使用时间序列数据库进行预测分析
作者:Anais Dotis-Georgiou / 用例, 产品
2023 年 9 月 5 日
导航至
本文最初发表于 The New Stack,经许可在此处转载。
时间序列数据库以高速和高容量处理带时间戳的数据,特别适合异常检测和预测性维护。
预测分析利用大数据、统计算法和机器学习技术,根据历史数据预测未来结果。各行各业都在使用预测分析,从金融和医疗保健到零售和营销。在其众多用途中,预测性维护和异常检测是两个重要的应用。预测性维护使用预测分析来预测机械故障,从而实现及时的维护并防止意外停机。
同样,异常检测利用相同的预测能力来识别数据中的异常情况,这些异常情况可能表明存在问题,例如金融交易中的欺诈或网络安全中的入侵。预测分析的这些应用共同帮助组织保持积极主动和知情,为提高效率、降低风险和改进决策铺平道路。
时间序列数据库为执行预测分析提供了关键功能。它专门用于处理按时间顺序索引的数据点,可以高速和大容量地存储、检索和处理带时间戳的数据。这些功能使时间序列数据库特别适合异常检测和预测性维护等任务。
InfluxDB 3.0 是一个时间序列数据库和平台,用于存储所有类型的时间序列数据,包括指标、事件、日志和追踪。
在这篇文章中,我们将探讨如何结合 InfluxDB Cloud、Quix 和 Hugging Face 进行预测性维护,包括预测分析和预测。Quix 是一个平台,允许您部署用于分析和机器学习的流式管道。Hugging Face 是一个 ML 平台,使用户能够训练、构建、托管和部署开源机器学习模型和数据集。
数据集
我们在这篇文章中使用的数据集来自这个 repo,特别是 这个脚本。它包含生成的机器数据,其中包含各种机器 ID 的温度、负载和振动等值。这是一个虚构的数据集,因此我们可以在需要时引入异常来测试异常检测。这是来自 influxdb-query 服务的数据外观。
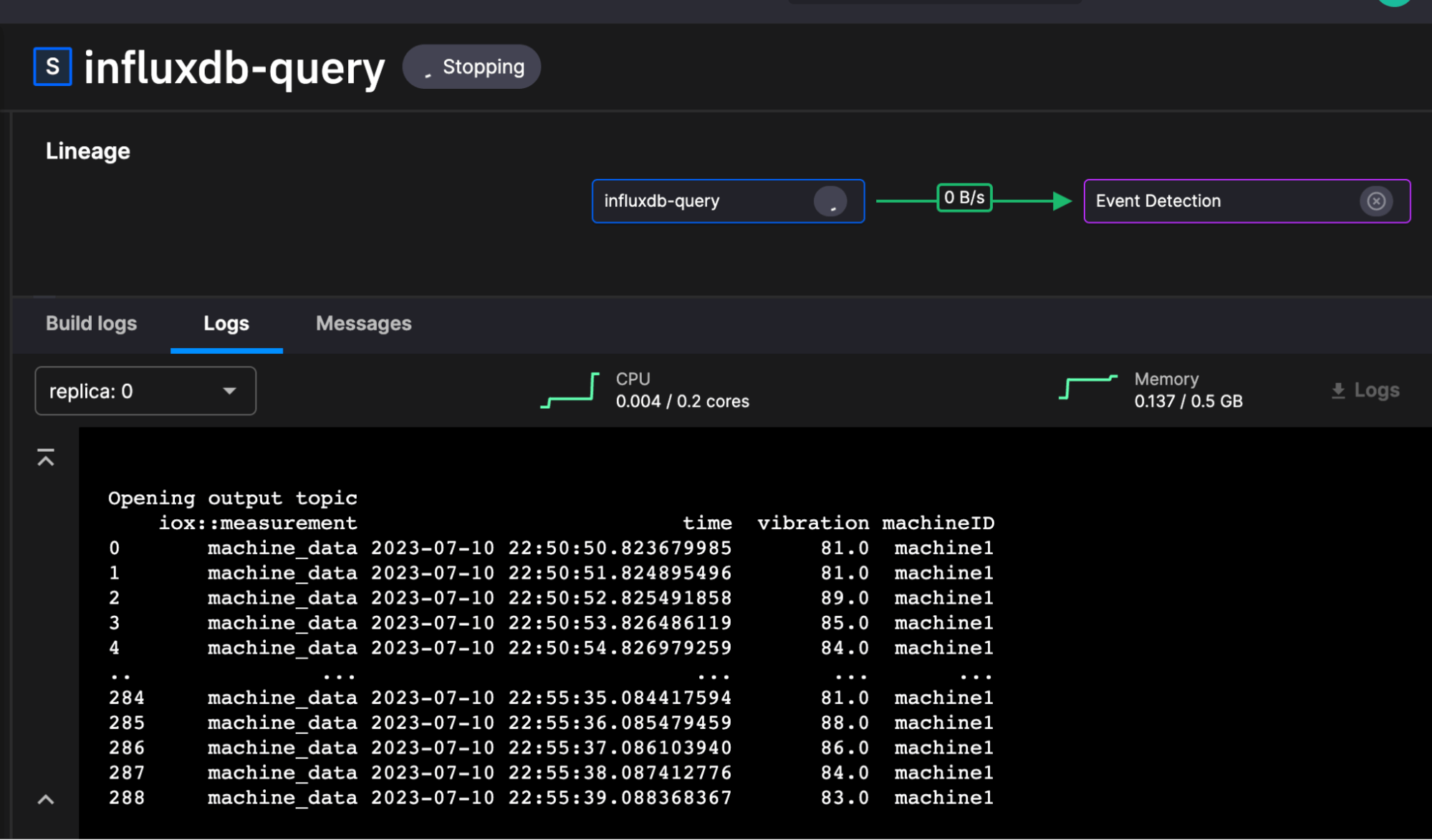
Quix 异常检测和预测管道
Quix 使我们能够部署用于分析和机器学习的流式管道。下图描述了我们的管道
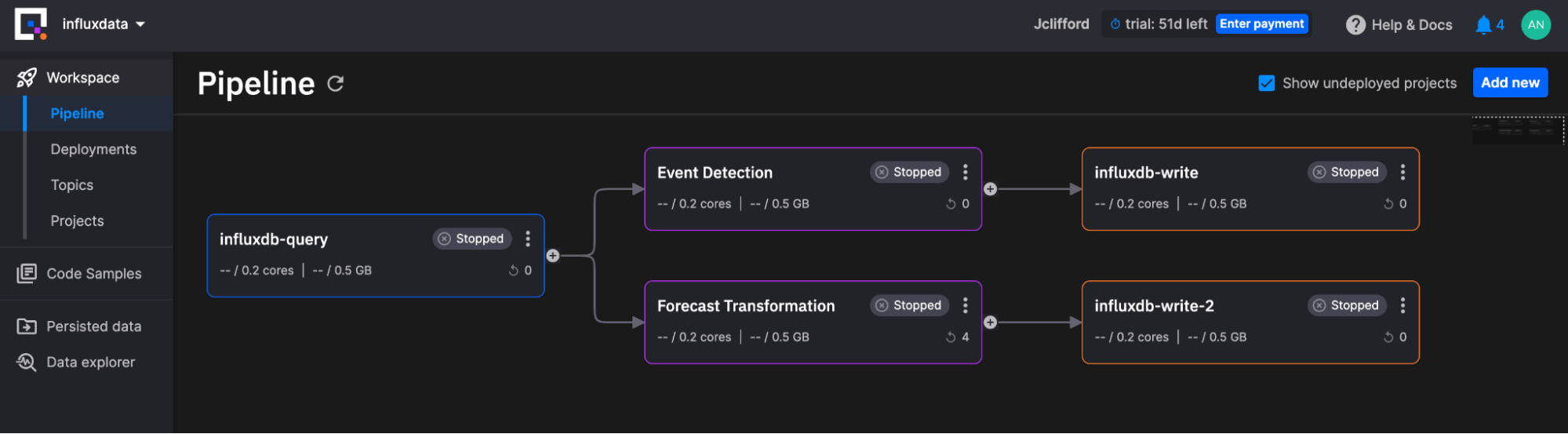
