OpenTelemetry 教程:使用 InfluxDB 3.0、Jaeger 和 Grafana 收集追踪、日志和指标
作者:Jay Clifford / Jacob Marble / 用例, 产品
2023 年 5 月 5 日
导航至
在 InfluxData,我们最近宣布了 InfluxDB 3.0,它扩展了 InfluxDB 可行的用例数量。为 InfluxDB 3.0 提供支持的新存储引擎的主要优势之一是它能够在一个数据库中存储追踪、指标、事件和日志。
每种类型的时间序列数据都有独特的工作负载,这留下了一些未解答的问题。例如
- 我应该遵循什么模式?
- 如何将我的追踪转换为行协议?
- InfluxDB 如何与更大的可观测性生态系统连接?
幸运的是,这就是我们在 OpenTelemetry 中所做的工作发挥作用的地方。如果您想了解更多关于 OpenTelemetry 的信息,我们推荐 Charles Mahler 的这篇博客。但是,本博客的目标是带您了解 OpenTelemetry 和 InfluxDB 3.0 的一个工作示例。
运行演示
让我们从有趣的部分开始,运行演示,然后讨论其背后的理论。以下是我们将要部署的演示
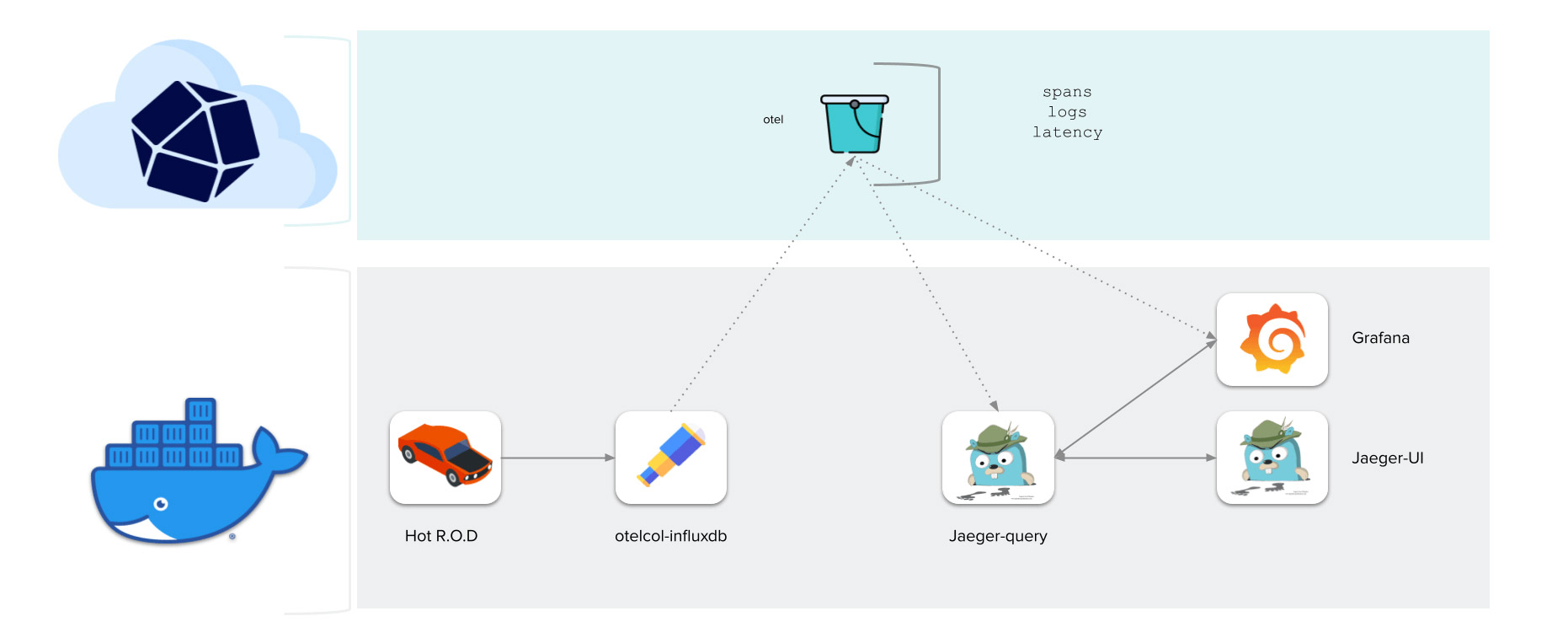
此演示使用 Hot R.O.D. 来模拟追踪、日志和指标。然后我们使用 OpenTelemetry Collector 收集这些数据并将其写入 InfluxDB 3.0。最后,我们使用 Grafana 和 Jaeger UI 以高度汇总的视图可视化这些数据。
要运行演示,您可以使用此 KillerCoda 演示环境。
只需创建一个帐户并按照教程运行演示,无需担心本地安装。对于本地安装,我们在 GitHub 仓库中提供了您需要的所有信息,因此请查看仓库自述文件以获取最新的安装说明。
演练
