使用 Quix 模板将数据从 InfluxDB v2 同步到 v3
作者 Anais Dotis-Georgiou / 开发者
2024年4月8日
导航至
如果您是 InfluxDB v2 用户,并希望使用 InfluxDB v3,您可能想知道如何迁移数据。我们仍在开发迁移工具。在此期间,您可以使用 Quix 模板将数据从 InfluxDB v2 同步到 InfluxDB v3。
Quix 是一个完整的解决方案,用于构建、部署和监控实时应用程序和流数据管道,它使用 Python 在 Kafka 和 DataFrames 上进行抽象。Quix Streams 是一个开源 Python 流处理库,而 Quix Cloud 是一个完全托管的平台,用于在数据管道中部署和运行 Quix Streams 应用程序。您可以快速开始使用 Quix 提供的托管 Kafka 代理,或者您可以连接到自托管或托管的 Kafka 提供商。
该框架在设计时特别考虑了时间序列数据的处理,并且在云端和本地部署中均可使用。它消除了管理基础设施的麻烦,其用户界面简化了事件流和 ETL 过程的构建、操作和维护。
Quix 模板的同步功能类似于 Edge Data Replication 工具(该工具仍然允许您将数据写入 InfluxDB v3)。但是,Quix 管道构建在 Kafka 之上,因此它们可以扩展以适应高吞吐量用例,并受益于 Kafka 的可靠性和持久性。
您还可以扩展任何 Quix 管道,以包含任何额外的或必需的 ETL 任务。此模板创建一个 InfluxDB v2 源连接器,该连接器使用 Flux 查询您的 InfluxDB v2 实例,并将数据发送到 Influxv2-data 主题。然后,InfluxDB v3 连接器从 Kafka 主题中拉取记录,并将它们写入 InfluxDB v3。 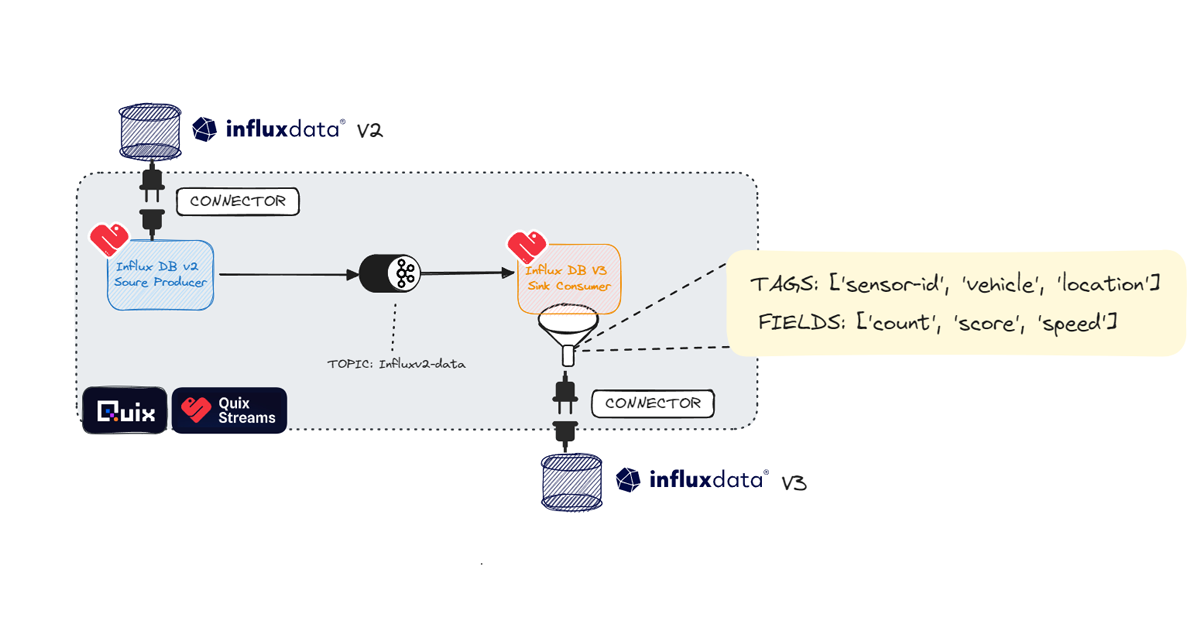
Quix 提供的 InfluxDB v2 到 v3 连接器的简单架构图。
要求
为了遵循本篇博客文章,您需要以下内容
请确保从您的 v2 和 v3 InfluxDB 账户中收集以下凭据
