使用 InfluxDB Cloud 进行物联网原型设计(第二部分):查询、任务和仪表板
作者:Rick Spencer / 用例, 产品, 开发者
2019 年 9 月 27 日
导航至
这是四部分系列文章的第二部分。阅读第一部分、第三部分和第四部分。
物联网场景
之前,我组装了一个物联网设备(使用 InfluxDB Cloud 进行物联网原型设计 - 本系列文章的第一部分),并开始将数据流式传输到我的 InfluxDB Cloud 帐户。从那时起,它一直在愉快地将数据流式传输到我的帐户。
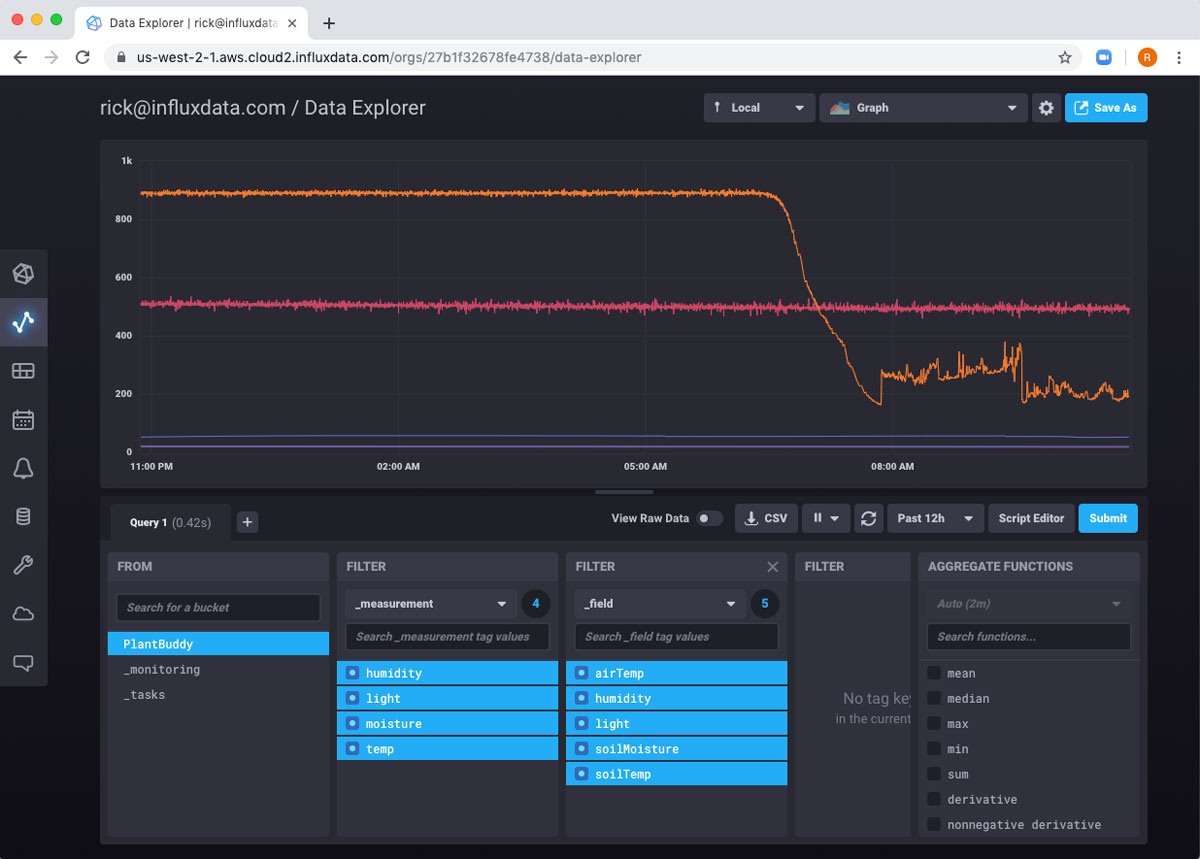
接下来,我想创建一个仪表板,显示土壤湿度水平随时间的变化以及当前的土壤湿度读数。
平滑土壤湿度读数
如您所见,土壤湿度读数可能有点抖动,我想稍微平滑一下。此外,我的 PlantBuddy 存储桶每 3 秒存储一次每个传感器的读数。虽然这对某些类型的分析和功能非常有用,但长期存储所有这些数据几乎没有价值,并且会增加项目的费用。
有很多方法可以解决这个问题。我将采用一种简单的方法进行第一次迭代。
- 我将创建一个新存储桶来保存下采样数据。
- 我将编写一个查询,从原始存储桶中获取最近 5 分钟的数据,计算平均值,并将此数据放入新的“压缩”存储桶中。
- 我将从此查询创建一个每五分钟运行一次的任务。
创建一个新存储桶
首先,我创建一个新存储桶来保存下采样数据。请注意,我仍然在使用免费层帐户,因此我无法将保留期延长超过 72 小时。
