开始使用 Python 和 InfluxDB
作者: 社区 / 产品, 用例, 开发者, 入门指南
2022 年 3 月 14 日
导航至
本文由 Pravin Rahul Banerjee 撰写,最初由 The New Stack 发布。向下滚动查看作者的照片和简介。
尽管时间序列数据可以存储在 MySQL 或 PostgreSQL 数据库中,但这效率不高。如果您想存储每分钟都在变化的数据(每年超过 50 万个数据点!),这些数据可能来自数千个不同的传感器、服务器、容器或设备,那么您不可避免地会遇到可扩展性问题。在使用关系数据库时,查询或对这些数据执行聚合也会导致性能问题。
另一方面,时间序列数据库 (TSDB) 经过优化,可以存储时间序列数据点。这在以下情况下尤其有用:
- 分析股票价格的金融趋势。
- 销售预测。
- 监控 API 或 Web 服务的日志和指标。
- 出于安全目的,监控来自汽车或飞机的传感器数据。
- 跟踪物联网设备(如智能电网)中的功耗。
- 跟踪运动员在比赛期间的生命体征和表现。
InfluxDB 创建了一个开源的 时间序列数据库 ,使开发人员更容易处理 时间序列数据。本文将向您展示如何使用 Python 设置 InfluxDB,并使用 Yahoo Finance API 获取股票数据。
您可以在 此存储库中访问本教程中编写的所有代码。
为什么使用 InfluxDB?
InfluxDB 附带一个预构建的仪表板,您可以在其中分析时间序列数据,而无需太多准备工作。而且,别忘了它 性能优于 Elasticsearch 和 Cassandra。
它有一个免费的开源版本,您可以在本地运行,还有一个云版本,它 支持主要的云服务 ,如 AWS、GCP 和 Azure。
使用 Python 设置 InfluxDB
开始之前,请确保您的计算机上已安装 Python 3.6 或更高版本 。您还需要一个虚拟环境。本文使用 venv,但您也可以使用 conda、pipenv 或 pyenv。
最后,需要一些 Flux 查询的经验。
本指南使用模块 influxdb-client-python 与 InfluxDB 交互。该库仅支持 InfluxDB 2.x 和 InfluxDB 1.8+,并且需要 Python 3.6 或更高版本。
都准备好了吗?让我们开始安装和连接客户端库。
如果您的计算机上安装了 Docker,您可以简单地使用以下命令运行 InfluxDB 的 Docker 镜像
docker run --name influxdb -p 8086:8086 influxdb:2.1.0
如果您没有 Docker,请在此处下载适用于您操作系统的软件并安装它。如果您在 Mac 上运行 InfluxDB,可以使用 Homebrew 安装它
brew install influxdb
如果您正在运行 Docker 镜像,您可以直接访问 localhost 8086。但是,如果您下载并安装了该软件,则需要在命令行中输入以下内容
influxd
