Rails 指标入门
作者:Katy Farmer / 产品, 开发者, 入门
2017 年 12 月 08 日
导航到
如果您和我一样,那么您也是指标领域的新手。您听到了它的召唤,想要了解更多,但您不知道从哪里开始。每次您开始学习教程时,您都会因为在 Google 上搜索教程中使用的词汇而分心(也许只有我是这样)。这可能是一条陡峭的学习曲线。
 <figcaption> 我总有一天会成为巫师的</figcaption>
<figcaption> 我总有一天会成为巫师的</figcaption>
Rails 中的指标
我决定从我确实知道如何做的事情开始,并尝试添加少量的指标工具,看看我能从一个简单的 Rails 应用程序中学到什么。Rails 是一个不错的选择,原因有两个:(1)我知道如何编写 Ruby 和使用 Rails,所以我可以专注于指标,以及(2)Rails 经常未被衡量,因为我们使用强大的测试套件和其他工具来告诉我们正在发生什么。
我像弗兰肯斯坦一样,让一个旧应用程序复活,将其拼凑在一起,直到它蹒跚醒来。它没有样式,删除操作似乎已损坏,它是衡量的完美候选者。认识一下 Blogger(您可以在我的 Github 上找到源代码)。
 <figcaption> 看!</figcaption>
<figcaption> 看!</figcaption>
我们想了解这个应用程序的哪些方面?一般来说,我们想知道它是否以意想不到的方式失败、它处理了多少请求,以及它是否像弗兰肯斯坦一样行为不端、横冲直撞并且只提供 404 错误。请求数据可能不是最复杂的指标,但它的价值是直接的;存在并提供 200 状态码是我们对 Blogger 的最低期望,因此这是一个好的起点。
有很多工具可以收集指标,它们中的每一个都有适合它的用例。知道从哪里开始是最困难的部分,所以我听取了一位朋友的建议,观看了 Coda Hale 的演讲 “指标,指标,无处不在”。他出色地解释了仪器仪表的价值(总之,我们衡量事物是因为它可以帮助我们形成对其成本的准确心理地图)。它确实帮助我克服了我试图跨越的词汇/知识差距。
Coda 的演讲引导我找到了 Ruby 指标库,ruby-metrics 作者是 John Ewart,它基于 Coda 的指标库,metrics (+1 命名清晰)。Ruby-metrics 有一个很好的 README,因此它是初学者的完美选择。
 <figcaption> 我在吸收知识</figcaption>
<figcaption> 我在吸收知识</figcaption>
将“ruby-metrics”放入我的 Gemfile 并捆绑后,这是我添加到我的 Rails 应用程序中的内容。
config.middleware.use(
Metrics::Integration::Rack::Middleware, :agent => Metrics::Agent.new, :show => '/stats'
)就是这样。这个 Rack 中间件位于 application.rb 中,它创建了一个端点“/stats”,用于传递 JSON 有效负载。还有其他选项可以通过 ruby-metrics 获取指标,但“/stats”路径在 Rails 领域中很常见且易于理解。
{
"_requests": {
"count": 6,
"rates": {
"one_minute_rate": 0.062685889170148,
"five_minute_rate": 0.013168198374952,
"fifteen_minute_rate": 0.0044259829392568,
"unit": "seconds"
},
"durations": {
"min": 7.6055526733398e-5,
"max": 0.38426399230957,
"mean": 0.070876717567444,
"percentiles": {
"0.25": 0.0034220218658447,
"0.5": 0.010805130004883,
"0.75": 0.016463041305542,
"0.95": 0.29253399372101,
"0.97": 0.32922599315643,
"0.98": 0.34757199287415,
"0.99": 0.36591799259186
},
"unit": "seconds"
}
},
"_uncaught_exceptions": 0,
"_status_1xx": 0,
"_status_2xx": 4,
"_status_3xx": 0,
"_status_4xx": 2,
"_status_5xx": 0
}看看所有这些数字!
然后是 JSON
突然,数据!我甚至知道其中一些数据的含义。虽然我们当然可以解析它并理解这些统计数据,但可视化是否会成为更快获得重要细节的更简单方法?一切都还好吗?弗兰肯斯坦是否在攻击村民?
