在 DataFusion 中优化 SQL(和 DataFrames):第二部分
作者:Andrew Lamb / Mustafa Akur / 开发者
2025 年 4 月 3 日
导航至
第二部分:Apache DataFusion 中的优化器
在本系列文章的第一部分中,我们讨论了查询优化器是什么以及它扮演的角色,并描述了工业优化器是如何组织的。在第二部分中,我们将更详细地描述 Apache DataFusion 和其他工业系统中发现的各种优化。
DataFusion 包含高质量、功能齐全的始终优化和引擎特定优化(在第一部分中定义)的实现。优化器实现为 逻辑优化器中 LogicalPlan 的重写,或 物理优化器中 ExecutionPlan 的重写。这种设计意味着相同的优化器传递适用于 SQL 和 DataFrame 查询,以及其他查询语言前端的计划,例如 InfluxDB 3.0 中的 InfluxQL、Greptime 中的 PromQL 和 VegaFusion 中的 Vega。
始终优化
一些优化非常重要,几乎在所有查询引擎中都能找到,并且通常是首先实现的,因为它们提供了最大的成本效益比(并且没有它们,性能会非常糟糕)。
谓词/过滤器下推
原因:尽早避免携带不需要的行。
内容:将过滤器“向下”移动到计划中,使其在执行中更早运行,如图 1 所示。
示例实现:DataFusion、DuckDB、ClickHouse
数据在计划中越早被过滤掉,计划的其余部分需要做的工作就越少。大多数成熟的数据库都积极使用过滤器下推/早期过滤,并结合分区和存储修剪等技术(例如,Parquet 行组修剪)以提高性能。
一个极端且有些牵强的示例查询
SELECT city, COUNT(*) FROM population GROUP BY city HAVING city = ‘BOSTON’;从语义上讲,HAVING 是在 SQL 中 GROUP BY 之后评估的。但是,计算所有城市的人口并丢弃除波士顿以外的所有内容比仅计算波士顿的人口要慢得多,因此大多数查询优化器将在聚合之前评估过滤器。

图 1:过滤器下推。(A) 中,在没有过滤器下推的情况下,运算符处理更多行,降低了效率。(B) 中,在有过滤器下推的情况下,运算符接收更少的行,从而减少了总体工作量,并使查询更快、更高效。
投影下推
原因:尽早避免携带不需要的列。
内容: 将“投影”(仅保留某些列)更早地推送到计划中,如图 2 所示。
示例实现: DataFusion、DuckDB、ClickHouse
与过滤器下推的动机类似,计划越早停止做某事,总体工作量就越少,运行速度就越快。对于投影下推,如果计划的后续阶段不需要列,则将数据复制到其他运算符的输出是不必要的,并且复制成本可能会累积。例如,在第一部分的图 3 中,species 列仅在扫描中评估过滤器时需要,而 notes 永远不会使用,因此通过计划的其余部分复制它们是不必要的。
投影下推对于列式存储数据库尤其有效和重要,因为列式存储数据库本身的存储格式(例如 Apache Parquet)支持高效地仅读取所需列的子集。它与过滤器下推结合使用时尤其强大。投影下推对于面向行的格式(如 JSON 或 CSV)仍然重要,但效果较差,因为即使计划中未使用每一行中的每一列,也必须对其进行解析。

图 2: 在 (A) 中,在没有投影下推的情况下,运算符接收更多列,降低了效率。在 (B) 中,在有投影下推的情况下,运算符接收更少的列,从而实现了优化的执行。
限制下推
原因:计划越早停止生成数据,总体工作量就越少,并且某些运算符具有更高效的有限实现。
内容: 尽早将限制(最大行数)下推到计划中。
示例实现: DataFusion、DuckDB、ClickHouse、Spark (Window 和 Projection)
通常,查询具有 LIMIT 或其他子句,允许它们提前停止生成结果,因此它们越早停止执行,执行效率就越高。
此外,DataFusion 和其他系统对某些运算符具有更高效的实现,如果存在限制,可以使用这些实现。经典的例子是用 TopK 运算符替换完全排序 + 限制,该运算符仅使用堆跟踪顶部值。同样,DataFusion 的 Parquet 读取器在达到限制后会停止获取和打开其他文件。  图 3:在 (A) 中,在没有限制下推的情况下,所有数据都被排序,并且除前几行外的所有数据都被丢弃。在 (B) 中,在限制下推的情况下,Sort 被 TopK 运算符替换,后者做的工作少得多。