您应该在 localhost 8086 上看到以下屏幕

单击开始使用,这将重定向到以下页面
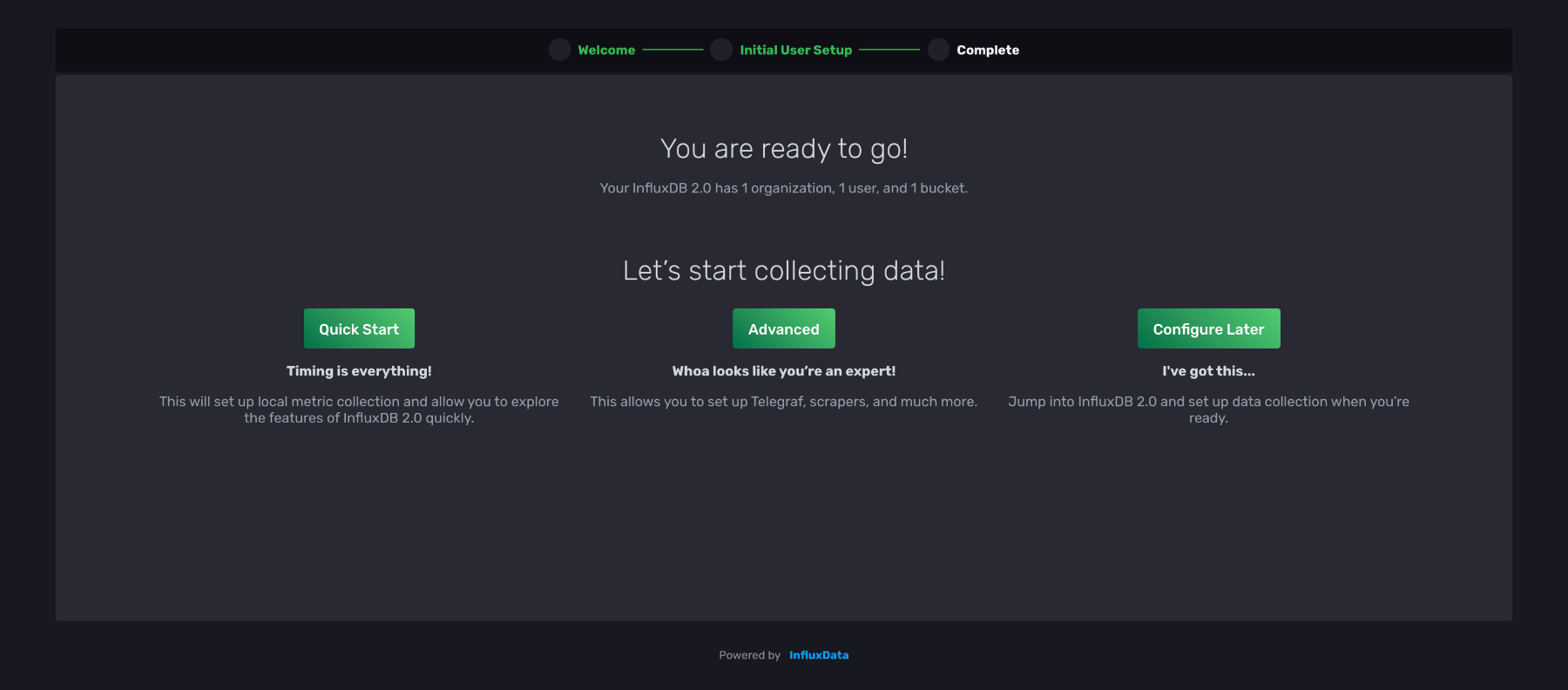
在本教程中,选择快速启动并在本页上输入您的信息
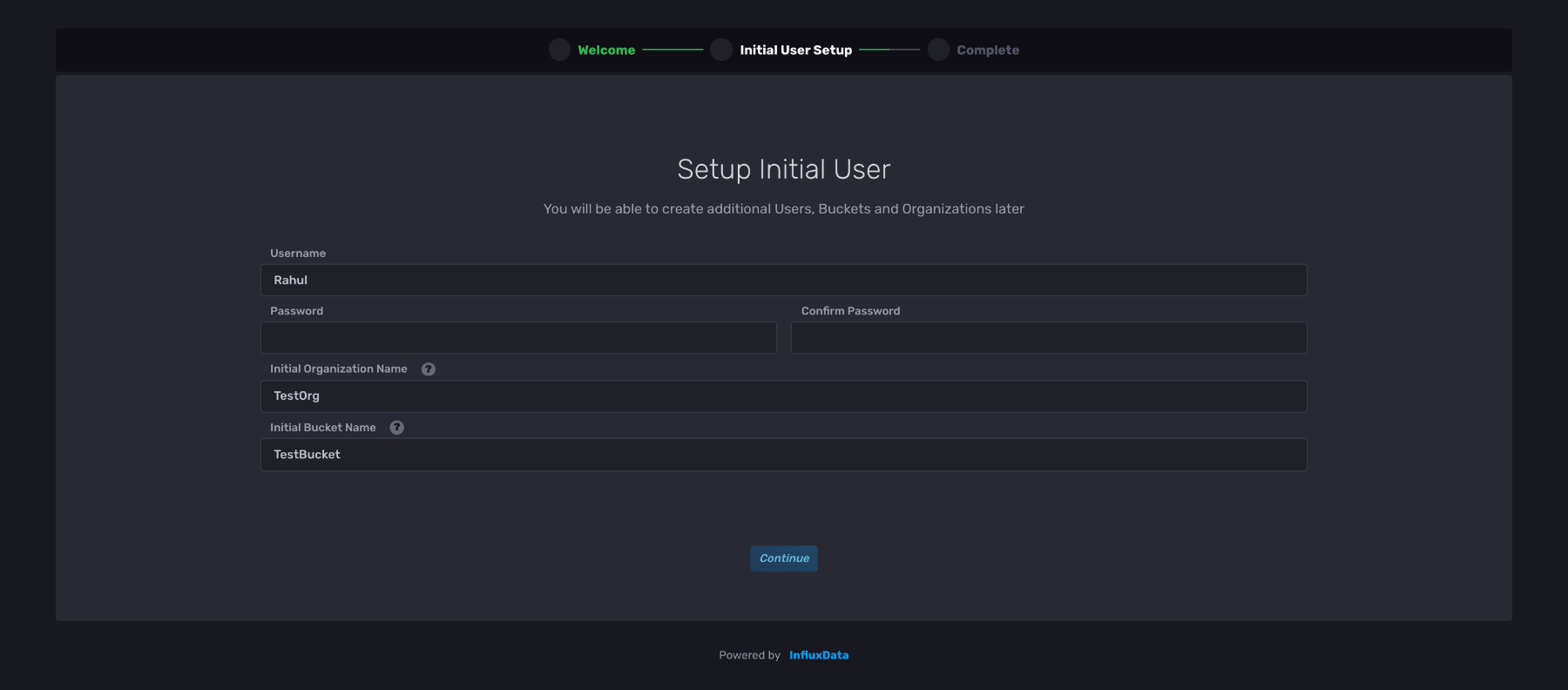
您也可以稍后创建组织和存储桶,但现在,只需为这些字段选择一个简单的名称即可。
注册后,您应该会进入仪表板页面。单击加载您的数据,然后选择 Python 客户端库。

您现在应该看到以下屏幕

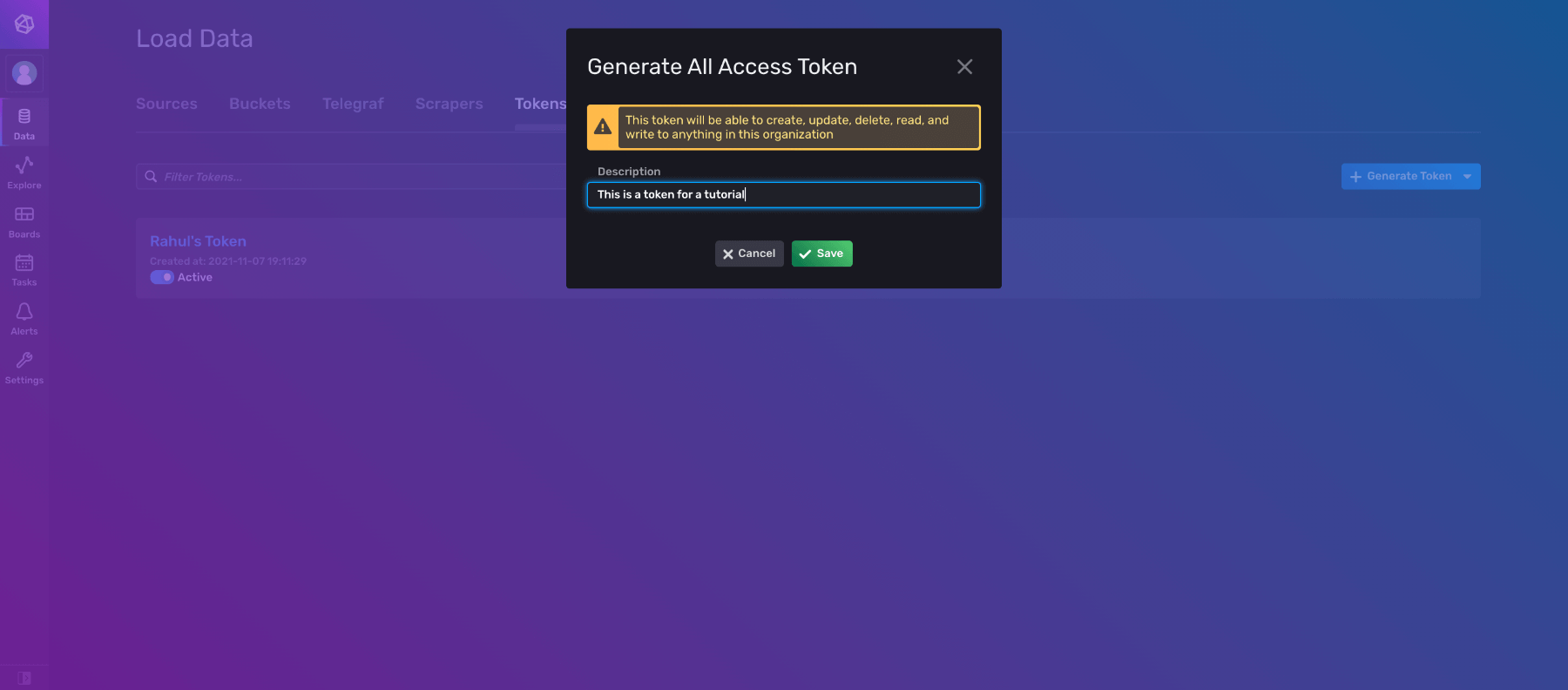
在令牌下,应该已经列出了一个令牌。但是,如果您愿意,您可以为此教程生成一个新令牌。单击生成令牌并选择所有访问令牌,因为您稍后将在教程中更新和删除数据。
请注意,InfluxDB 此时会发出警告,但您现在可以忽略它。
现在,您必须设置一个 Python 虚拟环境。为教程创建一个新文件夹
mkdir influxDB-Tutorial
然后将您的目录更改为新文件夹
cd influxDB-Tutorial
创建一个虚拟环境
python3 -m venv venv
激活它。
source venv/bin/activate
最后,安装 InfluxDB 的客户端库
pip install influxdb-client
创建一个名为 __init.py__ 的新文件,然后返回到 InfluxDB UI
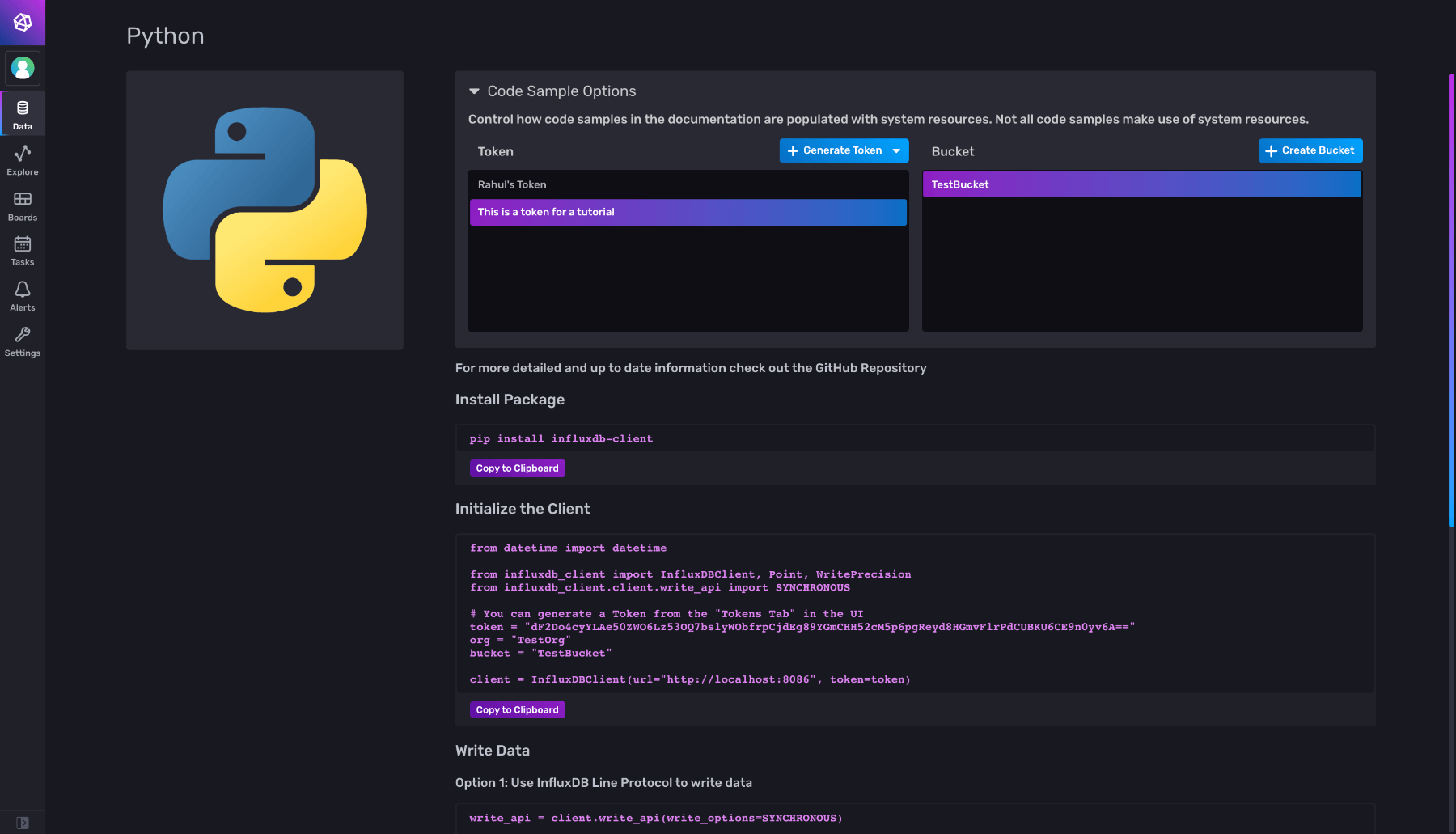
选择适当的令牌和存储桶,然后复制初始化客户端下的代码片段,并将其粘贴到您的 Python 文件中。如果您更改令牌/存储桶选择,代码片段将自动更新。
接下来,运行您的 Python 文件
python3 __init__.py
如果在终端中未显示错误消息,则您已成功连接到 InfluxDB。
为了遵循最佳实践,您可以将凭据存储在 .env 文件中。创建一个名为 .env 的文件并存储以下信息
TOKEN = 'YOUR TOKEN'
ORG = 'YOUR ORG NAME'
BUCKET = 'YOUR BUCKET NAME'然后安装 python-dotenv 模块以读取 .env 变量
pip3 install python-dotenv
最后,更新您的 Python 文件以从 .env 文件加载数据
from datetime import datetime
from dotenv import load_dotenv, main
import os
from influxdb_client import InfluxDBClient, Point, WritePrecision
from influxdb_client.client.write_api import SYNCHRONOUS
load_dotenv()
