InfluxDB 的检查和通知系统
作者:Anais Dotis-Georgiou / 产品
2021 年 4 月 19 日
导航至
InfluxDB 2.0 的检查和通知系统可能是目前用于基于时间序列数据创建警报的最强大和最灵活的系统。为了充分利用该系统,了解不同的组成部分以及它们如何协同工作会很有帮助。阅读本文后,您应该能够使用 InfluxDB 2.0 用户界面 (UI) 创建精确的警报,并能够扩展和自定义系统以满足您的特定需求。
组件
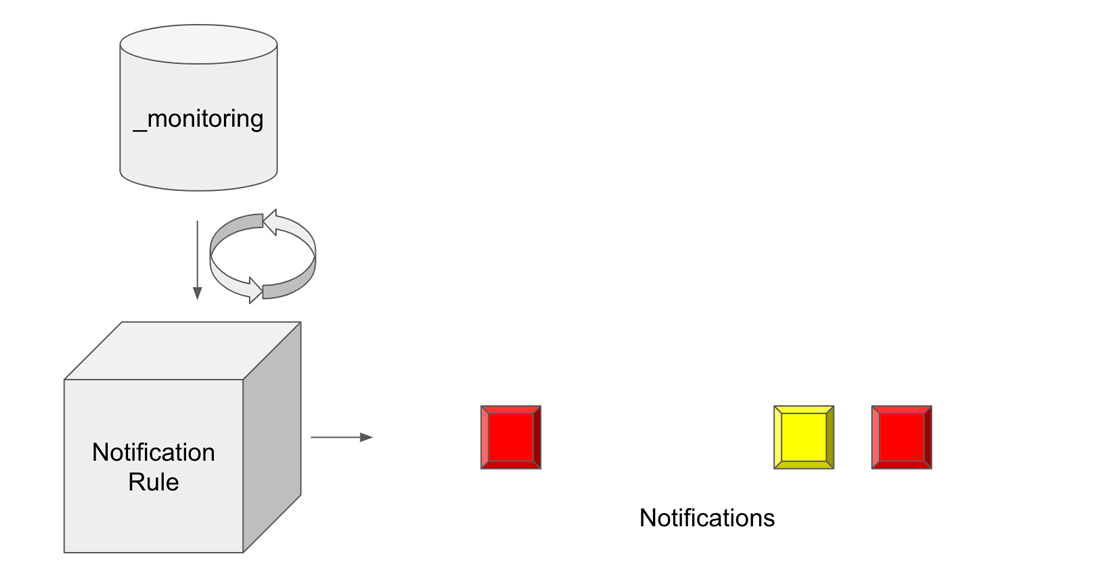
与功能较弱且灵活性较差的警报系统不同,InfluxDB 2.0 检查和通知系统包含五个组件,这些组件充当构建块,可以组合起来创建您需要的精确功能。
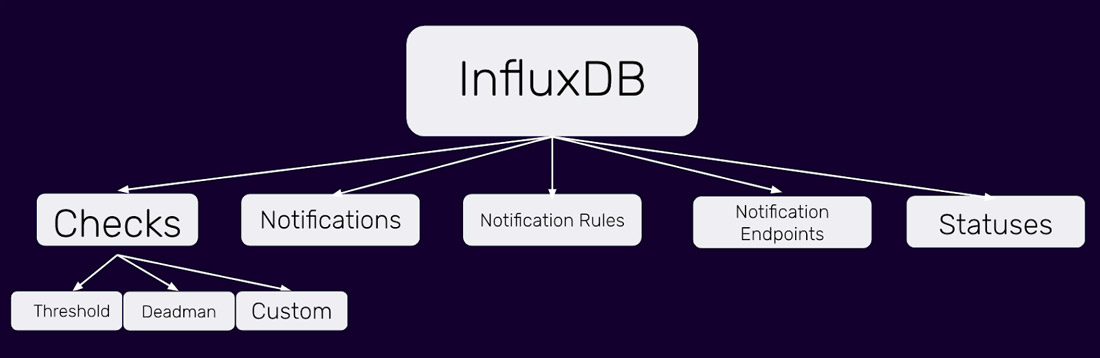
检查、通知、通知规则、通知端点和状态是构成 InfluxDB 2.0 检查和通知系统的五个组件。这些高度可定制的组件使您能够构建警报,以便您可以采取复杂的纠正措施来响应时间序列数据中的复杂条件。
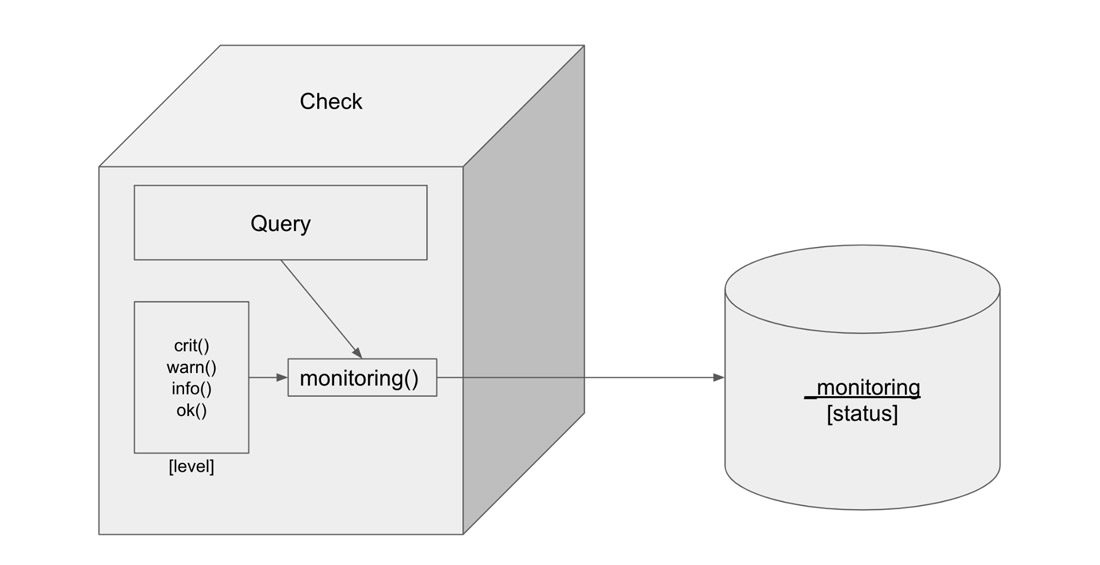
InfluxDB 中的检查
检查 在 InfluxDB 中是一种任务类型。任务 是一个 Flux 查询,它按计划或定义的频率运行。Flux 是 InfluxDB 的函数式数据脚本语言。Flux 允许您以几乎任何您需要的方式查询、转换和分析您的时间序列数据。检查查询数据并根据指定的条件为每个数据点应用状态或级别。检查的输出是一个状态,它被写入 “_monitoring” 存储桶。“_monitoring” 存储桶是一个默认的内部存储桶。
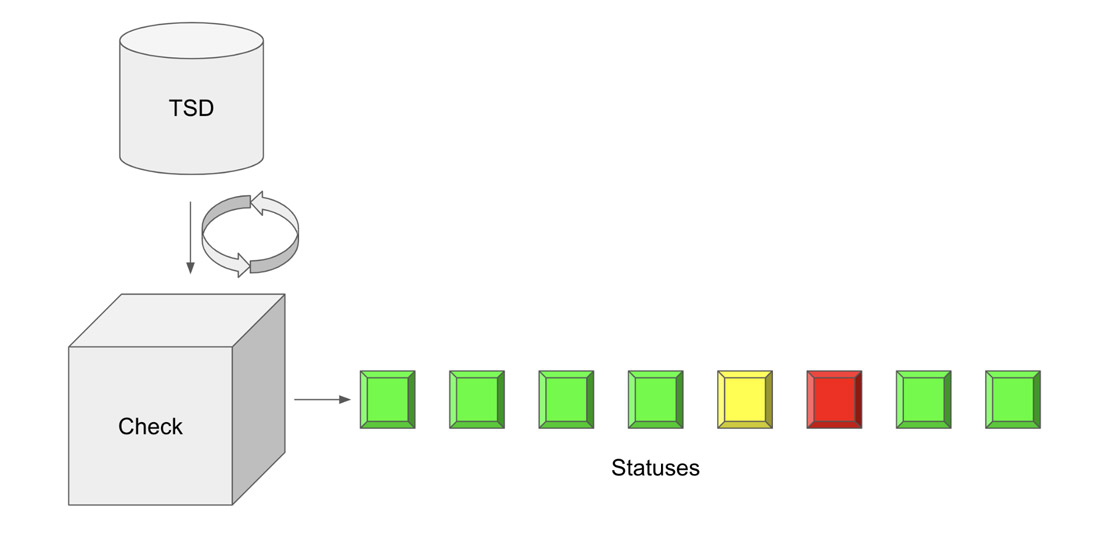
有两种方法可以创建检查。您可以通过 UI 创建检查,也可以使用 Flux 编写自定义检查。在开始使用 InfluxDB 编写检查的多种方法之前,重要的是要认识到 UI 使用 InfluxDB v2 API,并且所有检查都是用 Flux 编写的。因此,通过 UI 生成的检查将与作为任务自定义编写的检查一样高效。这就是 InfluxDB 和 Flux 的强大之处——开发者真正有能力自定义他们的时间序列工作负载,使其满足他们的需求。
InfluxDB UI 中的阈值检查
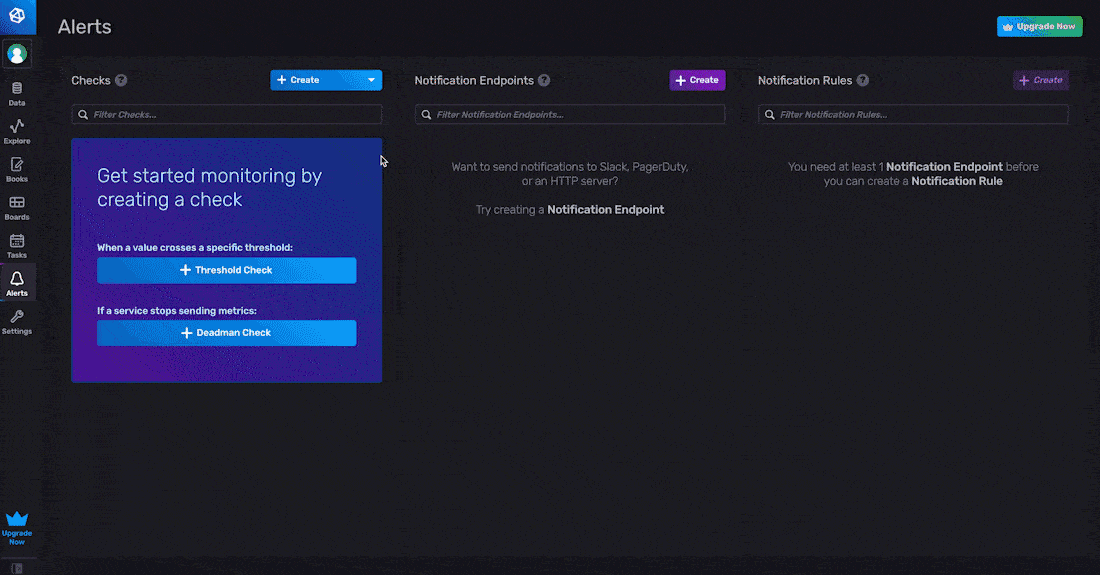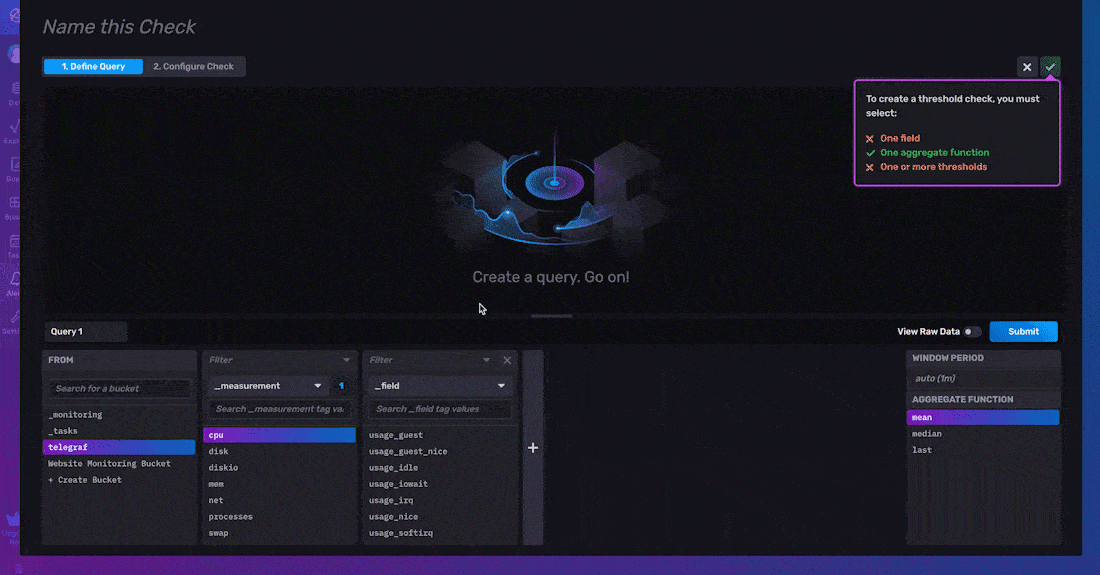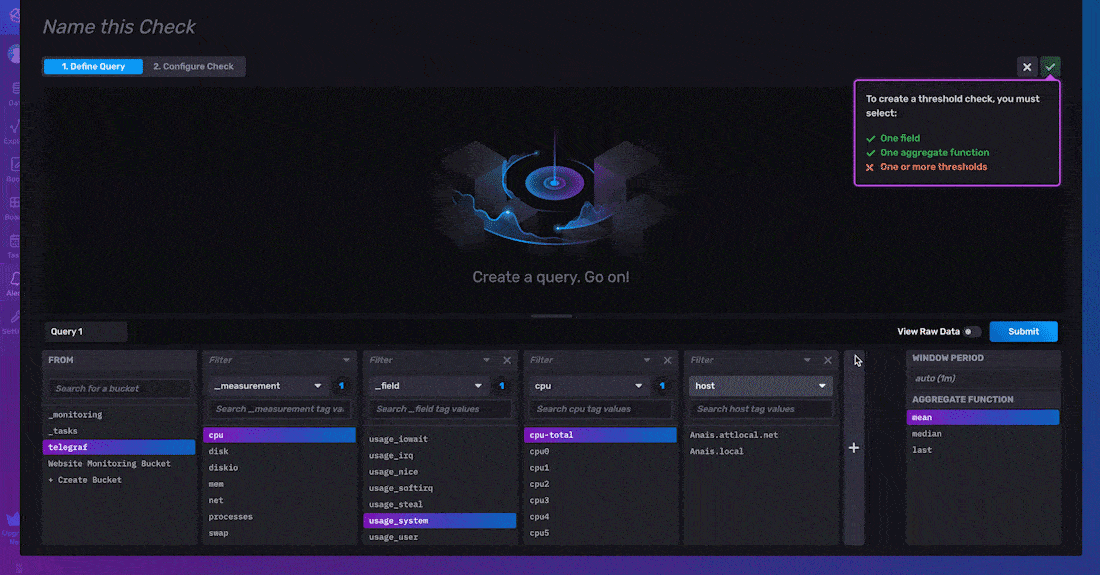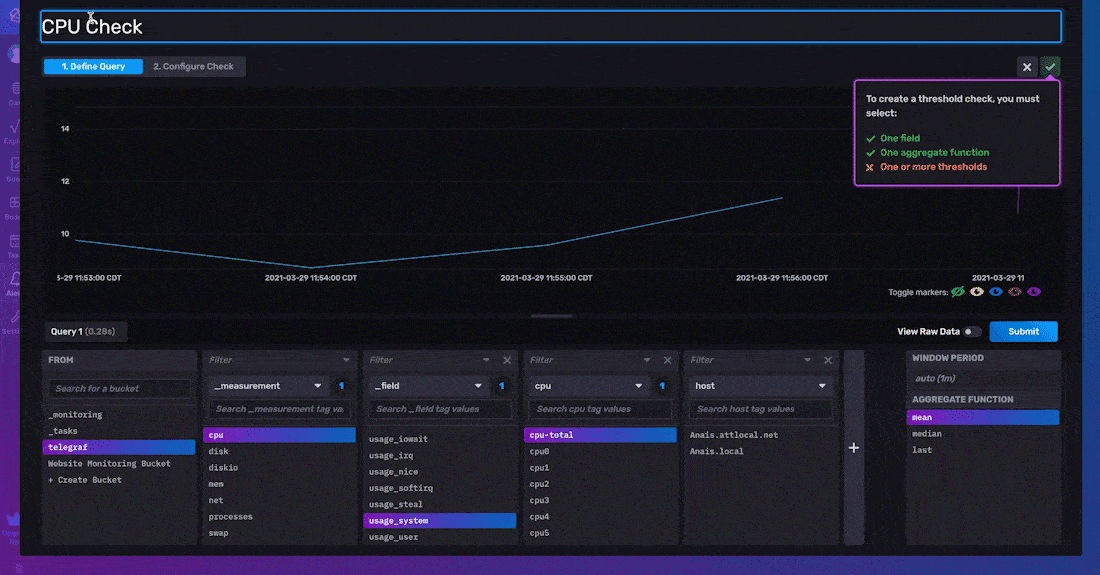
创建检查的最简单方法是通过 UI。您可以通过 UI 创建阈值检查或死信检查。要创建 阈值 或 死信 检查,请从右侧导航菜单导航到 UI 中的警报页面,单击 + 创建,然后在检查面板下选择阈值或死信检查。通过 UI 创建阈值检查有两个步骤
- 定义查询
- 配置检查
要 定义您的查询,请选择您要对其创建检查的字段。接下来,将 聚合函数 应用于您的数据。平均值是根据窗口期计算的,窗口期与 计划频率 配置选项匹配。默认情况下,聚合函数应用于您的数据有两个原因。首先,用户更喜欢对数据的趋势而不是原始时间序列数据发出警报。其次,此默认聚合间隔确保您的检查运行计划与您的聚合数据输出对齐。您可以通过更改 计划频率 配置选项来配置应用聚合的窗口期,如下所述。
要 配置您的阈值检查,您必须指定检查的 属性、状态消息模板 和 阈值。
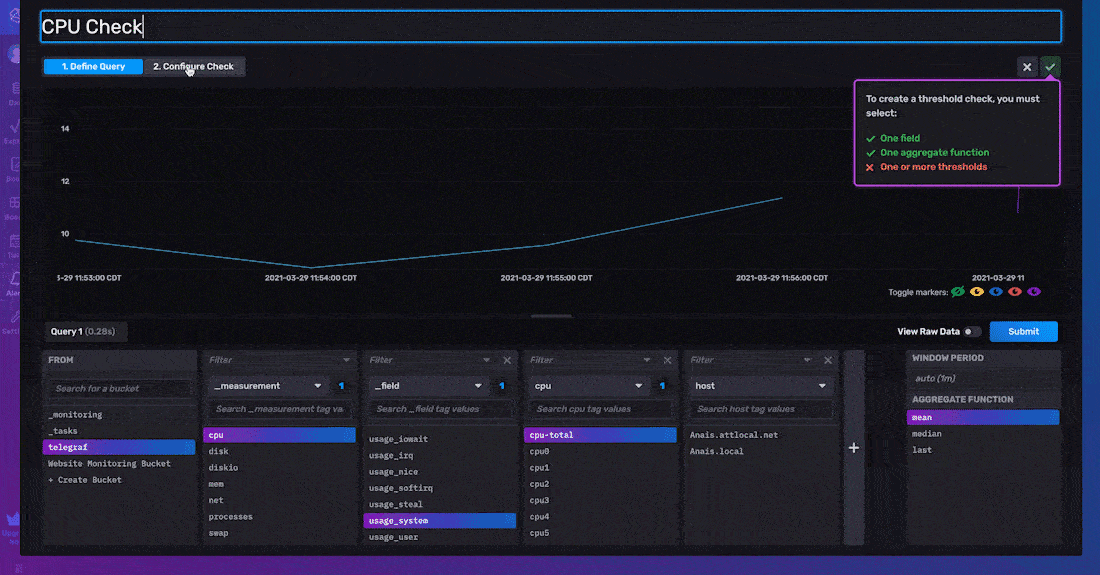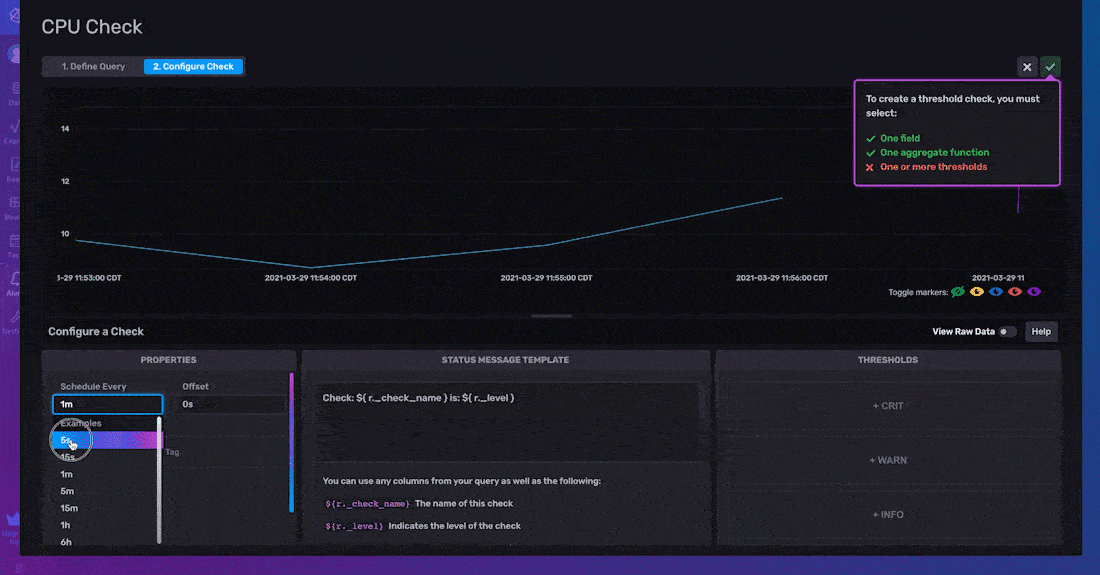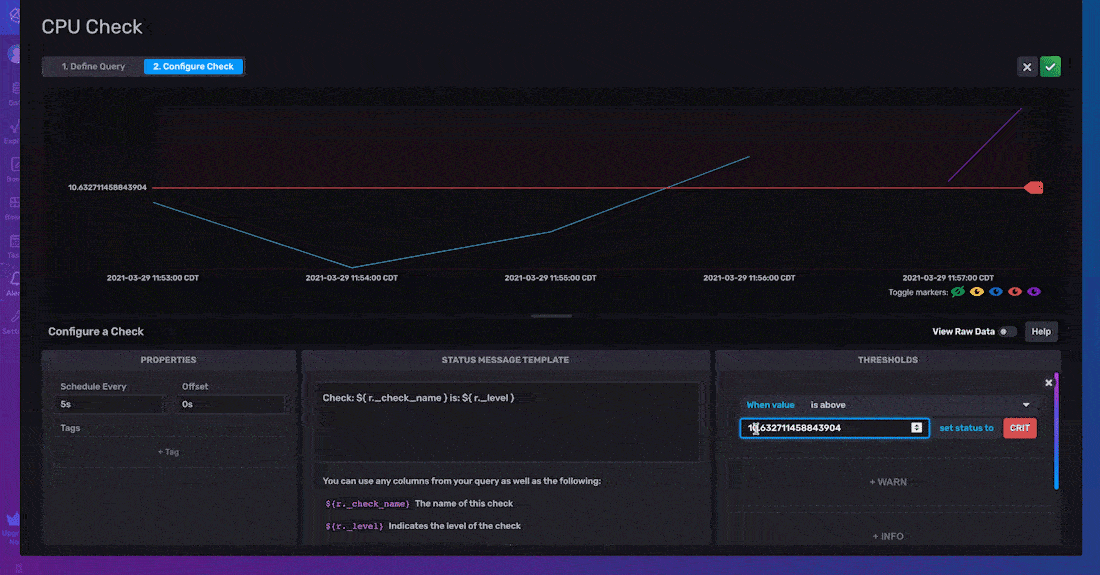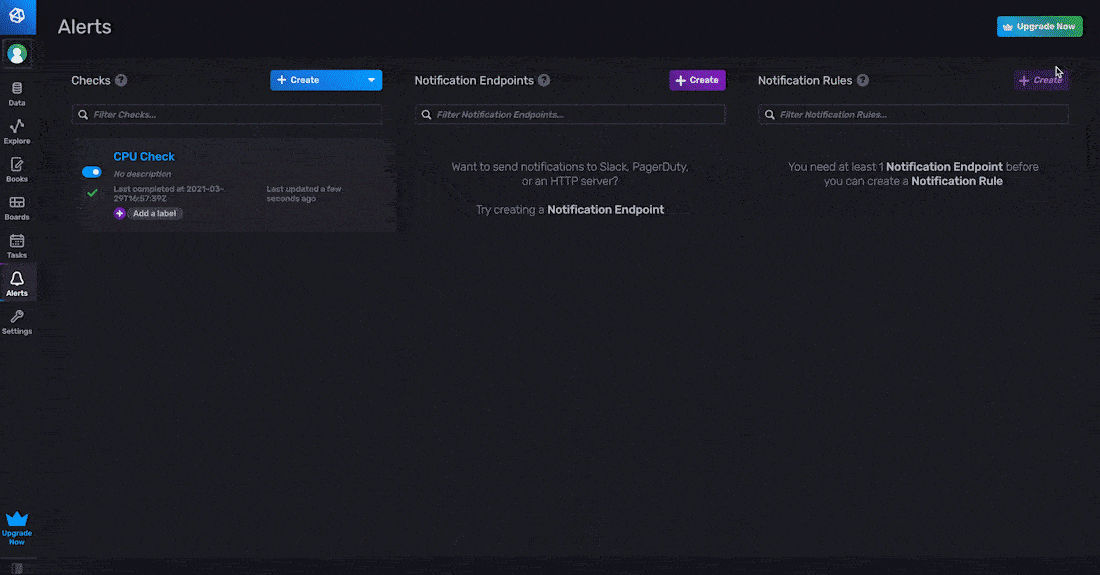
检查属性包括 计划频率(运行检查的间隔)和 偏移量(延迟任务执行的间隔)。包含偏移量可以帮助您避免读/写冲突,并有助于成功进行指标缓冲。最后,标签 属性允许您向检查输出添加自定义标签。此检查属性将添加一个新列,其中您的指定标签键作为列名,标签值作为行值。
向检查输出添加标签可以方便进一步的数据处理。例如,您可能决定仅当多个字段满足某些检查条件时才实施纠正措施或编程响应。由于所有检查的输出都写入 “_monitoring” 存储桶,因此向这些相关字段添加标签将有助于在这些检查之上编写后续通知和/或任务,因为您可以通过筛选您添加的标签轻松查询所有相关的检查状态数据。
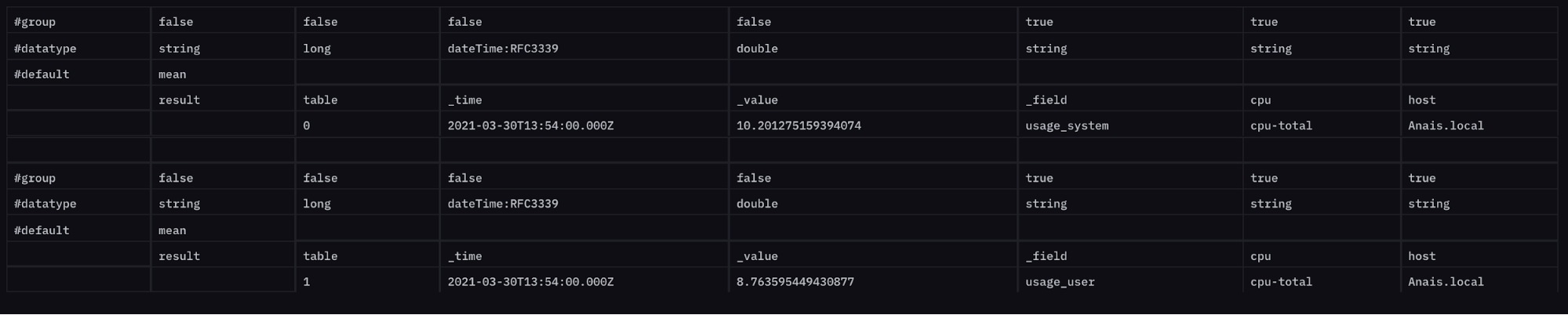
状态消息模板 允许您在通知和警报中包含自定义消息。这些状态消息可以帮助用户了解他们的检查是关于什么的。它们还可以用于在数据管道中进一步向下传递与检查或通知端点相关的重要信息,以供将来使用和集成。默认状态消息如下所示
检查:${ r._check_name } 状态:${ r._level }
但是,您可以选择包含来自状态消息中任何列的信息,该状态消息包含在 “_monitoring” 存储桶中的检查输出中。状态中包含的列是
