Quix 社区插件,用于 InfluxDB:构建您自己的流式任务引擎
作者:Jay Clifford / 产品
2023年10月18日
导航至
随着我们 InfluxDB 3.0 OSS 的计划制定,我和 DevRel 团队的其他成员一直在积极寻找生态系统平台,这些平台将成为 InfluxDB 未来合乎逻辑的集成。Quix 就是其中一个平台!
Quix 是一个全面的解决方案,专为使用 Python 创建、启动和管理事件流应用程序而定制。如果您希望实时筛选时间序列或事件数据以进行即时决策,Quix 是您的理想之选。我们发现它为 InfluxDB 3.0 提供了一个出色的替代任务引擎。如果您想查看我们与 Quix 合作创建异常检测管道的初始项目,请查看这篇博客。
在此基础上,我们非常高兴地宣布发布两个用于 Quix 的 InfluxDB 社区插件。在这篇博文中,我们将分解每个插件的功能,并提供一个您可以亲自尝试的用例示例。
插件
社区贡献包括两个插件
- InfluxDB Source:此插件允许用户使用 Apache Arrow Flight 在用户定义的间隔查询 InfluxDB 3.0,将数据解析为 pandas DataFrame,并发布到 Quix 流主题。
- InfluxDB Destination:此插件允许用户从 Quix 流主题摄取 DataFrame,并在将数据写入 InfluxDB 实例之前定义其结构(测量和标签)(此插件与 InfluxDB 2.x 和 3.x 兼容)。
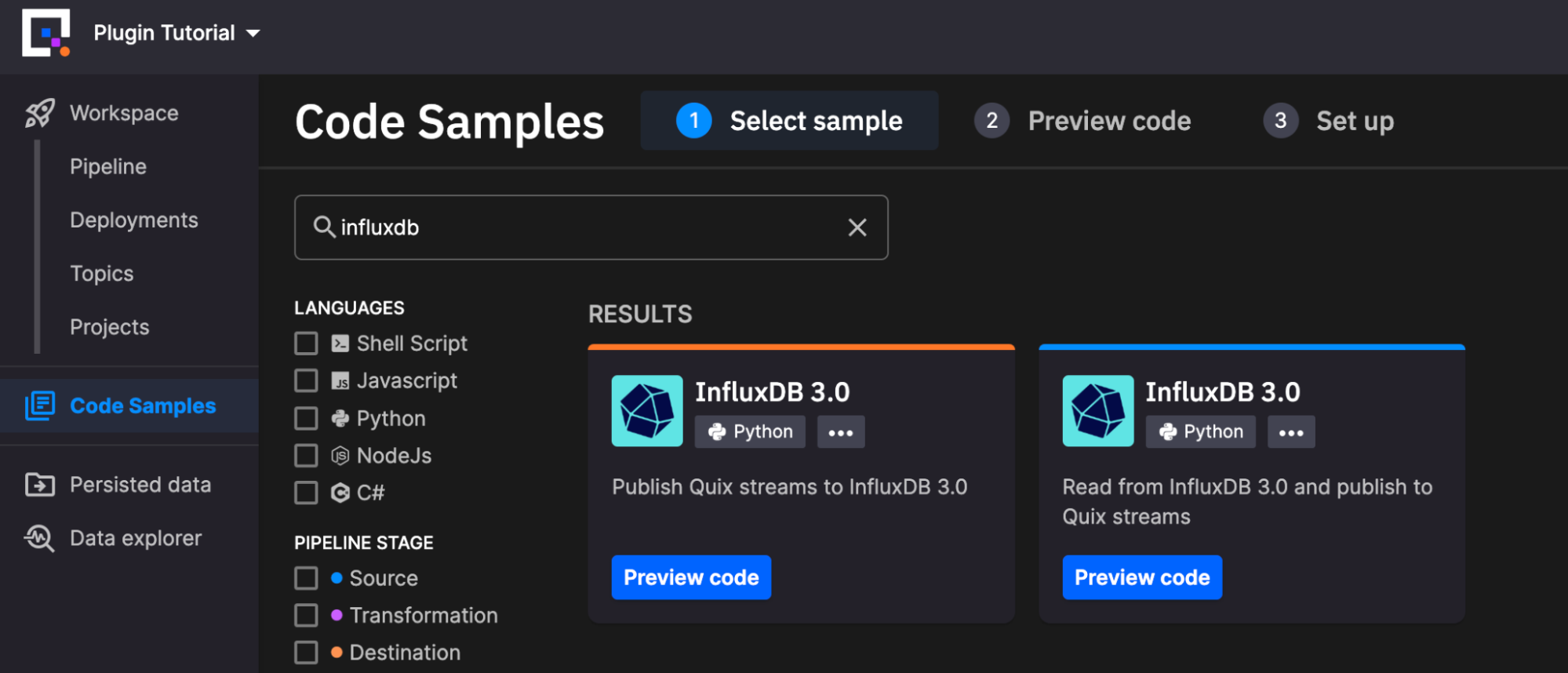
您可以通过导航到左侧菜单中的“代码示例”并在 Quix 平台中搜索“InfluxDB”来找到这些插件。让我们分别看一下每个插件的配置。
InfluxDB Source
InfluxDB Source 是一个基于 Python 的插件,因此在 Quix 环境中,它可以根据您的需求进行高度定制。您可以在部署前在其基于云的编辑器中简单地编辑 Python 脚本。让我们从“开箱即用”插件的概述开始。
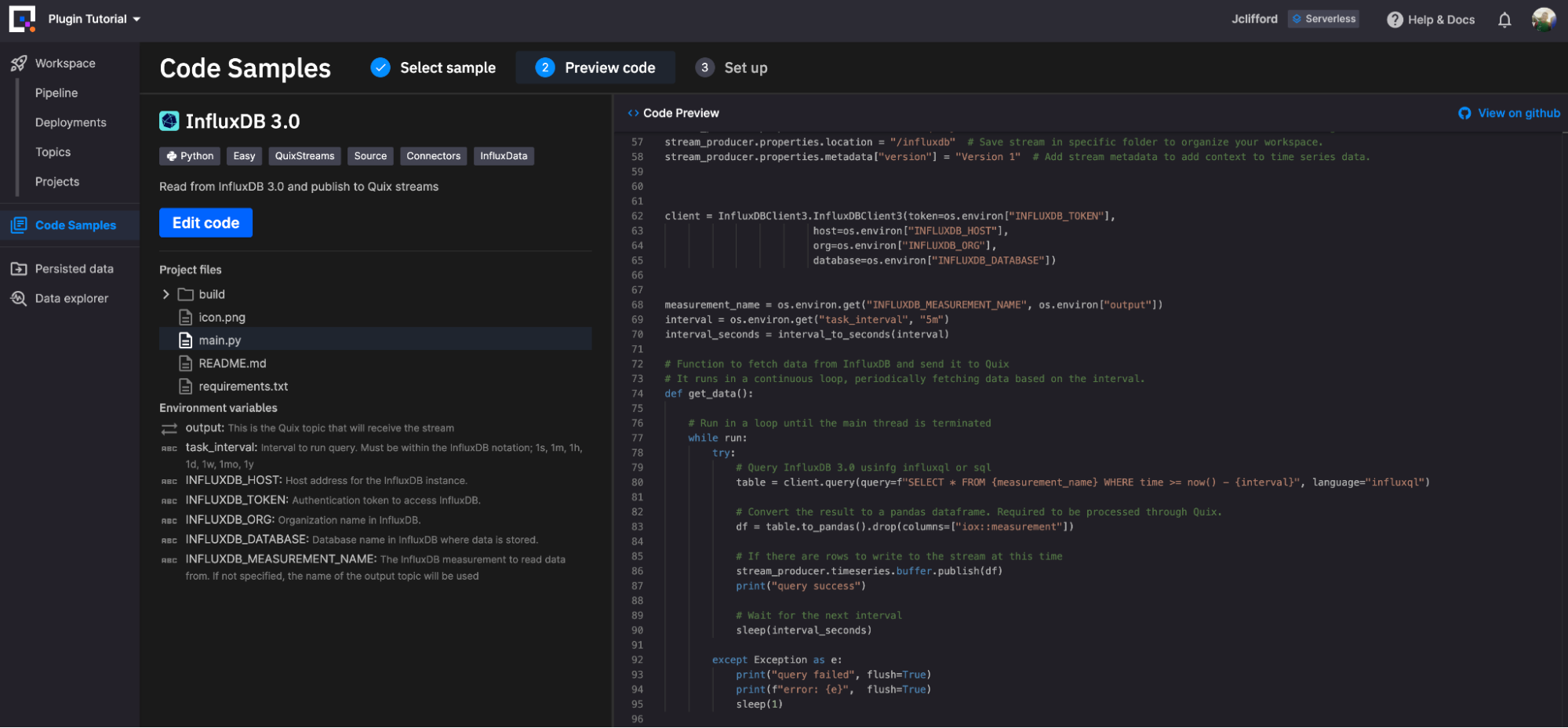
InfluxDB Source 插件需要定义以下环境变量才能运行
- output:这是将接收流的输出主题(默认值:influxdb,必填:True)
- task_interval:运行查询的间隔。必须在 InfluxDB 注释中;1s、1m、1h、1d、1w、1mo、1y(默认值:5m,必填:True)
- INFLUXDB_HOST:InfluxDB 实例的主机地址。(默认值:eu-central-1-1.aws.cloud2.influxdata.com,必填:True)
- INFLUXDB_TOKEN:访问 InfluxDB 的身份验证令牌。(默认值:
<TOKEN>,必填:True) - INFLUXDB_ORG:InfluxDB 中的组织名称。(默认值:
<ORG>,必填:False) - INFLUXDB_DATABASE:InfluxDB 中存储数据的数据库名称。(默认值:
<DATABASE>,必填:True) - INFLUXDB_MEASUREMENT_NAME:要从中读取数据的 InfluxDB 测量名称。如果未指定,将使用输出主题的名称(默认值:
<INSERT MEASUREMENT>,必填:True)
设置这些参数后,脚本将按如下方式运行
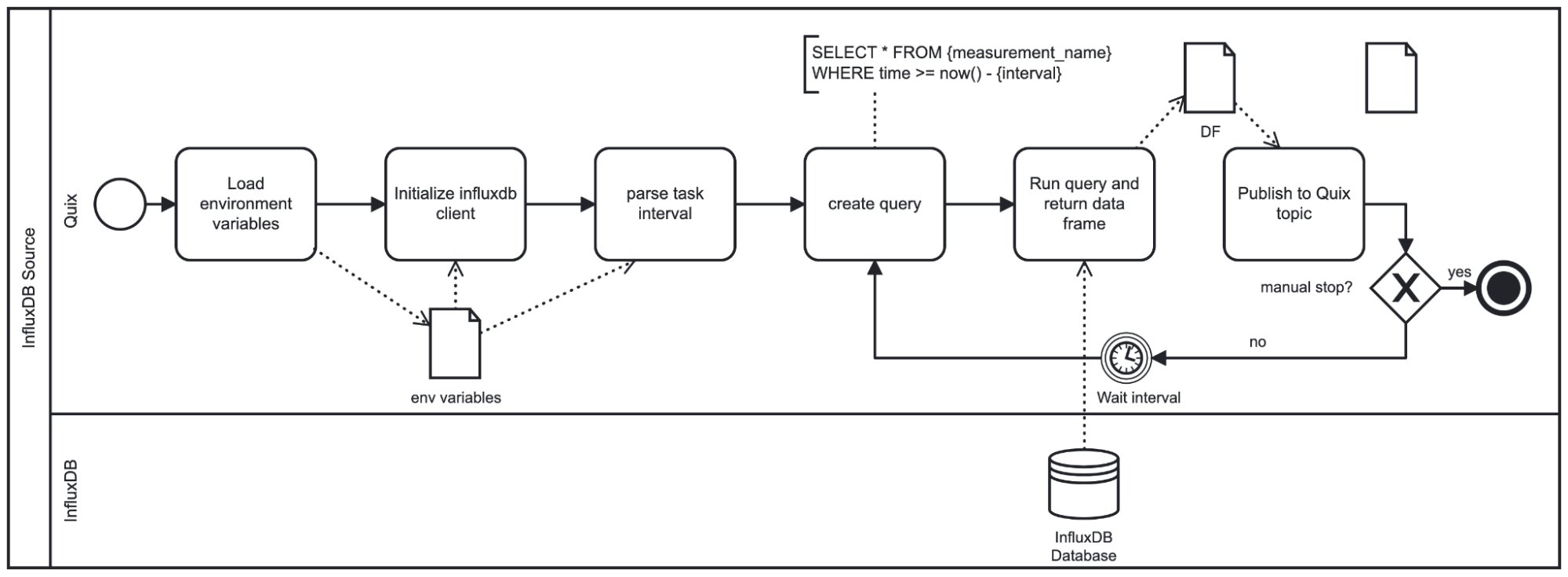
如图所示,此插件循环运行直到关闭。根据提供的间隔,脚本在重复查询之前休眠。间隔也用于制定查询,因为我们将仅查询基于插件休眠时长的最新数据。请注意,插件使用 DataFrame 格式推送结果数据。
InfluxDB Destination
InfluxDB Destination 插件(与 Source 插件一样,纯粹基于 Python)使您可以自定义插件将数据写入 InfluxDB 的方式(我们将在演示中使用的一项功能)。现在,让我们从“开箱即用”插件的另一个概述开始。
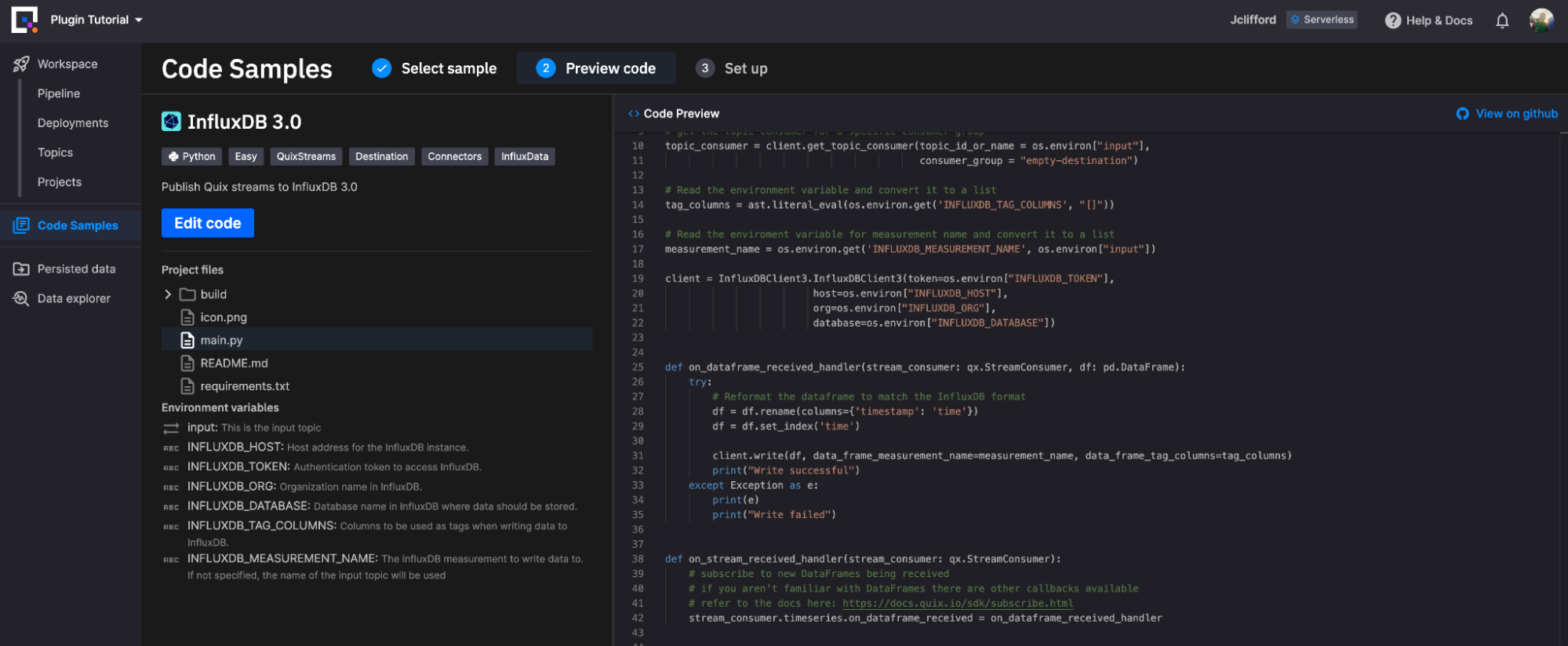
InfluxDB Destination 插件需要您定义以下环境变量才能运行
- input:这是输入主题(默认值:detection-result,必填:True)
- INFLUXDB_HOST:InfluxDB 实例的主机地址。(默认值:eu-central-1-1.aws.cloud2.influxdata.com,必填:True)
- INFLUXDB_TOKEN:访问 InfluxDB 的身份验证令牌。(默认值:
<TOKEN>,必填:True) - INFLUXDB_ORG:InfluxDB 中的组织名称。(默认值:
<ORG>,必填:False) - INFLUXDB_DATABASE:InfluxDB 中应存储数据的数据库名称。(默认值:
<DATABASE>,必填:True) - INFLUXDB_TAG_COLUMNS:将用作标签的列,用于将数据写入 InfluxDB。(默认值:
['tag1', 'tag2'],必填:False) - INFLUXDB_MEASUREMENT_NAME:要将数据写入的 InfluxDB 测量名称。如果未指定,将使用输入主题的名称。(默认值:
<INSERT MEASUREMENT>,必填:False)
设置这些参数后,脚本将按如下方式运行
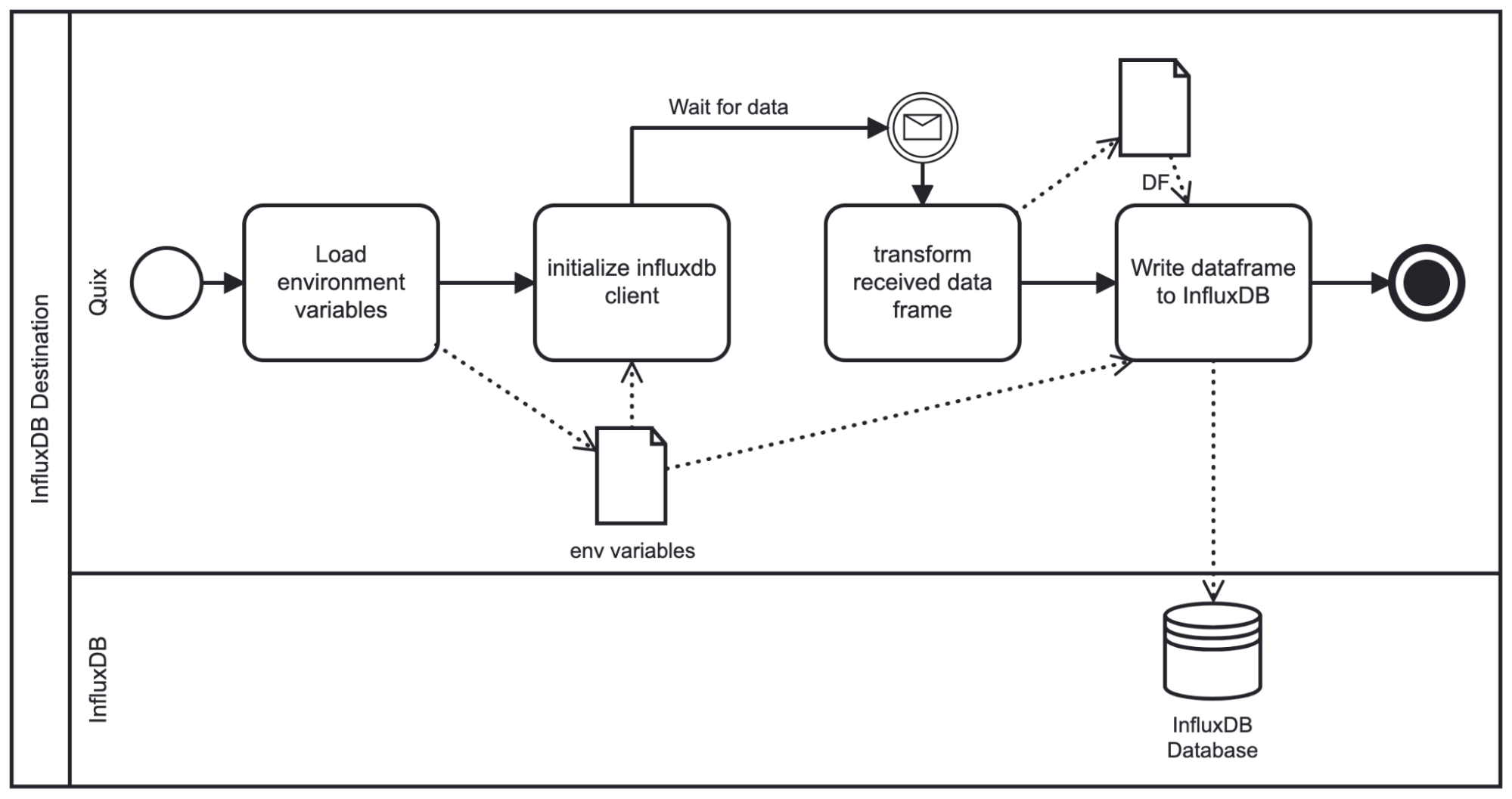
如图所示,在启动时,脚本加载给定的环境变量并初始化 InfluxDB 客户端。然后,它等待所选主题将数据流式传输到插件。流式传输的数据作为 pandas DataFrame 接收,因此我们需要应用一些基本转换(重命名时间列,将时间设置为索引),然后再写入 InfluxDB。从那里,我们根据环境变量中指定的架构将 DataFrame 写入 InfluxDB。
演示