# You can generate a Token from the "Tokens Tab" in the UI
token = os.getenv('TOKEN')
org = os.getenv('ORG')
bucket = os.getenv('BUCKET')
client = InfluxDBClient(url="https://:8086", token=token)请注意,如果您使用的是 InfluxDB Cloud 帐户,则需要更改 url 参数。URL 将取决于您选择的云区域。云 URL 可以在此处的文档中找到。
导入 DateTime 模块和 InfluxDB 库的行将在本教程的后面部分中需要。最好将所有导入语句放在开头。但是,如果您选择这样做,也可以在必要时导入它们。
或者,您可以将凭据存储在扩展名为 .ini 或 .toml 的文件中,并使用 from_config_file 函数连接到 InfluxDB。
使用 influxdb-client-python 进行 CRUD 操作
本文使用了 Python 中的 yfinance 模块来收集一些历史股票数据。使用以下命令安装它
pip install yfinance
您可以使用以下代码片段来获取数据
import yfinance as yf
data = yf.download("MSFT", start="2021-01-01", end="2021-10-30")
print(data.to_csv())确保将文件名参数传递给 to_csv 方法;这将把 CSV 本地存储,以便您稍后可以读取数据。
或者,您可以从 GitHub 存储库获取 CSV 文件。
接下来,创建一个类并将 CRUD 操作添加为其方法
class InfluxClient:
def __init__(self,token,org,bucket):
self._org=org
self._bucket = bucket
self._client = InfluxDBClient(url="https://:8086", token=token)如果您使用的是 InfluxDB 的云实例,您将需要将 URL 参数替换为正确的 云区域。
要创建类的实例,请使用此命令
IC = InfluxClient(token,org,bucket)
写入数据
InfluxDBClient 有一个名为 write_api 的方法,用于将数据写入数据库。以下是此方法的代码片段
from influxdb_client.client.write_api import SYNCHRONOUS, ASYNCHRONOUS
def write_data(self,data,write_option=SYNCHRONOUS):
write_api = self._client.write_api(write_option)
write_api.write(self._bucket, self._org , data,write_precision='s')InfluxDBClient 支持异步和同步写入,您可以根据需要指定写入类型。