要了解情况如何,我们需要一些帮助。同样,有很多工具可用。如果我可以用来自星球大战宇宙的随机行星填充我的博客应用程序,那么一切皆有可能,梦想成真。我的意思是,如果您有喜欢的可视化工具,请使用它。对于此示例,我将使用 Chronograf,因为它易于设置,而且我喜欢制作它的人。
这也是我滑回学习曲线的过程中的一点。这是我知道的:我在“/stats”端点有一个 JSON 有效负载,我想使用 Chronograf 查看该数据。
 <figcaption> 我的思考过程</figcaption>
<figcaption> 我的思考过程</figcaption>
如果您正在跟进并且之前没有安装过 TICK Stack,那么这里有一个快速的 5 分钟指南,用于入门。
配置 Telegraf
正如互联网和我的一些同事很快告诉我的那样,上面图片中的魔法森林的一部分是 Telegraf,它专门用于收集数据,另一部分是 Chronograf 可以连接到的数据库。为了在 Chronograf 中查看我的统计数据,我们需要设置一个管道。幸运的是,Telegraf 是插件驱动的,并且有两种类型的插件听起来非常合适:输入和输出。其中一个输入立即突出显示:httpjson。繁荣——那是频谱的一端。我使用 Telegraf 入门指南找到了我的 telegraf 配置文件。它因您的操作系统而异,但在 MacOS 上,它位于 /usr/local/etc/telegraf.conf。您可以生成一个 Telegraf 示例配置文件,但信息过多可能会让人不知所措(至少对我而言)。
[[inputs.httpjson]]
## Name for the service being polled. Will be appended to the name of the
## measurement e.g. "httpjson_webserver_stats".
##
## Deprecated (1.3.0): Use name_override, name_suffix, name_prefix instead.
name = "webserver_stats"名称保留为默认值,但如果我决定稍后使用多个输入插件,我会更改它。此外,这里有一个关于弃用的注释,我总是想注意它,但我尝试使用名称以外的其他名称一直都在破坏。我想跟进这一点,因为我不希望保留已弃用的代码(当我弄清楚时我会更新 Blogger)。
## URL of each server in the service's cluster
servers = [
"https://:3000/stats"
]我用 Blogger 统计信息的地址替换了样板地址。
## Set response_timeout (default 5 seconds)
response_timeout = "5s"文档建议减少响应超时可能不是一个好主意。我相信他们。
## HTTP method to use: GET or POST (case-sensitive)
method = "GET"这默认为 GET,这对于 Blogger 来说是完美的。我想到的一件事是,如果我需要授权才能访问端点,这可能会发生什么变化。目前,我易受攻击的(但本地的)端点应该可以工作。
我在这一步又遇到了障碍。我已经连接了我的输入插件。可能吧。但我不能确定——我也不知道如何确定。在花了太多时间寻找一种方法来深入研究 Telegraf 以查看发生了什么(我确信这是可能的,并且可能并没有那么复杂)之后,我决定跳到输出插件。如果我可以将 Telegraf 连接到数据库,我可以检查管道是否正在工作。
对于我的数据库,我几乎选择了 Postgres,因为我以前用过它并且我很了解它。但是,当我想到关系数据库的结构时,它感觉不太合适。我不想做很多工作来存储 Blogger 统计信息,所以我需要一些格式更宽松的东西。另一个因素是,我的 Blogger 统计信息似乎随着时间的推移比单独的统计信息更有价值。一次失败对我来说没问题——但是失败模式令人难过,可能没有人会在我悲伤的 Blogger 应用程序上写博客。
我选择了 InfluxDB;作为时间序列数据库,它可以按时间段对数据点进行分组,并且不需要预定义的架构。同样,我参考了 InfluxDB 输出插件的 README 来设置配置文件。与我早期的努力相反,输入和输出插件可以放在同一文件中。
[[outputs.influxdb]]