现在我们已经讨论了每个插件及其各自的设计,让我们将它们应用于工业物联网用例。
在本示例中,我们有一条生产线上的三台机器生成传感器数据并写入 MQTT 代理(对于此用例,我们使用 HiveMQ)。每台机器的有效负载都在一个 JSON 结构中,如下所示。
{"metadata": {"machineID": "machine1", "barcode": "31856669", "provider": "Miller-Phillips"}, "data": [{"temperature": 40}, {"load": 100}, {"power": 204}, {"vibration": 90}]}我们将首先将 Quix MQTT 客户端连接到 HiveMQ 代理。
MQTT 客户端 -> Quix -> InfluxDB
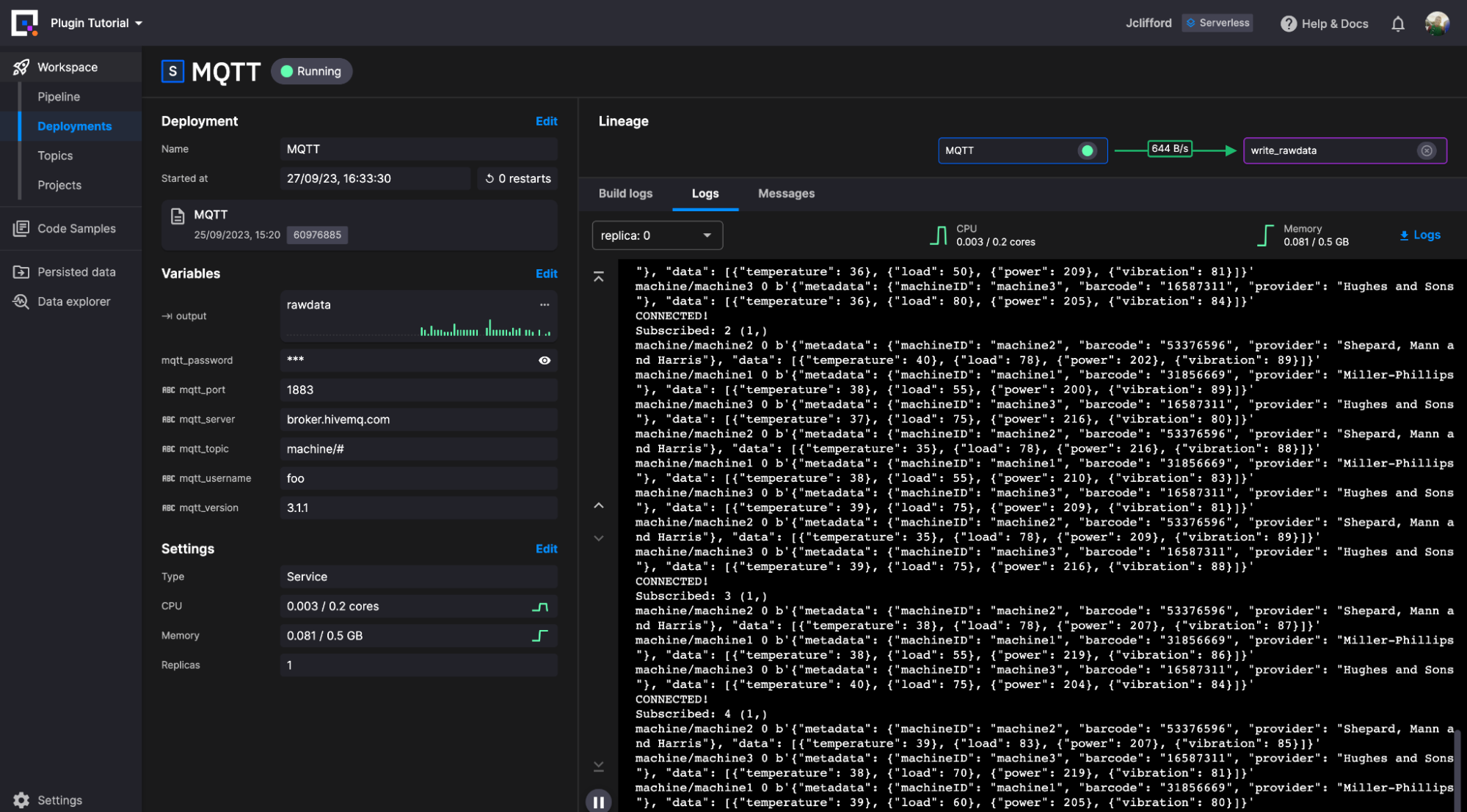
首先,我找到了 MQTT 插件,它连接到代理并将数据写入 Quix 流(右侧的那个)。
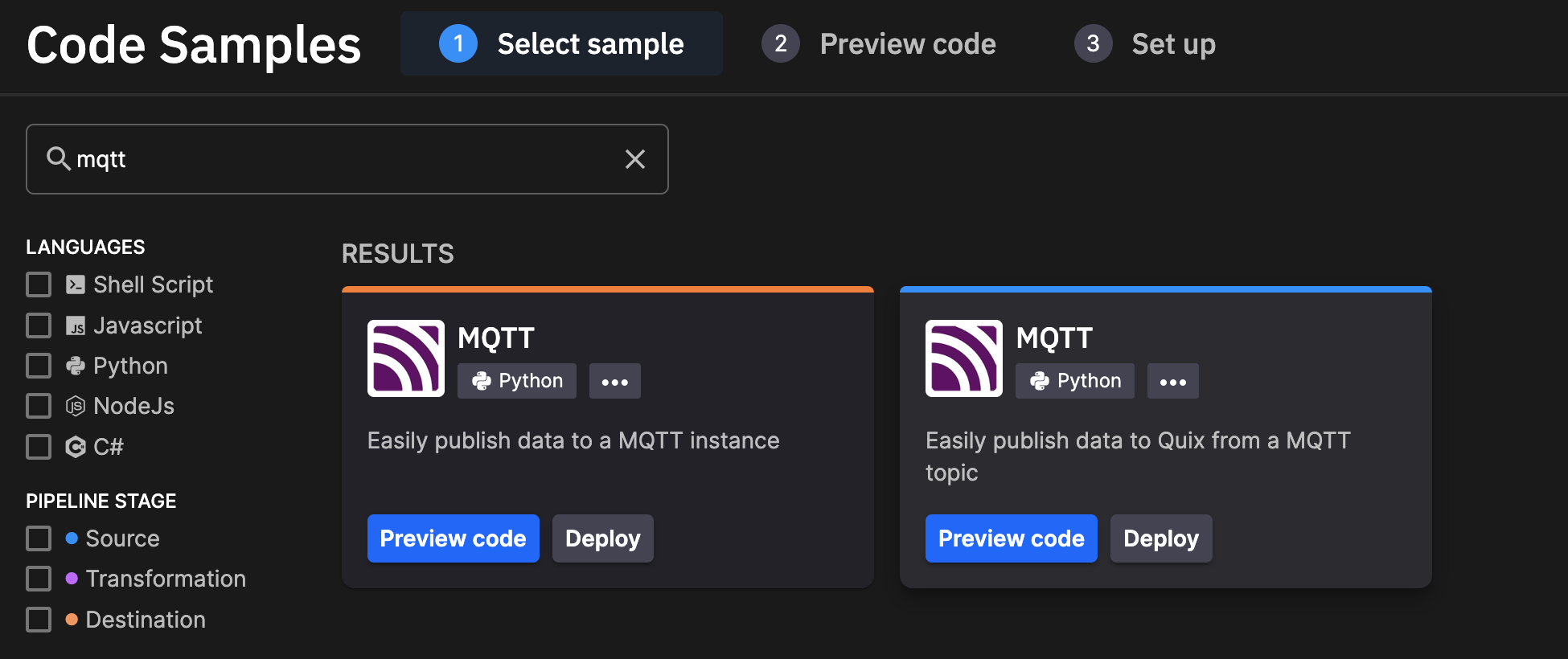
在检查代码后,我意识到我需要进行一些小的代码更改,因为我连接的代理不需要 TLS 身份验证。我需要删除这些行
# we'll be using tls
mqtt_client.tls_set(tls_version = mqtt.client.ssl.PROTOCOL_TLS)
mqtt_client.username_pw_set(os.environ["mqtt_username"], os.environ["mqtt_password"])接下来,我使用提供的环境变量来建立与代理的连接。
然后单击新部署。配置我们的资源限制(默认值即可),然后单击部署。这样,我们的第一阶段就完成了。
接下来,我们需要将此数据写入 InfluxDB。为此,我们使用新的目标插件进行一些修改。
我们遵循类似的过程来选择 InfluxDB 3.0 目标插件并生成一个项目。现在我们有一个小问题需要克服。目前,目标插件仅支持摄取 Quix DataFrame。在我们的例子中,我们正在写入 JSON 格式的事件数据。因此,我们需要为基于事件的数据编写一个小型的转换函数,您可以在这里看到
def on_event_data_received_handler(stream_consumer: qx.StreamConsumer,data: qx.EventData):
with data:
jsondata = json.loads(data.value)
metadata = jsondata['metadata']
data_points = jsondata['data']
fields = {k: v for d in data_points for k, v in d.items()}
timestamp = str(data.timestamp)