有关异步写入的更多信息,请参阅 如何在 influxdb-client 中使用 Asyncio。
data 参数可以通过三种不同的方式写入,如下所示
行协议字符串
# Data Write Method 1
IC.write_data(["MSFT,stock=MSFT Open=62.79,High=63.84,Low=62.13"])请注意,字符串必须遵循特定格式
measurementName,tagKey=tagValue fieldKey1="fieldValue1",fieldKey2=fieldValue2 timestamp
在 tagValue 和第一个 fieldKey 之间有一个空格,在最后一个 fieldValue 和 timeStamp 之间有另一个空格。在解析时,这些空格用作分隔符;因此,您必须按照上面显示的方式对其进行格式化。另请注意,在这种情况下,我假设第一个字段值 fieldValue1 是一个字符串,而 fieldValue2 是一个数字。因此,fieldValue1 应该用引号引起来。
另请注意,时间戳是可选的。如果未提供时间戳,InfluxDB 将使用其主机系统的系统时间 (UTC)。您可以在此处阅读有关 行协议的更多信息。
数据点结构
# Data Write Method 2
IC.write_data(
[
Point('MSFT')
.tag("stock","MSFT")
.field("Open",62.79)
.field("High",63.38)
.field("Low",62.13)
.time(int(datetime.strptime('2021-11-07','%Y-%m-%d').timestamp()))
],
)如果您不想处理行协议字符串中的格式,可以使用 Point() 类。这可确保您的数据正确序列化为行协议。
字典样式
# Data Write Method 3
IC.write_data([
{
"measurement": "MSFT",
"tags": {"stock": "MSFT"},
"fields": {
"Open": 62.79,
"High": 63.38,
"Low": 62.13,
},
"time": int(datetime.strptime('2021-11-07','%Y-%m-%d').timestamp())
},
{
"measurement": "MSFT_DATE",
"tags": {"stock": "MSFT"},
"fields": {
"Open": 62.79,
"High": 63.38,
"Low": 62.13,
},
}
],write_option=ASYNCHRONOUS)在这种方法中,您传递两个数据点并将写入选项设置为 ASYNCHRONOUS。这对于 Python 来说很友好,因为数据是作为字典传递的。
所有不同的数据写入方式都合并在下面的要点中
