InfluxDB 在时间序列数据和指标基准测试中超越 Cassandra
作者:Chris Churilo / 产品, 用例
2022 年 10 月 20 日
导航至
此博客文章已于 2022 年 10 月 20 日更新,包含 InfluxDB 1.8.10 和 Cassandra v4.0.5 的最新基准测试结果。为了向您提供最新的发现,此博客会定期更新最新的基准数据。
在 InfluxData,我们经常被开发者和架构师问到的一个常见问题是:“对于时间序列工作负载,InfluxDB 与 Cassandra 相比如何?” 提出这个问题可能有几个原因。首先,如果他们正在启动一个全新的项目并进行尽职调查,对几个解决方案进行正面比较,这有助于创建他们的比较网格。其次,他们可能已经在现有应用程序中使用 Cassandra 摄取数据,但现在想看看如何将指标收集集成到他们的系统中,并认为可能有一个比 Cassandra 更好的解决方案来完成这项任务。
在过去的几周里,我们着手比较 InfluxDB 和 Cassandra 在常见时间序列工作负载方面的性能和功能,特别是关注数据摄取率、磁盘数据压缩和查询性能。 InfluxDB 在所有三项测试中都优于 Cassandra,写入吞吐量高出 5 倍,同时磁盘空间减少 2.4 倍,并且测试查询的响应时间最多快 100 倍。
在我们深入研究基准测试的细节之前,重要的是要指出,如果不首先编写大量的应用程序代码来弥补 Cassandra 缺少的功能,就无法对 InfluxDB 和 Cassandra 进行时间序列工作负载的正面比较。实际上,您需要在自己的应用程序中重写 InfluxDB 的部分内容。为了将这些基准测试放在一起,我们不得不编写这些功能的一些基本版本,但生产应用程序将需要付出更多的努力。
要阅读基准测试和方法的完整详细信息,下载《InfluxDB 与 Cassandra 在时间序列数据、指标和管理方面的基准测试》技术论文,或观看录制的网络研讨会。
我们的首要目标是创建一个一致且最新的比较,以反映 InfluxDB 和 Cassandra 的最新发展,并在稍后涵盖其他数据库和时间序列解决方案。我们将定期重新运行这些基准测试,并使用我们的发现更新详细的技术论文。这些基准测试的所有代码都可以在 Github 上找到。如果您有任何问题、意见或建议,请随时在该存储库上打开 issue 或 pull request。
现在,让我们看一下结果…
测试版本
InfluxDB v1.8.10