_check_id: 每个检查都分配有一个检查 ID。检查 ID 可用于调试和重新运行失败的检查_check_name: 您的检查名称——或上面示例中的 “CPU Check”_level: UI 检查的 CRIT、WARN、OK 或 INFO(或可为自定义检查配置)_source_measurement:您的源数据的 measurement——或上面示例中的 “cpu”_type:检查类型——或上面示例中的 “threshold”- 添加到查询输出的自定义标签
- 查询中包含的列:要查看所有这些列,只需将鼠标悬停在查询中的一个点上。
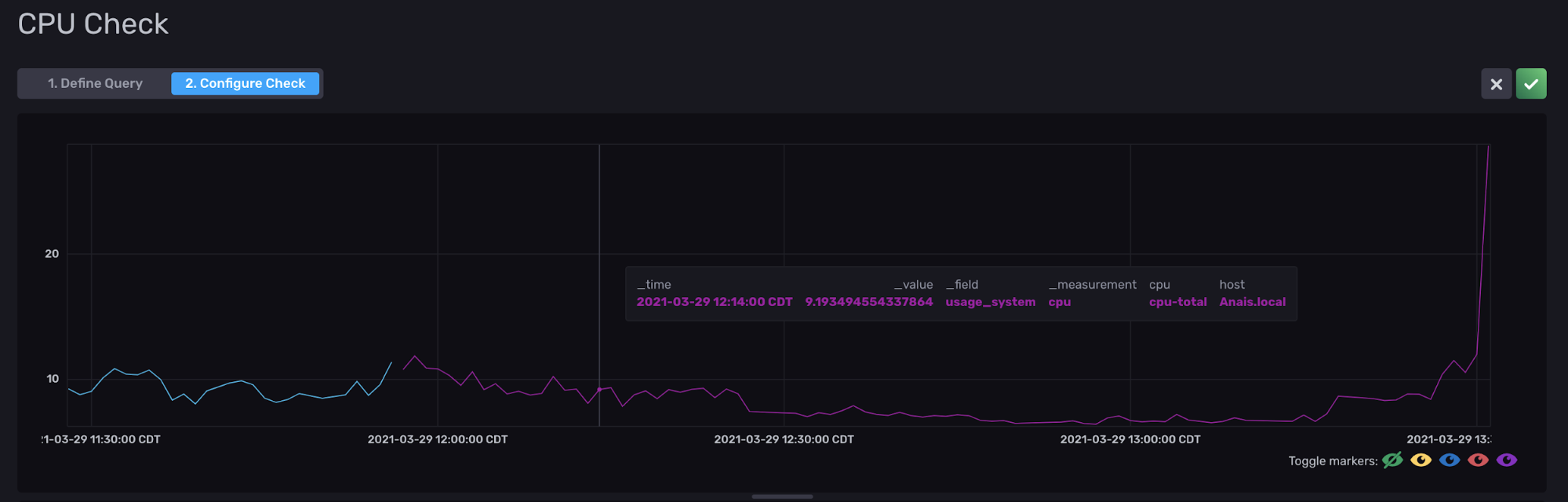
阈值检查背后的 Flux
要查看为您的阈值检查生成的相应 Flux 脚本,您可以使用 InfluxDB v2 API 或 UI。要查看为 UI 生成的阈值检查生成的相应 Flux 脚本,请查看默认的 “_task” 系统存储桶。
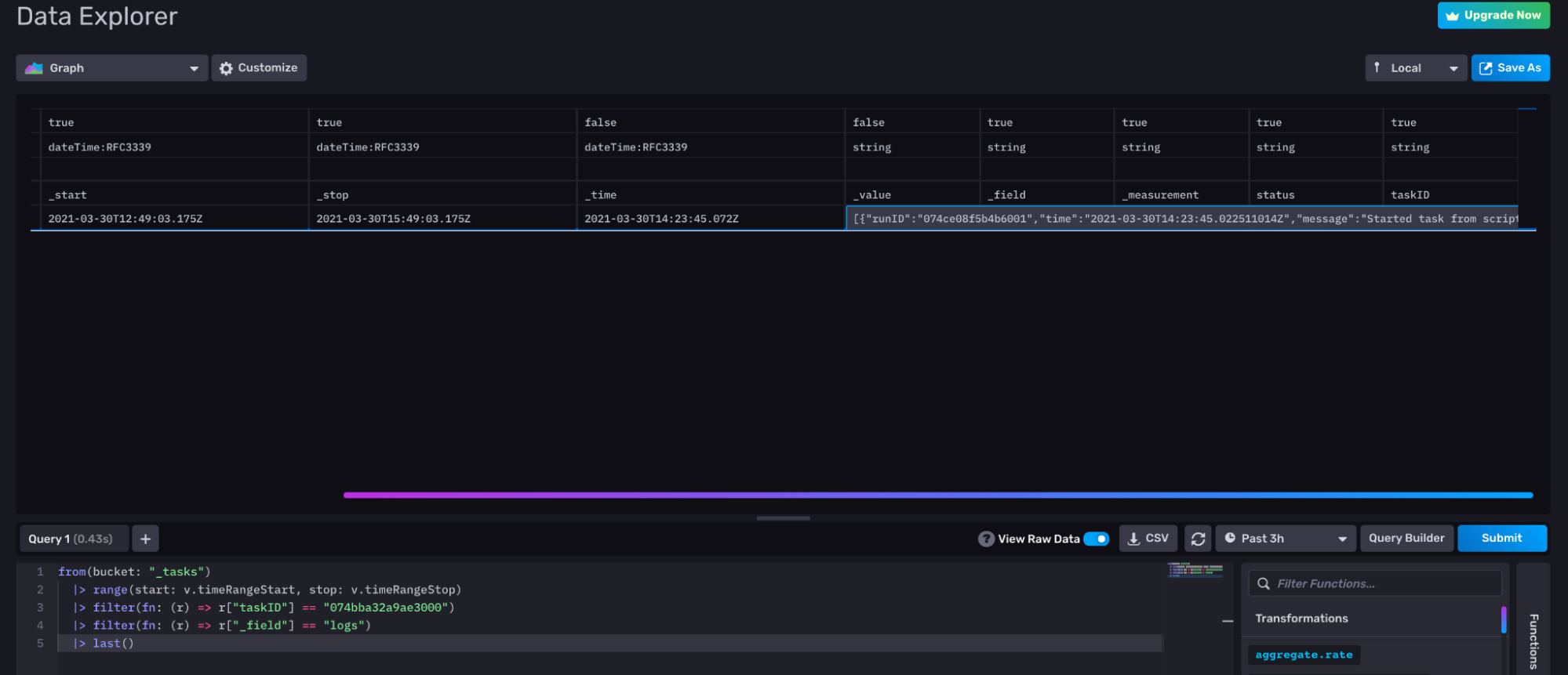
要通过 UI 筛选相应的任务,您可以首先执行以下查询
from(bucket: "_tasks")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_field"] == "name")滚动结果,直到找到您的检查并收集相应的 taskID。使用该 taskID 筛选您的任务,并找到检查的底层 Flux。以下查询使用该 taskID 筛选包含检查的底层 Flux 的日志。
from(bucket: "_tasks")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["taskID"] == "0754bba32a9ae300")
|> filter(fn: (r) => r["_field"] == "logs")如果您发现使用 UI 来显示底层任务很麻烦,请阅读功能请求 #1169,如果您认为在检查名称旁边显示底层任务 ID 和检查 ID 对您有用,请添加 +1 或评论。
要使用 InfluxDB v2 API 获取 UI 生成的检查的相应 Flux 脚本,请使用检查 ID 提交带有您的令牌作为授权参数的 GET 请求。这是一个 cURL 请求示例
curl -X GET \
https://us-west-2-1.aws.cloud2.influxdata.com/api/v2/checks/074...my_check_ID...000/query \
-H 'authorization: Token Oxxx
.my_token...xxxBg==' \获取检查 ID 的快速方法是在 UI 中编辑检查时查看 URL。
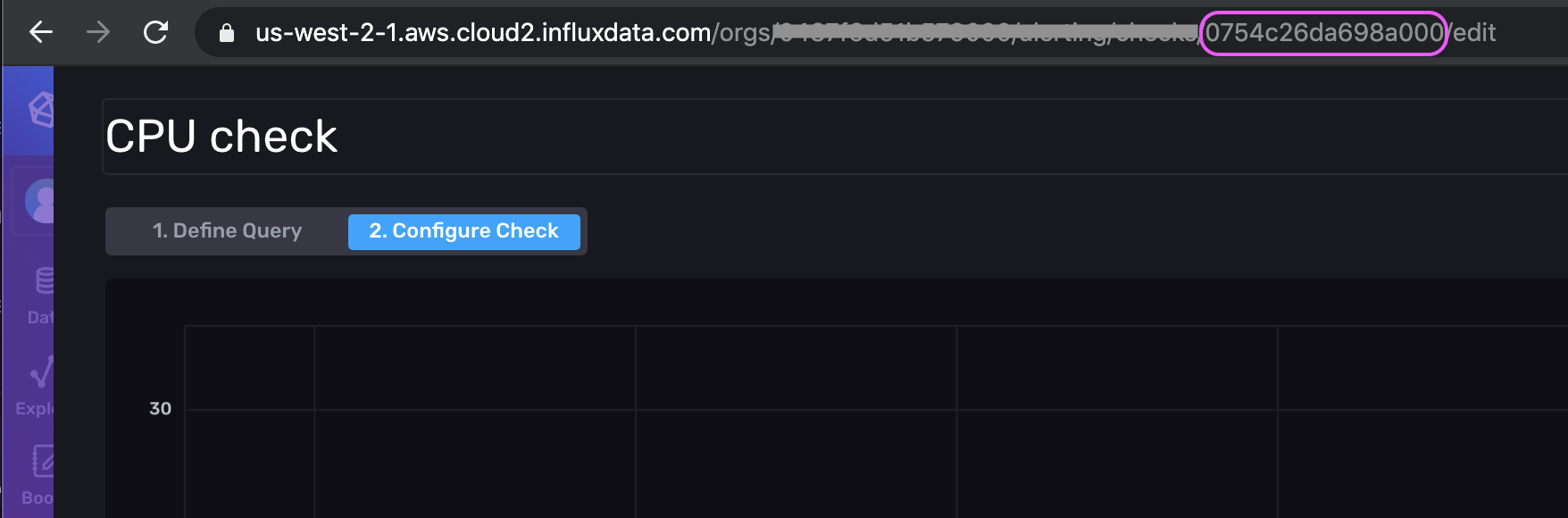
这是请求的相应数据部分,其中包含通过 UI 为上面的示例生成的检查的 Flux(原始 JSON 输出已转义并已清理以提高可读性)
package main
import "influxdata/influxdb/monitor"
import "influxdata/influxdb/v1"
data = from(bucket: "telegraf")
|> range(start: -5s)
|> filter(fn: (r) =>(r["_measurement"] == "cpu"))
|> filter(fn: (r) =>(r["_field"] == "usage_system"))
|> filter(fn: (r) =>(r["cpu"] == "cpu-total"))
|> aggregateWindow(every: 5s, fn: mean, createEmpty: false)
option task = {name: "CPU Check", every: 5s, offset: 0s}
check = {_check_id: "074bba32a48c3000",
_check_name: "CPU Check",
_type: "threshold",
tags: {},}
crit = (r) =>r["usage_system"] > 5.0
messageFn = (r) =>("Check: ${ r._check_name } is: ${ r._level }")
data
|> v1["fieldsAsCols"]()
|> monitor["check"](data: check, messageFn: messageFn, crit: crit)首先要注意的是,Flux 脚本使用了一种不太常用的 Flux 语法 - 方括号而不是点来表示 成员表达式。无论如何,我们可以看到在 UI 中生成阈值检查的步骤是如何通过这个相应的 Flux 脚本定义的。我们想要对其创建检查的数据被分配给 data 变量。聚合自动应用于 aggregateWindow() 函数。检查实际上只是一种特殊类型的任务这一事实通过聚合后的行中定义的任务选项突出显示。
检查参数在后续行中定义。自定义函数 定义了所选字段的关键阈值和状态消息,以便可以将它们传递到最后一行中的 monitor.check() 函数。monitor.check() 函数检查输入数据,为输出分配级别,并将输出写入 “_monitoring” 存储桶。最后,我们查询的数据 data 在传递给 monitor.check() 函数之前,使用 v1.fieldsAsCols 函数进行最后一次转换。此转换函数是 pivot() 函数的特殊应用,该函数旋转您的数据,以便您的字段被分离到多个列而不是多个表中。这种形状转换准备数据,以便 Flux 可以轻松地同时跨多个字段映射,以查看任何一个字段值或字段组合是否超过阈值。