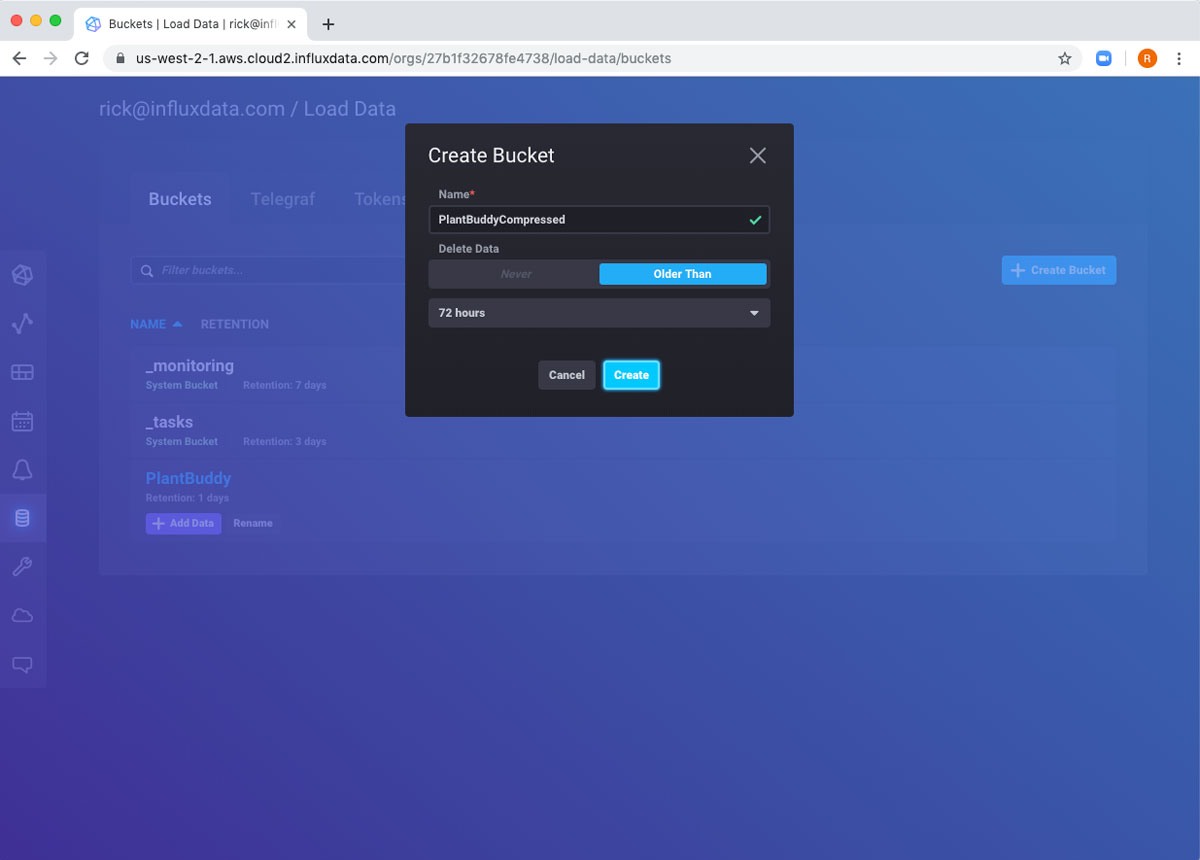
使用 Flux “压缩”数据
现在我将在数据浏览器中编写一个 Flux 查询来压缩数据。
Flux 简介
如果您不熟悉 Flux,Flux 是一种新的查询语言,旨在成为一种通用的数据转换语言。它的设计宗旨是简单易用,但功能强大,足以处理任何数据转换任务。
从概念上讲,Flux 让我想起了使用 awk 进行管道操作。本质上,您编写一系列语句,这些语句将数据表作为输入,对表进行一些更改,然后将新表输出到下一个语句。
Flux 具有以下有趣的语言特性组合
- Flux 是强类型和静态类型的。这意味着许多错误可以在您创建它们时立即捕获,而且您还可以获得丰富的编辑器功能,例如语句完成、内联帮助等。
- 声明变量时,Flux 不需要类型规范。虽然 Flux 是强类型和静态类型的,但它能够从上下文中推断类型,因此当您编写 Flux 代码时,您不必担心类型。
- Flux 在任何地方都使用关键字参数。这使得 Flux 代码更易于阅读和理解。
如果这些对您来说都没有意义,或者您根本不在意,那也没关系。与其解释,不如演示可能更容易。
首先,转到数据浏览器视图。
然后单击“脚本编辑器”切换到脚本编辑器视图。
现在我可以交互式地编写一些 Flux 代码了。通常,Flux 脚本将以 “from” 语句开头。这告诉脚本从哪里获取要处理的第一个表。在本例中,我想从 PlantBuddy 存储桶中获取表,因为所有数据都在那里。“from” 是一个函数,Flux 中的函数使用命名参数。因此,我将告诉我的查询从名为 “PlantBuddy” 的存储桶中获取初始数据,如下所示
