使最近值查询速度提升数百倍
作者:Nga Tran / Andrew Lamb / 开发者
2024 年 3 月 18 日
导航至
这篇文章解释了数据库如何优化查询,从而使查询速度提高数百倍。虽然我们专注于对 InfluxDB 3.0 很重要的一种特定查询类型,但我们描述的优化过程对于任何数据库都是相同的。
优化查询就像玩乐高
当使用同一套乐高积木时,您可以构建不同的结构,如图 1 所示。虽然您经常使用相同的基本砖块来构建您想要的任何结构,但有时您需要一种不同的形状(例如,小星星)用于特定项目。

图 1:使用相同的基本乐高正方形和长方形构建的两种不同结构
在数据库中,运行查询意味着运行一个查询计划,这是一个处理和流式传输数据的不同运算符树。每个运算符都像一块乐高积木:根据它们的连接方式,它们计算相同的结果,但性能不同。大部分查询优化都涉及交换或移动现有运算符以形成更好的查询计划,但在某些罕见的情况下,需要一个新的特殊情况运算符来更好地完成工作。
让我们通过创建一个专门的运算符并重新组合现有运算符来优化查询的示例,以形成具有卓越性能的查询计划。
查询最近的值
作为一个时间序列数据库,一个常见的用例是管理来自许多设备的信号数据。一个常见的问题是:“设备(例如,设备编号 10)最后发送的信号是什么?” 这个问题的答案(或其变体)通常用于驱动 UI 或监控仪表板。使用 SQL,可以回答这个问题的查询是
SELECT …
FROM signal
WHERE device = 10
AND time BETWEEN now() - interval 'X days' and now()
ORDER BY time DESC
LIMIT 1;
过滤器 time BETWEEN now() - interval 'X days' and now() 将问题稍微缩小了一点:“设备编号 10 在过去 X 天内最后发送的信号是什么?”
虽然此查询很简单,但实际查询可能更复杂。例如,“查找最近五个值的平均值”,因此我们的解决方案必须能够处理这些更通用的查询。
这些查询在毫秒内返回结果也很重要,因为每个设备所有者都会频繁请求值。一个挑战是所有者不知道上次信号发生的时间——可能是五分钟前或几个月前。因此,时间范围 X 的值可能非常大,并且查询运行时间很长。除非用户非常小心地编写查询,否则它将读取和处理大量数据,从而增加查询返回时间。
与传统的关联或时间序列数据库不同,InfluxDB 3.0 将数据存储在 Parquet 文件中,而不是自定义文件格式和专用索引。我们的使命是使此类查询在毫秒内运行,而不管时间范围 X 有多大,而无需引入特殊索引。
改进前后的运行时间
在解释我们的方法之前,让我们看一下图 2 中的结果。蓝色代表改进前不同时间范围内查询的标准化运行时间,绿色代表改进后的运行时间。查询在运行 30 个单位后超时,因此达到 30 个单位的查询的实际运行时间甚至更高。如图表所示,我们的改进使长时间范围查询的速度提高了数百倍,并将所有查询的运行时间降至客户要求的水平。
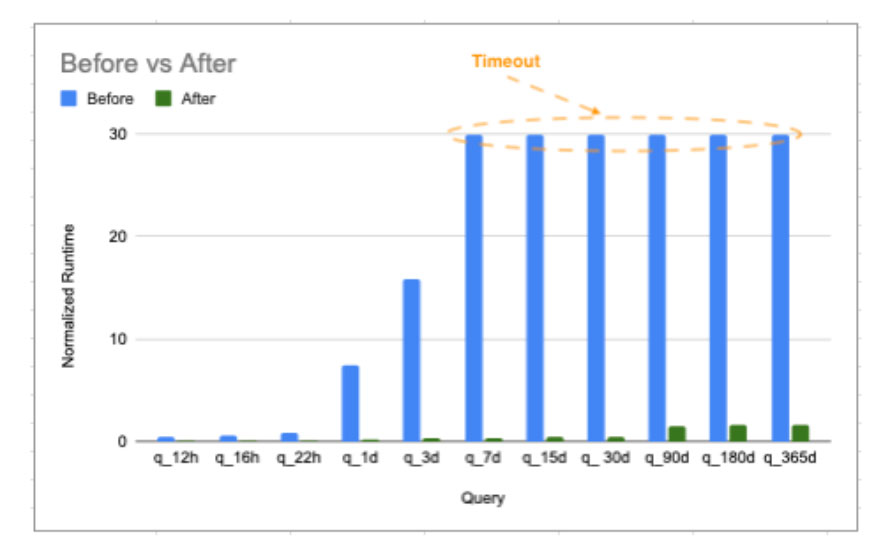