## The full HTTP or UDP URL for your InfluxDB instance.
##
## Multiple urls can be specified as part of the same cluster,
## this means that only ONE of the urls will be written to each interval.
# urls = ["udp://127.0.0.1:8089"] # UDP endpoint example
urls = ["http://127.0.0.1:8086"] # requiredInfluxDB 的默认端口是 8086,这正是我们希望数据最终到达的位置。
## The target database for metrics (telegraf will create it if not exists).
database = "metrics" # required与往常一样,我可以将此命名为任何我想要的名称,这很诱人,但如果我将其称为 gravy_train,我会期望它充满肉汁,而不是指标。
## Write timeout (for the InfluxDB client), formatted as a string.
## If not provided, will default to 5s. 0s means no timeout (not recommended).
timeout = "5s"说实话,在某个时候我会将此更改为零,看看会发生什么。今天不是那一天。
可视化我的指标
在这一点上,我满身是汗,饥肠辘辘,我需要它工作。是时候运行 Blogger 和 Telegraf 了。请记住,配置文件的路径是相对的。
rails stelegraf --config telegraf.conf我在 Blogger 上点击了一下,若有所思地看着它成功和失败。我检查了“/stats”端点。数字在那里。
 <figcaption> 不要吐,不要吐</figcaption>
<figcaption> 不要吐,不要吐</figcaption>
检查统计信息是否通过管道的最佳方法是 Influx CLI。
$influx您应该看到确认您已连接到 InfluxDB。
