深入挖掘!Chronograf 中的数据探索
作者:Will Faurot / 产品
2015 年 12 月 15 日
导航至
概述
首先,在此处下载最新版本的 Chronograf。
我是 Chronograf 的 Will!在这篇文章中,我们将了解 Chronograf 如何帮助您探索 InfluxDB 中的数据。在开始之前,让我们先了解一下 InfluxDB、时间序列以及为什么数据探索在像 Chronograf 这样的可视化工具中如此重要。
InfluxDB 针对时间序列数据进行了优化。通常情况下,数据量非常庞大。在时间序列领域,规模至关重要。当您处理千兆字节、太字节甚至拍字节级别的数据集时,您可能需要浏览数百甚至 1000 多个不同的指标以及相关的元数据。这涉及大量内容。从一开始,Chronograf 的设计理念就是“向下钻取”数据。我们从大型数据集开始,通过选择指标和/或标签来向下过滤到更小的子集。
探索的构建块:指标和标签
在这篇文章中,我们将重点介绍指标和标签,但完整的 InfluxDB 术语表可在此处获取。
指标和标签是 InfluxDB 中两个基本的构建块,很可能也是您使用 Chronograf 构建查询的起点。在开始示例之前,让我们先对每个概念进行清晰的工作定义
- 指标 - 这些是您的度量标准。在这些示例中,我们使用 Telegraf,这是一个插件驱动的服务器代理,用于将指标报告到 InfluxDB 中。它可以跟踪系统指标,如 CPU 和磁盘使用率,以及 Redis 和 ElasticSearch 等服务。
- 标签 - 用于提供元数据的键/值对(例如,region=us-west,host=server01)。
向下钻取
我们认为在 Chronograf 中构建查询至少有两种常见的用例
- 您知道您在寻找什么。您心中已经有一个查询,只想看到数据的可视化表示。
- 您想要探索。也许您有 100 多个指标,想查看在一个区域中跟踪哪些指标。或者情况可能相反,您想查看哪些区域正在跟踪哪些指标。这种用例对我们来说非常重要,也是本文的重点。
查询的乐趣与益处
要点如下
- 选择指标可以减少可用标签的列表