# Data Write Method 1
IC.write_data(["MSFT_2021-11-07_Line_Protocol,stock=MSFT Open=62.79,High=63.84,Low=62.13"])
# Data Write Method 2
IC.write_data(
[
Point('MSFT_2021-11-07_Point_Class')
.tag("stock","MSFT")
.field("Open",65)
.field("High",63.38)
.field("Low",62.13)
.time(int(datetime.strptime('2021-11-07','%Y-%m-%d').timestamp()))
],
)
# Data Write Method 3
IC.write_data([
{
"measurement": "MSFT_2021-11-07_Dictionary_Method",
"tags": {"stock": "MSFT"},
"fields": {
"Open": 66,
"High": 63.38,
"Low": 62.13,
},
"time": int(datetime.strptime('2021-11-07','%Y-%m-%d').timestamp())
},
{
"measurement": "MSFT_DATE",
"tags": {"stock": "MSFT"},
"fields": {
"Open": 67,
"High": 63.38,
"Low": 62.13,
},
}
],write_option=ASYNCHRONOUS)接下来,插入 MSFT 股票和 AAPL 股票的所有数据。由于数据存储在 CSV 文件中,因此您可以使用第一种方法——行协议字符串——来写入数据
import csv
MSFT_file = open('Data/MSFT.csv')
csvreader = csv.reader(MSFT_file)
header = next(csvreader)
rows = []
for row in csvreader:
date,open,high,low = row[0],row[1],row[2],row[3]
line_protocol_string = ''
line_protocol_string+=f'MSFT_{date},'
line_protocol_string+=f'stock=MSFT '
line_protocol_string+=f'Open={open},High={high},Low={low} '
line_protocol_string+=str(int(datetime.strptime(date,'%Y-%m-%d').timestamp()))
rows.append(line_protocol_string)