例如,如果您想创建一个同时评估两个字段的检查,您可以 只需将上面 Flux 脚本中的 crit 函数更改为 crit = (r) =>r["usage_system"]> 5.0 and r["usage_user"] > 5.0。

重要提示:v1.fieldsAsCol() 函数是 schema.fieldsAsCols() 函数的已弃用版本。此问题 #1114 已被记录,要求 UI 生成的检查使用 schema.fieldsAsCols() 函数代替。
InfluxDB UI 中的死信检查
通过 InfluxDB UI 创建死信检查几乎与创建阈值检查相同。但是,您必须在步骤 2) 配置检查 中的检查属性下指定死信信号的持续时间,而不是指定阈值。
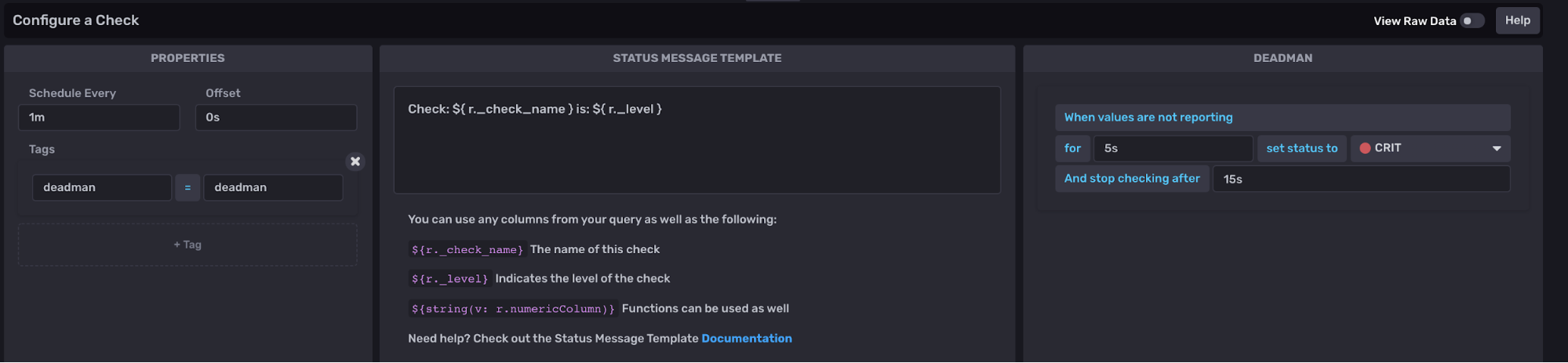
死信检查背后的 Flux
要查看为您的死信检查生成的相应 Flux 脚本,您可以使用 InfluxDB v2 API 或 UI。获取死信检查的相应 Flux 脚本的过程几乎与上面描述的阈值检查的过程相同。只需确保收集死信检查 ID 即可。生成的死信 Flux 脚本与阈值 Flux 脚本也非常相似。
package main
import "influxdata/influxdb/monitor"
import "experimental"
import "influxdata/influxdb/v1"
data = from(bucket: "telegraf")
|> range(start: -15s)
|> filter(fn: (r) => (r["_measurement"] == "cpu"))
|> filter(fn: (r) => (r["_field"] == "usage_system"))
|> filter(fn: (r) => (r["cpu"] == "cpu-total"))
option task = {name: "Deadman", every: 1m, offset: 0s}
check = { _check_id: "074bdadac4429000",
_check_name: "Deadman",
_type: "deadman",
tags: {deadman: "deadman"}}
crit = (r) => (r["dead"])
messageFn = (r) => ( "Check: ${r._check_name} is: ${r._level}")
data
|> v1["fieldsAsCols"]()
|> monitor["deadman"](t: experimental["subDuration"](from: now(), d: 5s))
|> monitor["check"](data: check, messageFn: messageFn, crit:crit)}死信 Flux 脚本中唯一与阈值 Flux 脚本显着不同的行是倒数第二行。monitor.deadman() 函数检测组何时停止报告数据。它接受一个表流,并报告自时间 t 以来是否已观察到数据。experimental.subDuration() 嵌套在 monitor.deadman() 函数中,以从当前时间值中减去持续时间,并评估信号是否已死信指定时间范围。
创建自定义检查
InfluxDB UI 使创建简单的死信和阈值检查非常容易,但它未能突出 InfluxDB 中检查系统的复杂性。Flux 允许您以几乎任何您认为合适的方式转换您的数据并定义自定义条件。编写自定义检查使您能够将任何 Flux 转换和自定义条件合并到您的检查中。创建自定义检查的步骤与 UI 中的检查创建步骤类似。首先,查询您的数据并将该查询分配给一个变量。将变量分配给您的初始查询不是必需的,只是建议这样做。接下来,实现检查的级别。如上节 阈值检查背后的 Flux 中所述,您可以通过更改级别的函数定义来分配自定义条件:crit = (r) => r["usage_system"] > 5.0 and r["usage_user"] > 5.0。
接下来,使用 monitor.check() 函数分配级别并将状态写入 “_monitoring”。您只能使用 monitor.check() 函数为您的时间序列数据分配 “CRIT”、“WARN”、“INFO” 和 “OK” 级别。我们建议使用默认级别作为您可能拥有的任何自定义级别的占位符。您可以在消息函数中包含有关默认级别如何与您的实际级别相关的其他信息。例如,假设您想根据电池数据的斜率来确定电池是否正在充电 (“CH”) 或放电 (“DH”)。您可以决定将 “CH” 的自定义级别与 “OK” 关联,将 “DH” 的自定义级别与 “CRIT” 关联,并在您的状态消息中包含该关联,以提高清晰度和组织性。在这种情况下,自定义检查可能如下所示
solarBatteryData = from(bucket: "solar")
|> range(start: -task.every)
|> filter(fn: (r) => r["_measurement"] == "battery")