工作区管道包含以下服务
-
源项目:此服务项目负责使用 InfluxQL(查询语言)查询 InfluxDB Cloud,并将输出转换为 Pandas DataFrame,以便转换块可以使用它。
-
两个转换:这些服务项目负责查找数据中的异常并生成预测。它们并行处理来自源服务的数据。
- 事件检测查找异常。
- 预测转换生成预测。
-
两个写入项目:这些服务项目负责使用 InfluxDB 3.0 Python 客户端库 将数据写回 InfluxDB Cloud。之所以有两个写入实例,是因为我们要写入两个独立的 InfluxDB Cloud 实例。但是,如果您想将所有数据写回同一个实例,则可以选择并行写入数据。
Quix 如此容易的原因在于,您可以通过从各种常用服务中进行选择来添加新服务(服务在用户定义的计划上运行)或新作业(作业运行一次)。它们包含流式传输数据并将输入传递到正确输出所需的所有样板代码。此外,您可以轻松地在项目之间流式传输 Pandas DataFrame,从而消除任何数据转换工作。
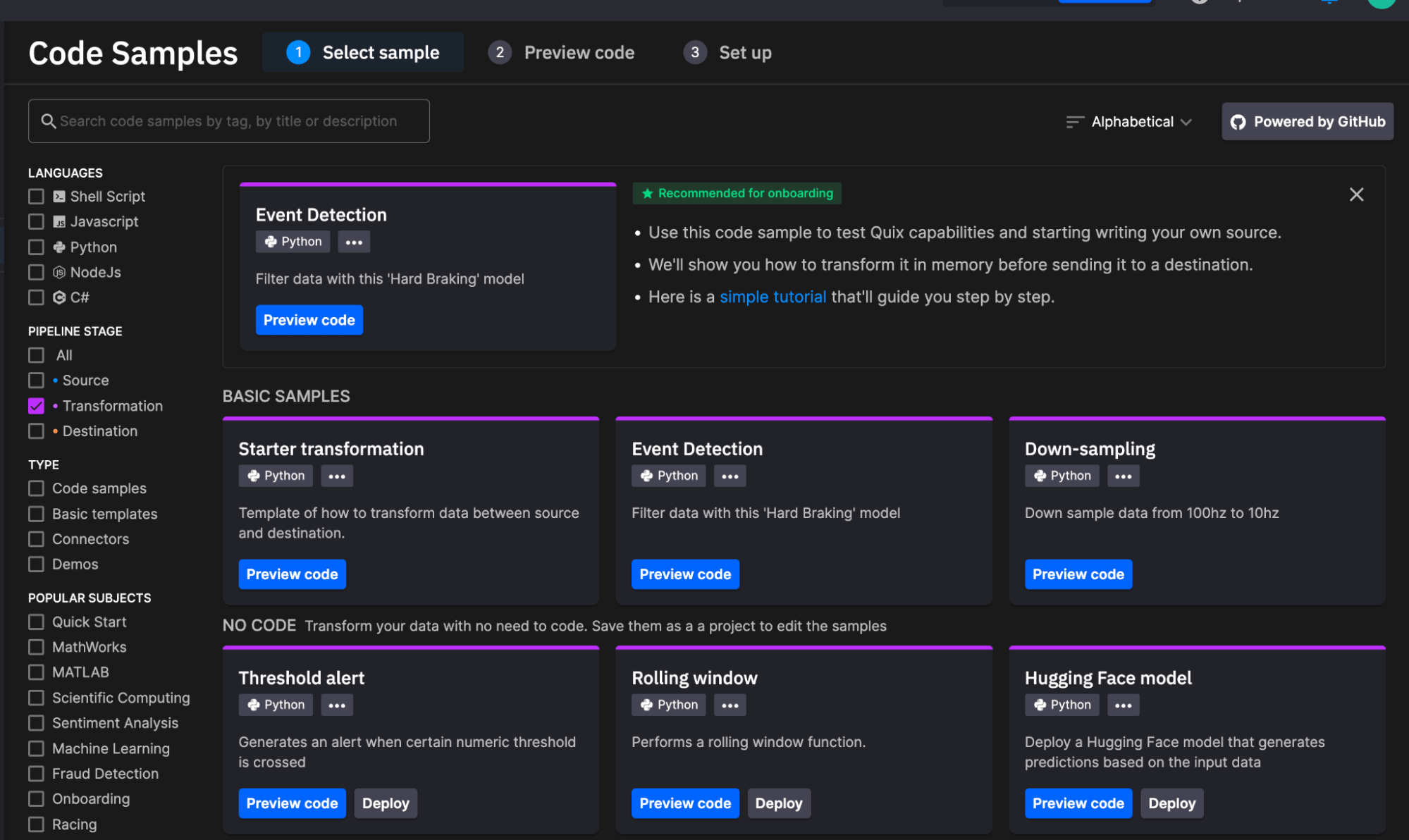
源项目
此块每 60 秒运行一次。它使用 InfluxDB 3.0 Python 客户端库使用以下代码查询过去 5 分钟的机器数据
def get_data():
# Query InfluxDB Cloud 3.0
while run:
try:
query = "SHOW TAG VALUES WITH KEY = \"machineID\""
table = client.query(query=query, language="influxql")
machines = table["value"].to_pylist()
for machine in machines:
# this will end up loop when all data has been sent
table = client.query(query=f"SELECT vibration, machineID FROM machine_data WHERE time >= now() - 5m AND machineID = '{machine}'", language="influxql")
