MySQL 指标 Part I:吞吐量
作者:Katy Farmer / 开发者, 产品
2018 年 1 月 11 日
导航至
在理想的世界中,这篇博文是关于 MySQL 指标和监控 MySQL 中的吞吐量。但在现实中,这篇文章是关于理解数据可视化、适当查询和不断失败——作为副产品,我也在监控 MySQL 中的吞吐量。让我们开始吧。(注意:如果您只对吞吐量感兴趣,并且不关心我的失败,请跳过标记为“失败”的部分。)

您可能想要监控吞吐量有很多原因——也许您有加载时间慢、连接断开、服务器崩溃,或者您只是好奇。但在您遇到问题之前,您可以监控吞吐量以深入了解您的流量。
与往常一样,我将使用我的业余项目 Blogger(再次说明,不是可工作、完全可用的 Blogger.com,而是我自己的可悲状态的 Blogger)。我可以整天谈论监控在理论上的用途,但这并不意味着我可以用原力举起 X 翼战机。让我们深入探讨如何开始监控吞吐量。
您可以选择任何您喜欢的工具来可视化数据——您甚至可以不使用任何工具,而是使用终端和您的大脑来分析数据。我将在我的示例中使用 Chronograf,因为这是我最熟悉的工具。
设置
我正在使用 Telegraf 和 InfluxDB 的组合将指标发送到 Chronograf。如果您需要帮助设置 Telegraf 的 MySQL 输入插件,您可以参考这篇 博文 的“配置 Telegraf”部分。流程如下所示

可视化
在 Chronograf 中,我将使用数据浏览器来,嗯,探索数据。
我从 DB 列表中选择我的数据库 (mysql-monitor),然后从列表中选择 mysql 测量。这为我们提供了来自 MySQL 的所有可用指标,这非常多。非常多是一种轻描淡写的说法。如果我是史高治·麦克老鸭,我可以在装满 MySQL 指标的金库里游泳。如果每个指标都是一把折叠椅,您都会希望这是摔跤狂热大赛。

您明白我的意思了。
我们专注于吞吐量,因此一个好的起点是问题和查询。在我之前的文章中,我们讨论了这些如何反映流量。它也可以作为至少一切都已启动并运行的测试。
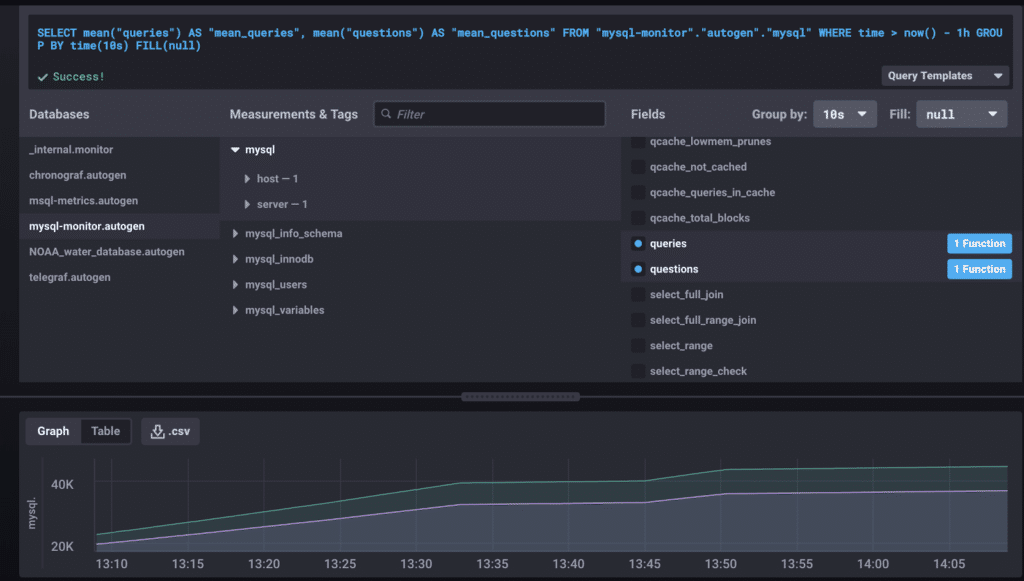
此图表显示了过去一小时,我们可以看到逐渐上升的趋势。老实说,即使如此漂亮地呈现,这些数据对我来说也没有多大意义。拥有 4 万个查询是好还是坏?数据需要上下文。
进入失败 #1
查看图表,我们可以看到查询量达到 4 万左右的峰值,但当我在之前的文章中统计问题和查询时,它们分别为 282590 和 294564。当时,这些数字对我来说没有用处,但现在我从我的监控过程中获得了更多数据点,我有了一个事件的证据。
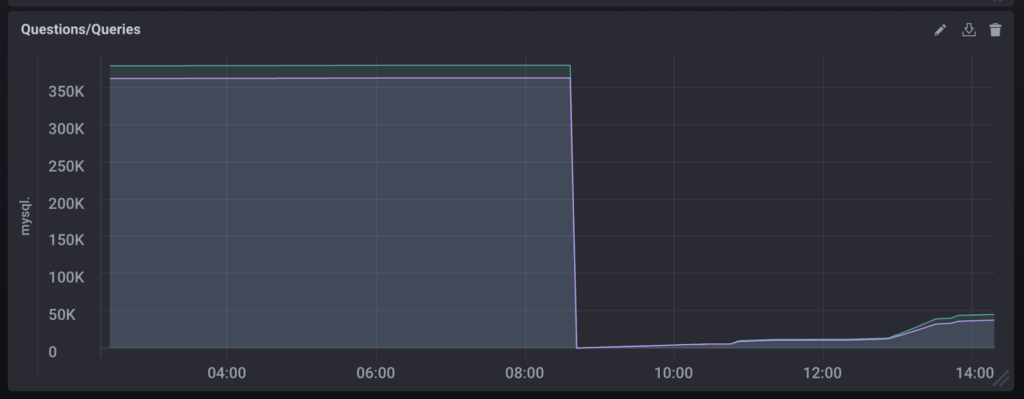
这是一个好消息/坏消息的情况。好消息:良好的监控实践让我意识到了一个可能的问题。坏消息:8:30 发生了什么?问题和查询都被重置为零。
查询
让我说一下,我不确定这是否值得追求。下降之后,系统似乎恢复了正常行为。但是,我发现从错误中学习比从正常行为中学习更容易。如果我们没有上下文,没有比较点,那么我们就不知道正常行为是什么样的。所以让我们变得异常。