图 3:在 (A) 中,在没有限制下推的情况下,所有数据都被排序,并且除前几行外的所有数据都被丢弃。在 (B) 中,在限制下推的情况下,Sort 被 TopK 运算符替换,后者做的工作少得多。
表达式简化/常量折叠
原因:当值不变时,为每一行评估相同的表达式是浪费的
内容:部分评估和/或代数简化表达式
示例实现: DataFusion、DuckDB(有多个 规则,例如 常量折叠和 比较简化)、Spark
如果表达式从一行到另一行没有变化,最好在规划期间一次评估它。这是一种数据库系统中使用的经典编译器技术。
例如,给定一个查询,查找当前年份的所有值
SELECT … WHERE extract(year from time_column) = extract(year from now())在每一行上评估 extract(year from now()) 比在规划时评估一次要昂贵得多,因此查询变为常量。
SELECT … WHERE extract(year from time_column) = 2025此外,通常可以将此类谓词推入扫描。
重写 OUTER JOIN → INNER JOIN
原因: INNER JOIN 实现几乎总是比 OUTER JOIN 实现更快(因为它们更简单)。INNER JOIN 对其他优化器传递(例如连接重排序和额外的过滤器下推)的限制更少。
内容:在 OUTER JOIN 引入的 null 行不会出现在结果中的情况下,可以将其重写为 INNER JOIN。
示例实现: DataFusion、Spark、ClickHouse。
例如,给定如下查询
SELECT …
FROM orders LEFT OUTER JOIN customer ON (orders.cid = customer.id)
WHERE customer.last_name = ‘Lamb’LEFT OUTER JOIN 保留 orders 中所有没有匹配客户的行,但用 null 填充字段。所有此类行都将被 customer.last_name = ‘Lamb’ 过滤掉,因此 INNER JOIN 产生相同的答案。如图 4 所示。

图 4:将 OUTER JOIN 重写为 INNER JOIN。(A) 中,原始查询包含 OUTER JOIN 和 customer.last_name 上的过滤器,该过滤器过滤掉所有可能由 OUTER JOIN 引入的行。(B) 中,OUTER JOIN 转换为内部连接,可以使用更高效的实现。
引擎特定优化
正如本博客的第一部分所讨论的,优化器还包含一组传递,这些传递始终是好的做法,但与查询引擎的特定性密切相关。本节介绍一些常见类型
子查询重写
原因:通过为外部查询的每一行运行查询来实现子查询非常昂贵。
内容:可以将子查询重写为连接,连接通常性能更好。
一次评估一行子查询非常昂贵,以至于 DataFusion 和 Vertica 等高性能分析系统中的执行引擎可能不支持一次评估一行,因为性能会非常糟糕。相反,分析系统将此类查询重写为连接,这对于大型数据集可以提高 100 倍或 1000 倍的速度。但是,将子查询转换为连接需要“特殊的”连接语义,例如 SEMI JOIN、ANTI JOIN 以及如何处理与 null 相等的变体1。
对于一个简单的示例,考虑如下查询
SELECT customer.name
FROM customer
WHERE (SELECT sum(value)
FROM orders WHERE
orders.cid = customer.id) > 10;可以将其重写为
SELECT customer.name
FROM customer
JOIN (
SELECT customer.id as cid_inner, sum(value) s
FROM orders
GROUP BY customer.id
) ON (customer.id = cid_inner AND s > 10);我们没有空间详细介绍此转换或解释为什么运行速度更快,但使用它和许多其他转换可以实现高效的子查询评估。