- 存储桶(您的 InfluxDB v2 源和 InfluxDB v3 目标存储桶)
- 令牌
- 组织 ID
- 您要从 v2 实例同步到 v3 实例的字段和标签
在本篇博客文章中,我们将演示如何使用 Telegraf CPU 输入插件将 CPU 数据写入从 InfluxDB v2 收集并写入到 InfluxDB v2。
配置和同步
开始使用这个 Quix 模板非常简单。您只需点击 UI 中的“克隆此项目”按钮。  您将被重定向到您的 Quix 账户。从那里导入项目。
您将被重定向到您的 Quix 账户。从那里导入项目。 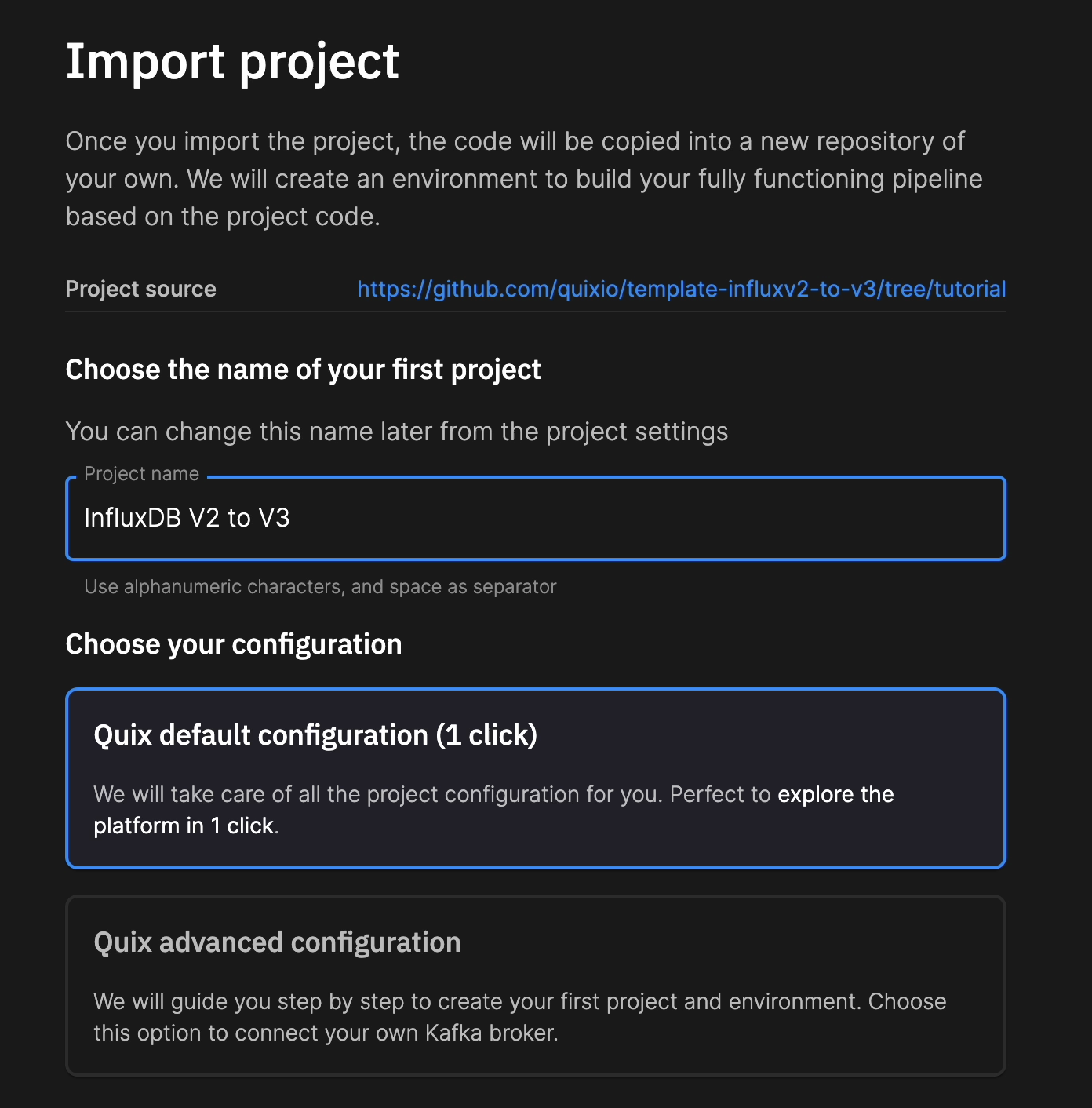 导入并创建项目后,您可以从“管道”页面同步您的环境。Quix 使用管道即代码,通过 YAML 文件实现管道版本控制。点击“同步环境”以将您的 InfluxDB v2 和 v3 令牌添加为密钥。