|> filter(fn: (r) => r["_field"] == "kWh")
|> derivative(unit: 3s, nonNegative: false, columns: ["_value"], timeColumn: "_time")
option task = {name: "CPU Check", every: 5s, offset: 0s}
check = {_check_id: "0000000000000001", //alphanumeric, 16 characters
_check_name: "CPU Check",
_type: "threshold",
tags: {},}
ok = (r) =>r["_value"] > 0.0
crit = (r) =>r["_value"] =< 0.0
messageFn = (r) => ("Check: ${r._check_name} is: ${if r._level == "crit" then "DH" else "CH"}")
solarBatteryData
|> v1["fieldsAsCols"]()
|> monitor["check"](data: check, messageFn: messageFn, crit: crit, ok:ok)通常认为最佳实践是将所有状态合并到同一个 “_monitoring” 存储桶中,以降低基数并通过使用 monitor.check() 函数来保持数据的组织性。从技术上讲,您可以使用 Flux 通过使用 map() 函数编写自定义状态和 “CRIT”、“WARN”、“OK” 和 “INFO” 以外的自定义级别。但是,我们强烈警告 不要 这样做,因为您需要合并大量模式转换,以便您的输出与 “_monitoring” 存储桶的输出匹配。此外,监控包中的许多有用函数都需要状态中默认的 “CRIT”、“WARN”、“INFO” 和 “OK” 级别才能正常工作。如果您需要为检查定义超过 4 个自定义级别,我们建议进行多次检查并实施有用的检查命名、自定义标签和消息。
InfluxDB 检查的常见问题
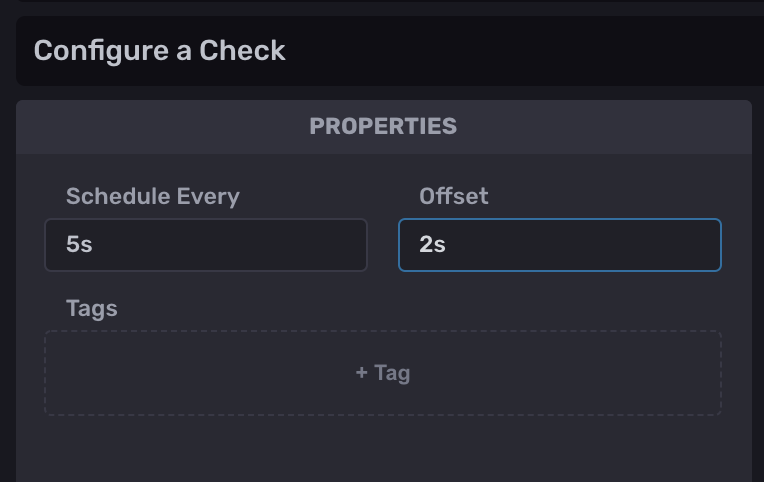
通常,用户会创建一个检查,却注意到状态没有写入 “_monitoring” 存储桶。他们还注意到,即使底层任务正在成功运行,检查也无法写入状态。此行为很可能是由读/写冲突引起的。这个障碍可能是 InfluxDB 检查(和通知)最常见的陷阱,但解决方案很简单。向您的检查添加偏移量很可能会解决此读/写冲突。
关于 InfluxDB 检查的结论
如果读者应该从本文档中获得一个重要的信息,那就是所有的检查、通知规则和任务都只是在计划中执行的 Flux。如果您担心检查和任务之间的性能问题,请不要担心。检查本质上只是一个任务。
与任何数据分析问题一样,我建议您熟悉 Flux 的功能并充分利用它们。使用 UI 帮助您学习 Flux、编写任务并验证您的任务是否按预期运行。然后使用 API 来执行、调试和维护这些任务,以满足您的监控或 IoT 应用程序开发需求。《InfluxDB 运维监控模板》是任务调试的绝佳工具。
状态
状态是一种时间序列数据,其中包含检查的结果。状态在检查成功运行后写入“_monitoring”存储桶。正如前面在阈值检查和创建自定义检查部分所述,状态包含来自源存储桶的数据以及有关检查结果的信息。状态的模式如下:
_time:检查执行的时间。_check_id:每个检查都分配有一个检查 ID。检查 ID 可用于调试和重新运行失败的检查 — 标签。_check_name:您的检查的名称(例如“CPU 检查”)- 标签。_level:UI 检查的“CRIT”、“WARN”、“OK”或“INFO”(或可为自定义检查配置)- 标签_source_measurement:您的源数据的 measurement(例如“cpu”)- 标签。_measurement:状态数据的 measurement(“status”)- measurement。_type:检查的类型(例如“threshold”)- 标签。_field:字段键。_message:状态消息。_source_timestamp:正在检查的源字段的时间戳,精度为纳秒${您的源字段}:正在检查的源字段。dead:特定于死信检查的附加字段。一个布尔值,表示死信信号是否满足死信检查条件。
- 在检查配置期间添加到查询输出的自定义标签。
- 查询中包含的任何其他标签,由
v1.fieldsAsCols函数产生。要查看所有这些标签,只需将鼠标悬停在数据浏览器中查询中的某个点上。
在 InfluxDB UI 中查看状态
在 InfluxDB UI 中,可以通过两个位置查看状态:通过警报页面和通过数据浏览器。要通过警报页面查看状态,请单击检查面板中眼睛图标下的查看历史记录。
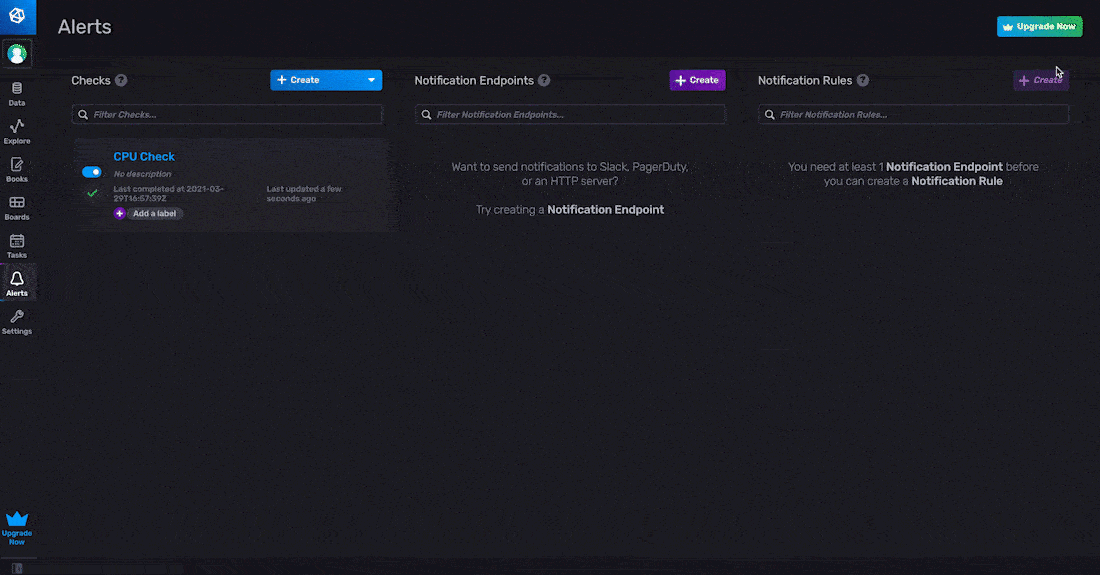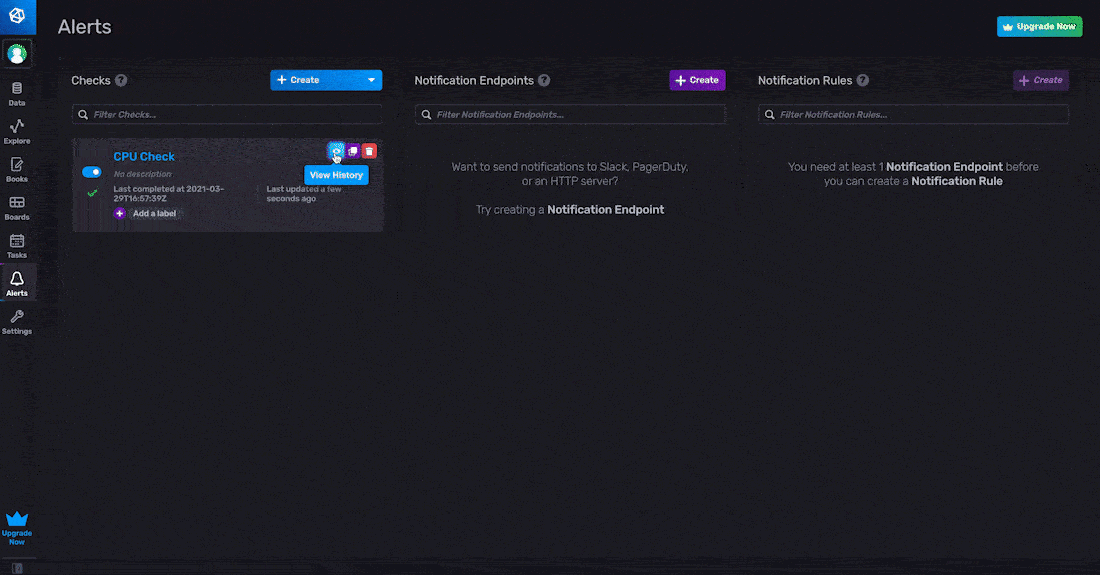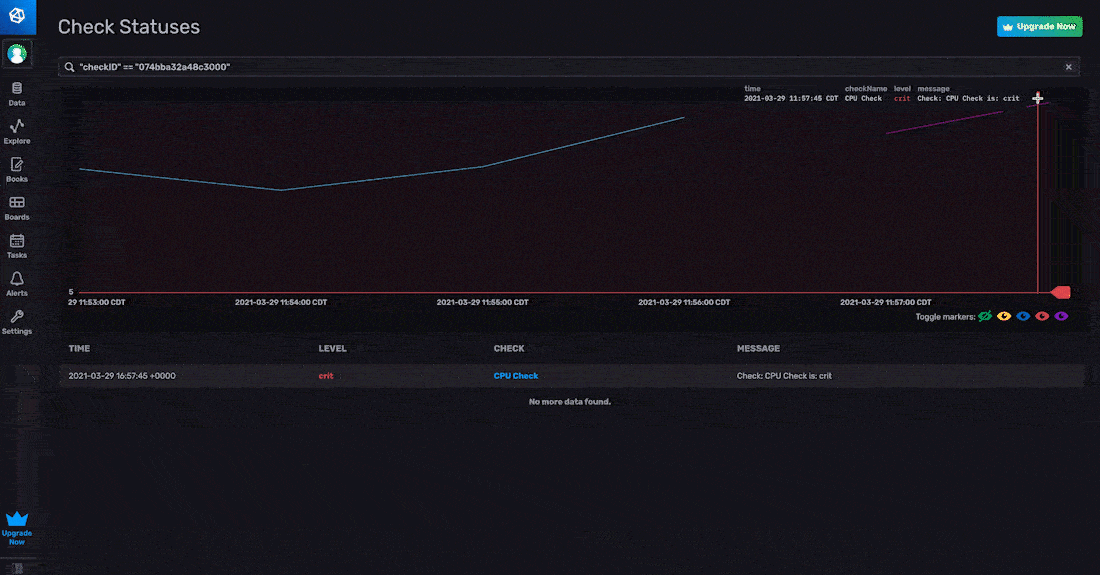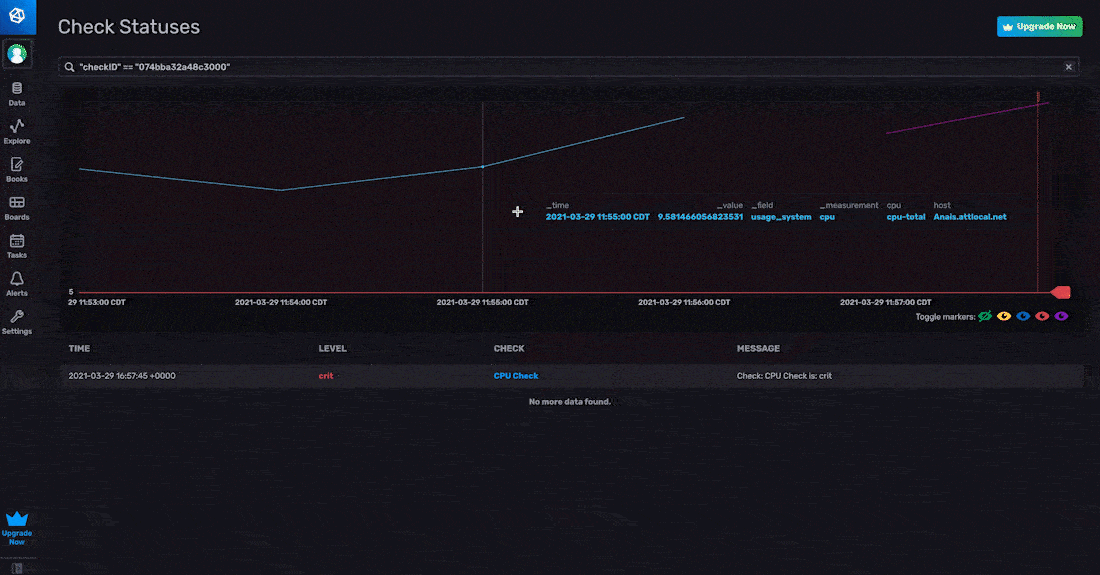
要通过数据浏览器查看状态,请从“_monitoring”存储桶中选择数据。数据浏览器会自动将 aggregateWindow() 函数应用于您的时间序列数据。状态包括状态消息字段,其中包含字符串值。因此,您可能会遇到以下错误消息:
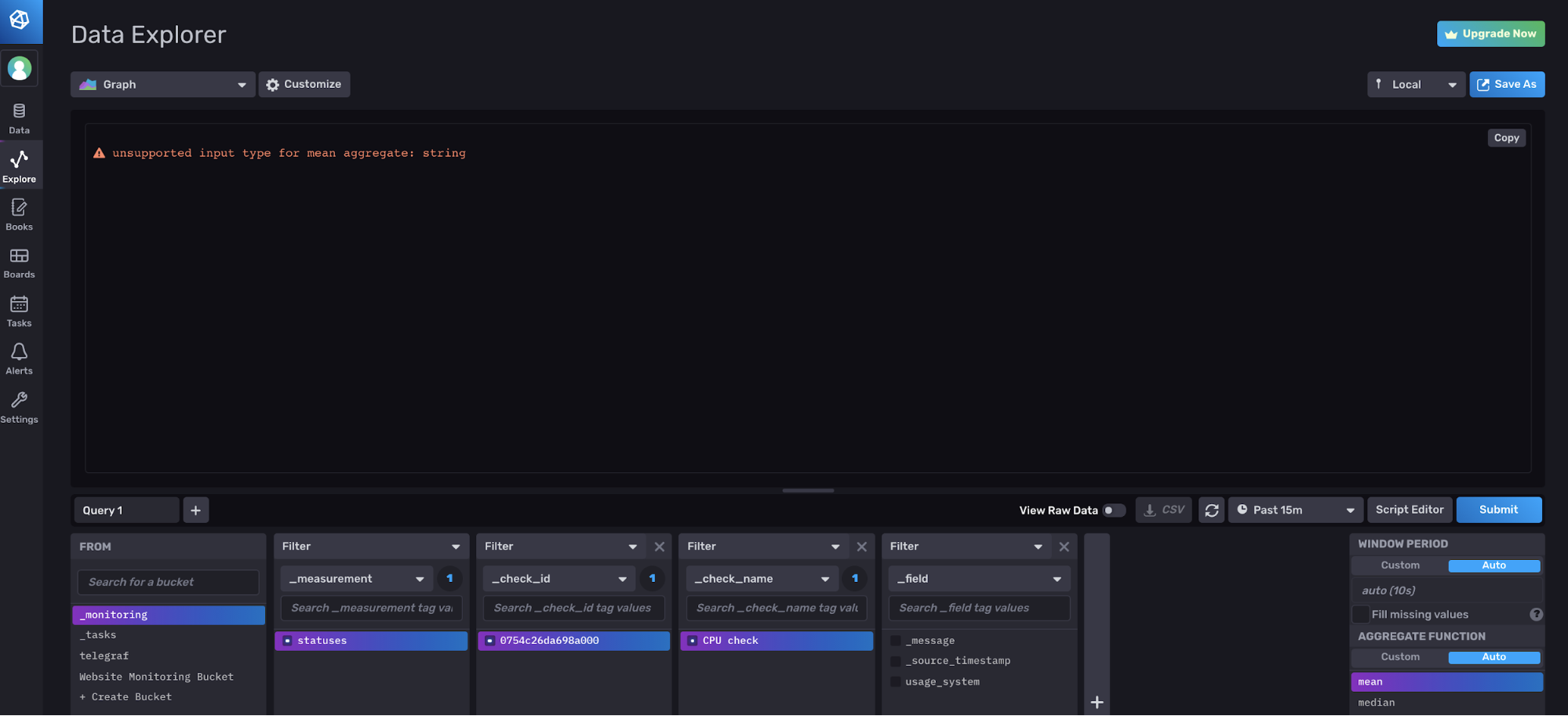
如果出现这种情况,并且您尚未过滤掉字符串字段,请导航到脚本编辑器并注释掉 (? + /) 或删除 aggregationWindow() 函数。
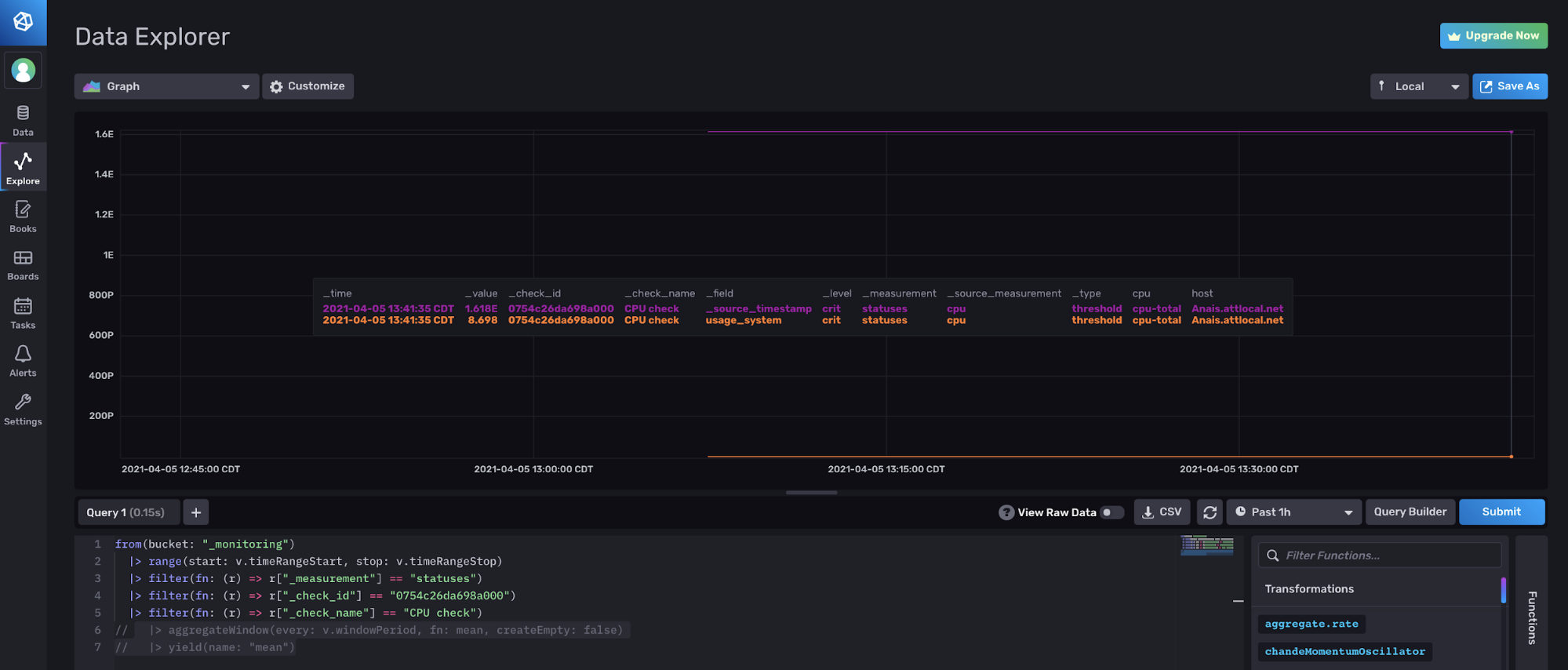
注释掉 aggregateWindow() 函数可让您在 InfluxDB UI 中可视化您的状态。
在任务和检查之间取得平衡
在文档的这一点上,希望您认识到检查本质上只是一个任务,而且检查已在 InfluxDB API 中被隔离。您可能还会想知道为什么在 UI 中查找底层任务很麻烦,以及为什么存在这种模糊性。做出此决定的目的是尝试鼓励用户在单独的任务中执行转换工作,并阻止他们将转换和分析工作塞入检查中。换句话说,尽量保持您的自定义任务简单。
例如,假设您想对来自不同 measurement 的两个字段之间的差异创建阈值检查。最佳实践是首先创建一个任务,该任务使用 join() 连接来自两个 measurement 的字段,使用 map() 计算它们之间的差异,并使用 to() 函数将输出写入新的 measurement 或存储桶。然后创建一个简单的阈值检查来查询新数据。在单独的任务中隔离数据处理工作可以提高您对系统的可见性,并降低检查的复杂性。
最后,如果此处提到的方法让您担心增加 InfluxDB 的写入和基数,您可以始终将任务的输出写入具有较小保留策略的存储桶。特别是如果您在检查中使用该数据,则可以将保留策略减少到 Schedule Every 间隔的 2 或 3 倍。此设计建议也适用于下面讨论的通知规则。
InfluxDB 中的通知规则
InfluxDB 中的通知规则是一种任务类型,类似于检查。通知规则从“_monitoring”存储桶查询检查的状态,将通知规则应用于状态,将通知记录到“_monitoring”存储桶,并将通知消息发送到通知端点。通知是一种时间序列数据类型。与状态一样,通知也写入“_monitoring”存储桶,并且是 Flux 任务的输出。状态是检查的输出,而通知是通知规则的输出。通知端点是通知规则中的元数据,它使通知消息能够发送到 HTTP、Slack 或 PagerDuty 等第三方服务。总而言之,将通知规则视为与警报同义可能很有帮助。但是,在 InfluxDB API 和 InfluxDB UI 中,这些任务被称为通知规则。
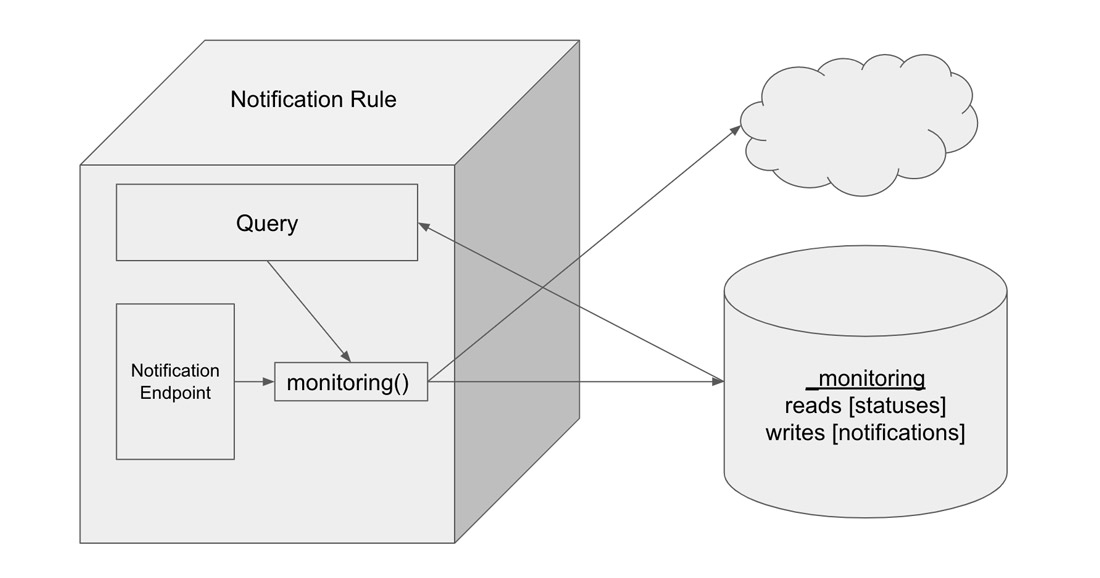
有两种创建通知规则的方法。您可以通过 UI 创建通知规则,也可以使用 Flux 编写自定义通知规则。在开始探索使用 InfluxDB 制作通知规则的多种方法之前,重要的是要认识到 InfluxDB UI 使用 InfluxDB v2 API,并且所有通知规则都用 Flux 编写。因此,通过 UI 生成的通知规则与自定义通知规则的性能相同。InfluxDB 和 Flux 的强大之处在于 - 开发人员真正有能力根据自己的意愿自定义其时间序列工作负载。
InfluxDB UI 中的通知端点
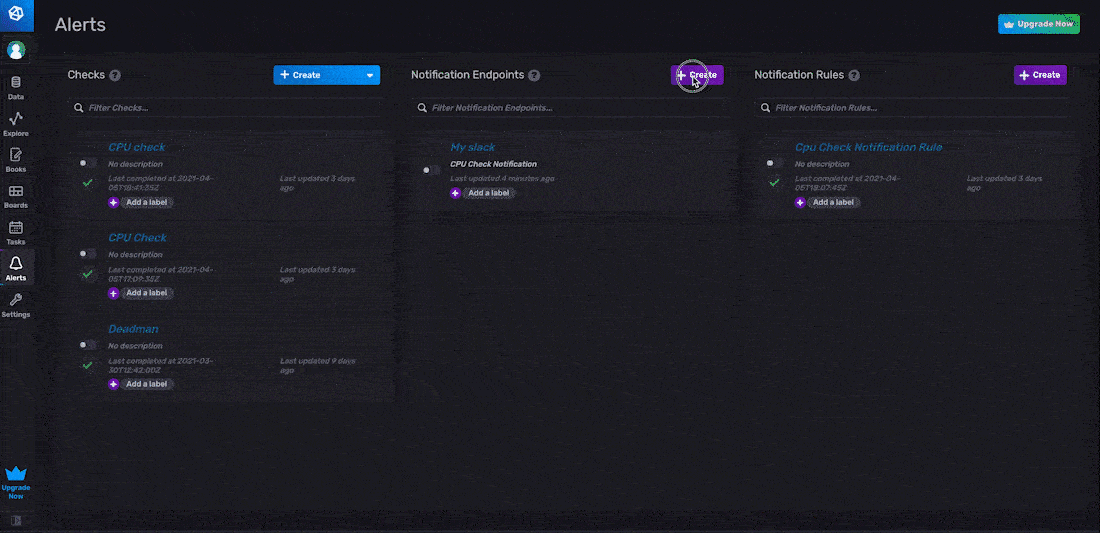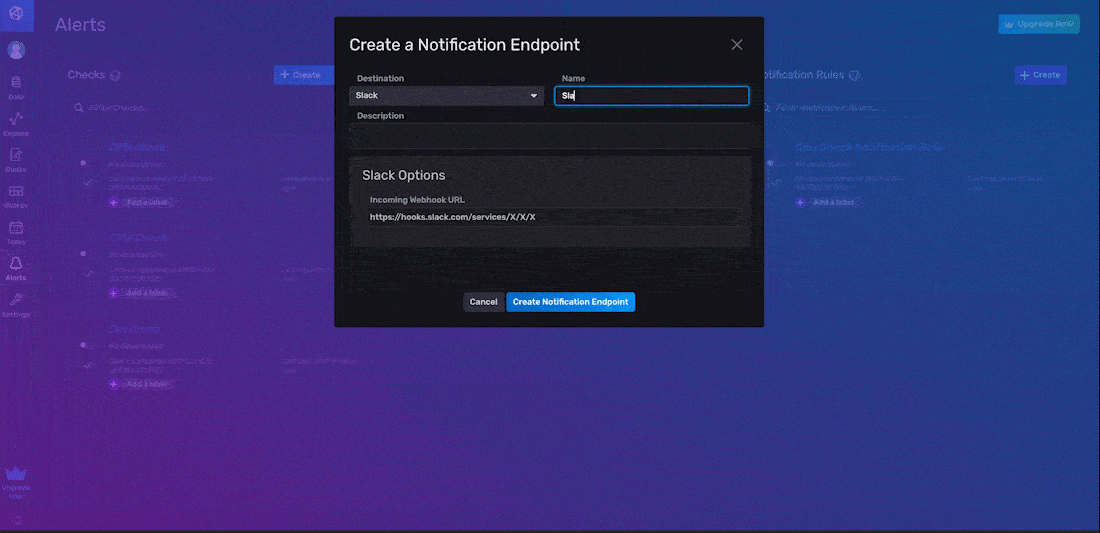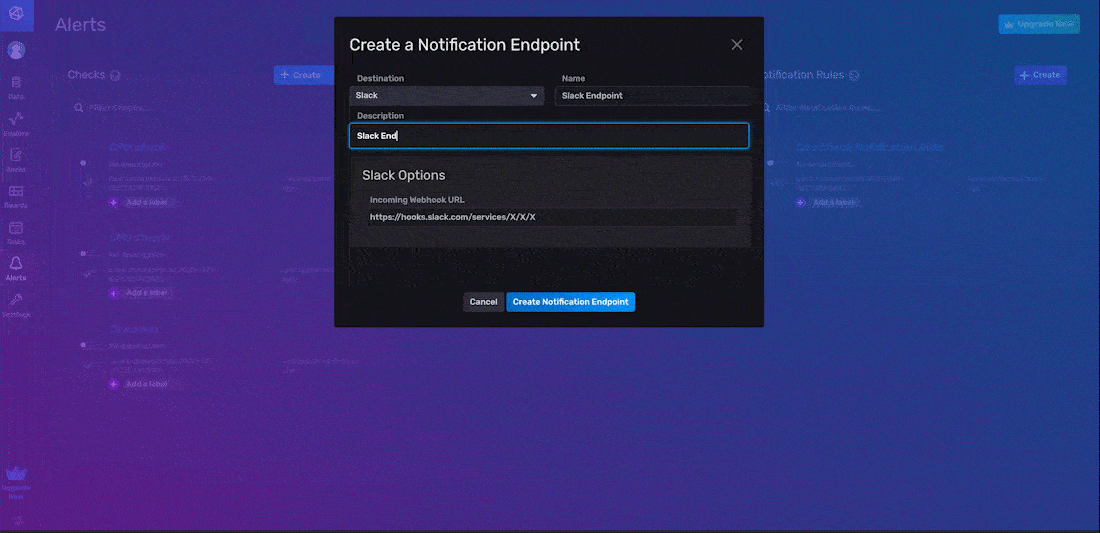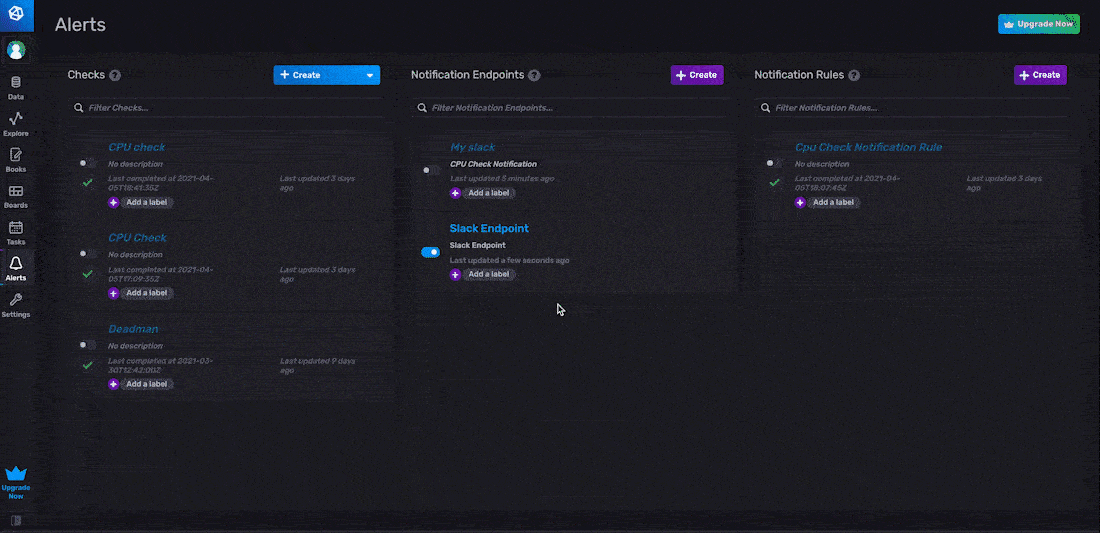
在 InfluxDB UI 中创建通知规则的第一步是配置通知端点。通知端点是您要将通知消息发送到的第三方服务。为通知规则配置通知端点的最简单方法是通过 InfluxDB UI。要创建通知端点,请从右侧导航菜单导航到 UI 中的警报页面,然后单击 + 创建。通过 UI 创建通知端点有两个步骤:
- 指定您的目标
- 指定选项
您可以通过 InfluxDB UI 配置 HTTP、Slack 和 PagerDuty 端点。在下面的示例中,我们创建了一个 Slack 通知端点,我们将其命名为“Slack 端点”。
InfluxDB UI 中的通知规则
在 InfluxDB UI 中创建通知规则的第二步是配置通知规则条件。这些用户定义的条件描述了哪些状态应转换为通知,以及哪些通知消息应发送到通知端点。
配置通知规则条件和创建通知规则的最简单方法是通过 InfluxDB UI。要创建通知规则,请从右侧导航菜单导航到 UI 中的警报页面,然后单击 + 创建。通过 UI 创建通知端点有三个步骤:
- 包含关于信息。
- 指定通知规则条件。
- 配置通知消息选项。
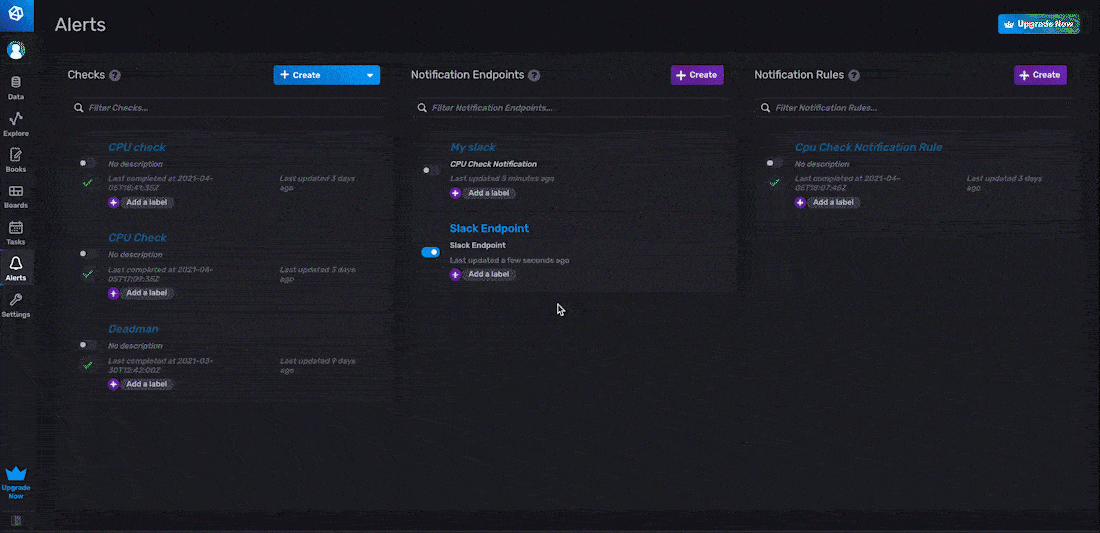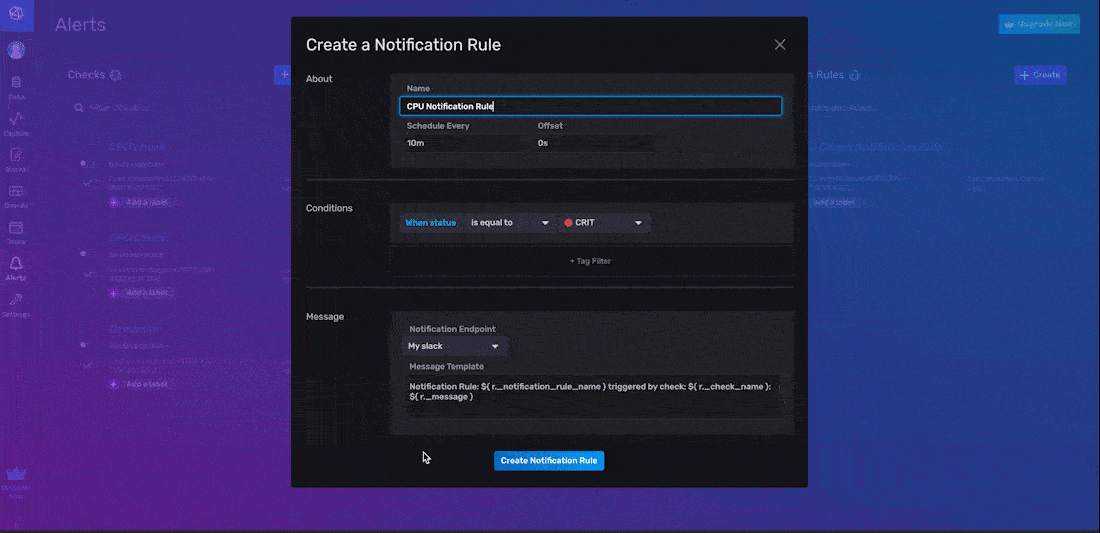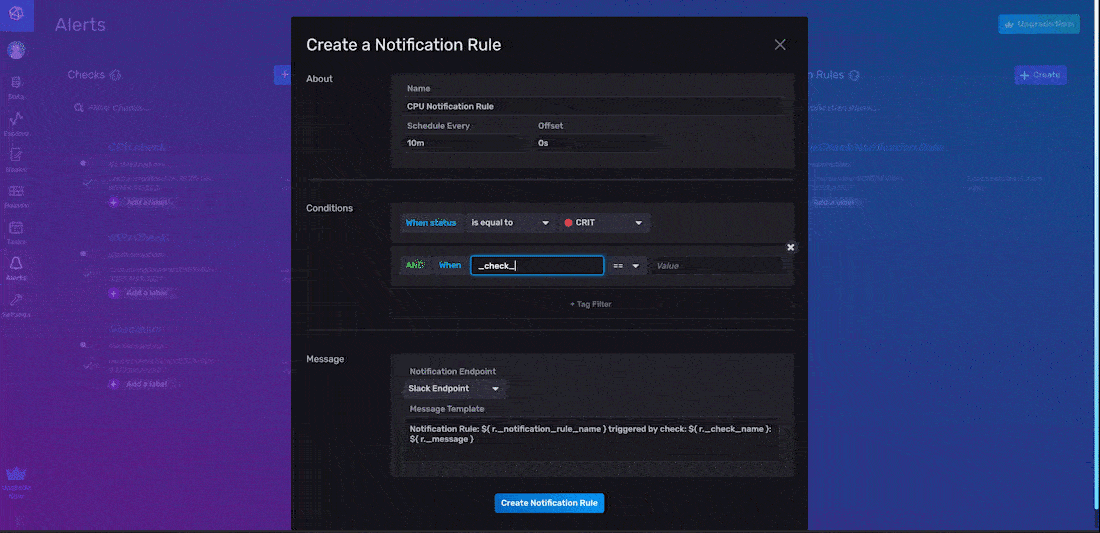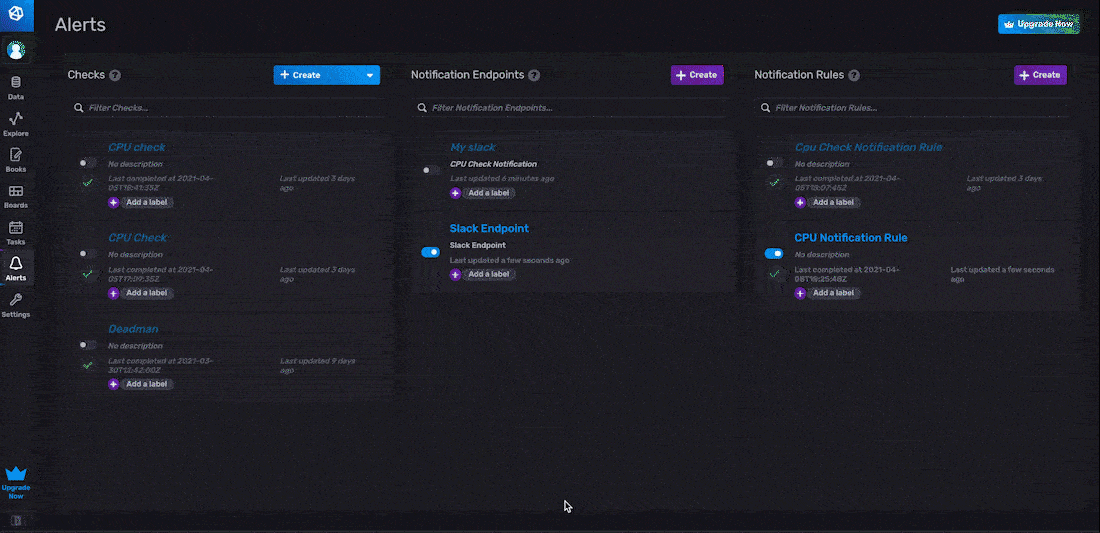
作为关于信息配置的一部分,您必须命名您的通知规则,指定 Schedule Every 间隔,并指定 Offset 间隔。在上面的示例中,我们将我们的通知规则命名为“CPU 通知规则”,并将 Schedule Every 间隔设置为 10 分钟。对于通知条件,您必须定义要为其创建通知并发送通知消息的状态类型。在上面的示例中,我们仅在状态级别等于“CRIT”时创建通知。我们还为此通知规则添加了一个标签;该标签将此通知规则的范围限定为单个检查 - “CPU 检查”。此标签是可选的。如果未添加,则我们的通知规则将为每个“_level”为“CRIT”的状态发送警报。