df = table.to_pandas()
print(df)
if df.empty:
break
# If there are rows to write to the stream at this time
stream_producer.timeseries.buffer.publish(df)
sleep(int(os.environ["task_interval"]))
except:
print("query failed")
sleep(int(os.environ["task_interval"]))您配置与 InfluxDB Cloud 的连接
事件检测项目
在本教程中,我们使用 Keras Autoencoders 来创建和训练异常检测模型。自动编码器是一种用于学习输入数据高效编码的人工神经网络。在异常检测中,自动编码器在正常数据上进行训练,并学习尽可能接近地重现它。当呈现新数据时,自动编码器尝试使用从正常数据中学到的模式来重建它。如果重建误差(原始输入和自动编码器的输出之间的差异)非常高,则模型会将新数据点分类为异常,因为它明显偏离了正常数据。
我们使用了这个 Jupyter 笔记本 在 将其推送到 Hugging Face 之前训练数据模型。接下来,我们将模型导入到 Quix 事件检测项目中。该模型是一个变量,因此您可以轻松地在 Hugging Face 中交换模型。这使您可以将模型调整和训练工作流程与管道部署分开。
from huggingface_hub import from_pretrained_keras
# Quix injects credentials automatically to the client.
# Alternatively, you can always pass an SDK token manually as an argument.
client = qx.QuixStreamingClient()
print("Opening input and output topics")
