最常见问题解答:InfluxDB 新手用户过于急切指南
作者:Anais Dotis-Georgiou / 产品, 用例, 开发者
2018年6月28日
导航至
您是否草率地启动了一个 InfluxDB 项目?您是否创建了一个数据库,但仍然不真正理解分片组持续时间与保留策略之间的关系?您是否开始意识到,在尝试使用这项技术之前,您几乎没有让自己消化文档?没有?好吧,也许只有我一个人难以让躁动不安的手指远离键盘。

作为一名新的 InfluxDB 用户,我想避免其他人遇到的最常见绊脚石。本博客包含最常见问题解答以及一些答案,以指导我们走上正确的道路。请注意:这些问题大多是开放式的。因此,请期待找到一系列考虑因素、资源和问题,这些因素、资源和问题可能会启发某人(咳嗽 咳嗽 我)仔细阅读文档。

在我们开始之前,请记住 InfluxData 的好心人已经尝试帮助我们。您可以在此处找到所有常见问题解答。我还强烈建议您查看这些 TL;DR InfluxDB 技术提示
- InfluxQL 查询示例
- 查询与写入布尔值 & 检查字段类型
- 相同的字段键 & 标签键,Chronograf 中现有的 Kapacitor TICKscripts & 更多
- 关于 SELECT 子句、字段键和选择器函数的 InfluxQL 查询解决方案
- 写入历史数据、在 InfluxDB 中设置时间戳精度以及查找您的日志文件
- 不需要的序列、保留策略、绑定参数
- 分片组持续时间建议
- 转换时间戳以使其可通过 InfluxDB 的 CLI 读取
1) 为什么我的保留策略没有删除我的数据?
这个问题表明,经验不足的用户没有意识到以下两件事之一:1) 保留策略到底是什么,以及 2) 在哪里可以找到默认设置。
如果您发现自己属于第一组,那么这里有一个插图可能会帮助您回忆起来。如果您仍然感到困惑,您可能需要查看分片和保留策略。
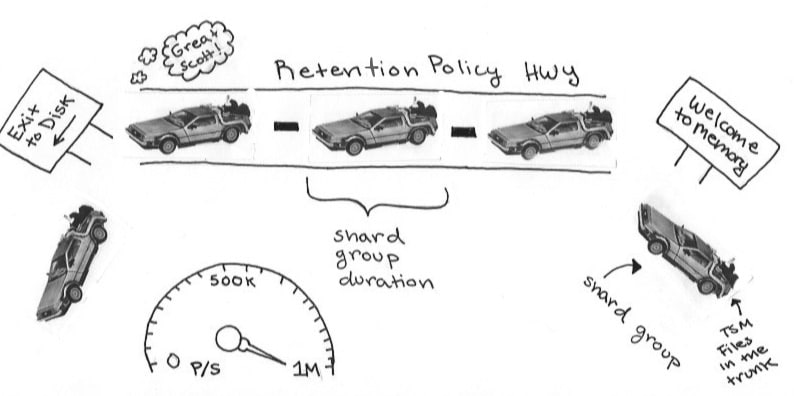
您已了解分片和 RP。您甚至遵循分片组建议和最佳实践。您的分片组
- 持续时间是您最长典型查询时间范围的两倍——这很有道理。您今天只对查询 4 天的流量数据感兴趣,但下周您发现您非常受欢迎。您想找出世界最终了解您的原因。您很感激您通过将分片组持续时间延长一倍来为自己提供了一些查询回旋余地。
- 每个分片组至少有 100,000 个点
- 每个序列至少有 1,000 个点
尽管您掌握了这些知识,但您的数据仍然存在!这是怎么回事?好吧,也许您没有正确配置数据库。现有的分片组和旧的 RP 可能会让您感到困惑。当您更改 RP 时,它仅适用于未来的分片组。在感到压力之前,请尝试让您的旧 RP 过期。此外,您不能删除部分分片。如果您更改了分片组持续时间,您可能必须等待旧分片过期才能看到您的更改生效。在您调查这些难题时,请注意 InfluxDB 的默认设置。
2) 为什么 InfluxDB 占用这么多内存?
让我们看看……您是否……
A. 在压缩期间查看内存使用情况?
是。稍后再回来,使用量有望下降。或者,如果您在本地计算机上运行 InfluxDB,您知道您的磁盘可以产生多少 IOPS 吗?您的机器可能无法处理您。
B. 执行不良查询?
是。 “SELECT * FROM mydb.” 不是探索您的模式的明智方法,尤其是在处理大量时序数据时。尝试以下任何一种查询。
从不。您是明星,您甚至正在运行连续查询来下采样您的数据。调整您的 Influx 环境很棘手,尤其是在没有企业级支持的情况下。但是,有一些很棒的工具可以让您监控和调整您的 Influx 环境。您可能从未听说过它们。它们被称为 InfluxDB 和 Telegraf。这是一个您可以按照执行此操作的教程。
我不这么认为。您是对的 - 您的查询可能不是问题所在。而是查看您的模式。您可能具有高基数(尤其是在您是企业用户的情况下)。
InfluxDB 可以处理正常数据集中的数十万个唯一标签。如果您使用的是 OSS 版本,并且您具有高基数(数百万个唯一测量值、标签集或字段键 = 高基数),您的模式设计可能很差。
例如,假设您要创建一个包含金融时序数据的数据库。一个好的模式设计将包括
- 一个包含标签和字段的测量值 ("financial_TS_data")
- 其中标签应包括工具名称 ("APPL"),
- 字段(“high”、“open”、“close”和“volume”)包含数据本身。
您是否遵循了建议的模式设计?
3) 如何获得返回给我的人类可读时间戳?
您的精度和纪元配置是否良好?您是否确保 InfluxDB 以RFC3339 格式返回时间戳?或者,在将时间戳写入 InfluxDB 之前,先在您首选的语言中转换时间戳。
4) 如何备份/恢复?
我警告过您会出现这种情况,所以请阅读此文档。
5) InfluxDB 如何处理写入/查询负载?
- 如此之多,以至于CERN 使用 OSS 版本来帮助他们寻找 Dog Particle?我不知道,听起来不错。

在阅读本文后,我希望您感觉自己更有准备执行您的时序项目。请通过在 Twitter 上 @InfluxDB 告诉我们进展情况。祝您好运!
