MQTT 与 Kafka:物联网倡导者的视角(第 3 部分 - 天作之合)
作者:Jay Clifford / 产品, 用例
2022 年 6 月 28 日
导航至
我们来到了...最后一章。在本系列的第 2 部分中,我们开始深入研究使 Kafka 变得出色的某些概念。我们的结论是,尽管 MQTT 和 Kafka 之间的术语相似(例如主题),但它们在底层的工作方式却大相径庭。我们还简要概述了 Kafka Connect,以及如何使用一些企业连接器将数据流式传输到其他平台。
然而,我们确实了解到 Kafka 存在一些缺点
-
Kafka 专为部署良好基础设施的稳定网络而构建。
-
它不部署关键的数据交付功能,例如 Keep-Alive 和 Last Will。
MQTT 来解救了!
正如本最终博客文章中所承诺的那样,我们将着眼于在 MQTT、Kafka 和 InfluxDB 之间创建完整的混合架构。
在开始之前,这里有一些准备工作
这是我的计划:
在此架构中,我们将
-
将我们的原始生成器数据直接发送到 MQTT 代理(Kafka MQTT 代理)。我们将继续使用第 2 部分中的主题层次结构。
-
Kafka MQTT 代理将数据桥接到我们的 Kafka 集群。
-
然后,我们将利用 InfluxDB 同步连接器将数据发送到 InfluxDB Cloud(如果您是主机,则发送到 InfluxDB OSS)。
-
从那里,我们将结合使用 InfluxDB 源连接器和 Flux 来对我们的数据进行降采样和聚合(然后再将转换后的数据发送回新的 Kafka 主题以供进一步消费)。
有很多事情要做,但谁不喜欢挑战呢!让我们开始行动吧。
发电机模拟器 + MQTT 代理
在 InfluxDB Roadshow 之后,我对发电机模拟器进行了一些很酷的更改
-
为输出的结果添加了更好的逻辑
-
添加了一些新字段:负载 + 功率
-
添加了 Docker 支持
您可以在此处找到第 3 部分的存储库。
现在进行重大更改...我们已从架构中删除了 Mosquitto 代理。我知道您在想什么。您在世界上的什么地方连接 MQTT 客户端?让我向您介绍 MQTT 代理。
那么 MQTT 代理到底是什么?我必须承认文档有点稀疏(我花了一个小时左右的时间才弄清楚它到底是如何工作的)。因此,我认为解释一下我认为它的工作方式与它实际的工作方式之间的区别会很有趣。
我认为它的工作方式 
它的实际工作方式 
很酷,对吧?因此,我认为 MQTT 代理本质上是一个秘密 MQTT 客户端,它将连接到您当前的代理。然后,您将指定要从中提取的主题,然后一些黑魔法会发生,将有效负载映射到 Kafka 主题。但实际上,MQTT 代理本质上是一个秘密 MQTT 代理,带有附加的 Kafka 功能。这允许我们的 MQTT 客户端直接连接到它。
配置
现在我们有了一些背景知识,让我们来谈谈配置。以我无限的智慧,我决定使用 Docker 容器来设置此架构。如果我可以回到过去,我只会本地安装 Confluent Kafka 并完成它。通过一线希望,我现在可以与您分享我的配置!
version: '3.9'
services:
generators:
image: emergency-generator:latest
environment:
- GENERATORS=3
- BROKER=kafka-mqtt-proxy
networks:
- mqtt
kafka-mqtt-proxy:
image: confluentinc/cp-kafka-mqtt
networks:
- mqtt
environment:
- KAFKA_MQTT_BOOTSTRAP_SERVERS=pkc-l6wr6.europe-west2.gcp.confluent.cloud:9092
- KAFKA_MQTT_KEY_CONVERTER=org.apache.kafka.connect.storage.StringConverter
- KAFKA_MQTT_VALUE_CONVERTER=org.apache.kafka.connect.json.JsonConverter
- KAFKA_MQTT_VALUE_CONVERTER_SCHEMAS_ENABLE=false
- KAFKA_MQTT_SSL_ENDPOINT_IDENTIFICATION_ALGORITHM=https
- KAFKA_MQTT_SECURITY_PROTOCOL=SASL_SSL
- KAFKA_MQTT_SASL_MECHANISM=PLAIN
- KAFKA_MQTT_SASL_JAAS_CONFIG="org.apache.kafka.common.security.plain.PlainLoginModule required username="######" password="######";
- KAFKA_MQTT_REQUEST_TIMEOUT_MS=20000
- KAFKA_MQTT_RETRY_BACKOFF_MS=500