consumer_topic = client.get_topic_consumer(os.environ["input"], "default-consumer-group")
producer_topic = client.get_topic_producer(os.environ["output"])
model = from_pretrained_keras(os.environ["model"])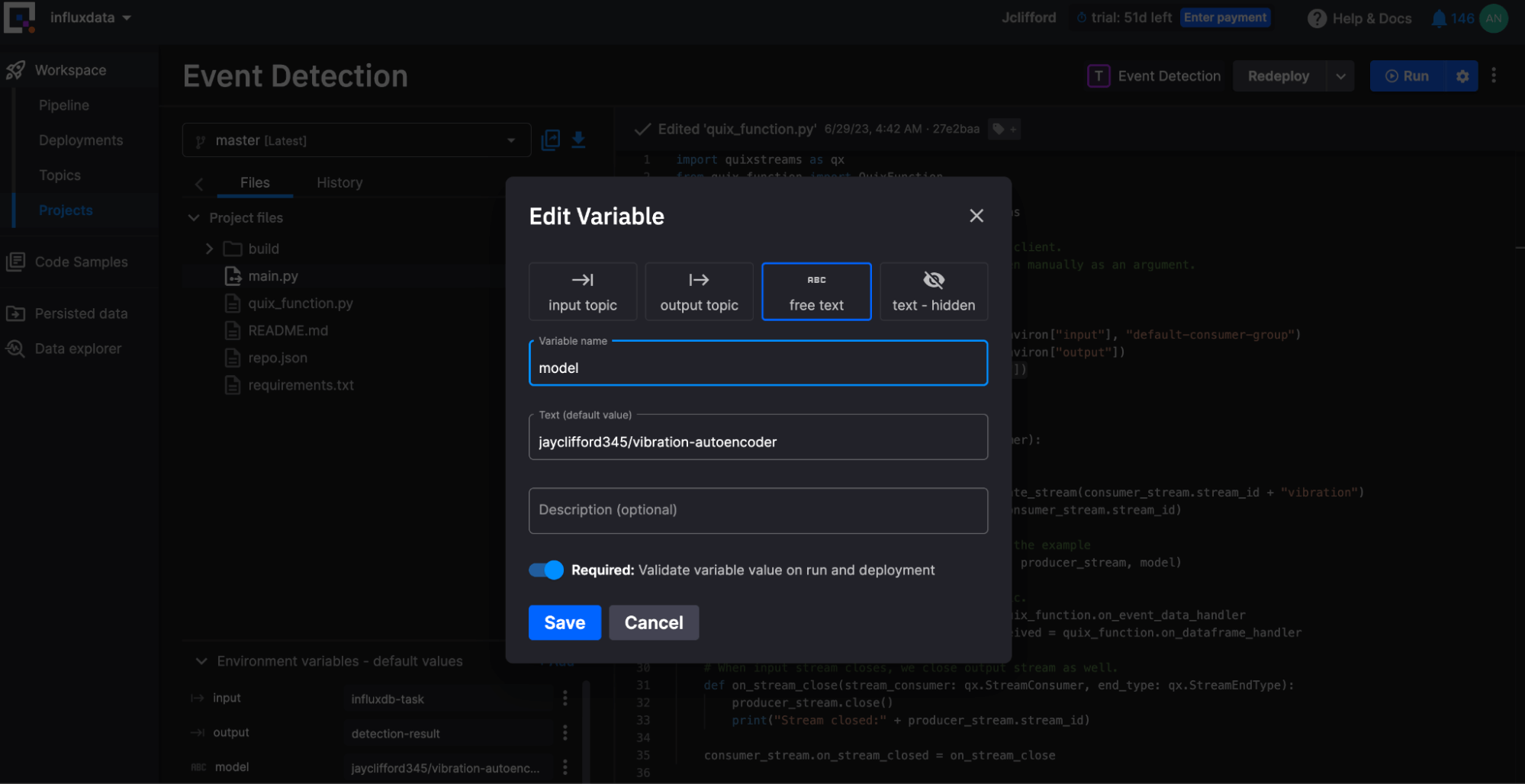
jayclifford345/vibration-autoencoder 已被选中。预测转换项目
我们从代码示例中的示例Starter Transformation项目构建了这个项目。它使用 statsmodels 中的 Holt Winters 来创建快速预测。
df = df.set_index('timestamp')
data = df.drop(columns=['iox::measurement', 'machineID'])
fit = Holt(data,damped_trend=True,initialization_method="estimated").fit(optimized=True)
fcast = fit.forecast(10).rename("Multiplicative damped trend")
fcast = fcast.reset_index().rename(columns={'index': 'timestamp'})写入项目
写入项目(influxdb-write 和 influxdb-write-2)将异常和预测写入两个独立的 InfluxDB 实例。这种设计选择是任意的。它仅仅展示了这种架构作为一种选择。InfluxDB 3.0 Python 客户端库将 DataFrames 写入两个实例。
import influxdb_client_3 as InfluxDBClient3
client = qx.QuixStreamingClient()
# get the topic consumer for a specific consumer group
topic_consumer = client.get_topic_consumer(topic_id_or_name = os.environ["input"],