from(bucket: "PlantBuddy")这应该只是返回一个包含存储桶中所有数据的表。但是,InfluxDB Cloud 2.0 不支持此操作,因为这很可能要导出大量数据,而且很可能不是您想要执行的操作。请注意,这本身不是 Flux 语言的限制,而只是为了防止用户意外超出其使用配额,并且不会因意外查询而给数据库引擎带来压力。
因此,必须至少添加一个管道来限制要选择的数据。在 Flux 中,您使用管道前向运算符 (|>) 将表输出到查询中的下一个操作。这显然类似于 Unix 系统中的管道符号。因此,首先,我将向 InfluxDB 请求存储桶中最近 5 分钟的数据。我通过将存储桶中的数据“管道”到 range 函数来完成此操作。range 函数具有 start 和 end 参数。我将使用以下表示法将 “start” 设置为 “5 分钟前”
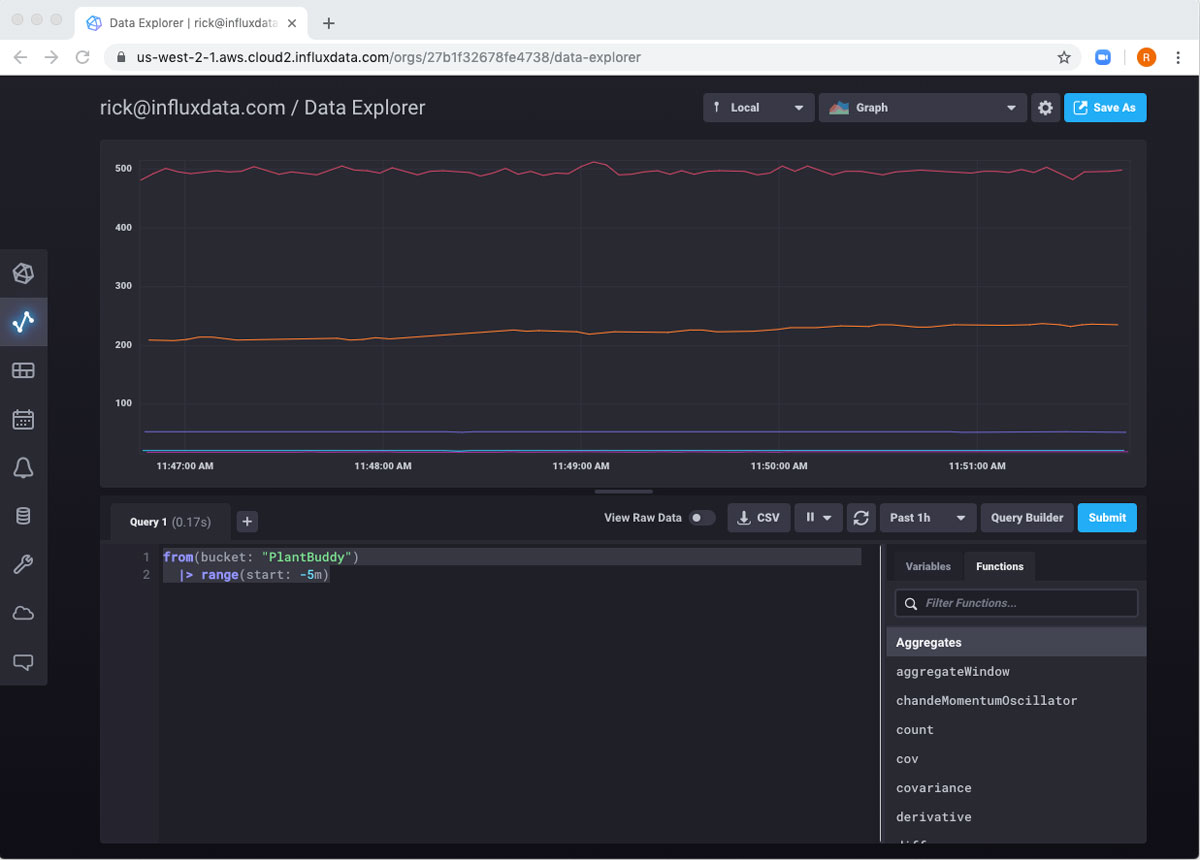
from(bucket: "PlantBuddy")
|> range(start: -5m)现在,如果我点击 “提交”,我可以看到返回的最近 5 分钟的数据。
为了更容易查看结果表,我可以切换到 “原始数据” 视图。
现在我可以真正看到返回的数据了。
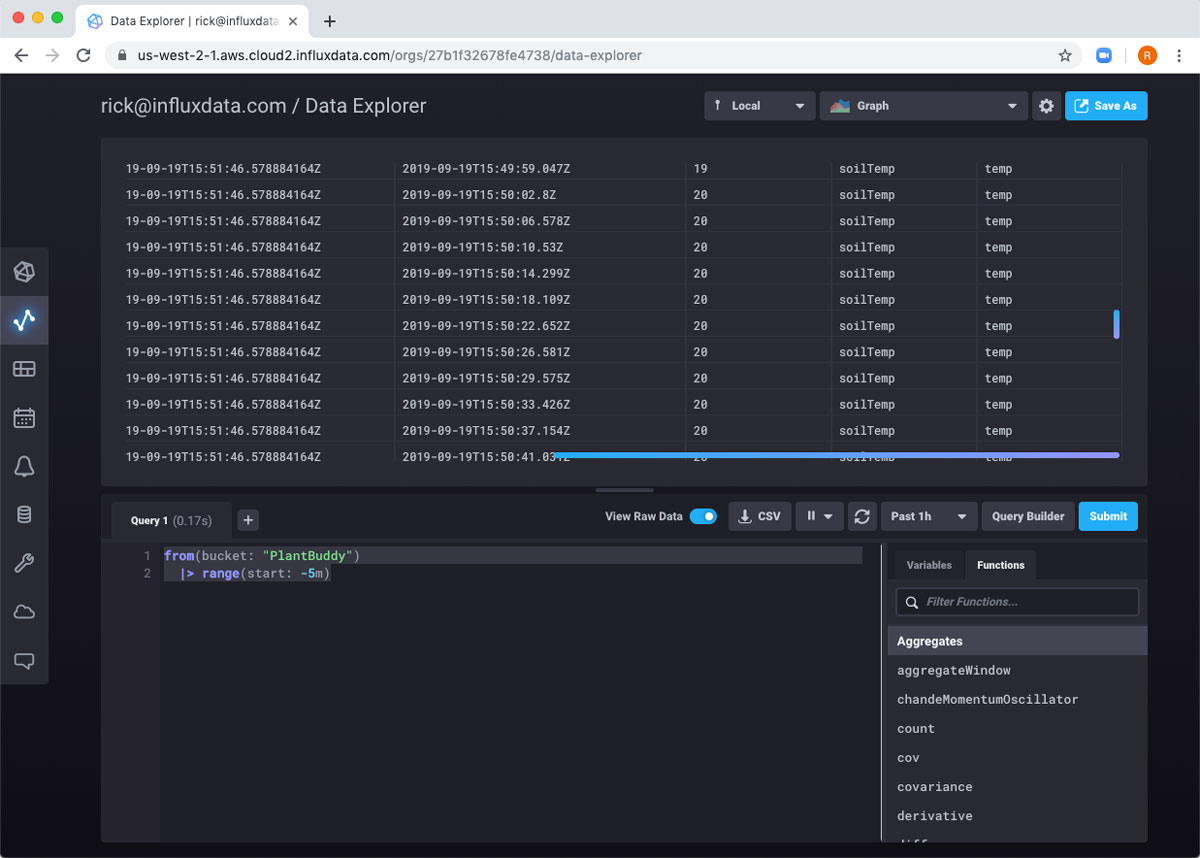