- KAFKA_MQTT_PRODUCER_BOOTSTRAP_SERVERS=pkc-l6wr6.europe-west2.gcp.confluent.cloud:9092
- KAFKA_MQTT_PRODUCER_SSL_ENDPOINT_IDENTIFICATION_ALGORITHM=https
- KAFKA_MQTT_PRODUCER_SECURITY_PROTOCOL=SASL_SSL
- KAFKA_MQTT_PRODUCER_SASL_MECHANISM=PLAIN
- KAFKA_MQTT_PRODUCER_SASL_JAAS_CONFIG=org.apache.kafka.common.security.plain.PlainLoginModule required username="######" password="######";
- KAFKA_MQTT_PRODUCER_REQUEST_TIMEOUT_MS=20000
- KAFKA_MQTT_PRODUCER_RETRY_BACKOFF_MS=500
- KAFKA_MQTT_OFFSET_FLUSH_INTERVAL_MS=10000
- KAFKA_MQTT_OFFSET_STORAGE_FILE_FILENAME=/tmp/connect.offsets
- KAFKA_MQTT_LISTENERS=0.0.0.0:1883
- KAFKA_MQTT_TOPIC_REGEX_LIST=emergency_generators:.*
- KAFKA_MQTT_CONFLUENT_TOPIC_REPLICATION_FACTOR=1
networks:
mqtt:
name: mqtt为了稍微解释一下,我的 Kafka 集群仍然托管在 Confluent Cloud 中并由其维护。我在我的笔记本电脑上本地运行此 docker-compose。因此,本质上我们有一个混合架构,通过 MQTT 代理进行边缘到云的通信。让我们分解一下 docker-compose 文件
generators: 这是我们的发电机模拟器,我不会在此花费任何时间。环境变量允许您选择要 MQTT 客户端连接到的代理以及要启动的生成器数量。
Kafka-mqtt-proxy: 因此,如果您熟悉 Kafka 配置,您就会知道您通常需要定义如下属性文件
properties
topic.regex.list=temperature:.*temperature, brightness:.*brightness
listeners=0.0.0.0:1883
bootstrap.servers=PLAINTEXT://:9092
confluent.topic.replication.factor=1在处理 Confluent Kafka 容器时,这会被稍微抽象化。相反,我们必须将它们定义为环境变量。我将在此处链接文档此处。经验法则
- 全部大写
- . 替换为 _
- 所有环境变量都附加了服务名称。文档将在此处指导您,但在我们的示例中,它是:KAFKA_MQTT
现在进入环境变量的内容。我将把它们分为两类,因为使用的大部分环境变量用于连接和验证 Confluent Cloud
-
Confluent Cloud 身份验证:其中大部分可以由 Confluent Cloud 自动生成。
 如果您使用 Docker,则需要将属性转换为 docker 环境变量格式。或者,更好的是,您可以使用我的环境变量并替换以下内容
如果您使用 Docker,则需要将属性转换为 docker 环境变量格式。或者,更好的是,您可以使用我的环境变量并替换以下内容- KAFKA_MQTT_BOOTSTRAP_SERVERS
- KAFKA_MQTT_SASL_JAAS_CONFIG(用户名 + 密码)
- KAFKA_MQTT_PRODUCER_SASL_JAAS_CONFIG(用户名 + 密码)
-
MQTT 代理:因此,您可以在此处添加相当多的参数。我将在此处留下完整列表此处。对于此博客,我们使用的是基本知识
- KAFKA_MQTT_LISTENERS:代理将侦听客户端的端口。在我们的示例中,我们使用的是未经身份验证的 1883。您可以将 TLS 8883 与适当的配置一起使用。
- KAFKA_MQTT_TOPIC_REGEX_LIST:这是 MQTT 主题如何映射到 Kafka 主题。经验法则
<KAFKA_TOPIC_NAME>:.<MQTT_REGEX>。尽管这不是一个好的做法,但我建议从根级别开始使用通配符(如果可以),以确保您正在收集数据,然后再相应地缩小您的主题范围。 - KAFKA_MQTT_CONFLUENT_TOPIC_REPLICATION_FACTOR:您的有效负载应复制多少次。在生产级别,建议至少 3 次。
 如果您使用 Docker,则需要将属性转换为 docker 环境变量格式。或者,更好的是,您可以使用我的环境变量并替换以下内容
如果您使用 Docker,则需要将属性转换为 docker 环境变量格式。或者,更好的是,您可以使用我的环境变量并替换以下内容InfluxDB 同步连接器 -> InfluxDB-> Influx 源连接器
