提高机器学习模型的性能或相似性搜索的准确性,因为它确保数据的尺度不会偏差学习过程。
- 兼容性:向量化和规范化的数据与一系列分析工具和算法兼容,从而实现更直接和有效的分析。
在我们规范化时间序列数据之后,我们可以对其进行向量化。向量化是一个将时间序列转换为适合机器学习模型、统计分析或其他计算过程(例如向量数据库中的存储)的格式的过程。它可能涉及诸如特征提取、分割/窗口化、编码、重塑和填充之类的步骤。在本教程中,我们将重点关注分割/窗口化,因为它使您能够捕获数据中的时间依赖性,并且可能是最重要的向量化类型。窗口化涉及将时间序列数据分割成更小的、固定大小的窗口或序列。您可以将每个段视为一个向量。
这是仅规范化我们的平均速度数据后的相应代码和 DataFrame 输出
# Set the window size (number of rows in each window)
window_size = 24
step_size = 10
# define windows
windows = [
df.iloc[i : i + window_size]
for i in range(0, len(df) - window_size + 1, step_size)
]
# Iterate through the windows & extract column values
start_times = [w["Timestamp"].iloc[0] for w in windows]
end_times = [w["Timestamp"].iloc[-1] for w in windows]
avg_speed_values = [w["Average Speed"].tolist() for w in windows]
vehicle_count_values = [w["Vehicle Count"].tolist() for w in windows]
# Create a new DataFrame from the collected data
embedding_df = pd.DataFrame(
{"start_time": start_times, "end_time": end_times, "vectors": avg_speed_values}
)
# Function to normalize the sensor column
def normalize_vector(vectors: list) -> list:
min_val = min(vectors)
max_val = max(vectors)
return (
[0.0] * len(vectors)
if max_val == min_val
else [(v - min_val) / (max_val - min_val) for v in vectors]
)
embedding_df["vectors"] = embedding_df["vectors"].apply(normalize_vector)
# Apply a lambda function to convert timestamps to Unix timestamp format.
embedding_df['start_time'] = embedding_df['start_time'].apply(lambda x: pd.Timestamp(x).timestamp()).astype(int)
embedding_df['end_time'] = embedding_df['end_time'].apply(lambda x: pd.Timestamp(x).timestamp()).astype(int)
embedding_df.head()

创建集合并将实体插入 Milvus
在 Milvus 的上下文中,嵌入是存储实体的核心组件。您可以使用嵌入执行相似性搜索,在其中您可以根据各种距离度量(例如,欧几里得距离、余弦相似度)定位最接近给定查询嵌入的实体。实体是一个记录,其中包含一个或多个嵌入(向量)以及可能的其他标量字段。
现在我们已经创建了窗口化和规范化的平均速度交通数据的嵌入,我们终于可以将数据或实体插入 Milvus。让我们首先创建一个实体。
# Data to insert from DataFrame into Milvus
data_to_insert = [
{"vector_field": v, "start_time_field": start, "stop_time_field": stop, "anomaly_type_field": anomaly_type}
for v, start, stop, anomaly_type in zip(embedding_df["vectors"], embedding_df["start_time"], embedding_df["end_time"], embedding_df["anomaly_type"])
]
# Including output of the data_to_insert or entities to understand the dictionary structure.
其中 data_to_insert[1] 看起来像
{'vector_field': [0.4152889075137363,
0.0,
0.5160786959257689,
0.9339400228588051,
0.9594734908121221,
0.005125718915339806,
1.0,
0.5317701130450202,
0.1734560938192518,
0.7041917323428484,
0.3683492576103222,
0.2146284560942277,
0.6996001992375626,
0.022975347039706807,
0.14385381806643827,
0.29834547817214996,
0.03032638050008518,
0.25497817191418676,
0.5015006484653414,
0.7528119491160616,
0.7916886403499066,
0.8741175973964925,
0.7576124843394686,
0.6639498473288101],
'start_time_field': 1710977934,
'stop_time_field': 1710978049,
'anomaly_type_field': 'accident'}
现在,我们准备将数据插入 Milvus。首先,我们导入客户端并建立连接。然后,我们可以定义模式并创建索引。Milvus 支持多种索引,每种索引都针对不同类型的向量搜索操作进行了优化。索引的选择取决于诸如数据集的大小、向量的维度、查询延迟要求以及搜索准确性和速度之间可接受的权衡等因素。在这种情况下,索引的目的是优化对与查询向量相似的向量的搜索。这被称为相似性搜索或最近邻搜索。
- Flat Index(平面索引):这是最简单的索引形式,本质上是一种暴力搜索,其中将查询向量与数据库中的每个向量进行比较以找到最接近的匹配项。虽然准确,但它也是计算量最大的。
- IVF(倒排文件)索引:此方法涉及基于相似性将向量聚类成组,然后在查询期间仅在最有希望的集群中搜索,从而显着减少所需的比较次数。
- HNSW(分层可导航小世界)索引:这创建了一个分层图结构,其中每个节点都是一个向量,边缘连接向量空间中彼此接近的节点。搜索从顶层向下导航此图,以有效地找到近邻。
- PQ(乘积量化)索引:此方法通过将向量分成更小的块并将每个块量化为有限数量的质心来压缩向量。它通过近似原始向量来实现更快的搜索和减少的存储。
- ANNOY(近似最近邻哦耶)索引:ANNOY 构建了一个二叉树森林,其中每棵树都是通过使用随机选择的超平面将数据集分成两部分来构建的。这种结构允许高效的近似搜索。
在本教程中,我们将使用 Flat Index,因为我们既不插入也不跨大型数据集进行搜索。虽然 Flat Index 对于大型数据集效率不高,但它可以提供最高的准确性,并且适用于较小数据集中的实时搜索或对极高准确性至关重要的情况。
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
import pandas as pd
# Establish a connection to Milvus server (adjust host and port as necessary)
connections.connect("default", host="127.0.0.1", port="19530")
In [17]:
# Define the schema for your collection
pk = FieldSchema(name="pk", dtype=DataType.INT64, is_primary=True, auto_id=True)
vector_field = FieldSchema(name="vector_field", dtype=DataType.FLOAT_VECTOR, dim=24)
start_time_field = FieldSchema(name="start_time_field", dtype=DataType.INT64)
stop_time_field = FieldSchema(name="stop_time_field", dtype=DataType.INT64)
anomaly_type_field = FieldSchema(name="anomaly_type_field", dtype=DataType.VARCHAR, max_length=100)
# Create a collection schema
schema = CollectionSchema(fields=[pk, vector_field, start_time_field, stop_time_field, anomaly_type_field], description="test collection")
# Define your collection name
collection_name = "example_collection"
# Fix: Correctly check if the collection exists
if not utility.has_collection(collection_name):
collection = Collection(name=collection_name, schema=schema)
print(f"Collection {collection_name} created.")