IC.write_data(rows)您可以通过更改文件路径并将字符串从 MSFT 更改为 AAPL 来插入 AAPL 股票的数据
AAPL_file = open('Data/AAPL.csv')
csvreader = csv.reader(AAPL_file)读取数据
InfluxDBClient 还有一个名为 query_api 的方法,可用于读取数据。您可以使用查询来实现各种目的,例如根据特定日期过滤数据、在时间范围内聚合数据、查找时间范围内的最高/最低值等等。它们类似于您在 SQL 中使用的查询。从 InfluxDB 读取数据时,您需要使用查询。
以下代码是我们类的读取方法
def query_data(self,query):
query_api = self._client.query_api()
result = query_api.query(org=self._org, query=query)
results = []
for table in result:
for record in table.records:
results.append((record.get_value(), record.get_field()))
print(results)
return results在这里,它接受一个查询,然后执行它。查询的返回值是与您的查询匹配的 Flux 对象集合。Flux 对象具有以下方法
.get_measurement()
.get_field()
.values.get("<your tags>")
.get_time()下面显示了两个查询示例,演示了 query_data 函数的实际应用。第一个查询返回自 2021 年 10 月 1 日以来 MSFT 股票的最高值,第二个查询返回 2021-10-29 MSFT 股票的最高值。
'''
Return the High Value for MSFT stock for since 1st October,2021
'''
query1 = 'from(bucket: "TestBucket")\
|> range(start: 1633124983)\
|> filter(fn: (r) => r._field == "High")\
|> filter(fn: (r) => r.stock == "MSFT")'
IC.query_data(query1)
'''
Return the High Value for the MSFT stock on 2021-10-29
'''
query2 = 'from(bucket: "TestBucket")\
|> range(start: 1633124983)\
|> filter(fn: (r) => r._field == "High")\
|> filter(fn: (r) => r._measurement == "MSFT_2021-10-29")'
IC.query_data(query2)请确保根据需要在查询开头更改存储桶名称。在我的例子中,我的存储桶名称是TestBucket。