point = {"measurement": measurement_name, "tags" : metadata, "fields": fields, "time": timestamp}
print(point)
client.write(record=point)
def on_stream_received_handler(stream_consumer: qx.StreamConsumer):
# subscribe to new DataFrames being received
# if you aren't familiar with DataFrames there are other callbacks available
# refer to the docs here: https://docs.quix.io/sdk/subscribe.html
stream_consumer.timeseries.on_dataframe_received = on_dataframe_received_handler
stream_consumer.events.on_data_received = on_event_data_received_handler您将使用的大部分代码已存在。我们添加的主要元素是 on_event_data_received_handler。现在我们已经完成了此操作,我们像对 MQTT 连接器一样定义我们的环境变量。
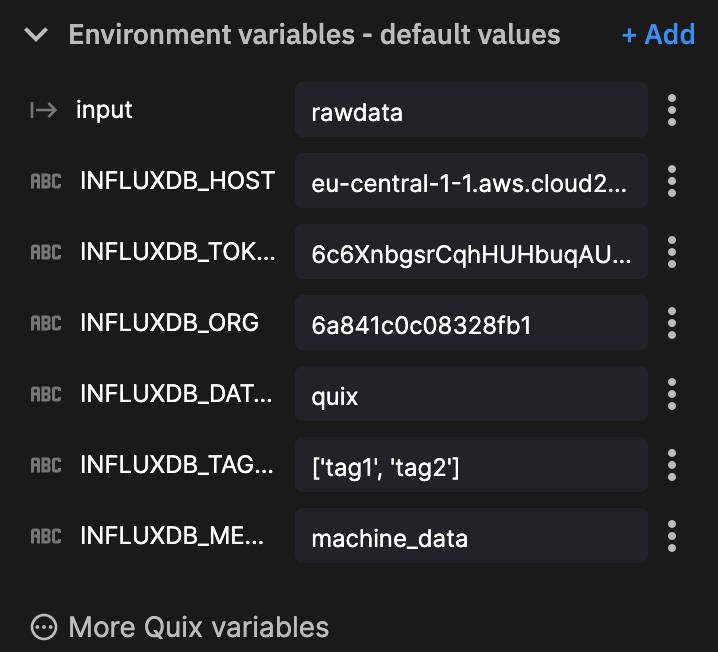
关于其中两个环境变量的说明
- 您可以将
InfluxDB_token修改为安全环境变量,以保护您的令牌安全。 - 在此示例中,我们未使用
InfluxDB_tag,因为我们使用 JSON 有效负载中的元数据作为标签。
单击新部署。配置我们的资源限制(默认值即可),然后单击部署。
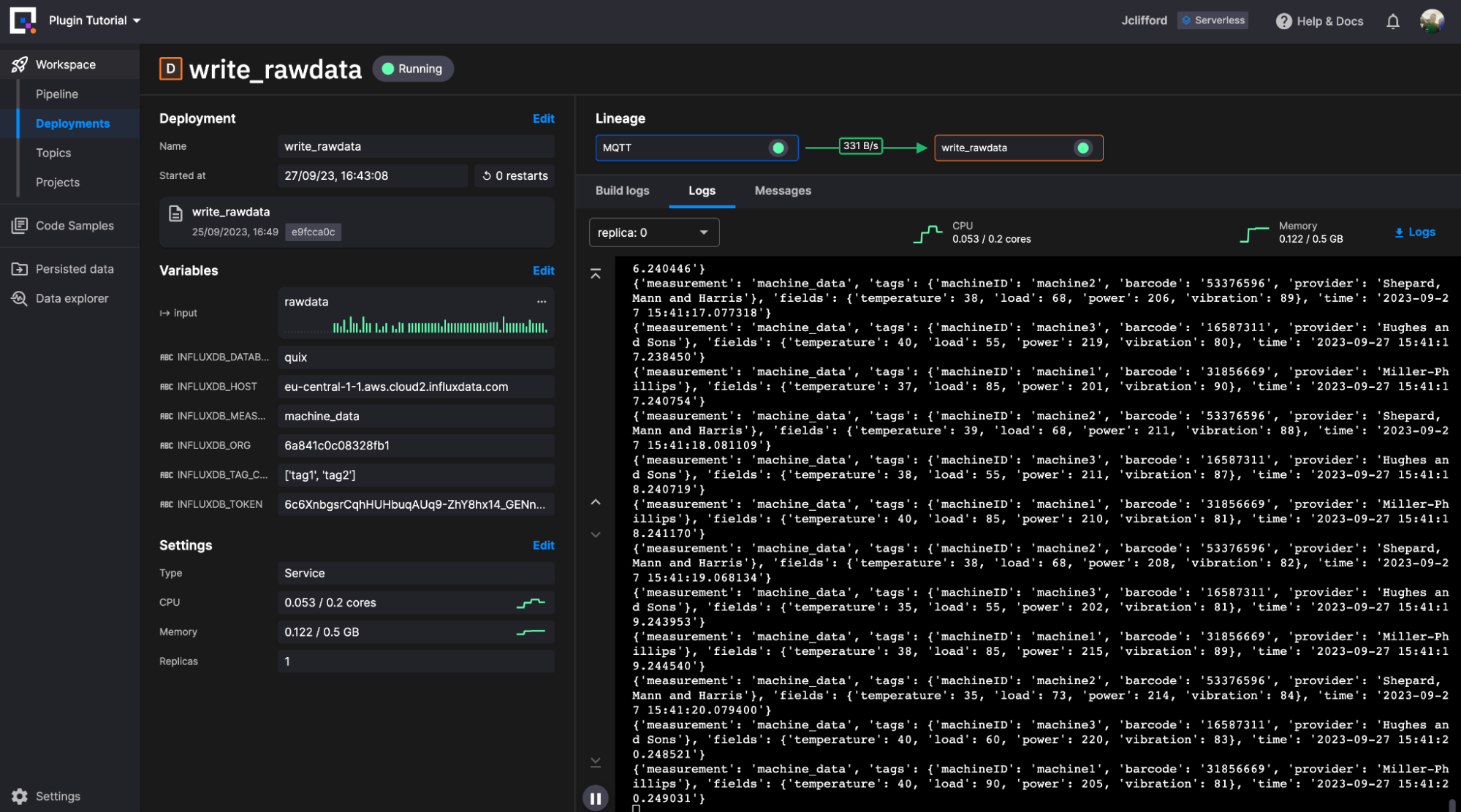
我们现在正在将原始机器数据写入 InfluxDB 中我们选择的测量。接下来,让我们继续讨论如何利用 Quix 作为基于任务的引擎来转换我们存储的原始数据。
InfluxDB -> Quix(转换)-> InfluxDB
我们将利用两个社区插件的开箱即用配置来组合转换任务。转换任务很简单
- 查询最近 1 分钟的数据
- 添加一个新列,用于检查该间隔内的振动是否超过用户定义的阈值。此列将包含基于结果的 true 或 false。
- 将数据写回 InfluxDB 中的新表
让我们从查询 InfluxDB 中的数据开始。这次我们将使用我们的 InfluxDB 3.0 Source 插件。与我们之前的示例一样,我们从代码示例库中搜索并选择它,然后创建一个项目。
我们不需要为此插件修改任何插件代码。只需简单地定义我们的环境变量
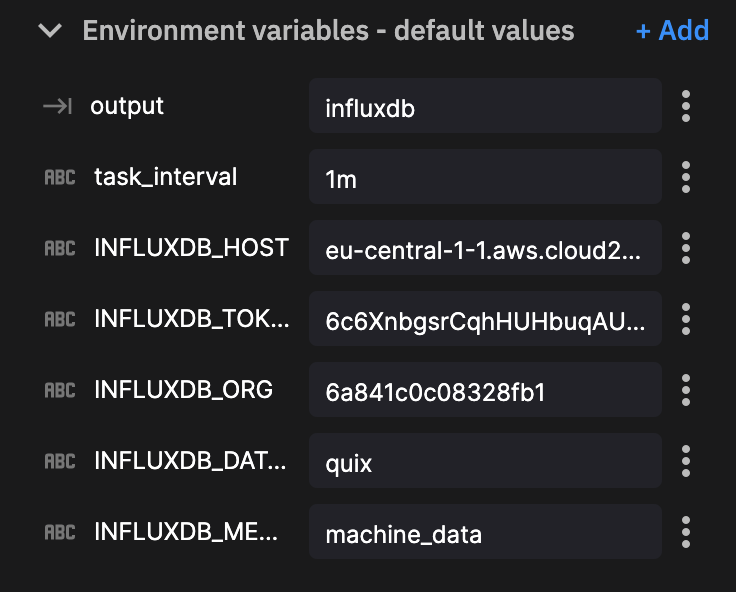
然后单击新部署。配置我们的资源限制(默认值即可),然后单击部署。
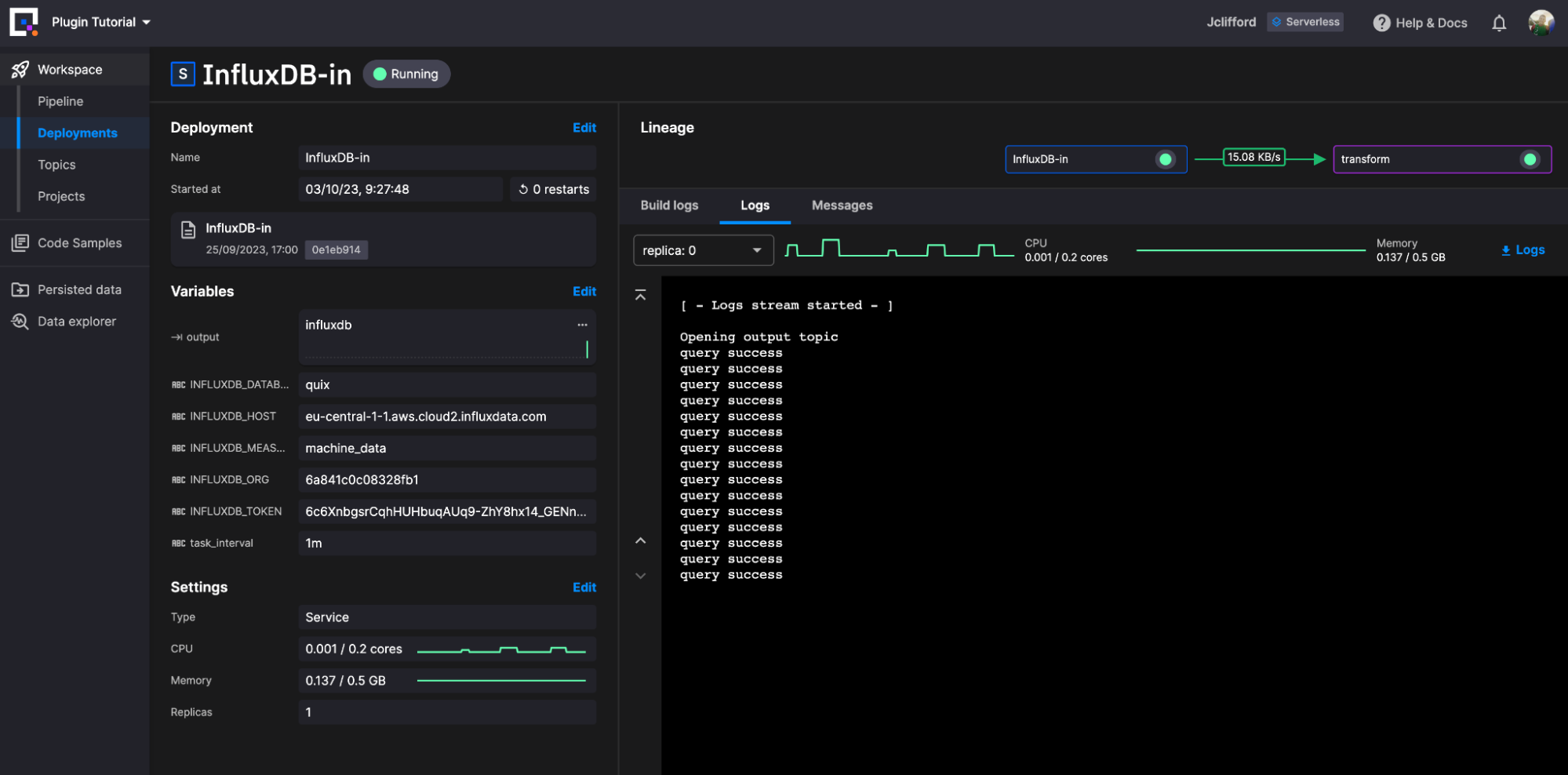