优化的表达式评估
原因:表达式评估的能力因系统而异。
内容:针对特定的执行环境优化表达式评估。
示例实现:此类优化有很多示例,包括 DataFusion 的 公共子表达式消除、unwrap_cast 和 识别相等连接谓词。DuckDB 重写 IN 子句和 SUM 表达式。Spark 也 解包二进制比较中的转换和 添加特殊的运行时过滤器。
为了给出一个 DataFusion 的公共子表达式消除的具体示例,请考虑这个查询,它多次引用一个复杂表达式
SELECT date_bin('1 hour', time, '1970-01-01')
FROM table
WHERE date_bin('1 hour', time, '1970-01-01') >= '2025-01-01 00:00:00'
ORDER BY date_bin('1 hour', time, '1970-01-01')每次遇到 date_bin('1 hour', time, '1970-01-01') 时都对其进行评估,与计算一次结果并在再次遇到时重用该结果相比效率低下(类似于缓存)。这种重用称为公共子表达式消除。
一些执行引擎在其表达式评估引擎内部实现了此优化,但 DataFusion 使用单独的 Projection 计划节点显式地表示它,如图 5 所示。实际上,上面的查询被重写为以下内容
SELECT time_chunk
FROM(SELECT date_bin('1 hour', time, '1970-01-01') as time_chunk
FROM table)
WHERE time_chunk >= '2025-01-01 00:00:00'
ORDER BY time_chunk
图 5: 添加 Projection 以评估公共复杂子表达式会降低后续阶段的复杂性。
算法选择
原因:不同的引擎针对某些操作具有不同的专用运算符。
内容: 根据查询的属性从可用运算符中选择特定的实现。
示例实现: DataFusion 的 EnforceSorting 传递使用排序优化的实现,Spark 的 重写使用 ASOF 连接的特殊运算符,ClickHouse 的 连接算法选择(例如 何时使用 MergeJoin)
例如,如果查询也有限制,DataFusion 使用 TopK(源)运算符而不是完整的 Sort。同样,当数据按组键排序时,它可能会选择使用更高效的 PartialOrdered 分组操作或 MergeJoin。  图 6: 分组专用操作的示例。在 (A) 中,输入数据没有指定的排序,DataFusion 使用基于哈希的分组运算符(源)来确定不同的组。在 (B) 中,当输入数据按组键排序时,DataFusion 使用专门的分组运算符(源)来查找分隔组的边界。
图 6: 分组专用操作的示例。在 (A) 中,输入数据没有指定的排序,DataFusion 使用基于哈希的分组运算符(源)来确定不同的组。在 (B) 中,当输入数据按组键排序时,DataFusion 使用专门的分组运算符(源)来查找分隔组的边界。
直接使用统计信息
原因:使用表中的预计算统计信息,而无需实际读取或打开文件,比处理数据快得多。
内容:用统计信息中的值替换对数据的计算。
示例实现: DataFusion、DuckDB
某些查询(例如用于数据探索的经典 COUNT(*) from my_table)可以使用统计信息来回答。优化器通常出于其他原因(例如访问路径和连接顺序选择)可以访问统计信息,并且统计信息通常存储在分析文件格式中。例如,Apache Parquet 文件的 元数据 存储 MIN、MAX 和 COUNT 信息。  图 7: 当聚合结果已存储在统计信息中时,可以使用统计信息中的值评估查询,而无需查看任何压缩数据。优化器用统计信息中的值替换聚合操作。
图 7: 当聚合结果已存储在统计信息中时,可以使用统计信息中的值评估查询,而无需查看任何压缩数据。优化器用统计信息中的值替换聚合操作。
访问路径和连接顺序选择
概述
最后但同样重要的是,优化是在具有潜在(非常)不同性能的计划之间进行选择的优化。此类别中的主要选项是
- 连接顺序: 应以什么顺序使用 JOIN 合并表?
- 访问路径: 应读取数据的哪个副本或索引来查找匹配的元组?