Flux 包含用于对数据进行排序的函数,但我特别不需要该函数。但是,我只想要 soilMoisture 读数。因此,我将此表管道传输到 filter 函数。我可以使用函数列表来获得一些编写函数的帮助。它在查询构建器中提供了存根实现和有用的文档。
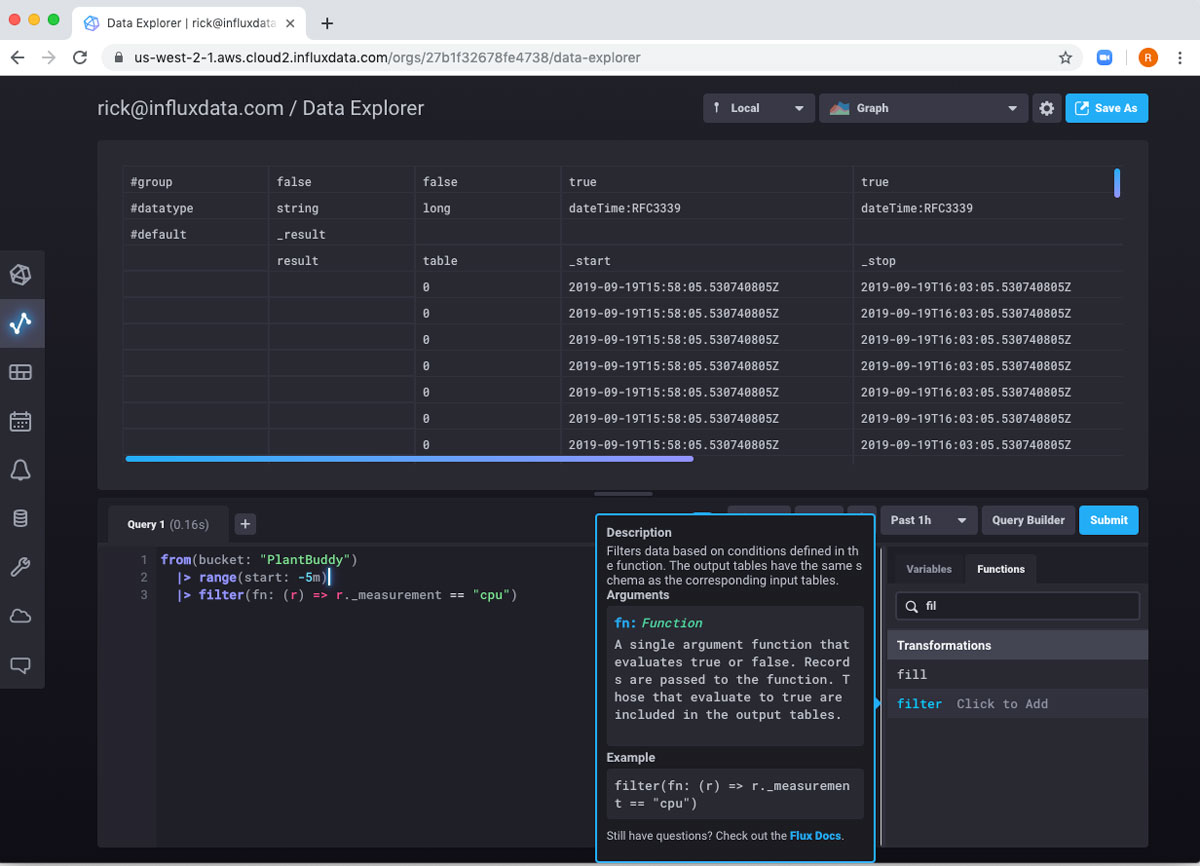
filter() 是一个将另一个函数作为参数的函数。各种 JavaScript 库的用户可能熟悉这种模式。如果您熟悉创建匿名函数,则这应该感觉像是创建匿名函数。如果不是,请不要担心,它在概念上和实践上都很简单。
这是执行过滤的 Flux 代码行
|> filter(fn: (r) => r._measurement == "cpu")我们可以稍微分解一下以帮助更好地理解它。“filter” 是函数的名称。filter() 需要一个名为 “fn” 的命名参数,该参数是另一个函数。这意味着我需要将另一个函数传递到 filter() 函数中。我传入的函数将执行实际的过滤。“r” 代表 “Record”,它是一个隐式变量,表的行正在传递到过滤实现中。实际的过滤只是一个枯燥的布尔表达式。如果它返回 true,则保留记录。否则,将丢弃记录。
当然,如果我提交此查询,我将不会得到任何结果,因为我的设备不测量任何 CPU。我关心的是 soilMoisture 读数,以及在字段名为 “soilMoisture” 的行中捕获的读数。
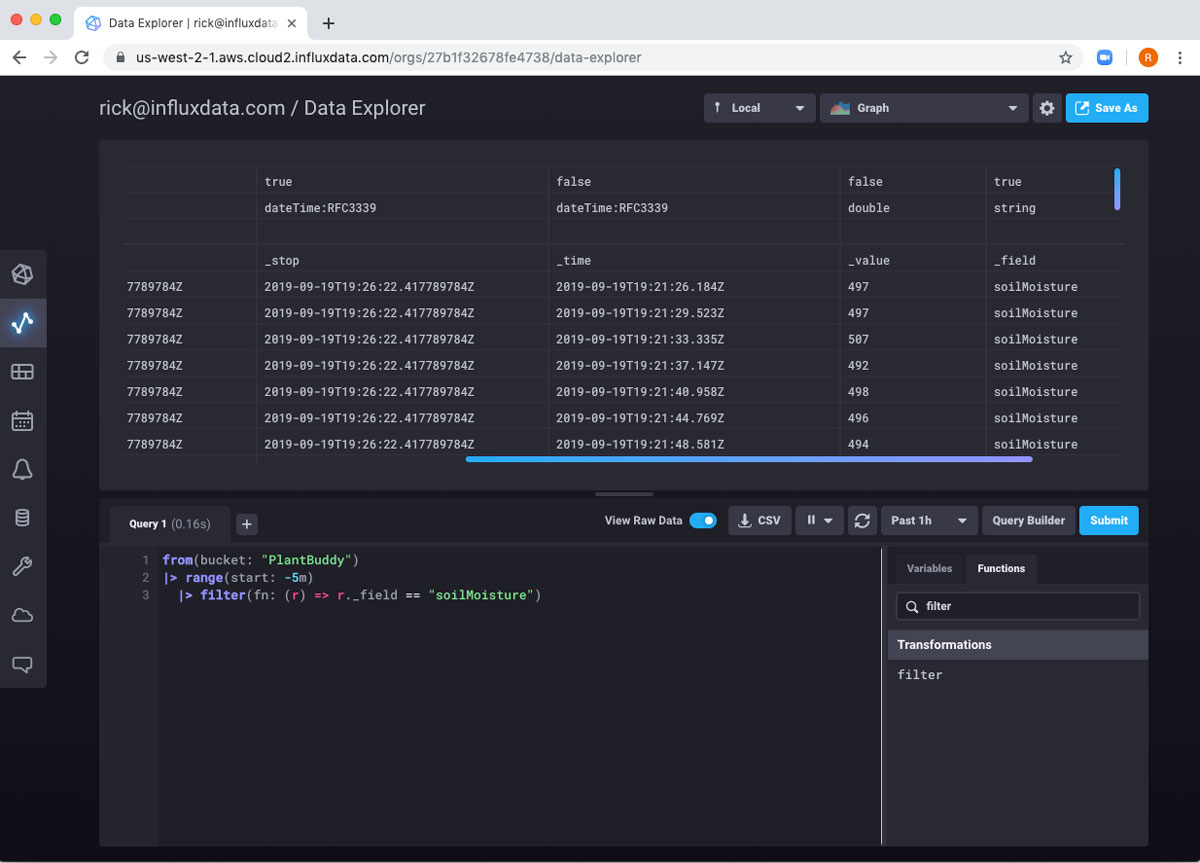