最后,指定通知消息选项,包括我们要将通知消息发送到的通知端点以及您希望消息读取的内容。我们选择刚刚创建的通知端点“Slack 端点”。默认通知消息如下所示:
Notification Rule: ${ r._notification_rule_name } triggered by check: ${ r._check_name }: ${ r._message }但是,您可以选择包含通知消息中任何列的信息,这些列包含在“_monitoring”存储桶中通知规则的输出中。通知的模式在下面的“通知”部分中描述。
通知规则背后的 Flux
要查看生成的相应 Flux 脚本,您可以使用 InfluxDB v2 API 或 UI。要查看 UI 生成的通知规则的相应 Flux 脚本,请按照阈值检查背后的 Flux 部分下的说明进行操作,因为过程是相同的。
要使用 InfluxDB v2 API 获取 UI 生成的通知规则的相应 Flux 脚本,请使用通知规则 ID 提交带有您的令牌作为授权参数的 GET 请求。这是一个 cURL 请求示例:
curl -X GET \
https://us-west-2-1.aws.cloud2.influxdata.com/api/v2/notificationRules/075...my_cnotification_rule_id...000/query \
-H 'authorization: Token Oxxx
.my_token...xxxBg==' \获取通知规则 ID 的一种快速方法是在 UI 中编辑通知规则时查看 URL。
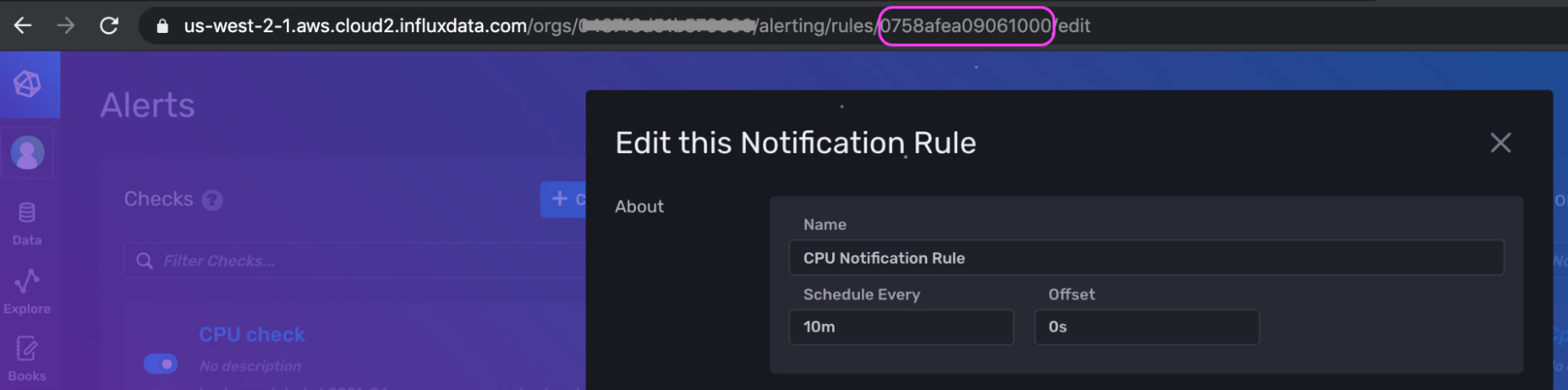
这是请求的相应数据部分,其中包含通过 UI 为上面的示例生成的通知规则的 Flux(原始 JSON 输出已转义并已清理以便于阅读):
package main
//CPU Notification Rule
import "influxdata/influxdb/monitor"
import "slack"
import "influxdata/influxdb/secrets"
import "experimental"
option task = {name: "CPU Notification Rule ",
every: 10m,
offset: 0s}
slack_endpoint = slack["endpoint"](url: "https:hooks.slack.com/services/xxx/xxx/xxx")
notification = {_notification_rule_id: "0758afea09061000",
_notification_rule_name: "CPU Notification Rule ",
_notification_endpoint_id: "0754bad181a5b000",
_notification_endpoint_name: "My slack",}
statuses = monitor["from"](start: -10s, fn: (r) = r["_check_name"] == "CPU Check")
crit = statuses
|> filter(fn: (r) => r["_level"] == "crit")
all_statuses = crit
|> filter(fn: (r) => (r["_time"] >= experimental["subDuration"](from: now(), d: 10m)))
all_statuses
|> monitor["notify"](data: notification,
endpoint: slack_endpoint(mapFn: (r) = (
{channel: "",
text: "Notification Rule: ${ r._notification_rule_name } triggered by check: ${ r._check_name }: ${ r._message }",
color: if r["_level"] == "crit" then "danger" else if r["_level"] == "warn" then "warning" else "good"})))我们可以看到 UI 中生成通知规则的步骤是如何由此相应的 Flux 脚本定义的。任务选项被分配给 option task 变量,其中包含有关通知规则的名称、Schedule Every 间隔和偏移间隔的信息。slack.endpoint() 函数用于配置 Slack 通知端点。Flux 中的每个通知端点包都包含一个消息和一个端点函数:
- message 函数向目标发送单个消息。
- endpoint 函数是一个工厂函数,它输出另一个函数。
输出函数需要一个 mapFn 参数。mapFn 然后构建用于生成 POST 请求的对象。虽然 message 函数可以将通知消息发送到您的目标,但 endpoint 函数还会将通知写入“_monitoring”存储桶,并将其他通知数据附加到您的通知中,特别是存储在 notification 变量中的数据。