让我们通过 Killercoda 运行演示,以便您了解预期效果
- 您将在首次加载时看到演示配置脚本在运行。它应该不会花费太长时间。一旦出现
InfluxDB OTEL Demo,您就会知道它已完成加载。
- 如果您还没有帐户,请按照步骤创建免费的 InfluxDB 3.0 Cloud 帐户进行演示。
 确保按照说明在 InfluxDB 中创建一个名为
确保按照说明在 InfluxDB 中创建一个名为 otel的存储桶,并为新的otel存储桶生成读写令牌。 - 接下来,我们为 InfluxDB 3.0 提供凭据,以便演示可以从我们的
otel存储桶写入和查询。为此,请选择 Killercoda 中的Editor选项卡,并导航到influxdb-observability/.env。这是我们更新连接凭据的地方。注意:请确保更新 INFLUXDB_ADDR 以指向您的 InfluxDB Cloud 区域。此外,从地址中删除任何协议(例如,HTTPS://)。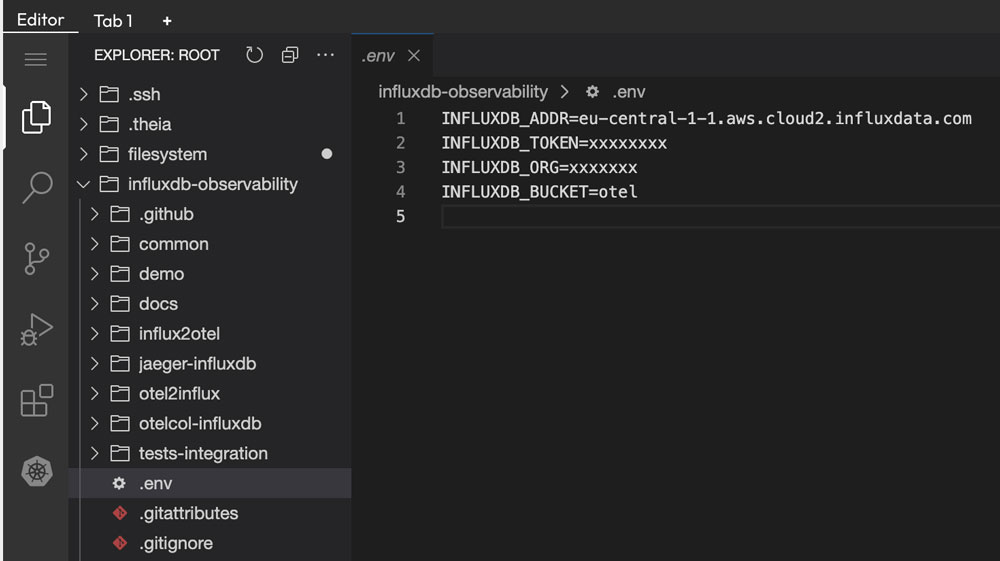
- 完成环境更新后,我们可以启动演示。只需单击此命令即可启动演示:

docker-compose --file demo/docker-compose.yml --project-directory - 现在我们进入有趣的部分!让我们生成一些追踪。首先,让我们打开 HotROD 应用程序。在本地安装中,它通过
localhost:8080运行。要在 Killercoda 中访问此地址,请按照以下屏幕截图中提供的超链接操作。
- 从那里我们可以通过单击不同的按钮开始生成追踪。每个按钮都模拟为指示的任务订购汽车,这将触发后台服务调用并创建追踪。

- 如果您转到您的 InfluxDB 3.0 Cloud 实例,您可以探索