我们可以看到这是有效的。因此,现在我可以添加另一个管道来计算所有这些字段的平均值。我可以搜索该函数并获得一些帮助。
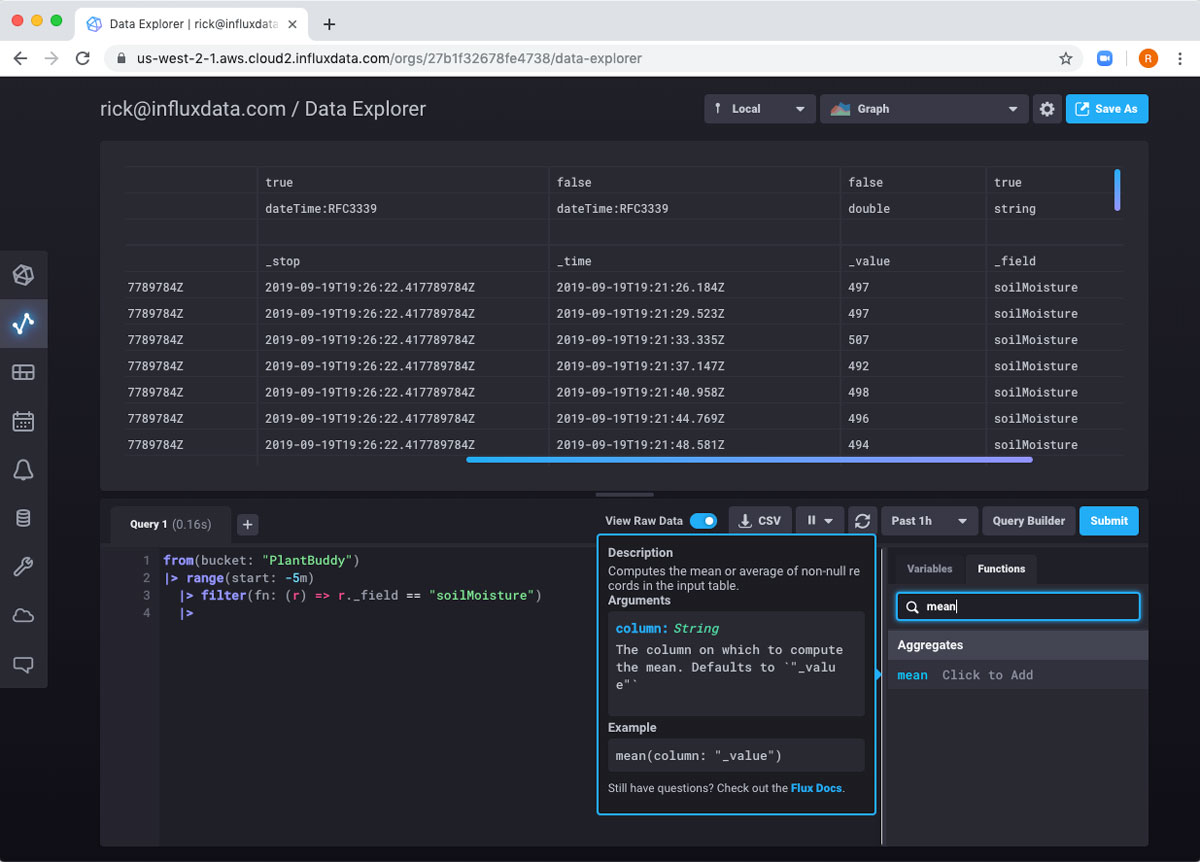
mean 函数默认使用 _value 字段,这对我来说有效,所以我只需将其添加到我的代码中即可
from(bucket: "PlantBuddy")
|> range(start: -5m)
|> filter(fn: (r) => r._field == "soilMoisture")
|> mean()现在,当我提交该查询时,我在表中获得一个值,即到目前为止通过管道传递的所有行的平均值。
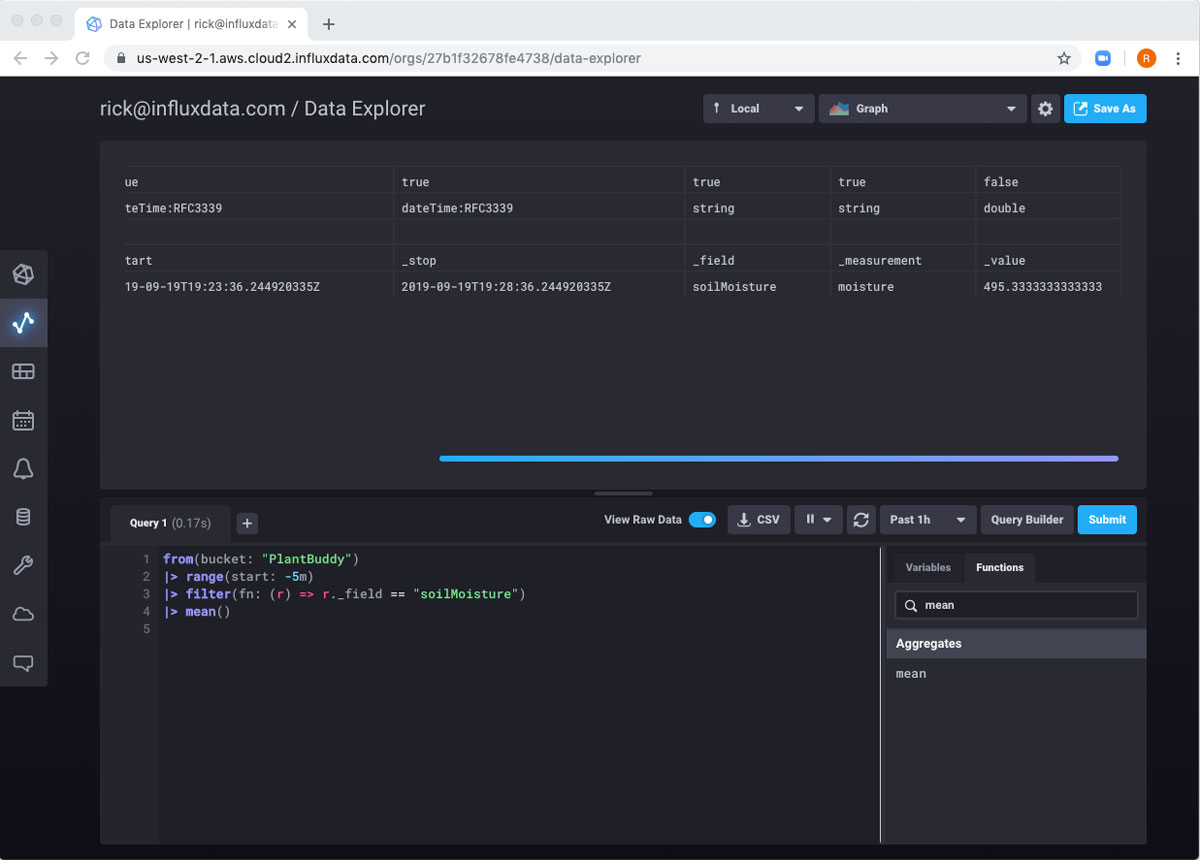
我还没有完全准备好将其移动到我的新存储桶,因为 mean() 函数的结果删除了 _time 列,如果我尝试将结果添加到没有 _time 列的存储桶,我将收到错误消息。mean() 函数确实添加了 _start 列和 _stop 列。我不需要它们中的任何一个,所以我将简单地使用 rename() 函数将 _stop 列的名称更改为 “_time”
from(bucket: "PlantBuddy")
|> range(start: -5m)
|> filter(fn: (r) => r._field == "soilMoisture")
|> mean()
|> rename(columns: {_stop: "_time"})如果我提交该查询,我可以看到现在有一个 _time 列。