我们要在其上创建通知的状态被分配给 statuses 变量。monitor.from() 函数检索存储在“_monitoring”存储桶中 statuses measurement 中的检查状态。我们的标签(将通知规则的范围限定为来自我们的检查“CPU 检查”的状态)在 monitor.from() 函数中应用。状态级别条件存储在 crit 变量中,该变量过滤 statuses 的输出,以查找级别为“CRIT”的状态。all_statuses 变量使用 experimental.subDuration() 函数来过滤在Schedule Every 间隔内写入的“CRIT”级别状态。最后,all_statuses 输出被馈送到 monitor.notify() 函数。此函数有两个必需参数:data 和 endpoint。data 参数包括您要附加到通知的其他信息。endpoint 参数指定构造和发送通知的函数,即 slack_endpoint。
创建自定义通知规则
InfluxDB UI 使创建简单的通知规则变得非常容易,但在突出显示 InfluxDB 中通知系统的复杂性方面,它有所不足。Flux 允许您以几乎任何您认为合适的方式转换您的数据。创建自定义通知规则的步骤与 UI 定义的步骤类似。相同的逻辑可以应用于创建您自己的自定义通知规则。虽然 UI 使您能够为 HTTP、Slack 和 PagerDuty 配置通知端点,但 Flux 有更多的通知端点包可供利用。

对于我们的自定义通知规则,我们将使用 Telegram Flux 包将通知发送到 Telegram 而不是 Slack。在编写自定义通知规则时,请确保导入正确的通知端点包,import "contrib/sranka/telegram"。然后配置 endpoint 函数。telegram.endpoint() 函数要求您指定您的 Telegram 机器人令牌。在此自定义通知规则中,我们将发送任何时候状态级别为“CRIT”或“WARN”的通知。此附加筛选分配给 critOrWarn 变量。最后,请确保包含 _notification_rule_id 和 _notification_endpoint_id。这些 ID 必须为 16 个字符长且为字母数字。
package main
//CPU Notification Rule for Telegram
import "influxdata/influxdb/monitor"
// import the correct package
import "contrib/sranka/telegram"
import "influxdata/influxdb/secrets"
import "experimental"
option task = {name: "CPU Notification Rule for Telegram ",
every: 10m,
offset: 0s}
telegram_endpoint = telegram["endpoint"](
url: "https://api.telegram.org/bot",
token: "S3crEtTel3gRamT0k3n",
)
notification = {_notification_rule_id: "0000000000000002", //alphanumeric, 16 characters
_notification_rule_name: "CPU Notification Rule for Telegram",
_notification_endpoint_id: "0000000000000002", //alphanumeric, 16 characters
_notification_endpoint_name: "My slack",}
statuses = monitor["from"](start: -10s, fn: (r) = r["_check_name"] == "CPU Check")
critOrWarn = statuses
|> filter(fn: (r) => r["_level"] == "crit" or r["_level"] == "warn") //altered to include two levels
all_statuses = critOrWarn
|> filter(fn: (r) => (r["_time"] >= experimental["subDuration"](from: now(), d: 10m)))
all_statuses
|> monitor["notify"](data: not
ification, endpoint: slack_endpoint(mapFn: (r) = ( {channel: “”, text: “Notification Rule: ${ r._notification_rule_name } triggered by check: ${ r._check_name }: ${ r._message }”, color: if r[“_level”] == “crit” then “danger” else if r[“_level”] == “warn” then “warning” else “good”})))</code></pre> 最后,请记住,您还可以使用其他 Flux 函数来进一步自定义您的通知规则和 监控状态