因此,我们已经启动并运行了物联网数据管道架构的第一阶段。现在我们可以开始在如何处理数据方面发挥更多创意。让我们从原始图表中向下钻取一层,看看我们试图实现的目标:
因此,在此架构中,InfluxDB 已发展成为不仅仅是一个数据存储。这是数据旅程
- 首先,我们使用 InfluxDB 同步连接器将数据写入 InfluxDB 存储桶 Kafka_raw。因此,根据您的有效负载格式,您可以定义哪些字段应为标签,但我们受到 MQTT 代理的限制。我们将把它留给 Flux 任务。
- 接下来,我们将使用 Flux 任务从我们的原始存储桶中收集新写入的数据,并执行以下丰富任务
- 我们通过选择自上次任务运行以来每个生成器的最后一个样本来聚合我们的数据。
- 然后,我们创建一个名为 alarm 的新字段。我们将根据每个生成器当前的燃料油位计算警报级别。
- 我们将设置一个名为 region 的新标签。
- 我们将丰富的数据存储在我们的第二个存储桶 Kafka_downsampled 中。
- 最后,我们将使用 InfluxDB 源从 Kafka_downsampled 中查询数据,并将其发布到新的 Kafka 主题以供进一步消费。
配置
让我们摇滚起来。
InfluxDB 同步连接器
这部分非常简单
- 我们选择 InfluxDB 2 Sink Plugin。
- 填写论坛以构建连接器属性。它应该看起来像这样
{ "name": "InfluxDB2SinkConnector_0", "config": { "topics": "emergency_generators", "input.data.format": "JSON", "connector.class": "InfluxDB2Sink", "name": "InfluxDB2SinkConnector_0", "kafka.auth.mode": "KAFKA_API_KEY", "influxdb.url": "https://us-east-1-1.aws.cloud2.influxdata.com", "influxdb.org.id": "05ea551cd21fb6e4", "influxdb.bucket": "kafka", "measurement.name.format": "genData", "tasks.max": "1" } } - 您现在应该看到数据出现在您的 InfluxDB 存储桶中。如果您看到数据进入 DLQ,这通常是由于选择了错误的数据格式。

Flux 任务
现在我们可以开始丰富我们的数据了
- 创建一个新任务。
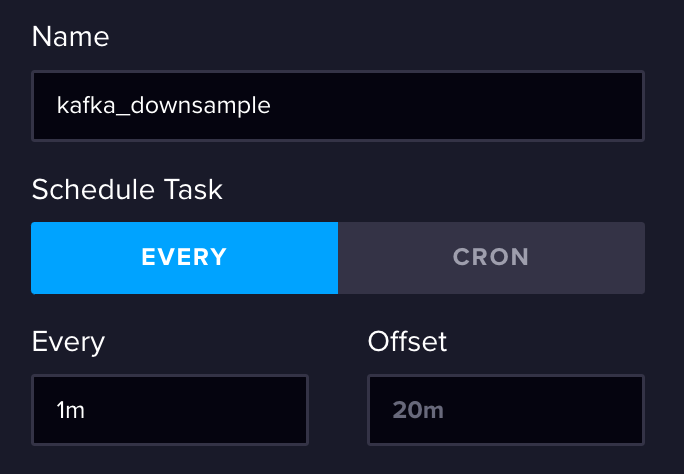
- 让我们给它一个名称和一个触发时间。我们希望我们的聚合数据能够及时合理地生成,所以我选择了 1 分钟的间隔。
- 现在让我们创建任务


import "influxdata/influxdb/tasks"
option task = {name: "kafka_downsample", every: 1m, offset: 0s}
from(bucket: "kafka")
|> range(start: tasks.lastSuccess(orTime: -1h))
|> filter(fn: (r) => r["_measurement"] == "genData")
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
|> group(columns: ["generatorID"], mode: "by")
|> last(column: "fuel")
|> map(fn: (r) => ({r with alarm: if r.fuel < 500 then "refuel" else "no action"}))
|> set(key: "region", value: "US")
|> to(
bucket: "kafka_downsampled",
tagColumns: ["generatorID", "region"],
fieldFn: (r) =>
({
"alarm": r.alarm,
"fuel": r.fuel,
"lat": r.lat,
"lon": r.lon,
"power": r.power,
"load": r.load,
"temperature": r.temperature,
}),
)快速分解
-
我们使用 range() + tasks.lastSuccess 在上次任务运行后收集一系列数据。如果是第一次运行,我们默认使用静态值 (-1h)
-
接下来,我们过滤测量 genData 下的所有数据。
-
Pivot() 用于将垂直存储的值转换为水平格式,这类似于使用 SQL 数据库。(这对于使用我们的 map 函数非常重要)。
-
我们按 generatorID 列进行 group()。这会将每个生成器的数据分隔到自己的表中。
-
Last() 将选择并返回每个表的最后一行。
-
然后,我们使用 map() 和一些条件逻辑来检查我们当前的燃油油位。我们创建一个名为 alarm 的新列。警报值将根据条件逻辑填充。