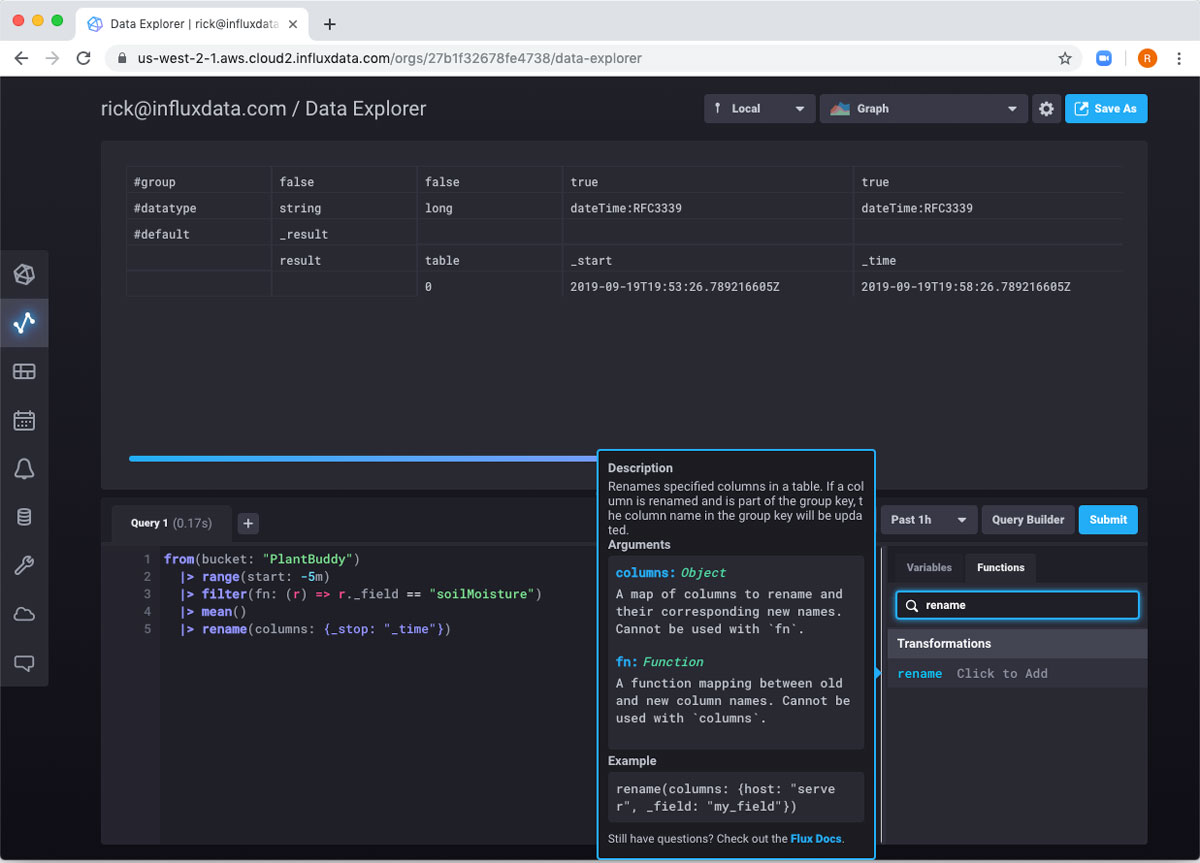
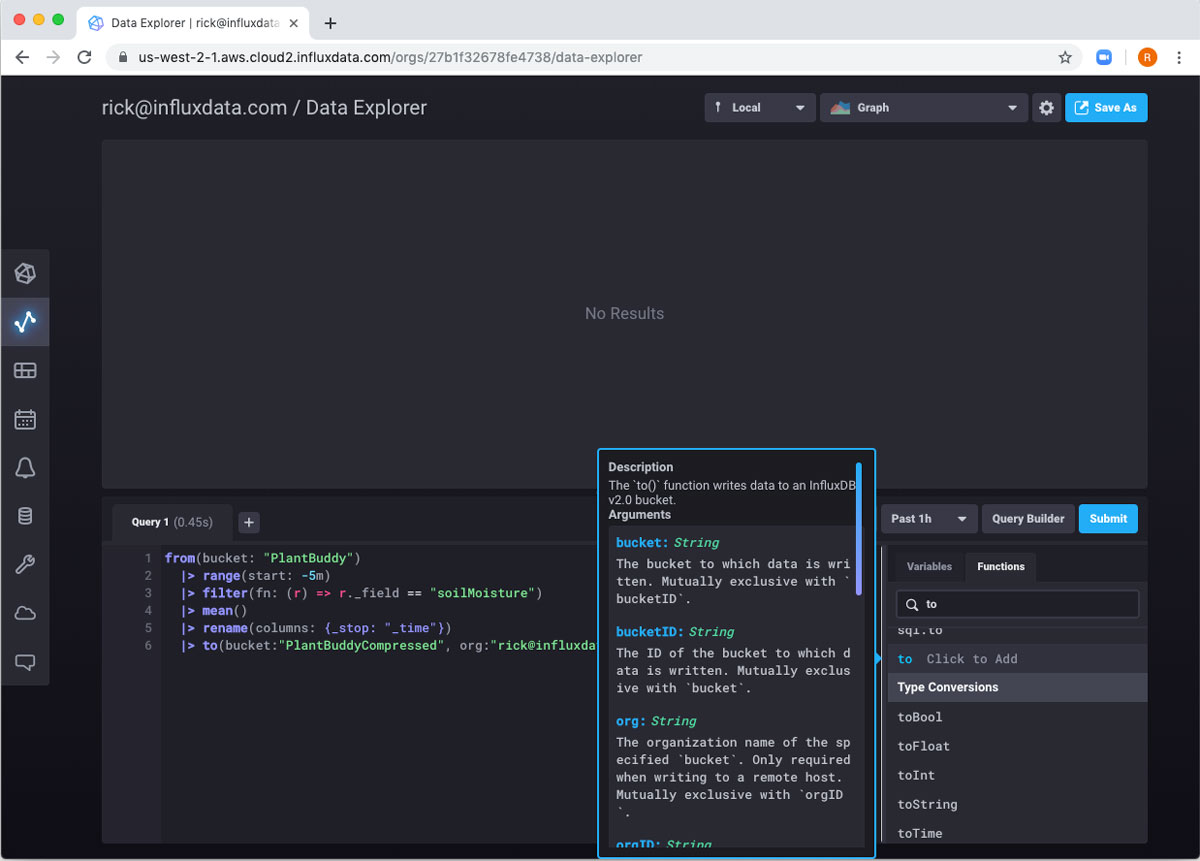
现在我只需要将其发送到我的存储桶。由于您使用 “from” 将数据导入 Flux 脚本,因此使用 “to” 导出数据是有道理的
from(bucket: "PlantBuddy")
|> range(start: -5m)
|> filter(fn: (r) => r._field == "soilMoisture")
|> mean()
|> rename(columns: {_stop: "_time"})
|> to(bucket:"PlantBuddyCompressed", org:"[email protected]")当我提交此查询时,我得到 “无结果”,因为我已将所有数据发送到另一个存储桶。
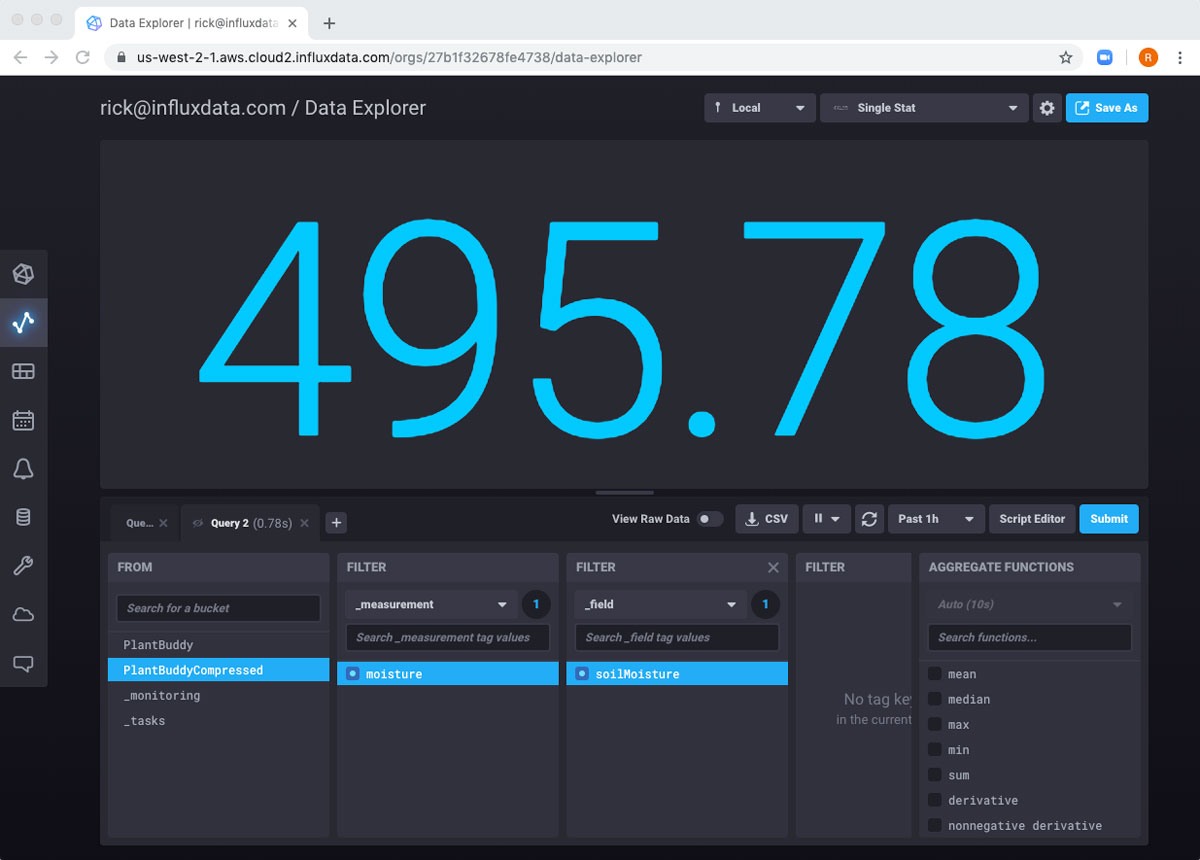
由于我只运行了一次任务,所以我知道存储桶中只会有一行。如果我查看 PlantBuddyCompressed,我可以看到单行在那里。
从查询创建任务
现在我已经有了一个运行良好的 Flux 查询,我如何每五分钟运行一次它?这正是任务的目的。右上角的 另存为 按钮将允许我将查询转换为任务。
我只需要填写任务的名称以及运行频率(在本例中为每 5 分钟)。
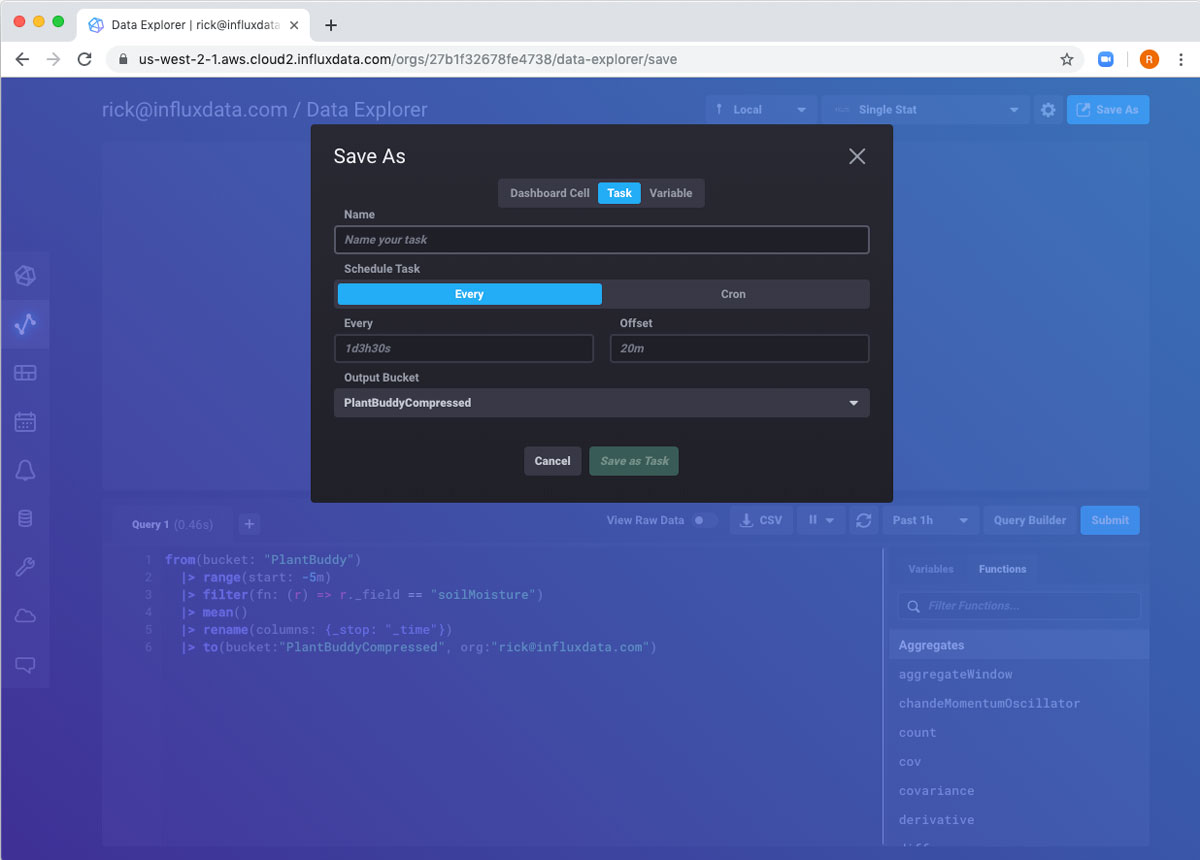