otel存储桶模式,以了解我们如何将 OpenTelemtry 数据结构转换为 InfluxDB 的行协议,其中包括 measurements、tags 和 fields。(注意:我们将在下一篇博客中更深入地介绍行协议。)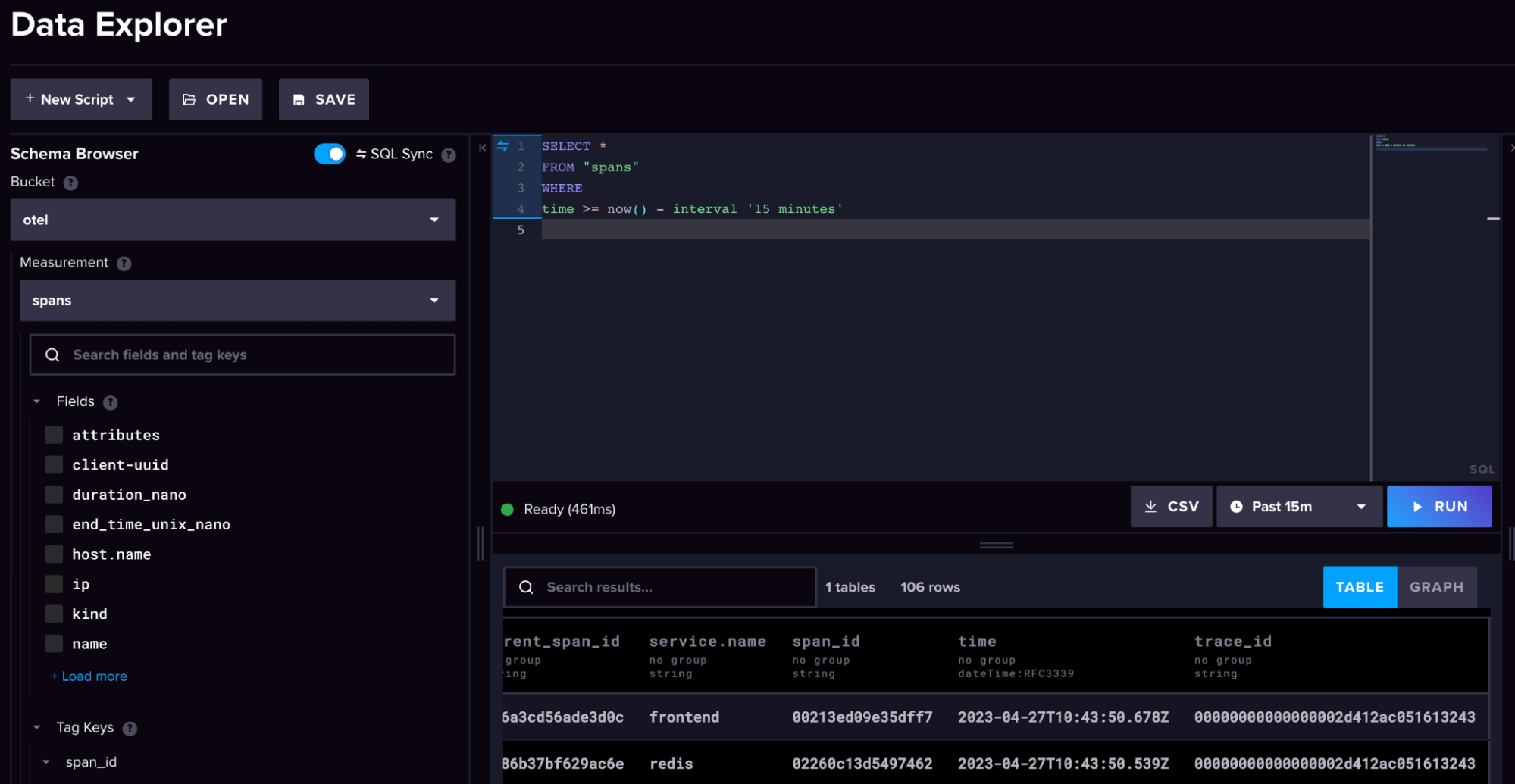
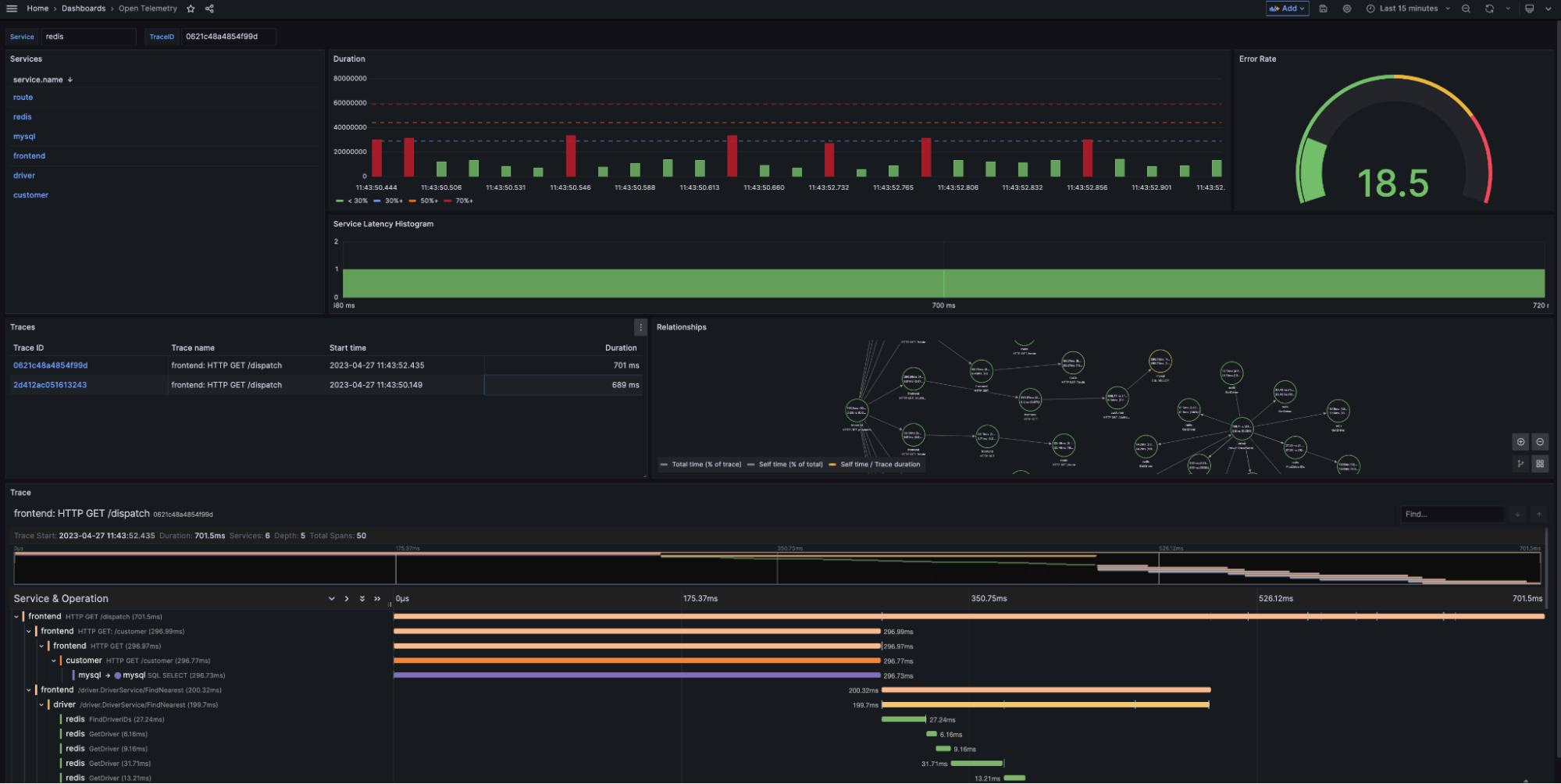
- 如果我们回到我们的 Killercoda 实例并打开 Grafana,我们可以探索我们的 OpenTelemetry 仪表板和配置。

 确保按照说明在 InfluxDB 中创建一个名为
确保按照说明在 InfluxDB 中创建一个名为 





Grafana 详解
本节分解了 Grafana 仪表板的一些主要功能。让我们从数据源开始。
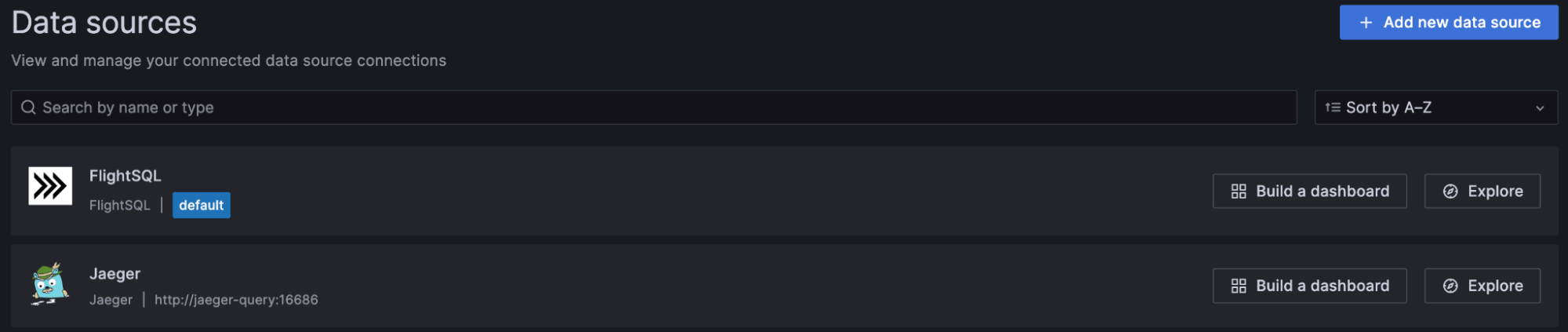