我们的查询数据现在正作为 DataFrame 直接写入主题 InfluxDB。我们现在可以部署并创建一系列转换插件来重塑我们的数据。对于此示例,我们将使其保持简单
- 摄取 DataFrame
- 在振动列中使用基本的条件逻辑来检查它是否超过我们预定义的阈值
- 创建新的布尔列并将 DataFrame 写入新的主题读取器以进行摄取。
代码如下所示
import quixstreams as qx
import os
import pandas as pd
client = qx.QuixStreamingClient()
topic_consumer = client.get_topic_consumer(os.environ["input"], consumer_group = "empty-transformation")
topic_producer = client.get_topic_producer(os.environ["output"])
def on_dataframe_received_handler(stream_consumer: qx.StreamConsumer, df: pd.DataFrame):
vibration_limit = int(os.environ["vibration_limit"])
df['over_limit'] = df['vibration'] > vibration_limit
stream_producer = topic_producer.get_or_create_stream(stream_id = stream_consumer.stream_id)
stream_producer.timeseries.buffer.publish(df)
def on_event_data_received_handler(stream_consumer: qx.StreamConsumer, data: qx.EventData):
print(data)
# handle your event data here
def on_stream_received_handler(stream_consumer: qx.StreamConsumer):
stream_consumer.events.on_data_received = on_event_data_received_handler # register the event data callback
stream_consumer.timeseries.on_dataframe_received = on_dataframe_received_handler
topic_consumer.on_stream_received = on_stream_received_handler
print("Listening to streams. Press CTRL-C to exit.")