更新数据
与 Write 和 Query API 不同,InfluxDB 没有 Update API。以下声明取自他们关于如何处理重复数据点的文档。
对于具有相同测量名称、标签集和时间戳的点,InfluxDB 创建旧字段集和新字段集的并集。对于任何匹配的字段键,InfluxDB 使用新点的字段值
要更新数据点,您需要具有名称、标签集和时间戳,并简单地执行写入操作。
删除数据
您可以使用 delete_api 删除数据。以下是一些演示如何删除数据的代码
def delete_data(self,measurement):
delete_api = self._client.delete_api()
start = "1970-01-01T00:00:00Z"
stop = "2021-10-30T00:00:00Z"
delete_api.delete(start, stop, f'_measurement="{measurement}"', bucket=self._bucket, org=self._org)删除函数需要数据点的测量值。以下代码显示了删除函数的简单用例
'''
Delete Data Point with measurement = 2021-10-29
'''
IC.delete_data("MSFT_2021-10-29")
'''
Return the High Value for the MSFT stock on 2021-10-29
'''
query2 = 'from(bucket: "TestBucket")\
|> range(start: 1633124983)\
|> filter(fn: (r) => r._field == "High")\
|> filter(fn: (r) => r._measurement == "MSFT_2021-10-29")'
IC.query_data(query2)InfluxDB 的文档包含一份写入数据的最佳实践列表。还有一些数据布局和模式设计最佳实践,您应该遵循这些实践以获得最佳结果。
时间序列数据库的一些实际用例
本文研究了 TSDB 的一个简单用例,即存储股票值,以便您可以分析历史股价并预测未来值。但是,您也可以处理物联网设备、销售数据以及任何其他随时间变化的数据序列。
其他一些实际用例包括
结论
希望本指南使您能够设置自己的 InfluxDB 实例。您学习了如何构建一个简单的应用程序,以使用 InfluxDB 的 Python 客户端库执行 CRUD 操作,但如果您想仔细查看任何内容,可以在此处找到包含完整源代码的存储库。
查看 InfluxDB 的开源 TSDB。它拥有包括 Python、C++ 和 JavaScript 在内的十种编程语言的客户端库,并且还拥有许多内置的可视化工具,因此您可以准确了解您的数据在做什么。
关于作者

Rahul 是一名计算机工程专业的学生,他喜欢摆弄不同的库/API。