调查
现在,问题和查询实际上只是一种健全性检查。它们给了我们一个模糊的流量概念,但它们没有给我们细节。我们看到了可怕的瀑布,但它非常笼统。放大数据可能会让我们了解是什么导致了下降,而每秒读取/写入次数最有可能告诉我们吞吐量是否导致了下降。
问题是:我不知道如何找到每秒读取/写入次数。但我有 Influx Query Language 文档和互联网,所以我并非没有选择。
首先,我做了我们都会做的事情:我谷歌了一下。有很多结果,但最有用且最终正确的答案是在 GitHub 上的 InfluxDB 问题中。实话实说:我快速浏览了对话,复制了查询,做了一些非常小的更改,然后将其弹出到我的 Chronograf 数据浏览器中。
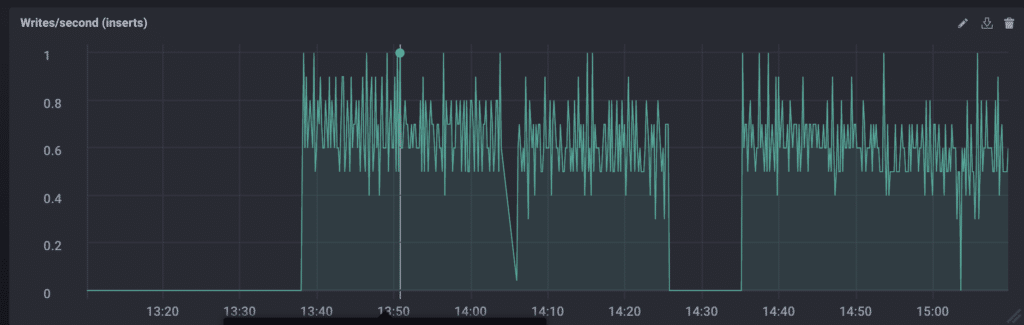
失败 #2
这是一个个人失败。我有一个有效的查询,我可以轻松地修改它以用于写入,如您在上面看到的。但是使用我不理解的代码不是前进的方向。我觉得尤达会对我感到失望,这是一个我需要重新评估我的行为的迹象。如果我要使用这个查询,我就要理解它。
这是查询
SELECT non_negative_derivative(first("commands_select"), 1s)
AS "mean_commands_select"
FROM "mysql-monitor"."autogen"."mysql"
WHERE time > :dashboardTime: -1h
GROUP BY time(10s) FILL(null)
它包含了很多东西。InfluxQL 类似于 SQL,所以我依赖于我对 SQL 的了解(这就像一个扎实的 B+)。
SELECT这非常不言自明。SELECT 语句之后的所有内容都构成了我们希望返回的内容。
SELECT non_negative_derivative听听那个。那是一位开发者倡导者开始崩溃的声音,因为她意识到她在查询中只进行了两个词,所有势头都消失了。