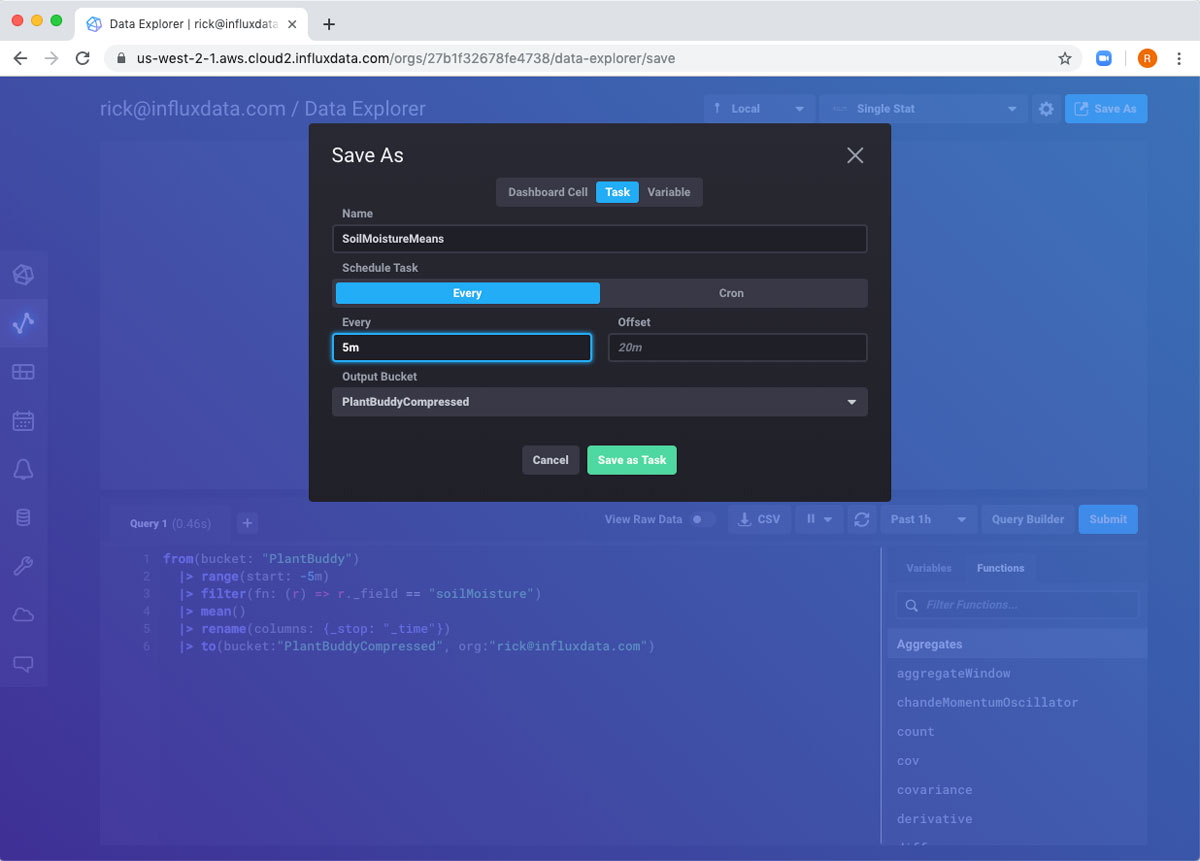
填写完表单后,任务即已创建,我将自动转到任务页面。
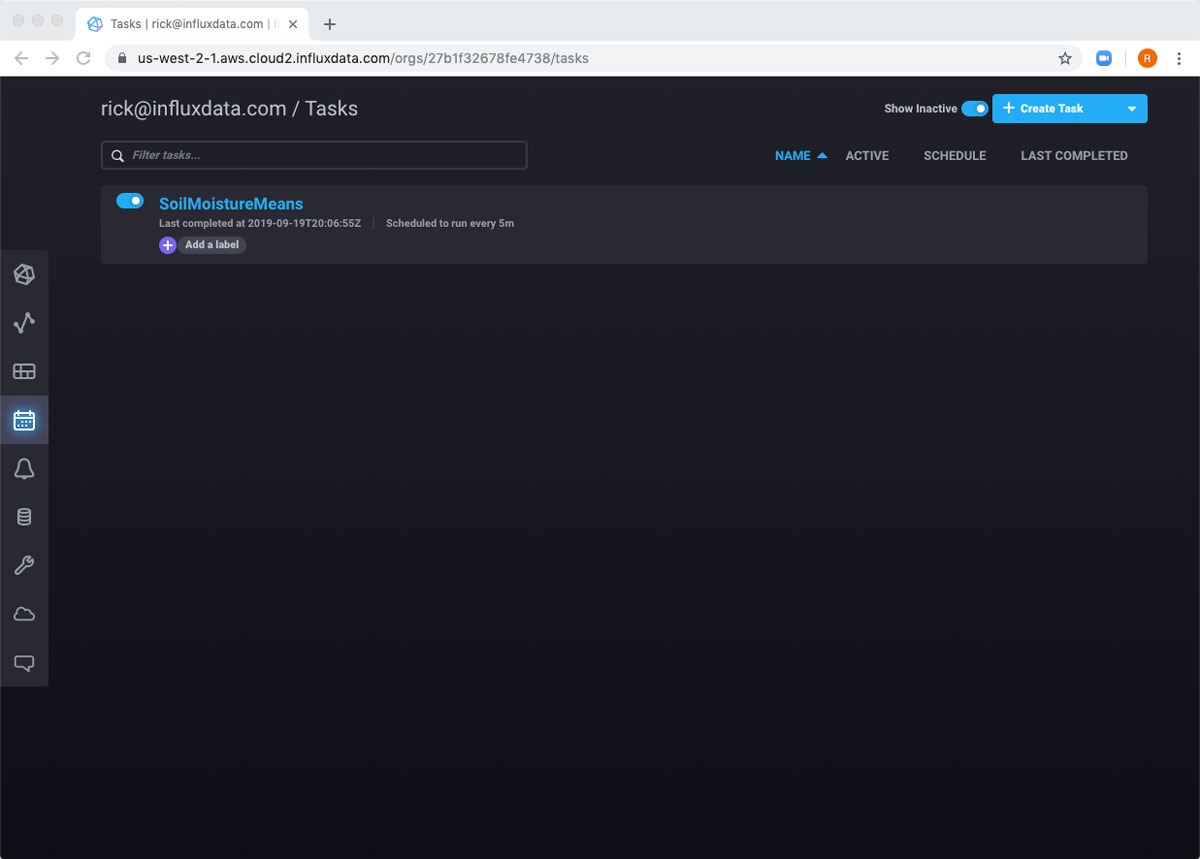
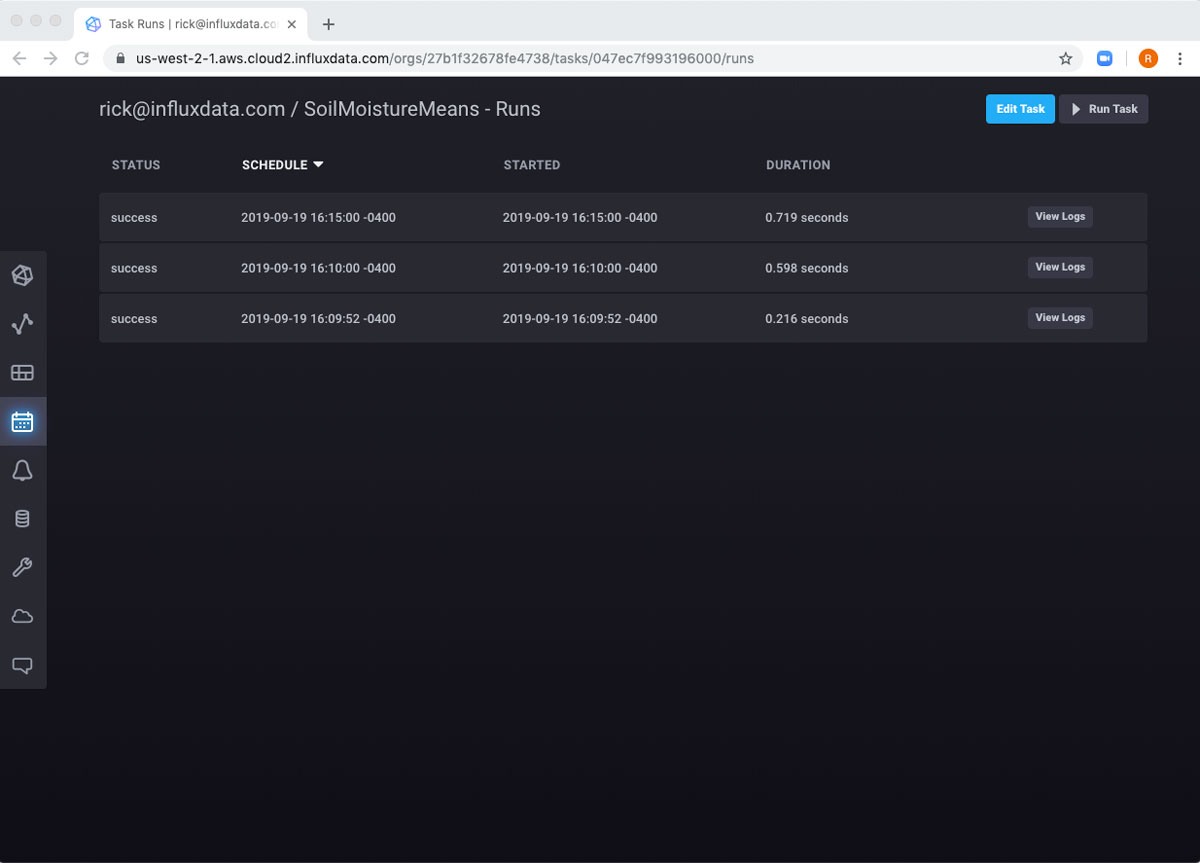
如果我将鼠标悬停在行上,我可以看到一些我可以与任务交互的不同方式。例如,我可以手动运行任务,然后查看日志。
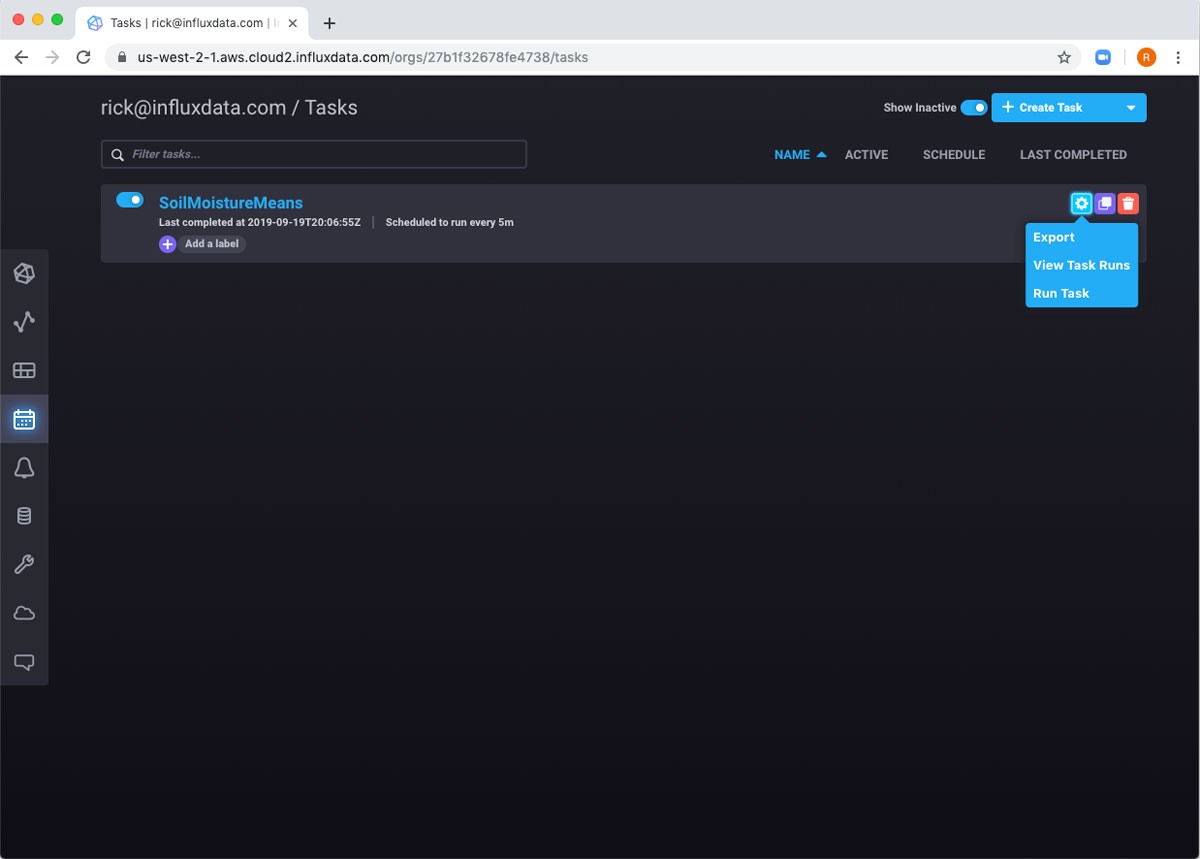

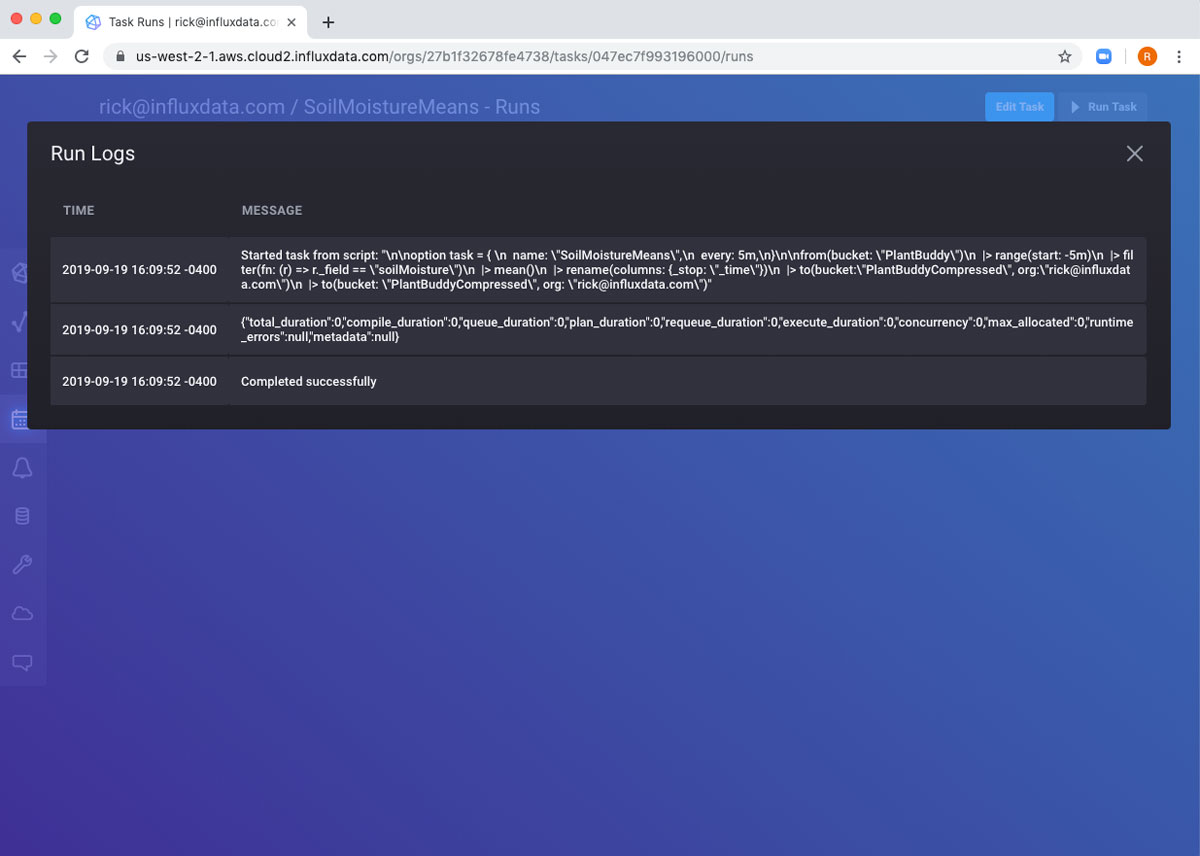
如果我等待五分钟,我可以看到任务已再次运行。
创建仪表板
因此,我定期且可靠地运行我的任务真是太棒了。但我真正想要的是一个仪表板,以便我可以一目了然地看到我的植物的生长情况。要开始使用,我将返回数据浏览器,以便我可以开始处理新查询。
这次,我对我的新存储桶 PlantBuddyCompressed 感兴趣,因此我将从那里选择 soilMoisture 读数。
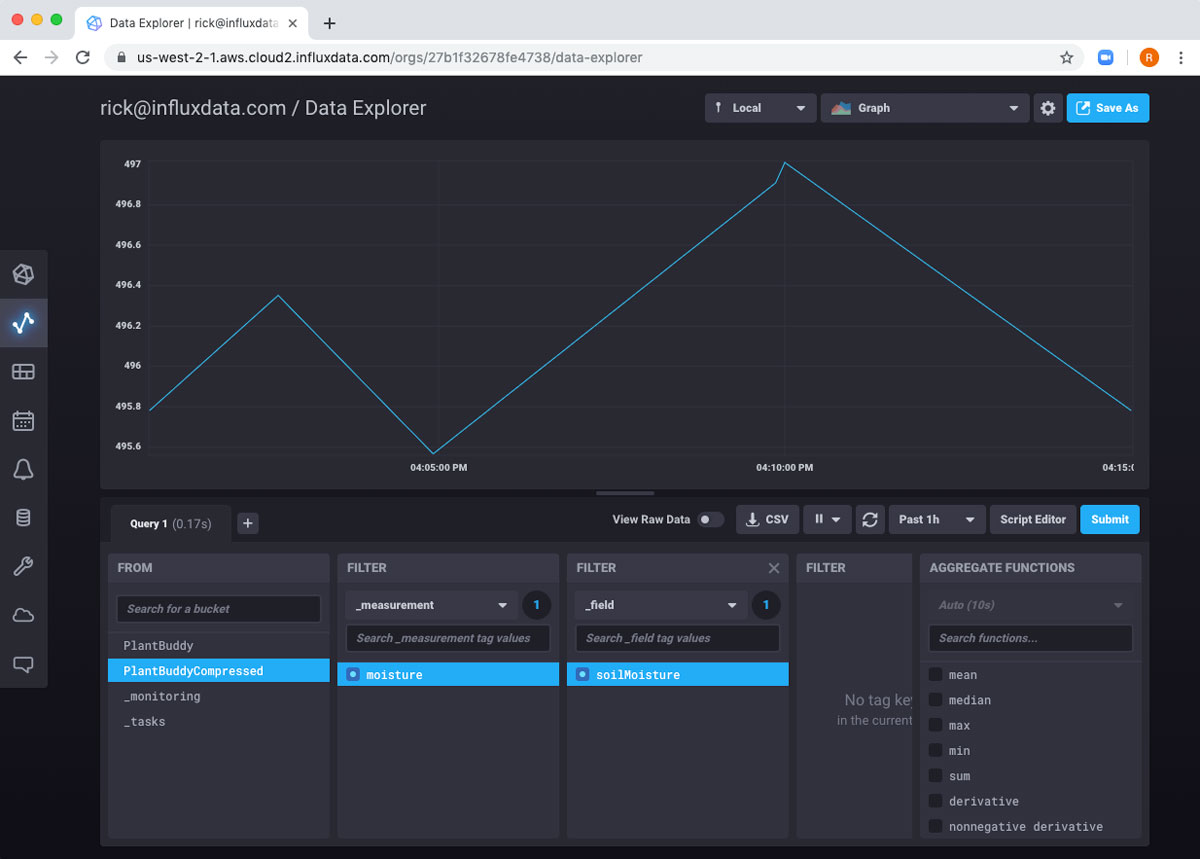
因此,我可以看到我的数据,但默认视图对于我的仪表板来说并不是很完美。我真的希望它自动刷新,并且我想查看值在 0 到 1000 的完整可能范围内的位置。为了实现这些,我只需单击右上角的齿轮图标,并将图表配置为我想要的方式,并将其设置为每 60 秒刷新一次。
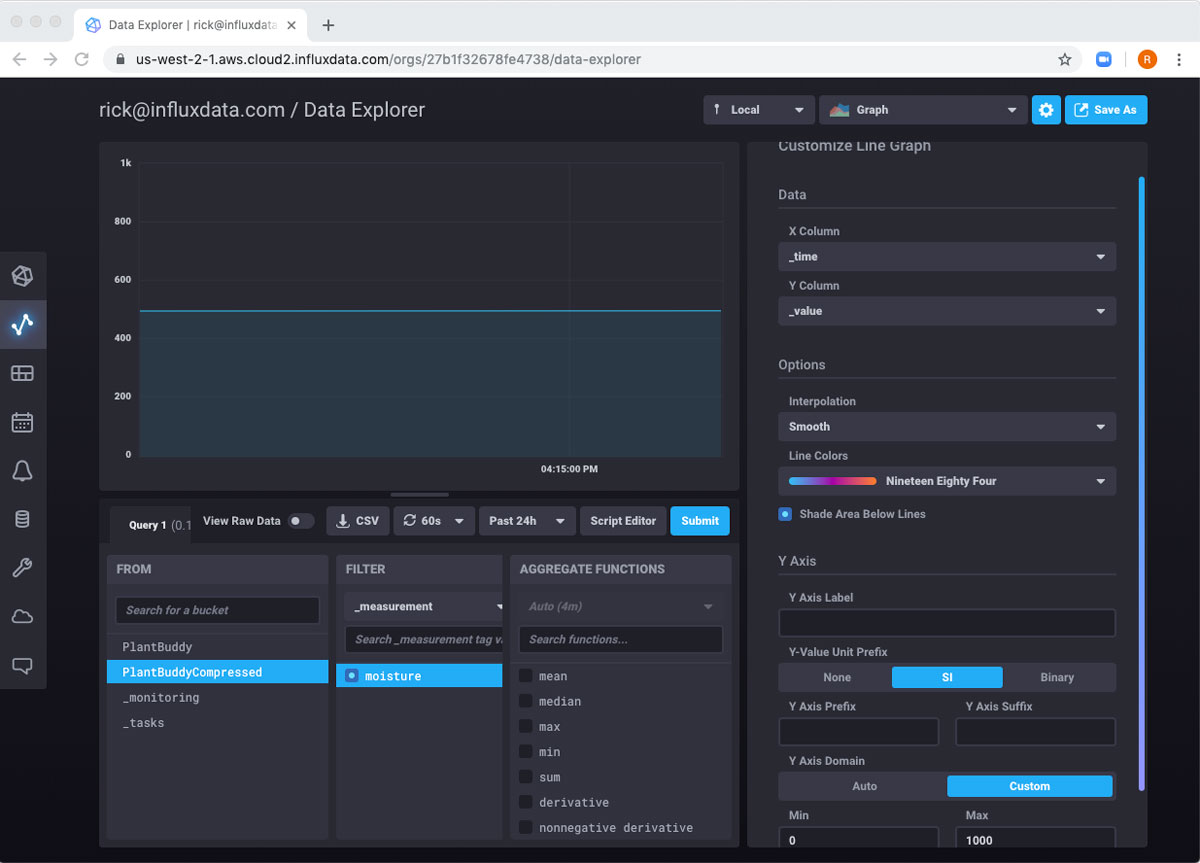