- stateDuration():允许您确定状态持续多长时间。
- stateCount():允许您计算连续状态的数量。
此外,《Flux InfluxDB 监控包》不仅包含 monitor.notify() 和 monitor.from() 函数。使用以下函数为您的自定义通知规则添加更多复杂性:
- monitor.stateChanges():允许您检测“_level”列中从一个级别到另一个特定级别的更改。
- monitor.stateChangesOnly():允许您检测“_level”列中从任何级别到任何其他级别的所有更改。
通知
通知是作为通知规则输出的时间序列数据。认识到状态和通知之间的相似之处很有帮助。状态之于检查,正如通知之于通知规则。因此,通知与状态非常相似,并包含以下模式:
_time:通知规则执行的时间。_check_id:每个检查都分配有一个检查 ID。检查 ID 可用于调试和重新运行失败的检查 - 标签。_check_name:您的检查的名称(例如“CPU 检查”)- 标签。_notification_rule_id:每个通知规则都分配有一个通知规则 ID。通知规则 ID 可用于调试和重新运行失败的通知规则 - 标签。_notification_rule_name:您的通知规则的名称(例如“CPU 检查通知规则”)- 标签。_notification_endpoint_id:每个通知端点都分配有一个通知端点 ID。通知端点 ID 可用于调试和重新运行失败的通知规则 - 标签。_source_measurement:您的源数据的 measurement(例如“cpu”)- 标签。_measurement:通知规则数据的 measurement(“notifications”)- measurement。_sent:一个布尔值,表示通知消息是否已发送到通知端点 - 标签_type:您的通知规则应用到的检查类型(例如“threshold”)- 标签。_level:相应检查的级别(例如“CRIT”)- 标签。_field:字段键。_message:通知消息。_status_timestamp:分配给您的源字段的状态的时间戳,精度为纳秒。_source_timestamp:正在检查的源字段的时间戳,精度为纳秒。${您的源字段}:正在检查的源字段值。
- 在通知配置期间添加到查询输出的自定义标签。
- 查询中包含的任何其他列,由来自相应检查的
v1.fieldsAsCols函数产生。
关于 InfluxDB 检查和通知系统的更多阅读资料和资源
虽然本文旨在全面概述 InfluxDB 中检查和通知系统的功能,但以下资源可能也让您感兴趣:
- TL;DR InfluxDB 技术技巧 - 监控任务和查找失控基数的来源:这篇文章描述了应用运维监控模板的优势。此模板可以帮助您确保您的任务成功运行。例如,假设您已将自定义标签作为 UI 生成的检查的一部分包含在内,并且这些标签包含在您的状态消息中。如果负责添加这些标签的底层任务失败,则您的检查将失败。应用运维监控模板可以帮助您发现自定义任务或检查失败的根本原因。
- TL;DR InfluxDB 技术技巧 - 使用任务和检查进行 InfluxDB 监控:这篇文章更详细地描述了创建 UI 生成的检查的基础知识及其局限性,以防您需要它。
- TL;DR InfluxDB 技术技巧 - 如何使用 InfluxDB 监控状态:这篇文章描述了 Flux InfluxDB 监控包 的一些复杂性和功能 - 对于任何希望使用 InfluxDB 执行有意义的任务的开发人员来说,这是一个必要的工具。
- TL;DR InfluxDB 技术技巧:使用 InfluxDB 配置 Slack 通知:这篇文章演示了如何通过 UI 创建 Slack 通知。具体来说,是如何启用 Slack 集成并收集 Slack Webhook URL。
- 自定义检查:文档中的另一个自定义检查示例。使用此自定义检查作为模板,帮助您使用 Flux 制作自定义检查。
- Telegram Flux 包:本教程演示了如何设置 Telegram 机器人并使用 Telegram Flux 包创建自定义通知规则。
- 贡献第三方 Flux 包:Discord 端点 Flux 函数:这篇文章描述了如何贡献您自己的第三方 Flux 包。具体来说,它描述了如何贡献 Discord 端点包。如果您需要的 Flux 通知端点包不可用,请考虑自己贡献一个!
关于 InfluxDB 检查和通知系统的结论
InfluxDB 的检查和通知系统是高度可定制的,使用户能够对其时间序列数据采取行动。所有检查和通知本质上都是 Flux 任务。检查和通知与其他任务之间的主要区别在于,检查和通知会从“_monitoring”存储桶读取数据并向其写入数据。它们还使用专门的 Flux 包,如 Flux InfluxDB 监控包和通知端点包。
我希望这篇文章能够启发您利用 InfluxDB 检查和通知系统,并构建您自己的自定义检查和通知。在评论区、我们的社区站点或我们的 Slack 频道中分享您的想法、疑虑或问题。我们很乐意获得您的反馈并帮助您解决遇到的任何问题!与往常一样,我们鼓励您分享您的故事,并告诉我们您正在使用 InfluxDB 或在其之上开发的酷项目。