图 2:改进前后的查询运行时间
让我们继续讨论我们是如何实现这一目标的。
改进前的查询计划
图 3 显示了使用排序合并算法的改进前查询计划的简化版本。我们从下往上读取查询计划。输入包括四个文件,四个对应的 scan 运算符并行读取这些文件。每个扫描输出都通过一个对应的 sort 运算符,该运算符按降序时间戳对数据进行排序。四个排序后的输出流被发送到一个 merge 运算符,该运算符将它们组合成单个排序后的流,并在达到限制行数后停止,在本例中为 1。signal 表中还有许多其他文件,但 InfluxDB 首先根据查询的过滤器修剪不必要的文件。
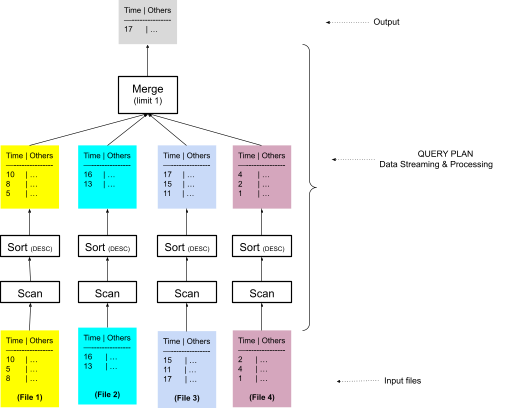
图 3:使用排序合并算法的查询计划
当文件重叠时,InfluxDB 可能需要去重数据。图 4 显示了一个更准确的计划,该计划将重叠文件 File 2 和 File 3 的数据一起排序,并在将数据发送到排序和合并运算符之前对其进行去重。
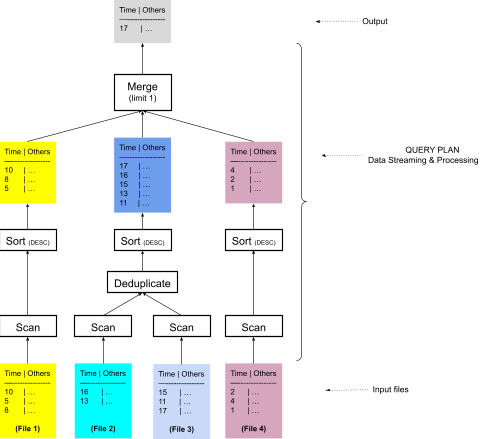
图 4:InfluxDB 查询计划,使用排序合并算法,但首先对重叠文件进行分组
下一节中描述的优化仅取决于计划顶部的运算符,因此,图 5 中的简化计划更清楚地说明了解决方案。请注意,我们省略了计划的许多其他细节——例如,由于查询中的 LIMIT 1,Sort 运算符不会对整个文件进行排序,而只是保留 Top “K” 行。
请注意,进入合并运算符的数据流不重叠。
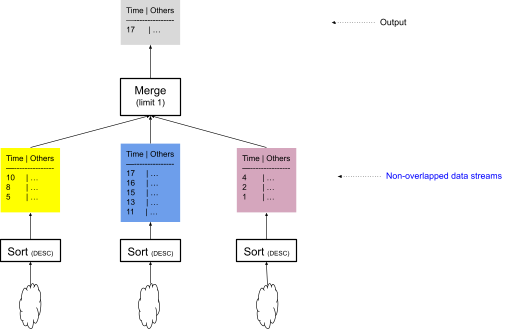
图 5:计划的顶部部分,包括要合并运算符的非重叠数据流
分析计划并确定改进
通常,当合并多个流时,必须在生成任何输出之前知道所有输入(因为第一行可能来自任何输入)。这意味着在上述计划中,我们必须读取和排序所有输入流。但是,如果我们知道流的时间范围不重叠,我们可以简单地逐个读取和排序流,一旦找到所需的行数就停止。这不仅比合并数据的工作量少,而且如果所需的行数很少,则可能只需要读取一个流。
值得庆幸的是,InfluxDB 在读取每个文件之前都有关于每个文件中数据的时间范围的统计信息,并将重叠文件分组以生成非重叠流,如图 5 所示。因此,我们可以应用此观察结果来制定更快的查询计划,而无需额外的索引或统计信息。但是,逐个读取流并在达到限制时停止的行为不再是合并。我们需要一个新的运算符。
新的查询计划
考虑到上述观察结果,图 6 说明了新的查询计划
- 非重叠数据流按时间降序排序。
- 一个新的运算符 ProgressiveEval 取代了 merge 运算符。
新的 ProgressiveEval 运算符按顺序从其输入流中提取数据,并在达到请求的限制时停止。ProgressiveEval 和 merge 运算符之间的最大区别在于 merge 运算符只能在所有输入 sort 运算符完成后才能开始合并数据,而 ProgressiveEval 可以在第一个 sort 运算符完成后立即开始提取数据。
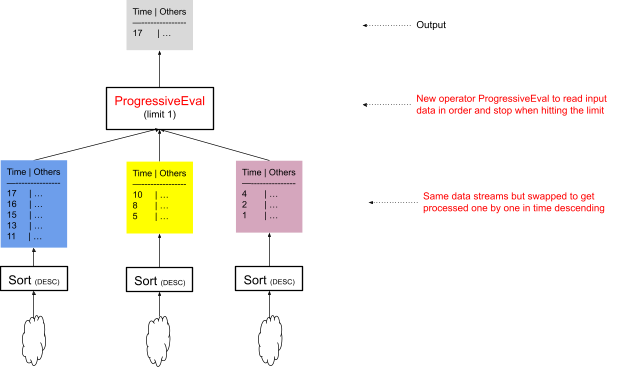