- 选择标签可以减少可用指标的列表,以及随后的可用标签
在这些示例中,我们将重点介绍查询编辑器中的“按...筛选”窗格
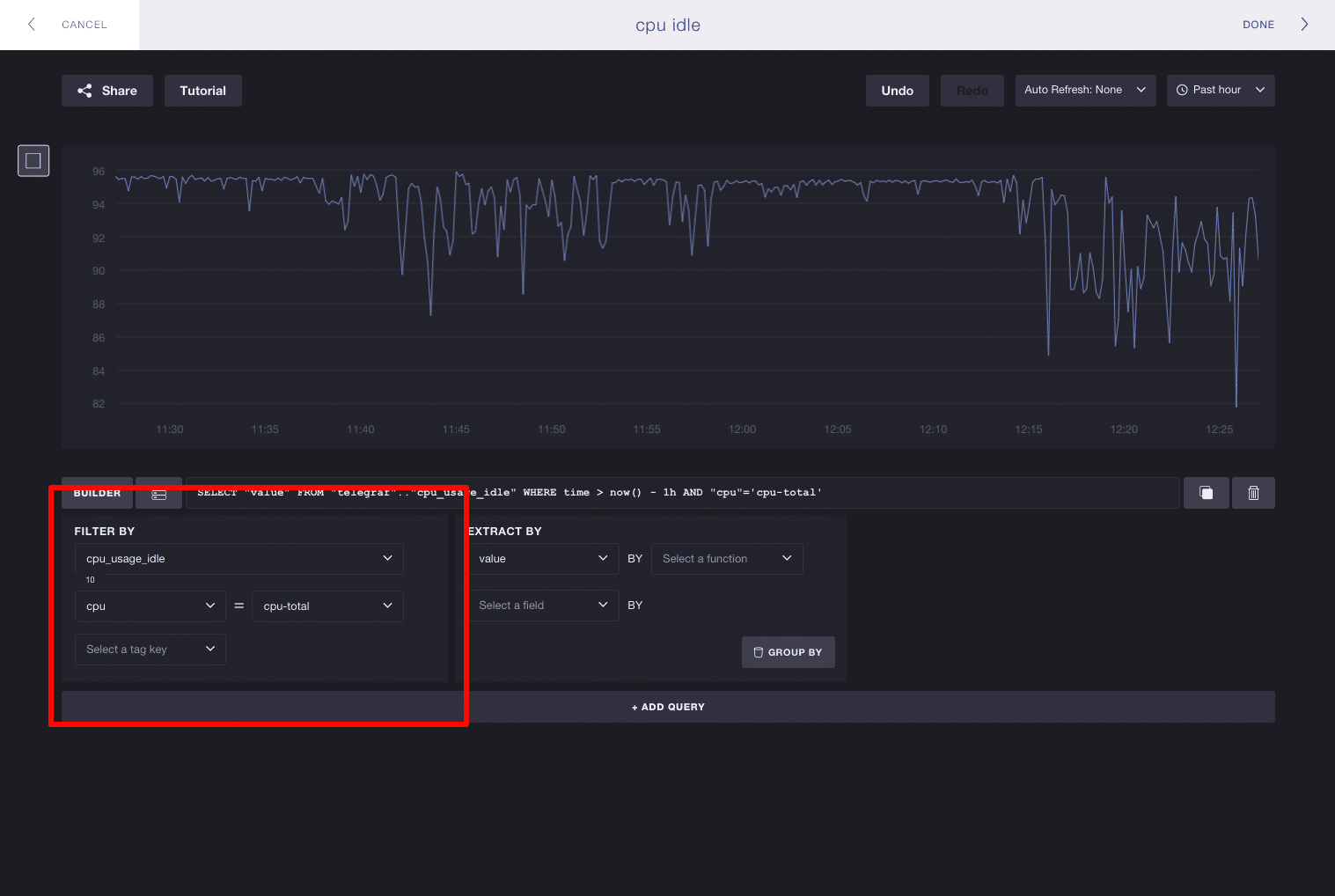
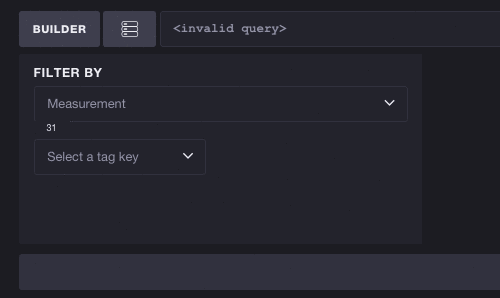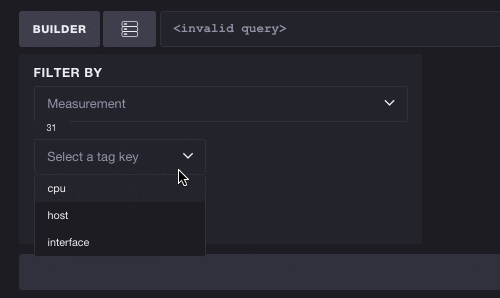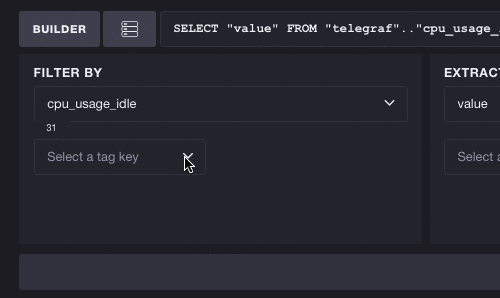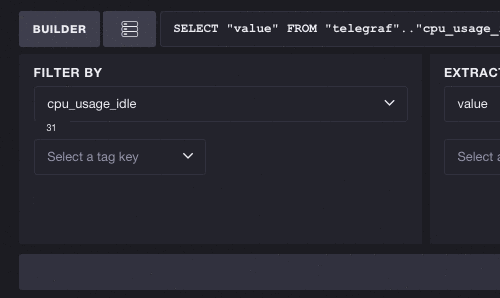
当您开始构建查询时,您将在“按...筛选”窗格中看到所有可用的指标和标签。在这些示例中,我使用 Telegraf 来跟踪系统指标,其中我有 31 个指标和 3 个标签键。在这里,我们将选择指标 cpu_usage_idle。可用标签键的列表从 3 个减少到 2 个,这意味着 cpu 和 host 是与 cpu_usage_idle 关联的唯二标签。
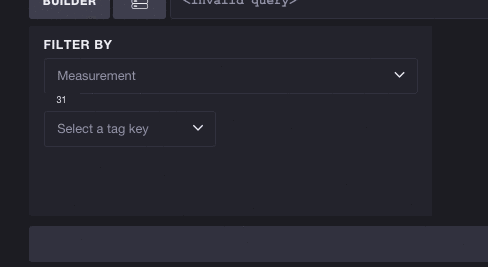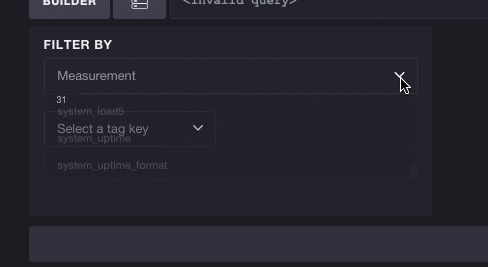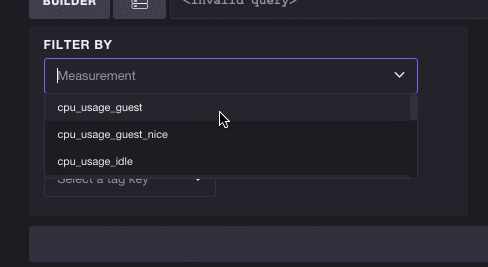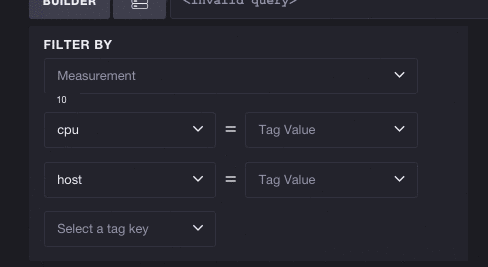
反过来也一样有效 - 您不必选择指标即可开始探索标签。每个标签键/值对都可能减少可用指标的列表。在这里,我们将查看完整的标签列表并选择键 cpu。您可以看到这会将可用指标的数量从 31 个减少到 10 个,这意味着我们可以更轻松地浏览基于 CPU 的指标。选择标签还会过滤后续标签。要选择的标签数量从 3 个减少到 2 个,这意味着标签键 host 是唯一可以与 cpu 并存的有效标签。
您也不必只选择一个标签。您可以随意继续选择标签,Chronograf 将继续就哪些后续指标和标签仍然有效进行探索做出明智的决策。
总结
就是这样!Chronograf 仍在积极开发中,我们非常欢迎任何反馈。请发送电子邮件至 [email protected]。