else:
collection = Collection(name=collection_name)
print(f"Collection {collection_name} already exists.")
# Insert the data into Milvus
insert_result = collection.insert(data_to_insert)
print("Insertion is successful, IDs assigned to the inserted entities:", insert_result.primary_keys)
# Create an index for better search performance
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128}
}
collection.create_index(field_name="vector_field", index_params=index_params)
print("Index created.")
# Load the collection into memory (before searching)
collection.load()
执行相似性搜索
现在,我们准备执行相似性搜索,以找到与其他时间序列最匹配的第一个嵌入或时间序列窗口。搜索将返回结果以及距离。我们可以使用 Milvus 从许多不同的相似性度量中进行选择。相似性度量(也称为距离度量或相似性度量)是一种数学函数,用于量化两个嵌入之间的相似性或不相似性。
我们选择欧几里得距离 (L2),因为它提供了向量之间相似性的直接且直观的度量。但是,请记住,我们正在使用先前插入的时间序列嵌入执行相似性搜索,并且我们的数据是随机的。因此,我们可以预期我们的嵌入结果将包括一个距离为 0 的相同嵌入。我们还可以预期我们的其余搜索结果将返回不相似的嵌入,因为我们插入了随机数据。
# Prepare for search
vectors_to_search = [data_to_insert[1]["vector_field"]] # Using the second vector for search
search_params = {
"metric_type": "L2",
"params": {"L2": 10},
}
result = collection.search(vectors_to_search, "vector_field", search_params, limit=3, output_fields=["vector_field", "anomaly_type_field"])
ids = []
# Display search results
for hits in result:
for hit in hits:
ids.append(hit.id)
print(f"ID: {hit.id}, Distance: {hit.distance}")
``
我们得到以下结果,证实了我们的假设: 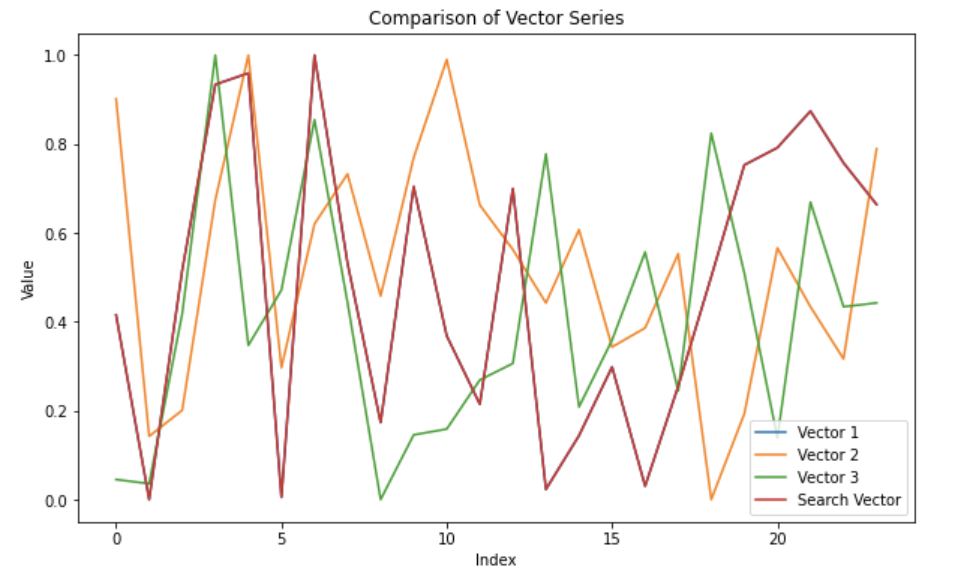
请注意,向量 1 和搜索向量如何重叠,因为差异最小的向量将是相同的向量,data_to_insert[1]。我们还执行 MAE(平均绝对误差)以量化相似性。请注意,在这种情况下,MAE 没有太多意义,因为我们生成了随机数据。在真实世界的示例中,您将比较代表事件并遵循一般模式或行为的时间序列数据。您还将在更多数据中进行搜索。
# Calculate MAE
mae = np.mean(np.abs(np.array(vectors_to_search[0]) - np.array(data_to_plot[1]["Vectors"])))
print(f"MAE: {mae}")
# A MAE of 0.3 indicates moderate to high dissimilarity which is expected when comparing random data.
MAE: 0.3145208857923114
最终想法
我希望本教程可以作为结合时间序列数据库(如 InfluxDB)和 Milvus 来识别时间序列数据中相似模式的样板。
从这里开始使用 InfluxDB Cloud 3.0。如果您需要帮助,请通过我们的社区站点或 Slack 频道联系我们。