qx.App.run()基于此基本转换插件,我们需要定义三个环境变量。
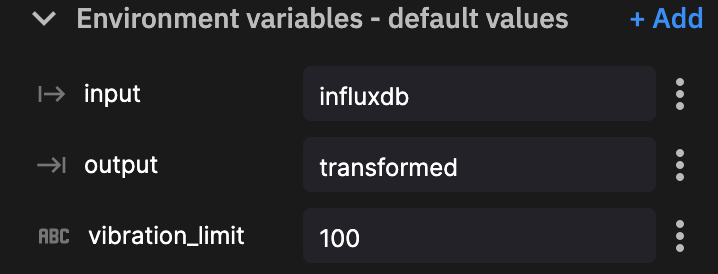
然后单击新部署。配置我们的资源限制(默认值即可),然后单击部署。
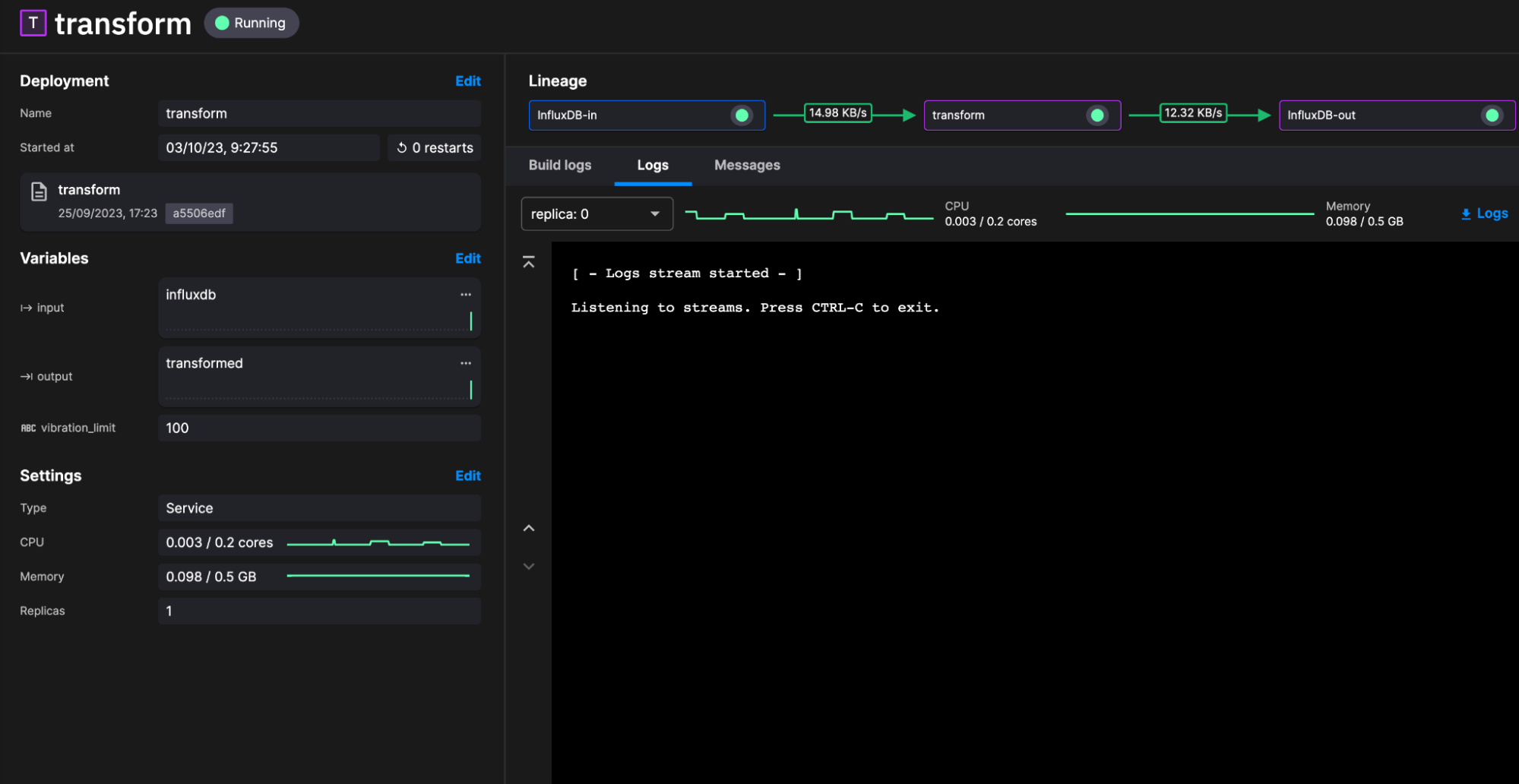
我们的最后一步是将数据写回 InfluxDB。对于此任务,我们部署另一个 InfluxDB Destination 插件实例。这一次,由于我们从转换主题中摄取 DataFrame,我们只需要定义环境变量。
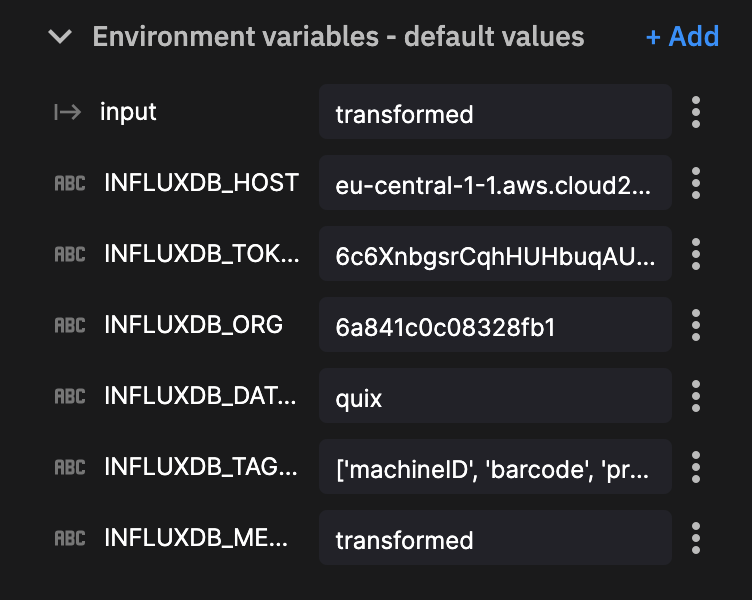
关于其中两个环境变量的说明
InfluxDB_measurement将我们的转换数据写入名为transformed的新表。InfluxDB 会按需创建此表。- 我们为希望定义为标签的列提供了一个字符串数组:
['machineID', 'barcode', 'provider']
然后单击新部署。配置我们的资源限制(默认值即可),然后单击部署。
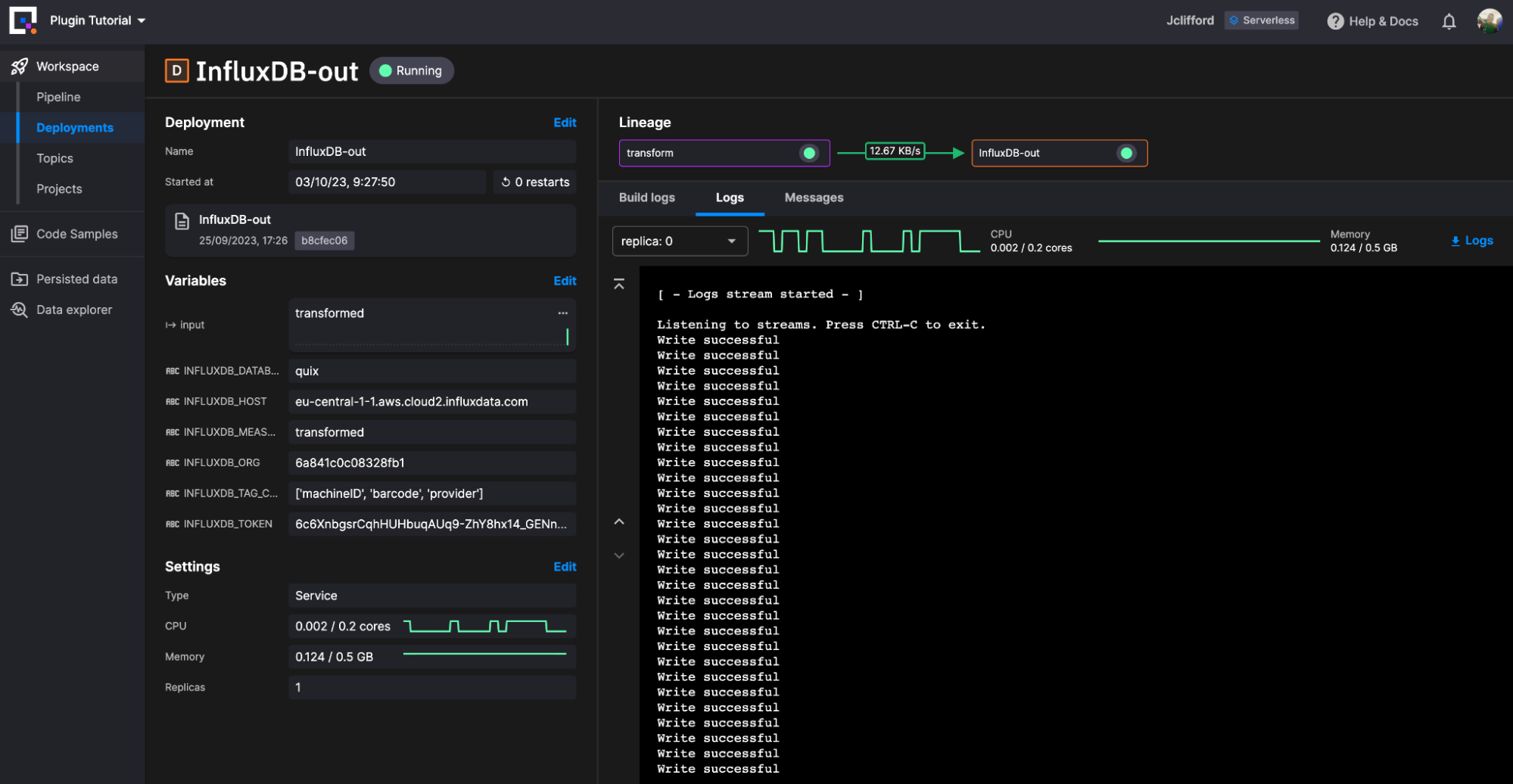
结论
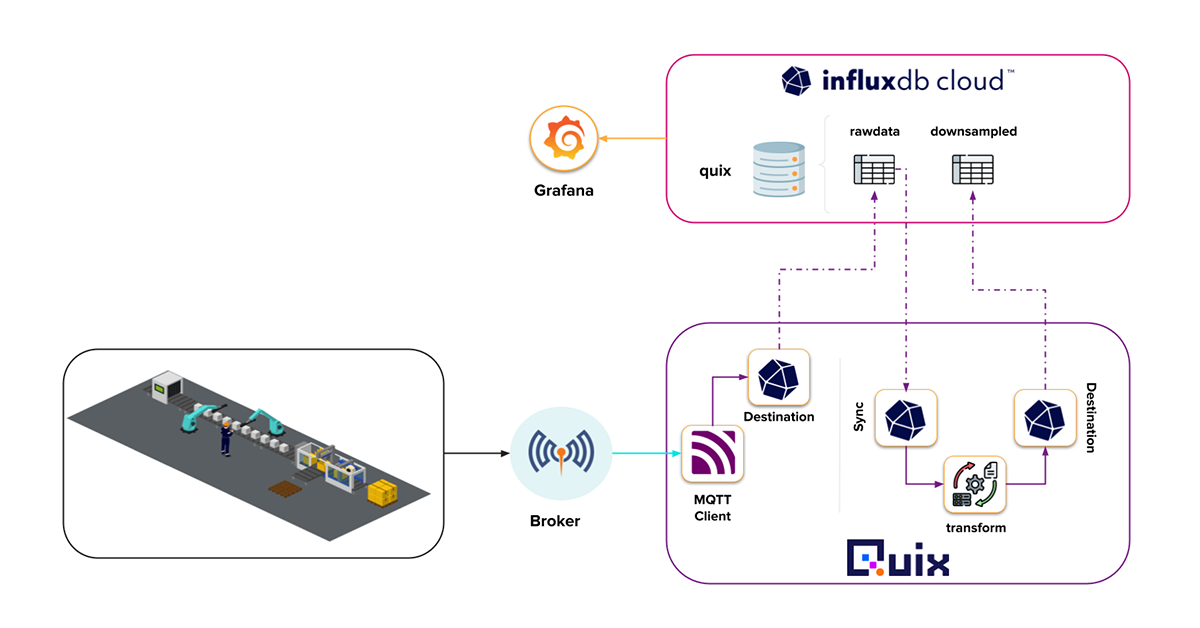
就是这样!我们成功部署了用于 InfluxDB 的事件流管道和任务引擎。从鸟瞰角度来看,它看起来像这样。
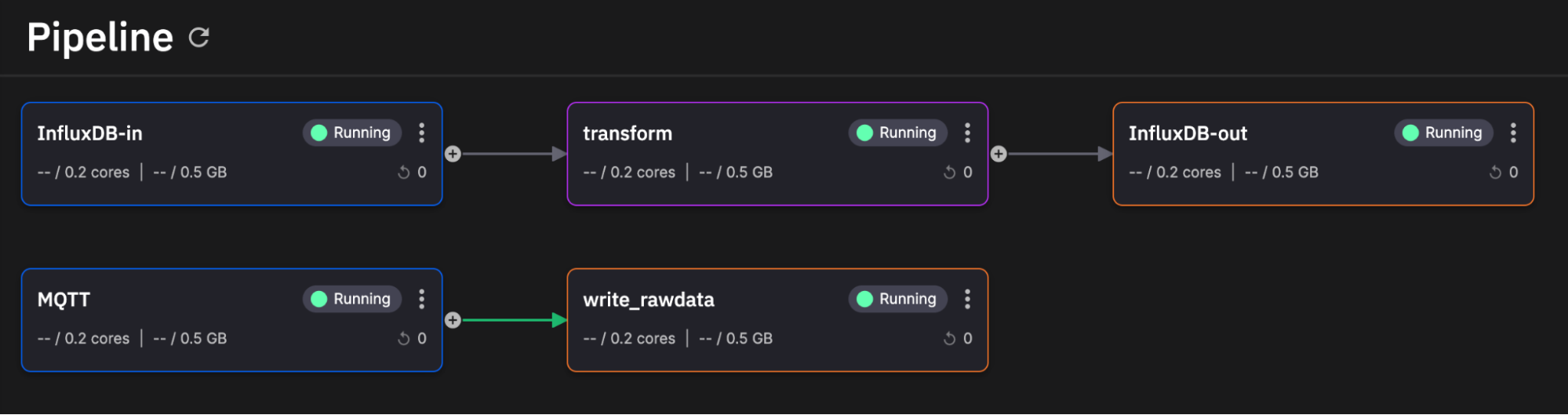
(感谢 Quix 提供的出色用户界面)
以下是我们的原始机器数据和转换后的数据在 InfluxDB 中的外观。
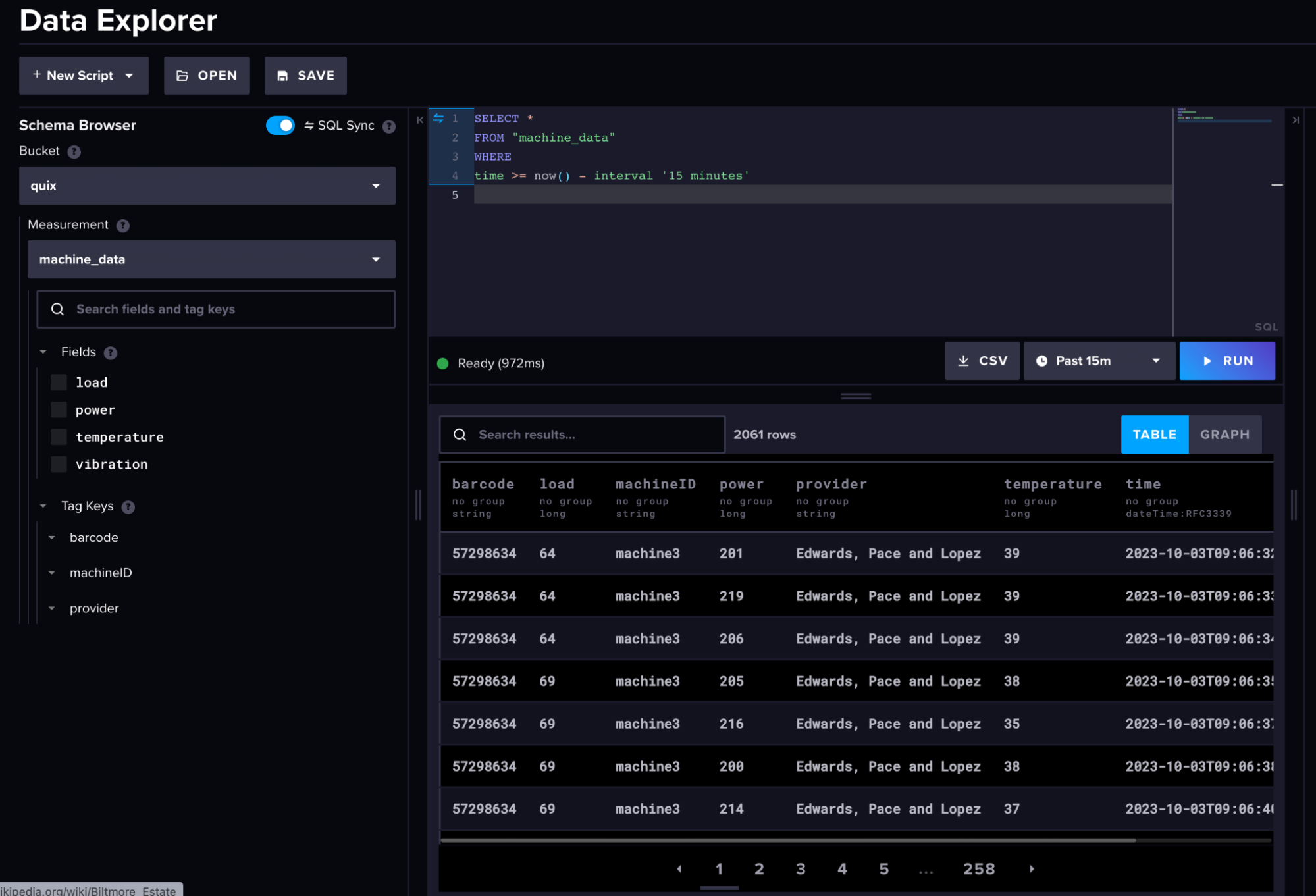 (原始机器数据)
(原始机器数据)
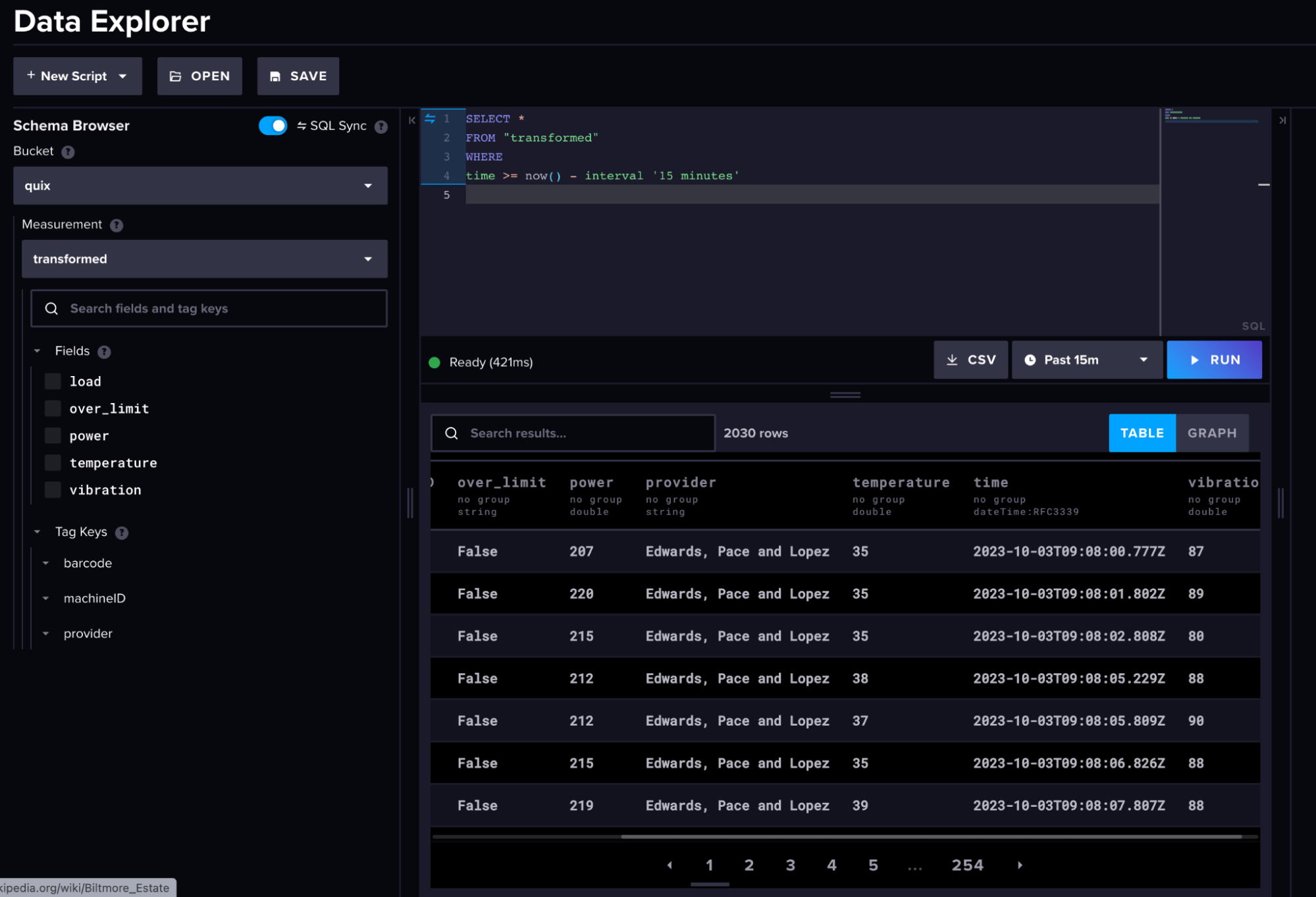 (转换后的机器数据)
(转换后的机器数据)
总而言之,我们利用 Quix 平台以及新的 InfluxDB 社区插件,从三个 MQTT 主题摄取“实时”原始机器数据,将此数据存储在 InfluxDB 中,然后从我们存储的数据中提取新价值。那么,接下来您可以做什么?
我希望您可以借鉴此示例,使其适应您自己的需求,并使用 Quix 平台对其进行扩展。使用 Quix 的主要优势在于,我们可以有效地扩展源、转换和目标的数量以满足我们的需求。扩展我们的任务引擎就是一个很好的例子
- 降采样脚本
- 异常检测算法
- 检查和警报脚本
每个脚本都将订阅我们的 InfluxDB 主题并彼此并行工作,与传统的任务方法相比,可以有效地利用事件流管道中的数据,而传统的任务方法将重新查询数据。
您可以在此处找到类似项目的源代码。如果您有任何疑问或想进一步讨论 InfluxDB 或 Quix,请加入我们的 Slack 频道。