您可以看到,我们连接了两个数据源 - Flight SQL 和 Jaeger。这两个源都直接从 InfluxDB 3.0 拉取数据,但我们将在下一篇博客中更详细地讨论它们的工作原理和差异。现在,您只需要知道以下内容
- Flight SQL – 这是 InfluxDB 3.0 的直接 SQL 查询接口。它非常适合通用的基于时间序列的查询和指标摘要。
- Jaeger – 它充当 InfluxDB 3.0 和 Grafana 可视化之间指标、日志和追踪的桥接接口。
让我们再次查看我们的仪表板,并将我们的数据源映射到不同的面板。
我们使用 Flight SQL 来生成我们的通用导航和摘要概览
-
服务查询 InfluxDB 以查找在
otel存储桶中找到的所有唯一服务。我们将服务名称用作其余可视化的数据链接。例如,单击redis会将我的摘要结果和追踪列表过滤为仅包含服务redis。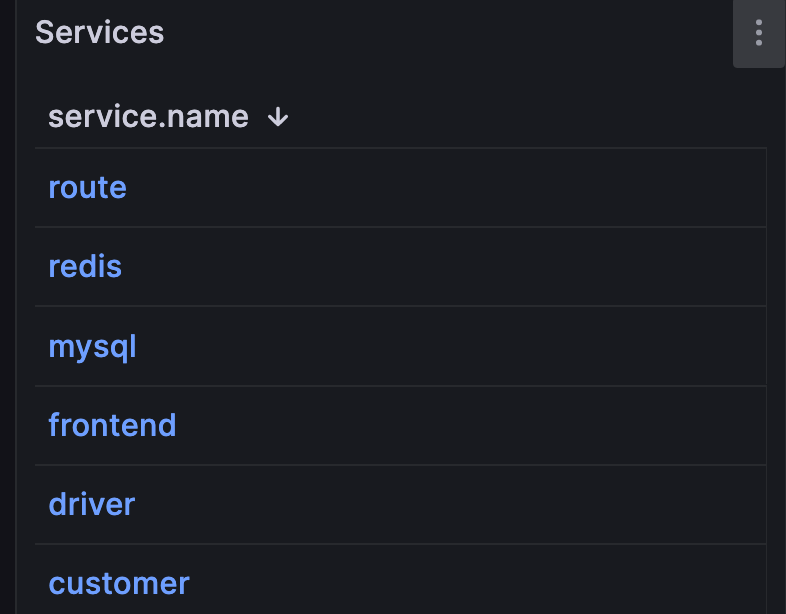