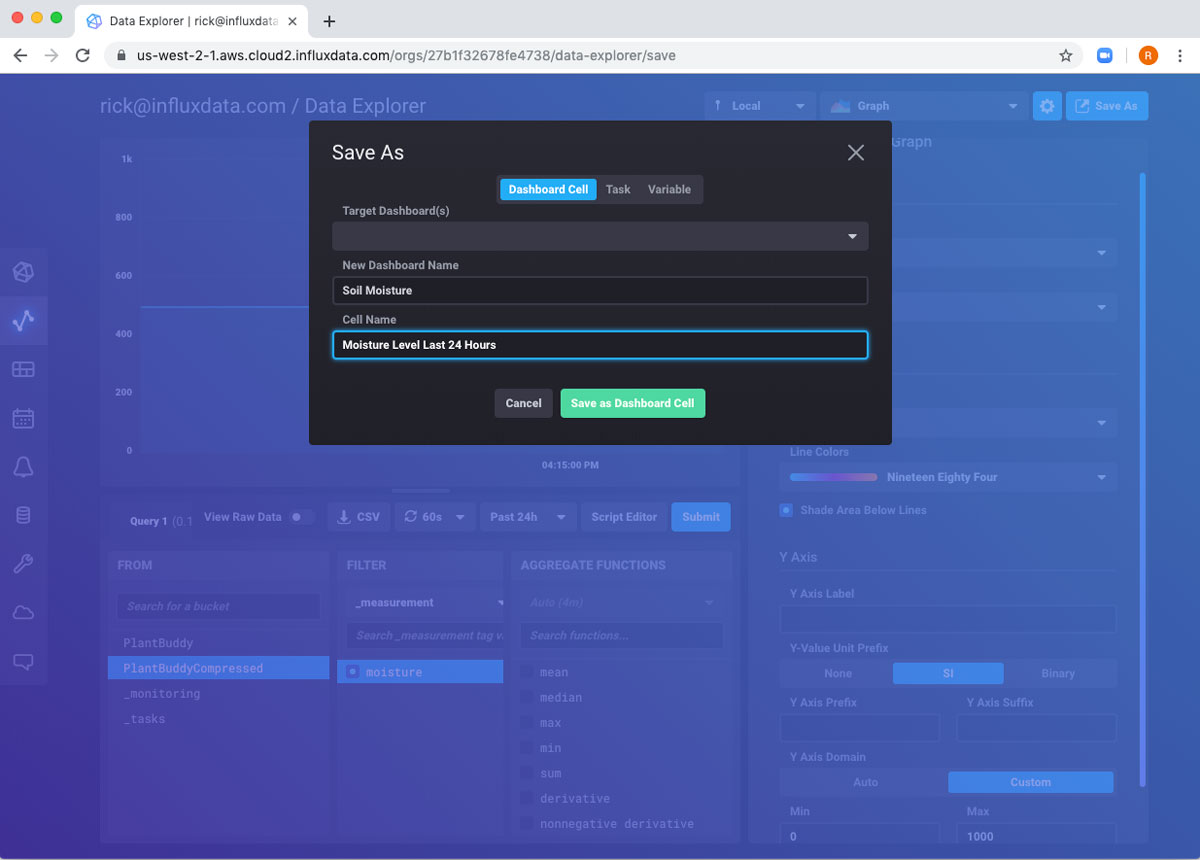
现在,我想将所有这些导出到仪表板。同样,右上角的 另存为 按钮将允许我执行此操作。
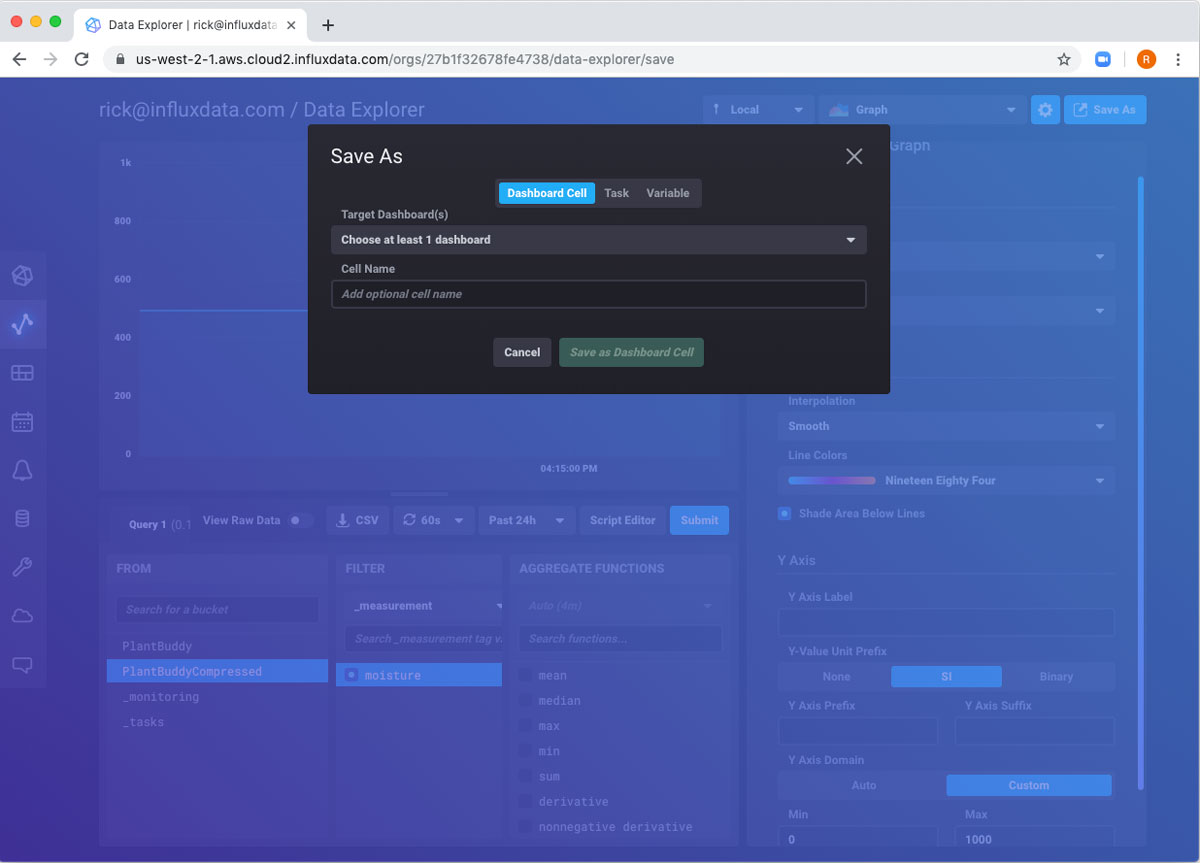
由于没有现有仪表板,我需要使用下拉列表选择创建新仪表板。我填写表单并保存。
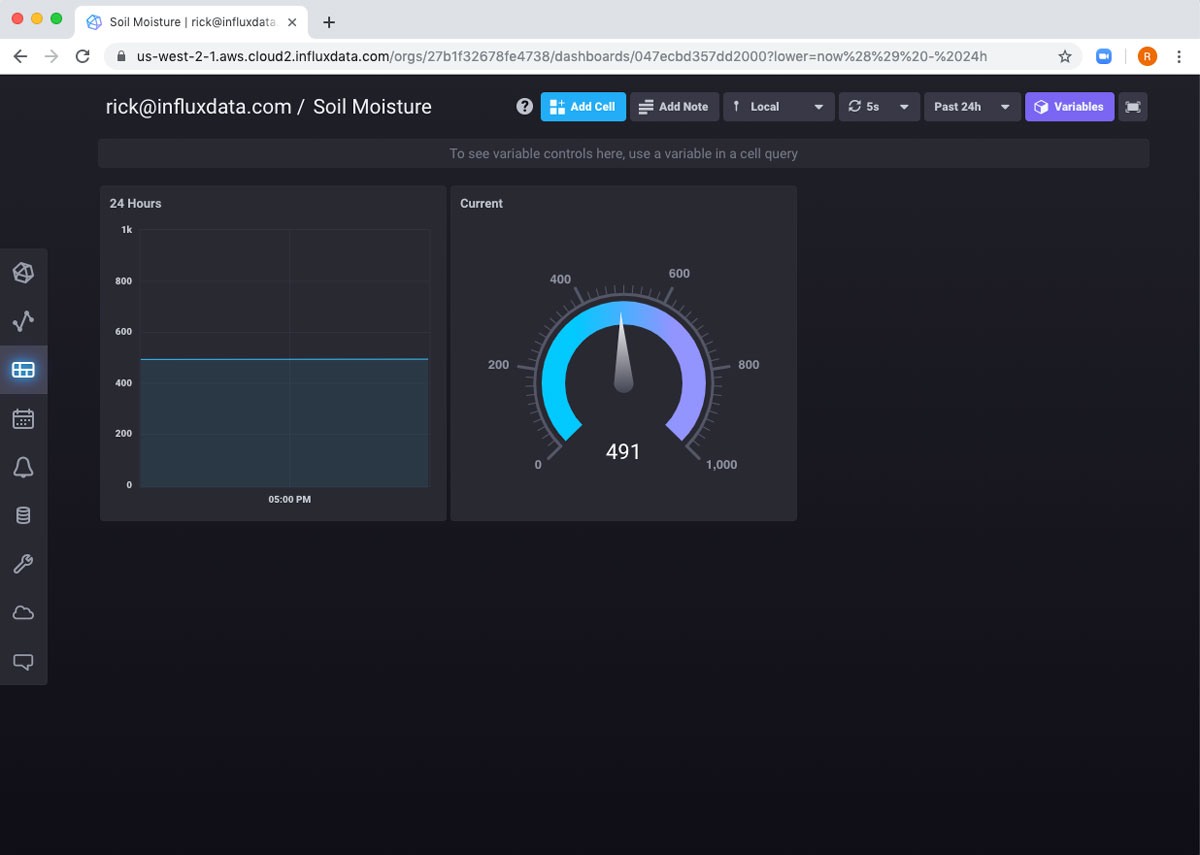
现在,如果我导航到左侧导航栏中的仪表板,我可以看到我的新仪表板已创建。如果我单击它,看起来好像没有任何效果。
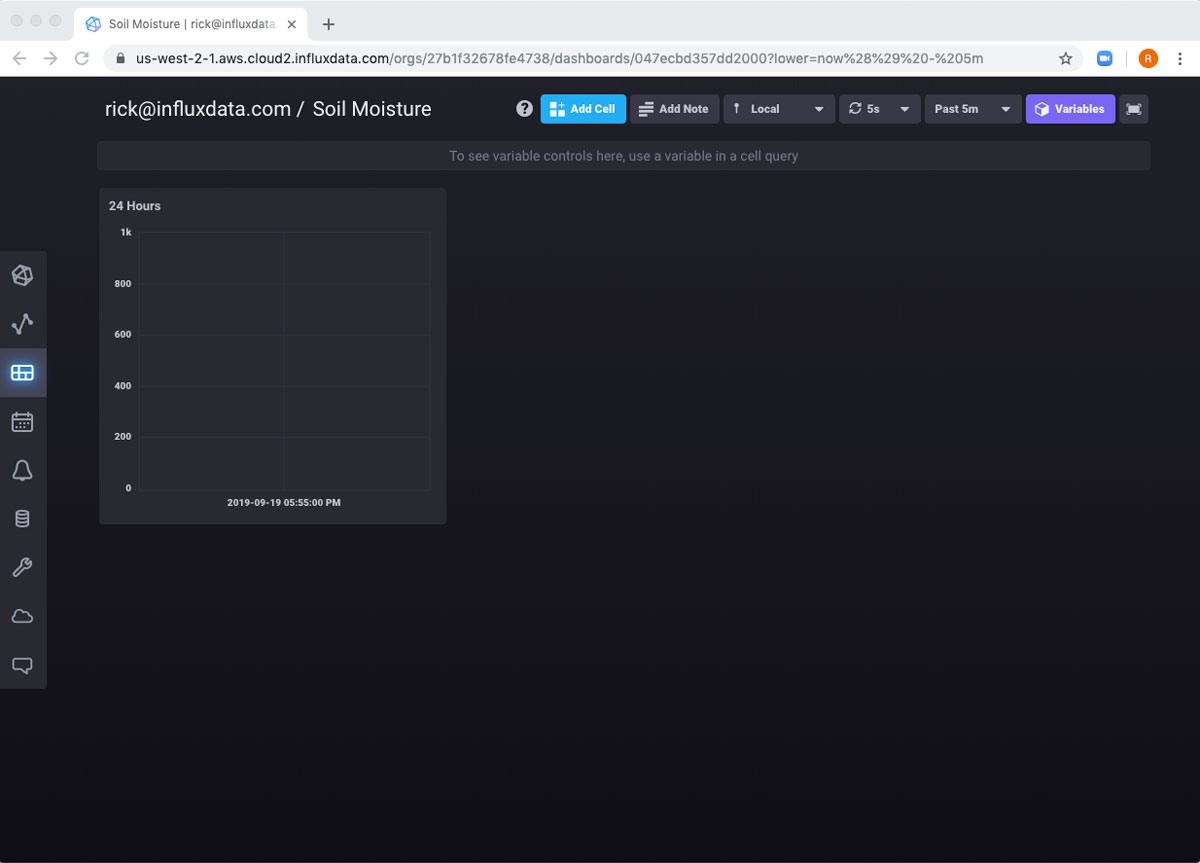
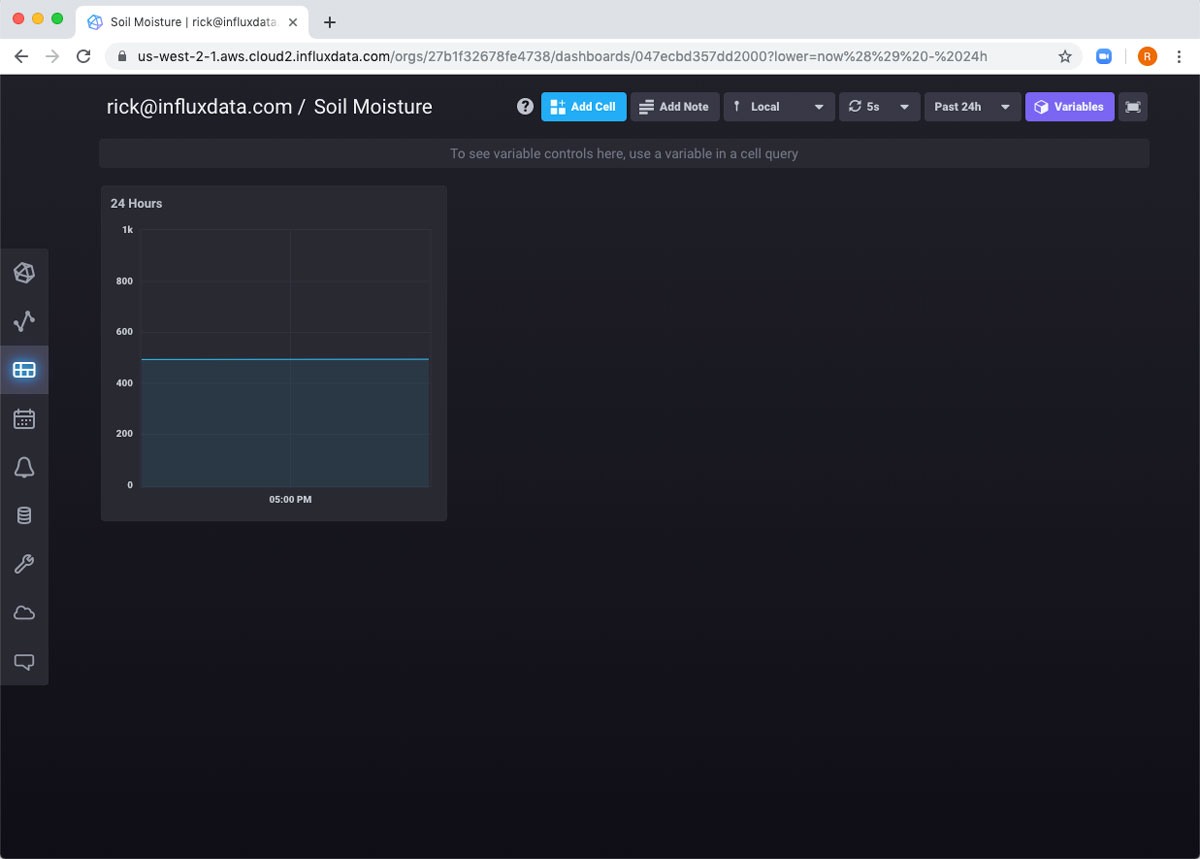
这只是因为仪表板顶部的全局范围设置为 5 分钟。如果我将其更改为 24 小时,它就可以正常工作了。
我想在仪表板中添加其他内容:当前的土壤湿度水平。我将从未压缩的存储桶中获取它。由于这是一个单独的数字,我可以使用仪表来可视化它。
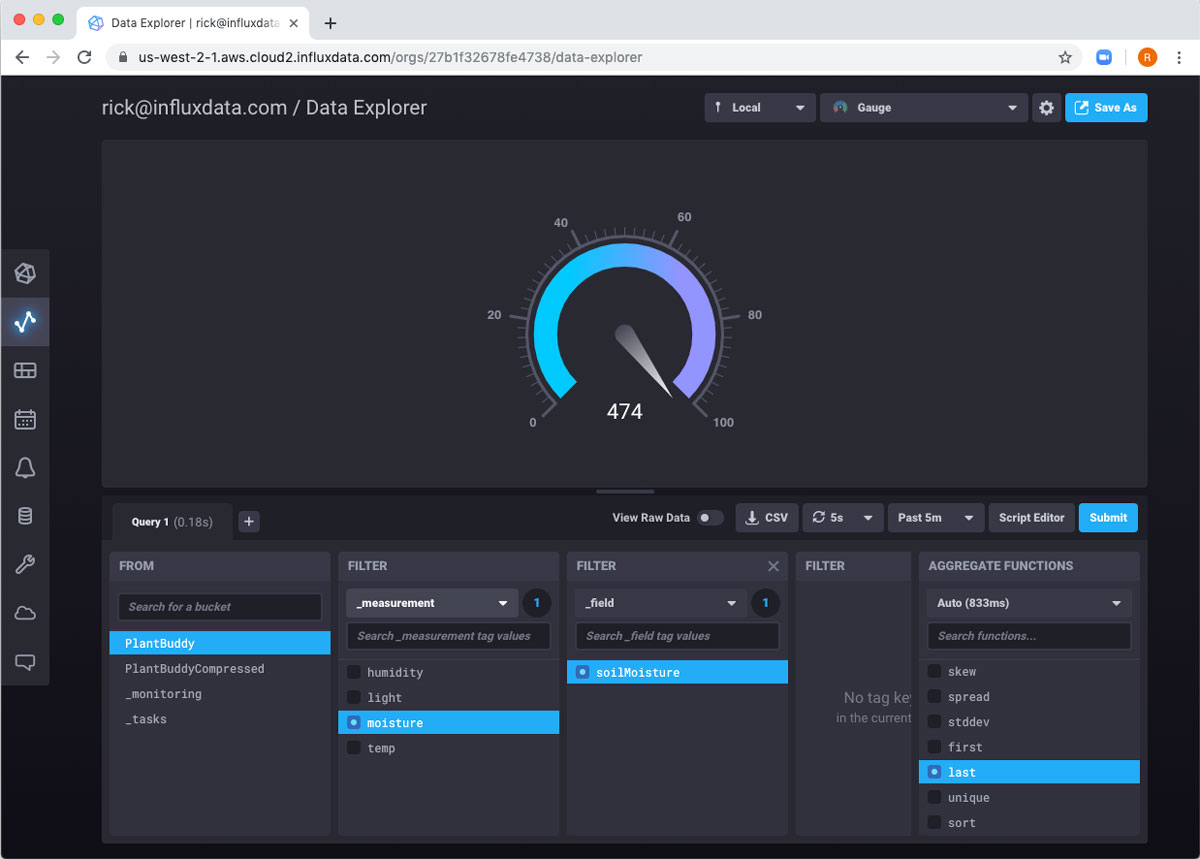
我将仪表的范围更改为 0 到 1000。
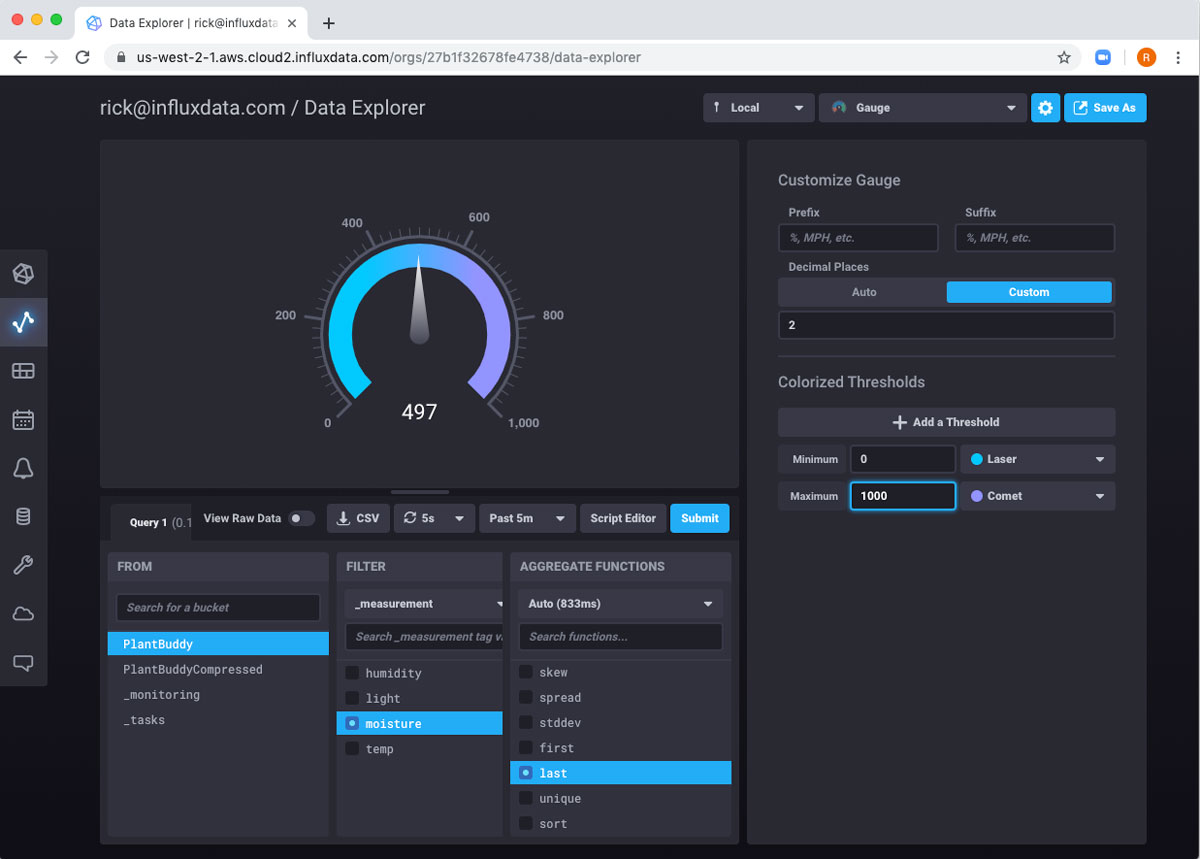
然后我将使用 另存为 按钮创建另一个仪表板单元格。现在我的仪表板上有两个单元格,我可以密切关注我的植物了!
现在您已完成阅读本系列文章的第二部分,请继续阅读第三部分。
