InfluxData 的 InfluxDB 和 TICK Stack 简介
作者:Gunnar Aasen / 产品, 开发者, 公司
2017 年 9 月 22 日
导航至
InfluxData 提供了一个 现代 时间序列平台,从头开始设计,以处理指标和事件。 InfluxData 的产品 基于开源核心。这个开源核心由以下项目组成:Telegraf、InfluxDB、Chronograf 和 Kapacitor - 统称为 TICK Stack。
什么是时间序列?
时间序列简单来说就是任何一组带有时间戳的值,其中时间是数据的有意义组成部分。时间序列的经典现实世界示例是股票货币兑换价格数据。例如,下图(来自 Coinbase Charts)显示了过去一个月美元兑比特币的兑换价格。
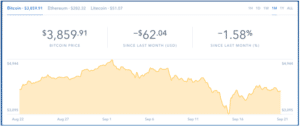
正如您在上图中看到的,比特币的美元价格随时间显示。用于创建此图表的底层数据集由许多带时间戳的值组成,这些值共同形成一组值。这组值就是一个时间序列。
此时您可能会想知道……
这有什么特别之处?
上图显示了一个月数据中的几千个点。然而,像比特币这样的加密货币交易频繁,因此用于导出该图表的底层数据集可能包含数千万个数据点。事实上,大多数时间序列通常包含大量数据,因此在显示时几乎总是会被总结,并且屏幕没有足够的像素来显示数据的完整粒度。还有其他加密货币,以及数千种常规货币正在兑换。
正在生成的时间序列数据量简直巨大。这种规模一直是创建专门的时间序列数据存储的主要驱动因素之一。
究竟什么是时间序列数据库?
时间序列数据库通常需要解决两个问题:高写入吞吐量和高查询率。让我们更深入地探讨这些要点。
- 写入吞吐量:例如,监控服务器群生成的时间序列量可以从每秒数千个新值快速增长到每秒数百万个新值。将如此大量的数据插入到像 MySQL 和 PostgreSQL 这样的常规关系数据库中,如果没有仔细调整,很快就会使大多数系统崩溃。即便如此,系统在任何给定时间可以接受的数据量也是有限的。
- 查询吞吐量:时间序列数据的一个方面是,新数据几乎总是比旧数据更有价值。再次以服务器群为例。知道一台服务器已开始耗尽其所有 CPU 比在 CPU 峰值出现几分钟后才查看证据更有用。时间序列的实时性使得尽可能快地在查询中公开新数据变得必要。此外,并非时间序列中的每个点都很重要。就像上面的比特币图表一样,大多数时间序列数据被总结为中间值,因为趋势比单个数据点提供更多信息。
由于时间序列数据库专门处理带时间戳的数据,因此有许多优化方法可以解决上述两个基本问题以及其他一些问题。
- 压缩:由于所有时间序列都由带时间戳的数据组成,因此可以实现大量的压缩。
- 查询函数:速度不是查询中唯一重要的事情。
什么是 InfluxDB?
InfluxDB 是一个高性能时间序列数据库。它可以每秒存储数十万个点。InfluxDB 类 SQL 查询语言专为时间序列而构建。查看 InfluxDB 文档 以开始了解更多信息。
什么是 TICK Stack?
TICK Stack 是一个首字母缩略词,代表一个开源工具平台,旨在使时间序列数据的收集、存储、绘图和警报变得异常简单。“TICK”中的“I”代表 InfluxDB。平台中的其他组件包括:
- Telegraf:指标收集代理。使用它来收集指标并将指标发送到 InfluxDB。Telegraf 的插件架构支持开箱即用地从 100 多个常用服务收集指标。
- Chronograf:整个 TICK Stack 的 UI 层。使用它来设置 InfluxDB 中数据的图形和仪表板,并连接 Kapacitor 警报。
- Kapacitor:指标和事件处理以及警报引擎。使用它将时间序列数据压缩为可操作的警报,并将这些警报轻松发送到许多流行的产品,如 PagerDuty 和 Slack。
整个 TICK Stack 是可互操作的,但每个组件都可以作为独立安装提供重要的价值。
本指南的其余部分将解释如何在 macOS 上设置 TICK Stack 以进行开发和测试。
步骤 1:安装 TICK Stack
在 macOS 上,使用 Homebrew 包管理器 可以轻松安装 TICK Stack。
brew install telegraf
brew install influxdb
brew install chronograf
brew install kapacitor上述命令会将多个二进制文件安装到您的路径中。重要的文件包括 telegraf、influxd (InfluxDB 服务器)、influx (InfluxDB CLI)、chronograf、kapacitord (Kapacitor 服务器) 和 kapacitor (Kapacitor CLI)。
步骤 2:配置 TICK Stack
Telegraf、InfluxDB 和 Kapacitor 都使用配置文件。TICK Stack 中的大多数配置值在 macOS 上开箱即用时都不需要更改。事实上,Chronograf 不需要配置文件,并且可以通过 CLI 标志完全配置。以下是为其他三个组件生成新配置文件的命令
# The telegraf config generated here will be already set up to only gather CPU, memory, and system metrics.
telegraf --input-filter cpu:mem:system --output-filter influxdb config > /usr/local/etc/telegraf.conf
influxd config > /usr/local/etc/influxdb.conf
kapacitord config > /usr/local/etc/kapacitor.conf在 macOS 上,InfluxDB、Chronograf 和 Kapacitor 将分别将其数据存储在 ~/.influxdb、~/.chronograf 和 ~/.kapacitor 的默认目录中。这些位置可以在配置文件中被覆盖,但现在不需要更改。
步骤 3:运行 TICK Stack
现在配置文件已生成,使用 Homebrew 服务启动 TICK Stack 非常容易。
brew services start telegraf
brew services start influxdb
brew services start chronograf
brew services start kapacitor这将在后台启动所有 TICK 组件进程。如果您遇到任何问题,可以在 /usr/local/var/log 目录中找到 Homebrew 服务的日志。
瞧!TICK Stack 现在正在运行。在此设置中,Telegraf 正在收集 CPU 和内存指标,并将它们写入到自动创建的 InfluxDB 的 telegraf 数据库中。
有几种方法可以与堆栈交互。InfluxDB 和 Kapacitor 具有可用的 API,以及使与它们的 API 交互更容易的 CLI 工具。可以配置其他 Telegraf 插件以收集更多数据。最后,Chronograf 为 InfluxDB 中的数据提供了一个 UI。
让我们在浏览器中打开 Chronograf,看看正在收集的数据。导航到 https://:8888。这将打开一个配置页面。使用默认设置将自动将 InfluxDB 连接到 Chronograf,并允许您开始探索您已开始在 InfluxDB 中收集的本地系统数据。
下一步
要了解有关 InfluxDB 和 TICK Stack 的更多信息,请阅读 InfluxDB 入门指南。然后查看 InfluxDB 关键概念文档,这是 InfluxDB 数据模型的出色概述。
查看 Telegraf 和 Kapacitor 的入门指南。如果您有疑问或遇到错误,我们建议查看 InfluxData 社区。最后,TICK Stack 是开源的,并且始终 欢迎新的贡献者。