图 6:优化的查询计划逐步读取数据,并在达到限制时提前停止
当图 6 中的查询计划执行时,它仅运行图 7 中显示的运算符。InfluxDB 有一个基于拉取的执行器(基于 Apache Arrow DataFusion 的执行),这意味着当 ProgressiveEval 启动时,它将询问第一个 sort, 而 sort 又会向其输入请求数据。然后,sort 执行排序并将排序后的结果发送到 ProgressiveEval。

图 7:如果指定设备的最新信号在最新时间范围文件中,则所需的执行运算符
由于 device = 10 参数,查询在扫描时过滤数据,我们不知道哪个文件包含设备编号 10 的最新信号。此外,由于每个 sort 运算符都需要时间才能完成,因此当 ProgressiveEval 从流中提取数据时,它也会开始执行下一个流以预取数据,如果第一个流不包含所需的行,则需要这些数据。
图 8 显示,当从第一个 Sort 的 Stream 1 中提取数据时,第二个 Sort 同时执行,以便如果 Stream 1 不包含来自设备编号 10 的请求数据,则 Stream 2 中的数据已准备就绪。如果来自设备编号 10 的数据在 Stream 1 中,则 ProgressiveEval 会在达到限制时立即停止并取消 Stream 2。如果来自 ProgressiveEval 从 Stream 2 中提取数据,它也会开始预执行 Stream 3 的 Sort,依此类推。
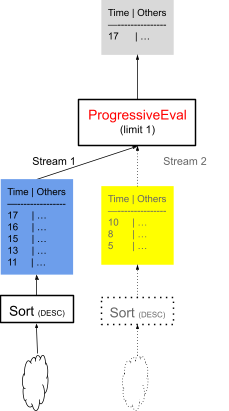
图 8:如果指定设备的最新信号在最新时间范围文件中,则实际的执行运算符
分析改进的优势
让我们比较图 5 中的原始计划和图 8 中的优化计划
- 更快地返回结果:原始计划必须扫描和排序可能包含数据的所有文件,而不管需要的行数是多少,然后才能生成结果。因此,时间范围越长,要读取的文件就越多,原始计划的速度就越慢。这解释了为什么我们的结果显示更长时间范围的改进。
- 更少的资源和更高的并发性:除了更快地生成数据外,优化后的计划需要的内存和 CPU 也少得多——它通常只会扫描和排序两个文件(最新的文件和预取下一个最新的文件)。这意味着更多查询可以使用相同的资源并发运行。
从此工作中受益的查询类型
此时(2024 年 3 月),此优化仅适用于一种查询类型,即“最近/最不近的值是什么...?”换句话说,查询的 SQL 必须包含 ORDER BY time DESC/ASC LIMIT n,其中“n”可以是任何数字,并且时间可以按升序或降序排序。所有其他受支持的 SQL 查询都可以工作,但可能不会从此优化中受益。我们正在继续改进它们。
结论
优化不仅使最近值查询更快,而且还减少了资源使用并提高了系统的并发级别。一般来说,如果查询计划在可能不重叠的数据流上包含 sort merge,则此优化适用。我们已经找到了许多此类查询计划,并且正在努力改进它们。
我们要感谢 Paul Dix 提出了基于 ELK 堆栈中 Elastic 的渐进式扫描行为的此设计建议。