>SHOW DATABASES希望您至少看到 _internal 和 metrics(或您的数据库名称)。
>USE metrics这就是我们告诉 InfluxDB 我们要查询哪个数据库的方式。
>SHOW measurements如果星星排列成行(也是管道),我们应该在此处看到列出的 httpjson 数据。
既然统计数据已在数据库中(太棒了!),我可以在 Chronograf 中看到好消息。我转到 Chronograf 中的 Dashboards 选项卡,创建了一个新的 Dashboard,并从列表中选择了我的数据库。这是我制作的过去五分钟内每分钟请求总数的图表。
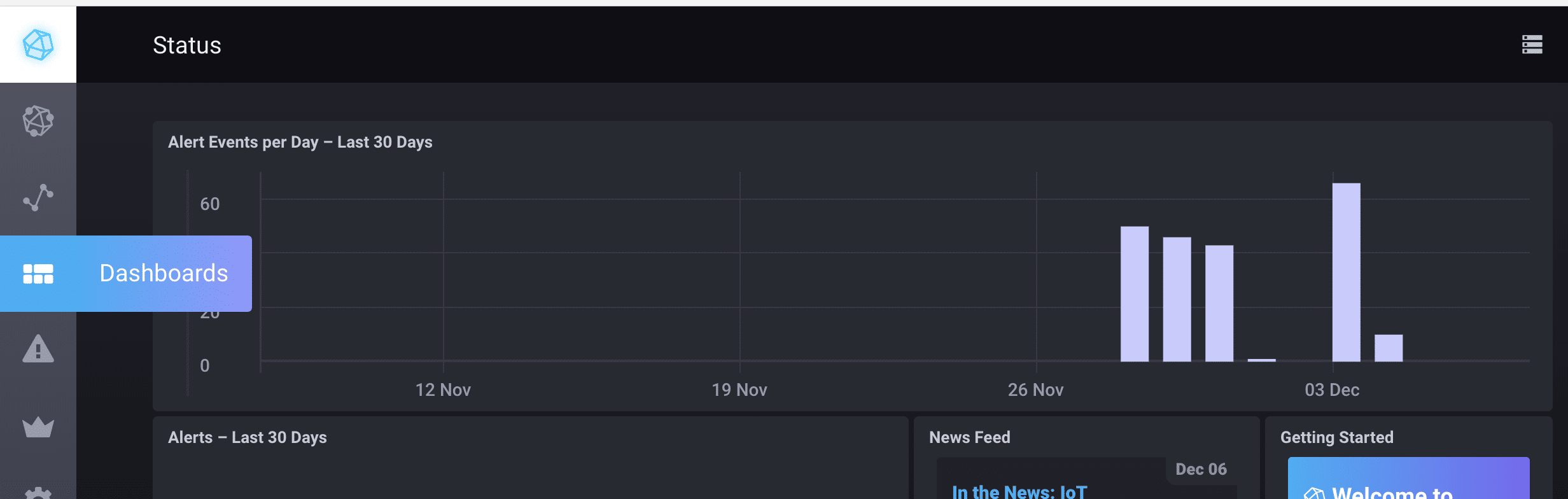 <figcaption> 选择 Dashboards 选项卡。</figcaption>
<figcaption> 选择 Dashboards 选项卡。</figcaption>
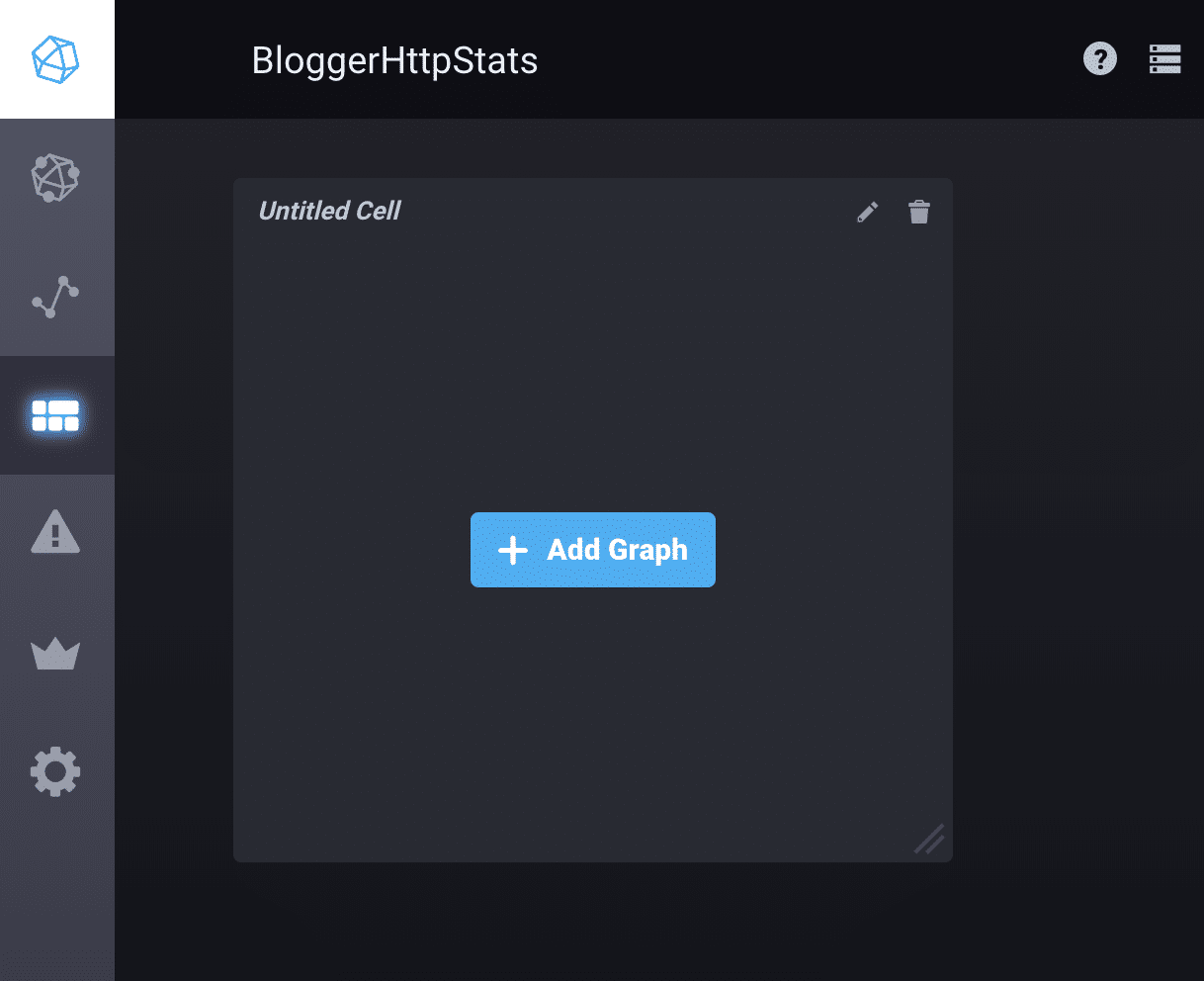 <figcaption> 选择创建新 Dashboard,然后选择添加图表。</figcaption>