不用担心。让我们去找文档。
来自 关于 non_negative_derivative 的条目
“返回后续 字段值 之间的非负变化率。非负变化率包括正变化率和等于零的变化率。”
变化率是有道理的。事实上,这正是我们试图用每秒读取次数来衡量的:从一秒到下一秒读取次数的变化率。
SELECT non_negative_derivative(first("commands_insert"), 1s)在 InfluxDB 中,FIRST 指的是具有最旧时间戳的条目。这是我可以理解的那种清晰定义。在本例中,我们想要 commands_insert(这是我们的写入指标之一)中的第一个条目。
第二个参数 (1s) 向 derivative 函数指定我们想要测量变化的速率。如果我们想每十秒测量一次写入,我们可以将其替换为 10s。
SELECT non_negative_derivative(first("commands_insert"), 1s)
AS "writes per sec"
FROM "mysql-monitor"."autogen"."mysql"
WHERE time > :dashboardTime: -1h
AS 为我们提供了一个别名,如果我们以后需要再次引用此函数,这将非常有用。
FROM 指定我们正在查询的数据库。“autogen”部分是 Chronograf 添加的默认值。
WHERE 是限定符,表示:只给我带来满足这些条件的结果。在我们的例子中,我们只想看到时间字段大于变量 :dashboardTime:(Chronograf 生成的变量,默认为一小时)减去一小时的条目。这有点难以理解,但我目前的看法是它只是更改您在结果中看到的时间窗口。从 :dashboardTime: 中减去一小时意味着没有偏移。
SELECT non_negative_derivative(first("commands_insert"), 1s)
AS "writes per sec"
FROM "mysql-monitor"."autogen"."mysql"
WHERE time > :dashboardTime: -1h
GROUP BY time(10s) FILL(null)
最后,我们到达了 GROUP BY。本质上,我们正在制作十秒桶,然后应用所有先前的函数。每隔十秒,获取第一个条目并找到每秒之间的变化率。
FILL 是我们可以设置的一个选项,用于告诉查询在缺少数据的情况下该怎么做。Null 是一个不错的选择,因为它不会歪曲数据。
结果
值得注意的有趣之处在于,使用 non_negative_derivative 实际上掩盖了我们正在调查的事件。用 derivative 替换 non_negative_derivative 会导致以下图表。
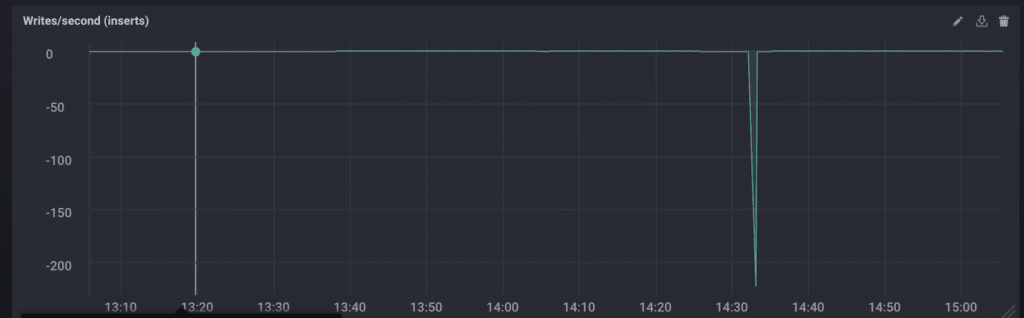
是的,上面写着 -200。其余数据被该下降倾斜得如此严重,以至于看起来相对稳定(范围约为 0-8 次写入/秒)。更真实的是:这时我意识到我当天早些时候重启了我的笔记本电脑来安装更新。本地运行真的又回来踢了我的 Blogger 一脚。
即便如此,使用和不使用负值测量每秒读取/写入次数向我展示了两件事:1) 仍然只有一个异常数据点,以及 2) 当该点被移除时,读取/写入次数非常一致。
数据中的模式对我来说比单个值更有意义,因此知道 Blogger 有规律的心跳意味着它正在按预期工作。

结论
尽管一路上有很多失败和分心,但吞吐量被证明是监控和调查我的数据的宝贵工具。可视化数据帮助我看到了趋势和疯狂事件,并帮助我确定我是否应该关心这些事情。
在下一篇文章中,我们将研究执行时间,最后的真相:我希望它不像吞吐量那样令人情绪疲惫。