- 物化视图:查询是否可以重写为使用物化视图(部分计算的查询结果)?这个主题值得单独写一篇博客(或一本书);我们在此不再进一步讨论。
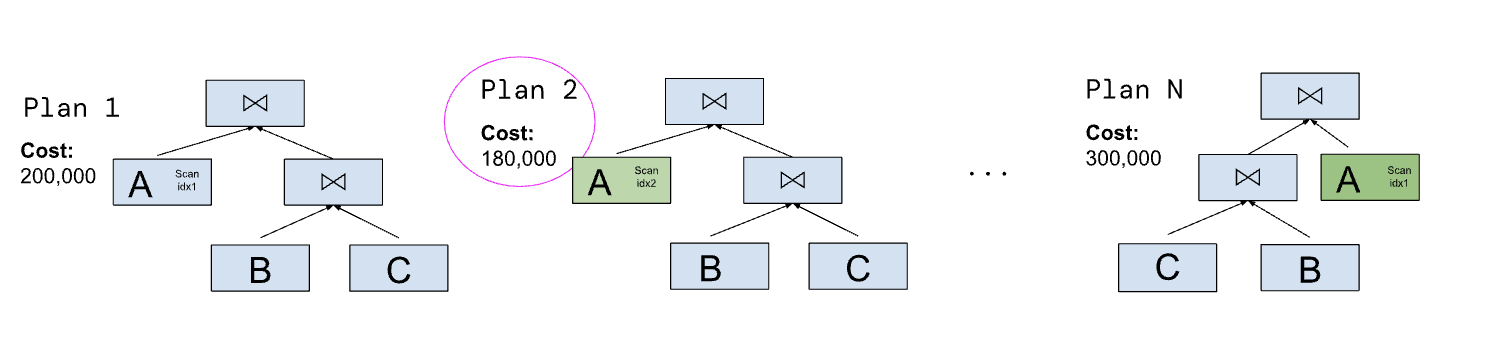 图 8: 访问路径和连接顺序选择查询优化器。优化器使用启发式方法枚举潜在连接顺序(形状)和访问路径(颜色)的某个子集。根据某些成本模型选择估计成本最低的计划。在本例中,选择成本为 180,000 的计划 2 执行,因为它具有最低的估计成本。
图 8: 访问路径和连接顺序选择查询优化器。优化器使用启发式方法枚举潜在连接顺序(形状)和访问路径(颜色)的某个子集。根据某些成本模型选择估计成本最低的计划。在本例中,选择成本为 180,000 的计划 2 执行,因为它具有最低的估计成本。
 图 8: 访问路径和连接顺序选择查询优化器。优化器使用启发式方法枚举潜在连接顺序(形状)和访问路径(颜色)的某个子集。根据某些成本模型选择估计成本最低的计划。在本例中,选择成本为 180,000 的计划 2 执行,因为它具有最低的估计成本。
图 8: 访问路径和连接顺序选择查询优化器。优化器使用启发式方法枚举潜在连接顺序(形状)和访问路径(颜色)的某个子集。根据某些成本模型选择估计成本最低的计划。在本例中,选择成本为 180,000 的计划 2 执行,因为它具有最低的估计成本。这类优化是一个难题,至少有以下原因
- 指数式搜索空间:潜在计划的数量随着连接和索引数量的增加而呈指数级增长。
- 性能敏感性:通常,结构非常相似的不同计划的性能可能差异很大。例如,交换哈希连接的输入顺序可能导致 1000 倍或更多(是的,千倍!)的运行时差异。
- 基数估计错误:确定最佳计划依赖于基数估计(例如,每个连接将输出多少行)。估计此基数是一个 已知的难题,并且在实践中,即使只有三个连接的查询也经常存在很大的基数估计错误。
启发式方法和基于成本的优化
工业优化器使用以下组合来处理这些问题
- 启发式方法: 裁剪搜索空间,避免考虑(几乎)永远不会好的计划。示例包括考虑左深树或使用
Foreign Key/Primary Key关系来选择哈希连接的构建大小。 - 成本模型:给定较小的候选计划集,优化器然后估计它们的成本并选择成本最低的那个。
对于一些示例,您可以阅读有关 Spark 的基于成本的优化器 的信息,或查看 DataFusion 的 连接选择 以及 DuckDB 的 成本模型 和 连接顺序枚举 的代码。
然而,启发式方法和(不精确的)成本模型的使用意味着优化器必须
- 对执行环境做出深刻的假设: 例如,启发式方法通常包括假设连接实现 侧向信息传递(RuntimeFilters) 或 Join 运算符始终保留特定的输入。
- 使用一个特定的目标函数: 在理想的计划属性(例如执行速度、内存使用和面对基数估计的鲁棒性)之间几乎总是存在权衡。工业优化器通常有一个成本函数,该函数试图在属性之间取得平衡,或者使用一系列难以使用的间接调整旋钮来控制行为。