-
持续时间返回每个 spanID 在选定时间段内的持续时间(以纳秒为单位)。作为我们的 SQL 查询的一部分,我们将此值转换为秒以提高可读性。
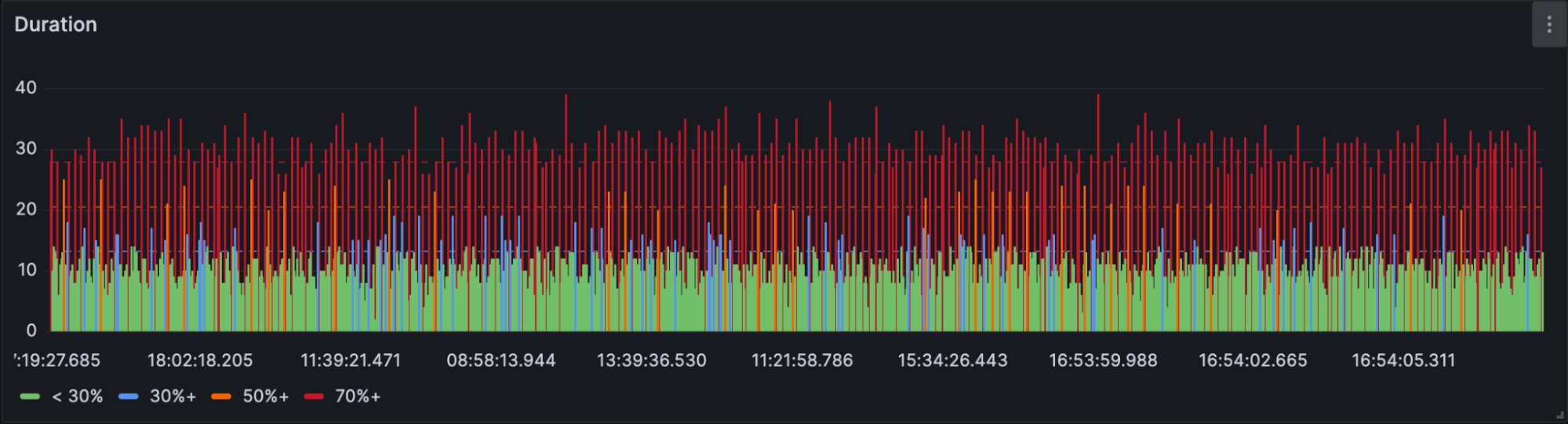
-
错误率根据
otel.status列中标记的错误数计算服务错误率(以百分比表示)。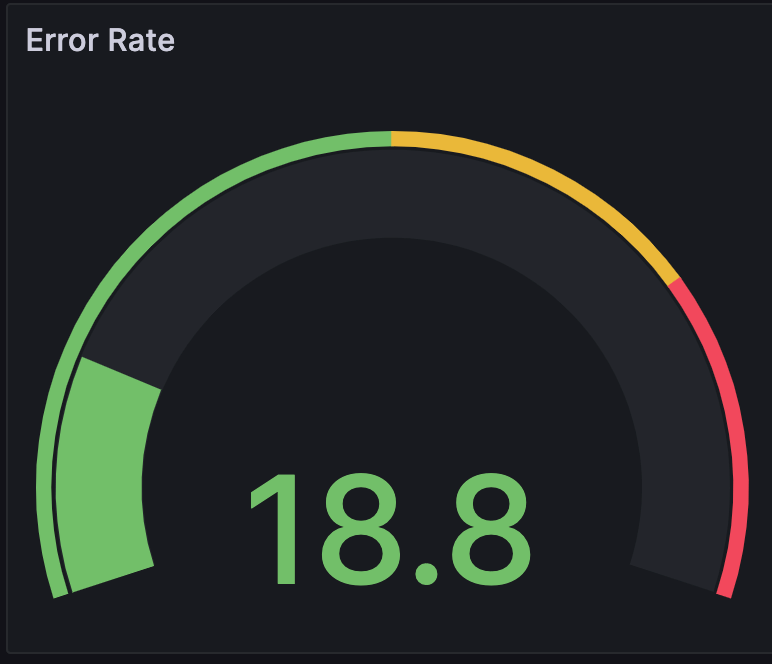



我们使用 Jaeger 通过以下可视化深入了解我们的追踪
- 服务延迟直方图根据服务中追踪的延迟创建直方图。此面板根据检测到的延迟范围对追踪 span 进行分组。

-
追踪提供与选定服务关联的追踪表。该表包括追踪名称、开始时间和持续时间。用户可以选择 TraceID 以生成接下来的两个可视化:关系和追踪。
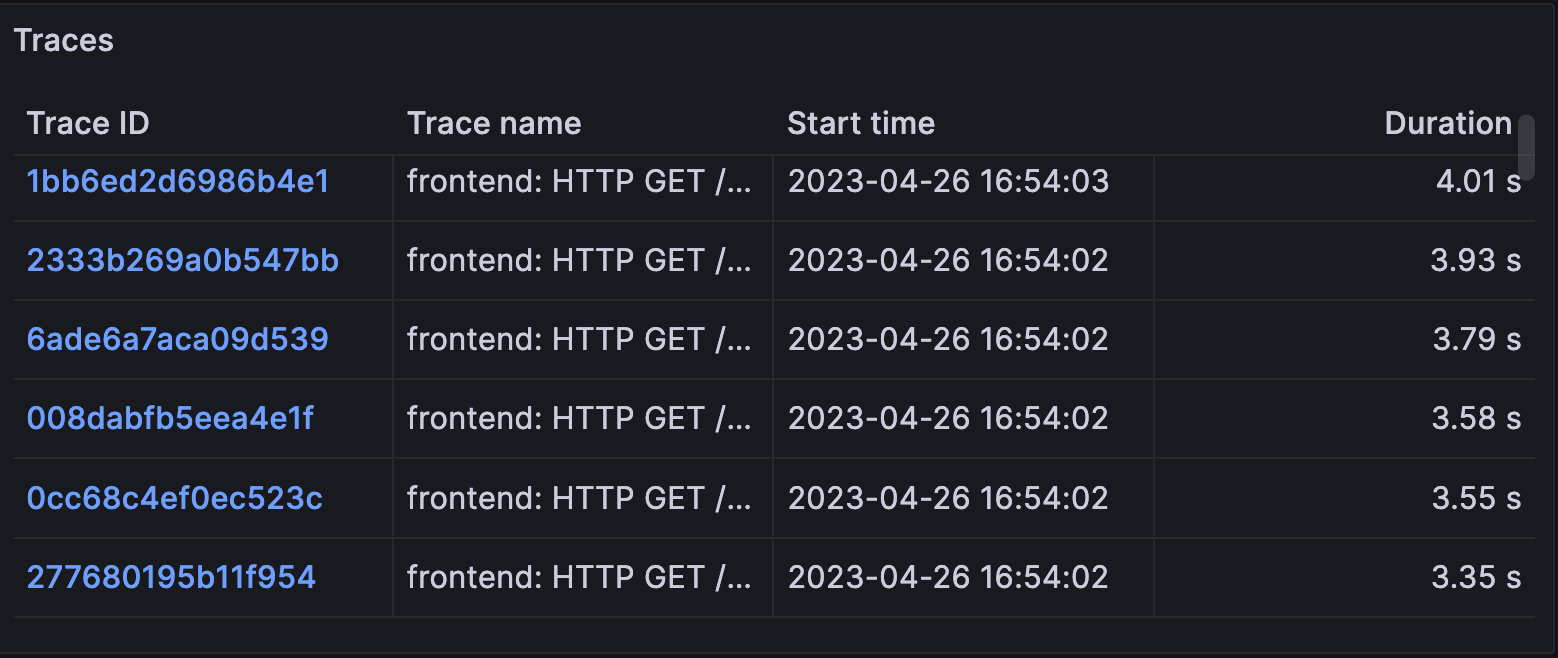