导入并创建项目后,您可以从“管道”页面同步您的环境。Quix 使用管道即代码,通过 YAML 文件实现管道版本控制。点击“同步环境”以将您的 InfluxDB v2 和 v3 令牌添加为密钥。 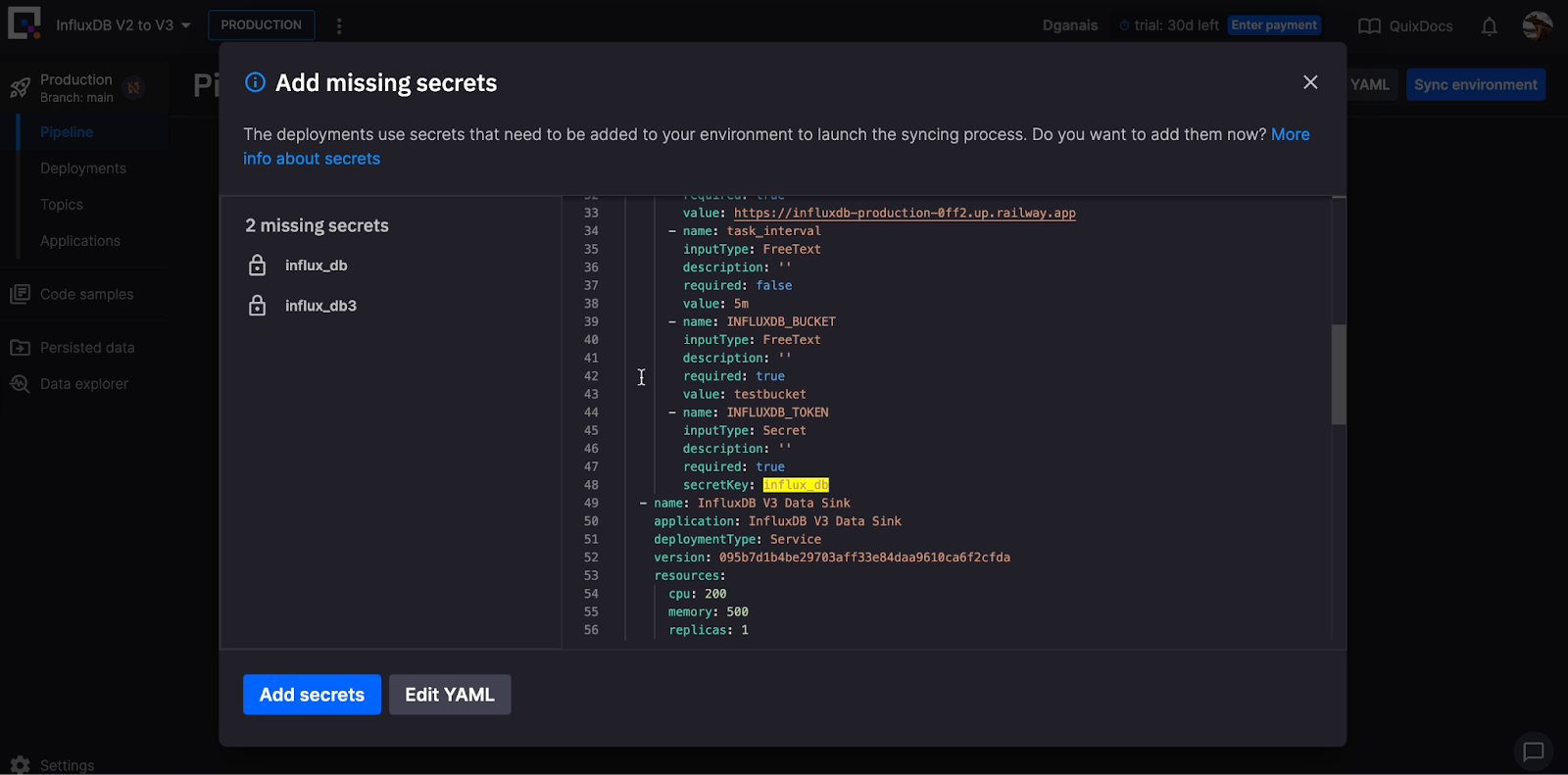 管道中的服务现在将启动。点击每个服务以编辑部署。在“环境变量”部分添加您的存储桶和查询信息以及任务间隔,并在“部署设置”下添加有关您要查询的数据的详细信息。
管道中的服务现在将启动。点击每个服务以编辑部署。在“环境变量”部分添加您的存储桶和查询信息以及任务间隔,并在“部署设置”下添加有关您要查询的数据的详细信息。 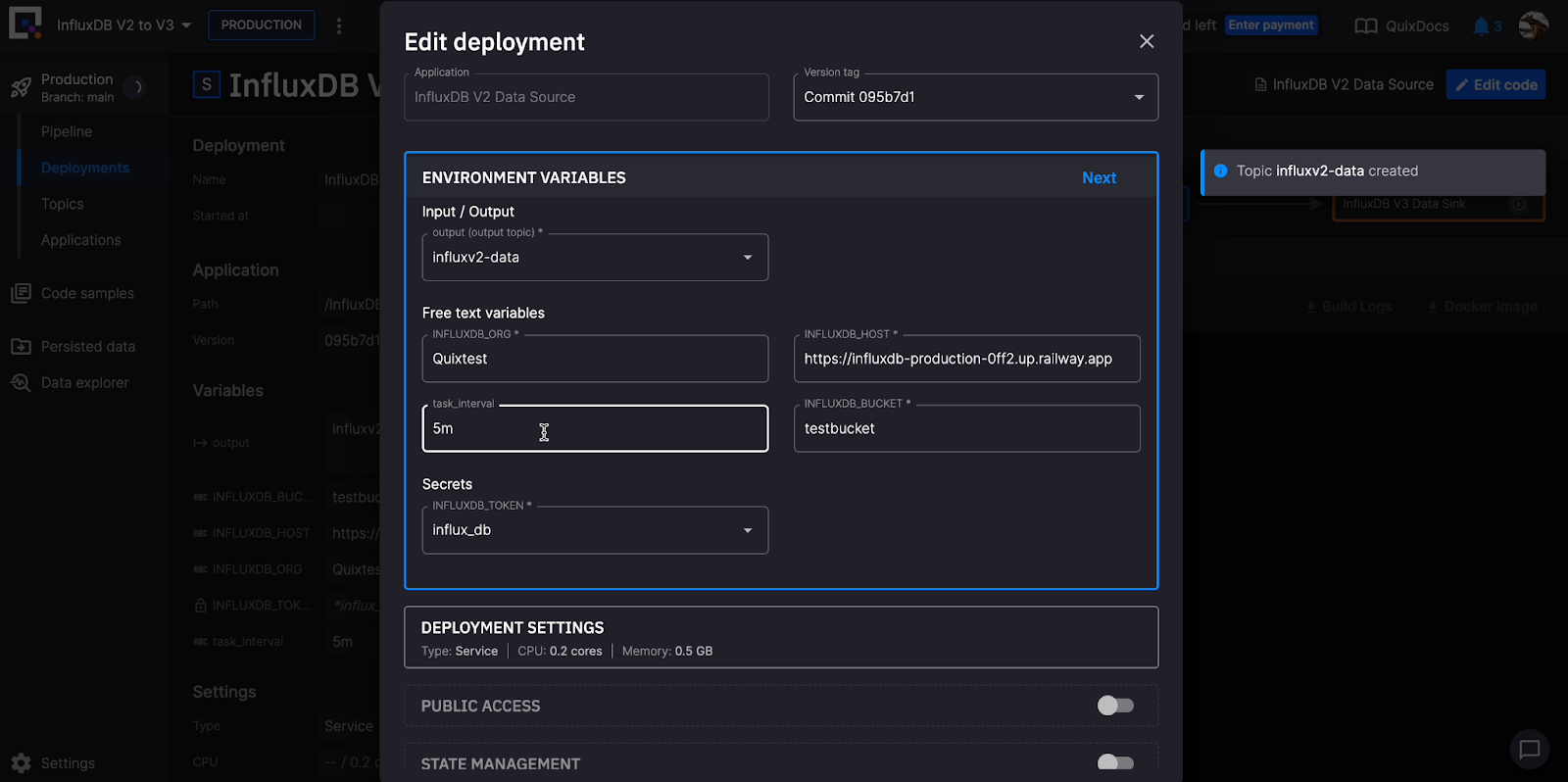 点击“日志”选项卡以验证您的 Flux 查询是否正确,以便您可以成功地将数据从您的 InfluxDB v2 实例复制到您的 InfluxDB v3 Cloud 账户。
点击“日志”选项卡以验证您的 Flux 查询是否正确,以便您可以成功地将数据从您的 InfluxDB v2 实例复制到您的 InfluxDB v3 Cloud 账户。 
最终想法
我希望本教程能帮助您开始使用 InfluxDB v2 到 v3 同步 Quix 模板。非常感谢 Quix 团队持续为 InfluxDB 社区提供解决方案。我也想鼓励您查看其他一些 InfluxDB Quix 模板和项目,包括
- 事件检测和警报功能,采用 InfluxDB 和 PagerDuty:在本教程中,您将学习如何使用 Quix Cloud、Quix Streams、InfluxDB 和 PagerDuty 创建 CPU 过载警报管道。
- 预测性维护:此项目模板包含数据管道和仪表板的完整源代码,说明了预测性维护如何在实践中工作。它使用时间序列预测算法,模拟由一组 3D 打印机生成的数据,并预测哪些打印机将在打印完成前发生故障。
- Quix 拯救假期:本项目提供了一个如何使用 Quix 和 InfluxDB 3.0 构建机器异常检测数据管道的示例。此仓库包含作为项目的完整数据管道,但不包括数据模拟器(更多详情请参阅入门指南)。
从此处开始使用 InfluxDB Cloud 3.0。如果您需要帮助,请联系我们的社区网站或 Slack 频道。