consumer_group = "empty-destination")
client = InfluxDBClient3.InfluxDBClient3(token=os.environ["INFLUX_TOKEN"],
host=os.environ["INFLUX_HOST"],
org=os.environ["INFLUX_ORG"],
database=os.environ["INFLUX_DATABASE"])
def on_dataframe_received_handler(stream_consumer: qx.StreamConsumer, df: pd.DataFrame):
# do something with the data here
df = df.rename(columns={'timestamp': 'time'})
df = df.set_index('time')
client.write(df, data_frame_measurement_name='mlresult', data_frame_tag_columns=['machineID'])
print("Write successful")最终想法
将异常和预测写入 InfluxDB 后,我们可以使用像 Grafana 这样的工具来可视化数据并创建警报以对其采取行动。例如,如果我们收到过多的异常,我们可能会决定需要诊断系统中的问题、更换传感器或机器、协助预测性维护或重新设计制造流程。对振动预测发出警报可以防止制造中断或优化运营。
InfluxDB Cloud 是存储所有时间序列数据的好工具。它构建在 Apache 生态系统之上,并利用 DataFusion、Arrow 和 Parquet 等技术来实现真正高效的写入、存储和查询。它支持 SQL 查询,这使开发人员可以专注于在 InfluxDB 之上构建解决方案,例如此预测性维护管道。它还提供与许多其他工具的互操作性,因此您可以将它们用于特定的预测分析需求。立即开始使用 InfluxDB Cloud 3.0。