-
set() 允许我们创建一个新列并手动用相同的值填充每一行。
-
最后,to() 允许我们将数据传输到 kafka_downsampled。我们提供了一些映射逻辑来定义哪些列是字段和标签。
InfluxDB 源连接器
最后,让我们将此数据流式传输回 Kafka 主题
- 我们选择 InfluxDB 2 源插件。
- 填写论坛以构建连接器属性。它应该看起来像这样
{ "name": "InfluxDB2SourceConnector_0", "config": { "connector.class": "InfluxDB2Source", "name": "InfluxDB2SourceConnector_0", "kafka.auth.mode": "KAFKA_API_KEY", "influxdb.url": "https://us-east-1-1.aws.cloud2.influxdata.com", "influxdb.org.id": "05ea551cd21fb6e4", "influxdb.bucket": "kafka_downsampled", "mode": "timestamp", "topic.mapper": "bucket", "topic.prefix": "EG", "output.data.format": "JSON", "tasks.max": "1" } } - 我们现在应该能够开始看到通过主题消息面板从我们的存储桶中提取的数据。请注意,我们在源配置“mode: timestamp”中启用了一个非常酷的功能。这将检查发送到 Kafka 主题的最后一个时间戳,并且仅返回此后的样本。您也可以使用批量模式。

结果和展望
因此,尽管视觉效果不佳,但这是结果
原始

已丰富

我认为这其中的含义非常有趣
-
它展示了一个架构,其中 InfluxDB 不是数据旅程的最后一步。
-
我们展示了一个解耦架构的绝佳示例,在该架构中,我们可以在 InfluxDB 中修改数据转换的行为,而无需修改架构的其他阶段。
-
总而言之,这个非常基本的示例在计划后花费了 1-2 个小时才完成。设置此架构的代码阈值也非常低。
我们做到了!我们已经到达了关于 MQTT 与 Kafka 的三部分系列的结尾。编写这个博客系列教会了我很多东西!第一个重大发现是标题应该更改:MQTT 与 Kafka -> MQTT 和 Kafka:物联网的混合架构。说真的,让我们总结一下
- 在第 1 部分中,我们学习了基础知识,我试图直接将 MQTT 与 Kafka 进行比较。从表面上看,它们共享相似的术语
- 主题和代理
- 发布者和订阅者
- 在第 1 部分中,很明显,将 Kafka 视为 MQTT 相当于用法拉利发动机为电动滑板车提供动力。我们利用的使 Kafka 成为如此有趣的流协议的功能非常少。
- 在第 2 部分中,我们更深入地研究了 MQTT 和 Kafka 之间的差异。例如,我们深入研究了主题和分区的概念。我们还通过 Kafka connect 了解了企业连接器。
- 结论还认为,尽管 Kafka 具有许多强大的功能,但它在物联网架构中确实存在一些缺点
- Kafka 专为部署良好基础设施的稳定网络而构建。
- Kafka 不部署关键的数据交付功能,例如 Keep-Alive 和 Last Will。
我们现在已经构建了一个架构,该架构保留了 MQTT 为物联网架构提供的优势(轻量级、专为连接不良而构建,并有效处理数千个连接)。然后,我们使用 Kafka 对 MQTT 进行了补充,从而提升了;高可用性、高吞吐量和企业级连接器。最后,我们展示了如何包含 InfluxDB 以通过提供;扩展的存储和数据转换功能来增强我们的物联网数据管道。
因此,我希望您像我写它一样喜欢这个系列。我坚信学习新事物的唯一方法就是尝试!理论只能让您走到这一步。我还想分享社区的这个小见解,我认为这真的很棒。有一家名为 WaterStream 的公司正在提供 Kafka 和 MQTT 之间更深层次的集成。他们制作了这个超级酷炫的演示,值得一看!
因此,下次再见,请尝试一下!从我们的社区存储库下载代码,让我知道您的想法。谁知道呢?如果有足够的反馈,我们也许能够启动第 4 部分社区版。
一些思考...
在上面的示例中,我们严重依赖 Kafka 基础设施来传输我们的数据。至关重要的是,Kafka 为我们提供了一种可行的方式来将数据从边缘传输到云端。在某些情况下,我们可能没有这么幸运。因此,让我们看一下另一种架构

上述架构是通过一项名为 边缘数据复制的新 InfluxDB 功能实现的。这允许我们将来自生成器的数据写入本地托管的 InfluxDB,然后再自动传输到 InfluxDB Cloud。这非常适合以下用例
-
边缘基础设施已经存在。您可能已经在边缘使用 InfluxDB,但希望有一种简单的方法将您的架构扩展到云端。
-
您需要本地存储和数据的可见性。
我们仍然可以保留托管在云端的 Kafka 解决方案用于我们架构的其余部分,但这允许 InfluxDB 在从边缘到云的数据传输中提供主干。