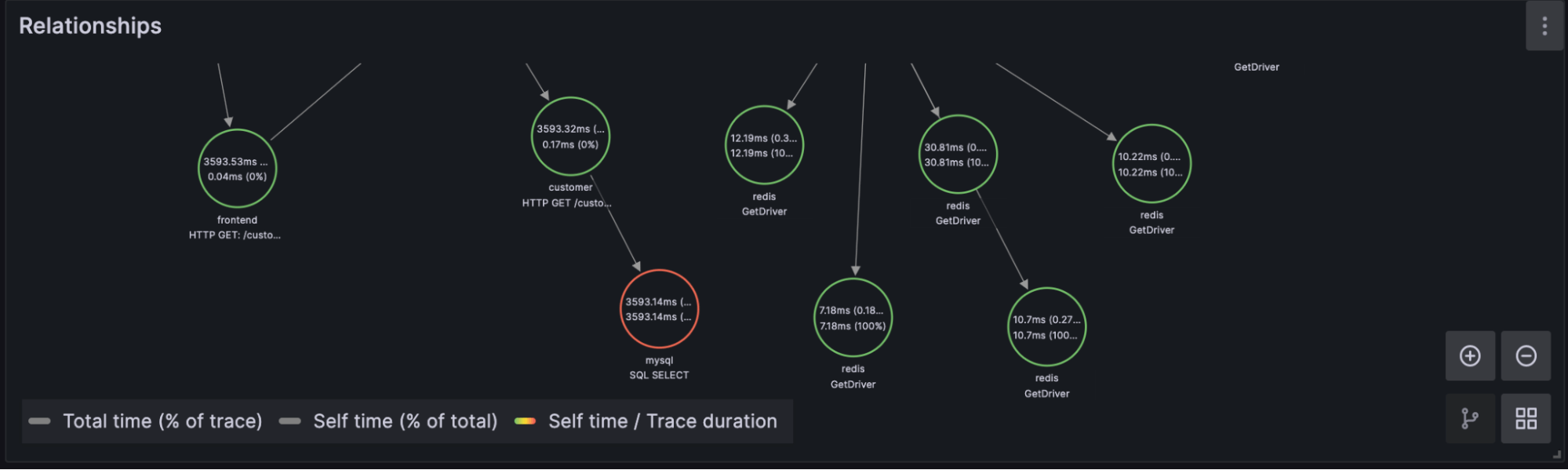
- 关系:在“追踪”面板中选择 TraceID 后,用户可以使用 span 树导航追踪中的 span 关系。我们将在下一篇博客中详细介绍这一点。
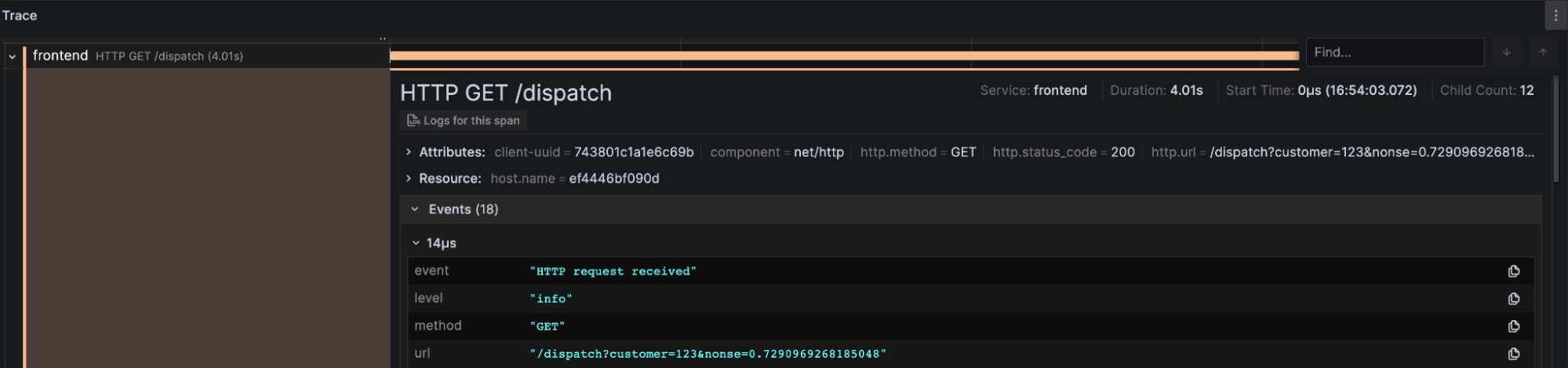
- 追踪:此面板允许用户导航选定 TraceID 的原始追踪数据及其关联的日志数据。




结论
我们希望本教程为您学习更多关于 OpenTelemetry 的知识以及 InfluxDB 3.0 将如何在未来的可观测性解决方案中发挥关键作用奠定坚实的基础。请继续关注下一篇博客,我们将深入探讨 OpenTelemtry 的理论,分解演示架构中的每个组件并讨论数据模式。在那之前,请试用演示,fork repo,看看您是否可以将这些组件应用于您自己的用例。如果您有任何问题,请随时在 Slack 上联系我们。