<figcaption> 选择创建新 Dashboard,然后选择添加图表。</figcaption>
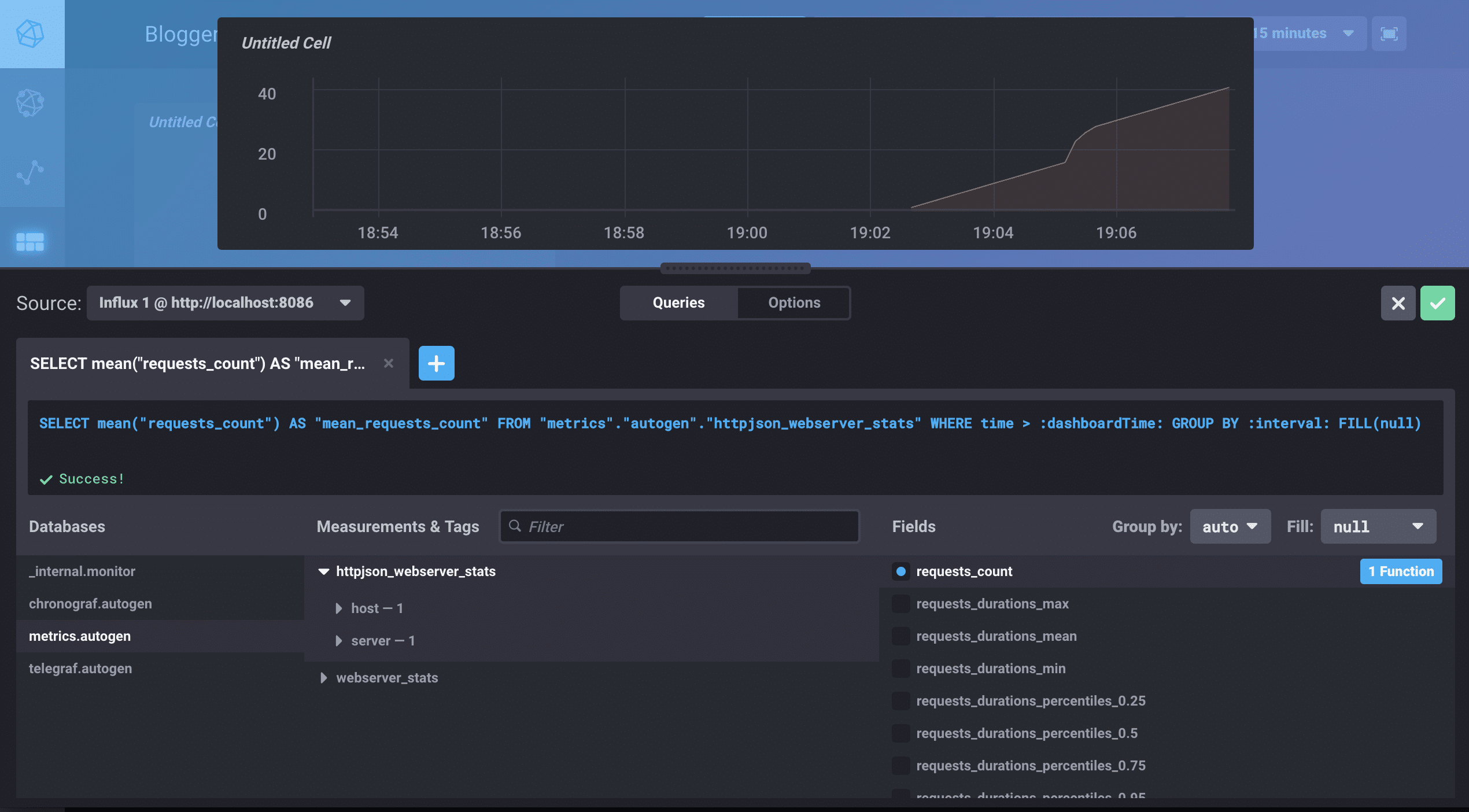 <figcaption> 选择添加查询。选择您的数据库、您的测量和您的字段。</figcaption>
<figcaption> 选择添加查询。选择您的数据库、您的测量和您的字段。</figcaption>
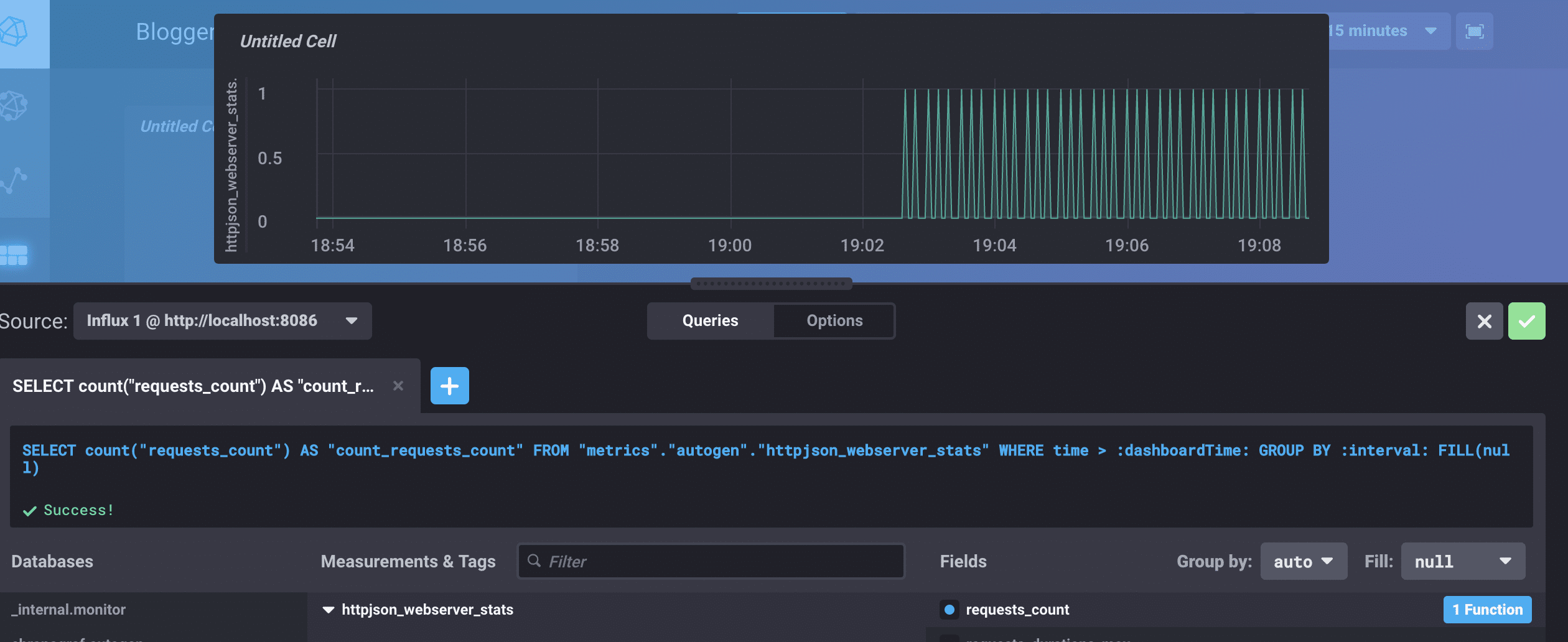 <figcaption> 我将 requests_count 函数更改为计数而不是平均值,这样我就可以看到每个请求。单击绿色复选标记!</figcaption>
<figcaption> 我将 requests_count 函数更改为计数而不是平均值,这样我就可以看到每个请求。单击绿色复选标记!</figcaption>
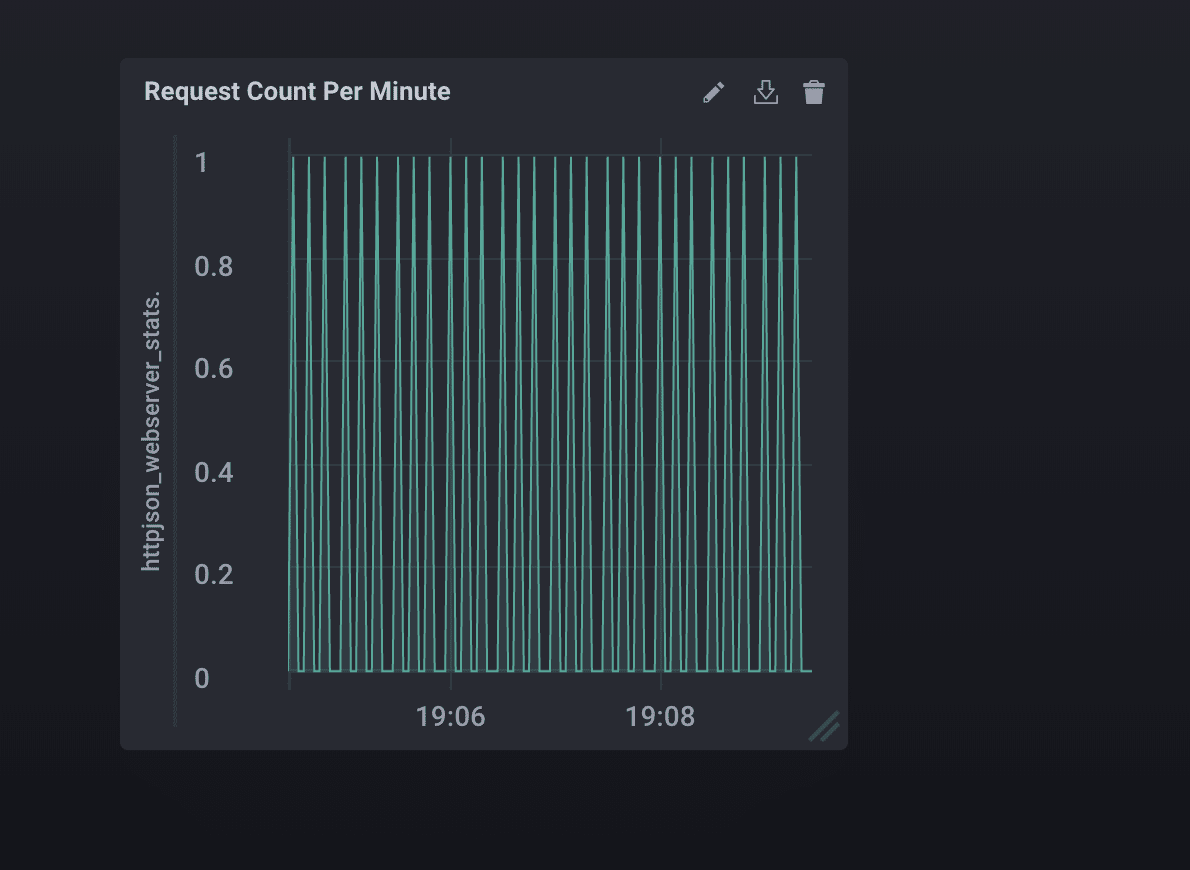 <figcaption> 我将时间窗口更改为过去五分钟。太美了。</figcaption>
<figcaption> 我将时间窗口更改为过去五分钟。太美了。</figcaption>
我没哭。是你哭了。
经过一次舞会和几袋 Skittles 之后,我从成功看到我的统计数据的兴奋中恢复过来。我的解决方案在探索过程中感觉良好,但它有一些问题。一个问题是它只在本地运行,而生产对于像这样的应用程序来说才是真正重要的。老实说,有很多工具可以查看网站流量。我想知道我的应用程序的执行情况(或不好)——这并没有做到这一点。尽管如此,这些都是我在使用 ruby-metrics 和 Telegraf 经历了这个探索阶段之后才能意识到的。
还有更多我想知道的:当博客数量增加且请求更频繁发生时,数据库的性能将如何?如果将 Blogger 移入容器或虚拟环境,Blogger 的性能会如何?我应该监控容器还是应用程序?还是两者都监控?我开始看到指标如何作为一个整体改进我的应用程序,甚至改进作为开发人员的我。
目前,我将消除 Blogger 的缺陷——也许添加一些 CSS。我将把它投入生产,以确保我的管道能够保持稳定。然后我将尝试再次破坏整个事情——并衡量它的失败和成功。