- 需要统计信息:通常,成本模型需要最新的统计信息,这些信息可能计算成本高昂,必须随着新数据的到来而保持更新,并且通常难以捕获真实世界数据集的非均匀性。
DataFusion 中的连接排序
DataFusion 有意不包含复杂的基于成本的优化器。相反,为了与其 设计目标 保持一致,它提供了合理的默认实现以及自定义行为的扩展点。
具体来说,DataFusion 包括
- “语法优化器”(按照查询中列出的顺序连接2),具有基本的连接重排序(source),以防止连接灾难
- 支持 ColumnStatistics 和 Table Statistics
- 用于 过滤器选择性 + 连接基数估计的框架
- 用于轻松重写计划的 API,例如 TreeNode API 和 重排序连接
这些功能的组合,以及 自定义优化器传递,允许用户根据其用例自定义行为,例如自定义索引,如 uWheel 和 物化视图。
仅包含基本优化器的理由是,任何特定的启发式方法和成本模型都不太可能适用于各种 DataFusion 用户,因为他们有不同的权衡。
例如,一些用户可能始终可以访问足够的资源,希望获得最快的查询执行速度,并且愿意容忍运行时错误或在内存不足时出现性能悬崖。然而,其他用户可能愿意接受较慢的最大性能,以换取在资源受限环境中运行时更可预测的性能。这种方法并非普遍认同。我们中的一位 先前在更学术的论文中论证了专用优化器的案例,并且该主题经常在 DataFusion 社区中出现(例如,最近的评论)。
注意:我们正在 积极改进 代码的这一部分,以帮助人们编写自己的优化器(🎣 快来帮助我们定义和实现它!)
总结一下
优化器非常棒,我们希望这两篇文章已经揭开了它们的神秘面纱,并说明了它们在工业系统中的实现方式。与许多现代查询引擎设计一样,常用技术是众所周知的,尽管需要付出巨大的努力才能正确实施。DataFusion 的工业级强度优化器可以并且确实为许多现实世界的系统提供了良好的服务,我们预计这个数字会随着时间的推移而增长。
我们还认为 DataFusion 为优化器研究提供了有趣的机会。正如我们所讨论的,仍然存在未解决的问题,例如最佳连接排序。论文中的实验通常使用学术系统或修改开源但紧密集成的系统中的优化器(例如,最近的 POLARs 论文 使用了 DuckDB)。然而,这种风格意味着研究受限于这些特定系统提供的启发式方法和结构集。希望 DataFusion 的文档、新近可引用的 SIGMOD 论文 和模块化设计将鼓励在该领域进行更广泛适用的研究。
最后,与往常一样,如果您有兴趣从事查询引擎工作并了解更多关于它们的设计和实现,请 加入我们的社区。我们欢迎首次贡献者以及长期参与者一起享受构建数据库的乐趣。
-
有关更学术化的处理方法,请参阅 Neumann 和 Kemper 的 Unnesting Arbitrary Queries。
-
我从 Andy Pavlo 的 CMU 在线讲座中学到的我最喜欢的术语之一。