InfluxDB 是用 Go 编写的开源时间序列数据库。其核心是名为 Time-Structured Merge (TSM) Tree 的定制存储引擎,该引擎针对时间序列数据进行了优化。 InfluxDB 由名为 InfluxQL 的自定义类 SQL 查询语言控制,为跨时间范围的数学和统计函数提供开箱即用支持,非常适合自定义监控和指标收集、实时分析以及物联网和传感器数据工作负载。
Cassandra v4.0.5
Cassandra 是一个用 Java 编写的分布式非关系数据库,最初由 Facebook 构建,并于 2008 年开源。它于 2010 年正式成为 Apache 基金会的一部分。它是一个通用平台,提供分区行存储,它同时提供键值和面向列的数据存储的功能。
虽然它为构建可扩展的分布式数据库提供了出色的工具,但 Cassandra 缺少时间序列数据库的大多数关键功能。因此,常见的模式是在 Cassandra 之上构建应用程序逻辑来处理缺少的功能。这就是我们将要做的,以帮助对 Cassandra 进行公平的时间序列工作负载评估。
关于基准测试
在构建具有代表性的基准测试套件时,我们确定了使用时间序列数据时最常评估的特征。我们查看了三个向量的性能
- 数据摄取性能 – 以每秒值数衡量
- 磁盘存储要求 – 以字节为单位衡量
- 平均查询响应时间 – 以毫秒为单位衡量
关于数据集
对于此基准测试,我们专注于模拟常见 DevOps 监控和指标用例的数据集,其中服务器集群定期以规则的时间间隔报告系统和应用程序指标。我们每 10 秒对 9 个子系统(CPU、内存、磁盘、磁盘 I/O、内核、网络、Redis、PostgreSQL 和 Nginx)中的 100 个值进行采样。对于关键比较,我们查看了代表 100 台服务器在 24 小时内的部署数据集,这代表了一个相对适中的部署。
- 服务器数量:100
- 每台服务器测量的数值:100
- 测量间隔:10 秒
- 数据集持续时间:24 小时
- 数据集中的总数值:每天 87,264,000 个
这只是整个基准测试套件的子集,但它是一个具有代表性的示例。如果您对更多细节感兴趣,可以在 GitHub 上阅读有关测试方法的更多信息。
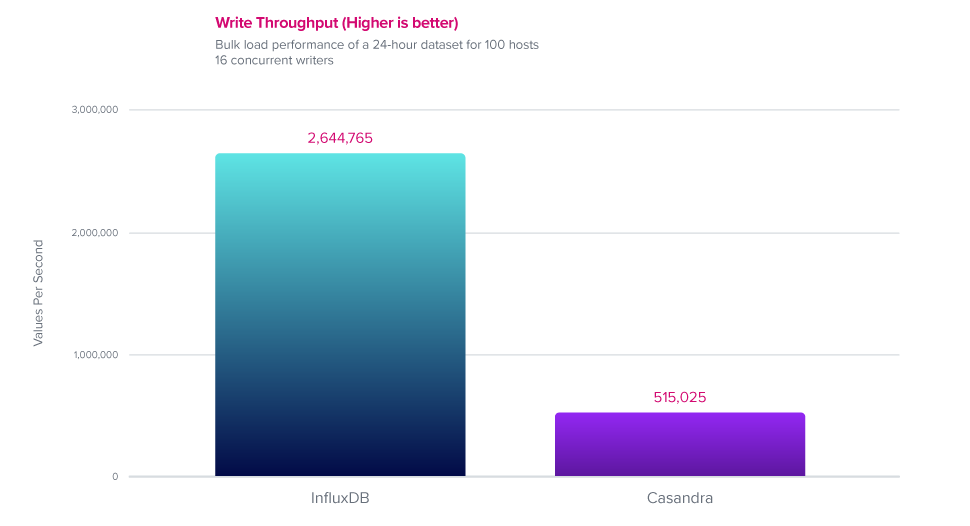
写入性能
在数据摄取方面,InfluxDB 的性能比 Cassandra 高出 5 倍。
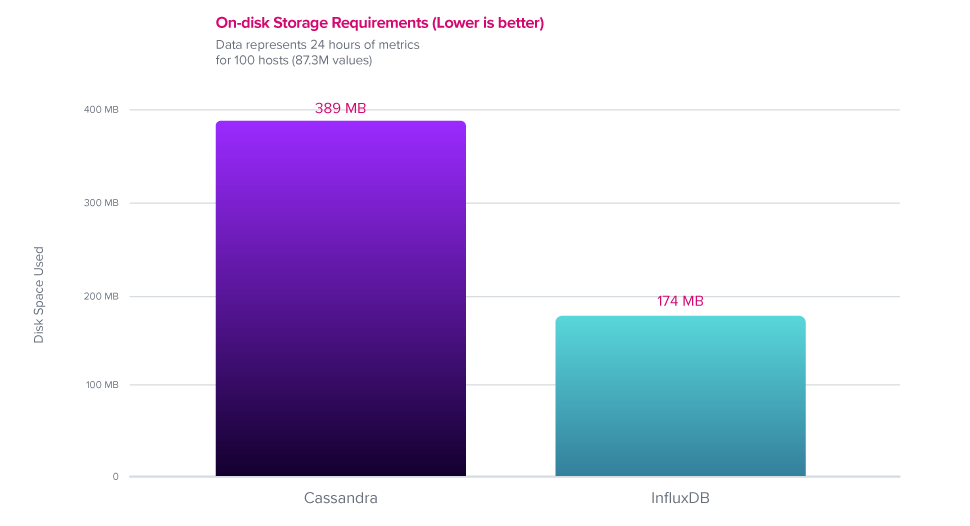
磁盘压缩
InfluxDB 实现了 2.4 倍更好的压缩率,性能优于 Cassandra。
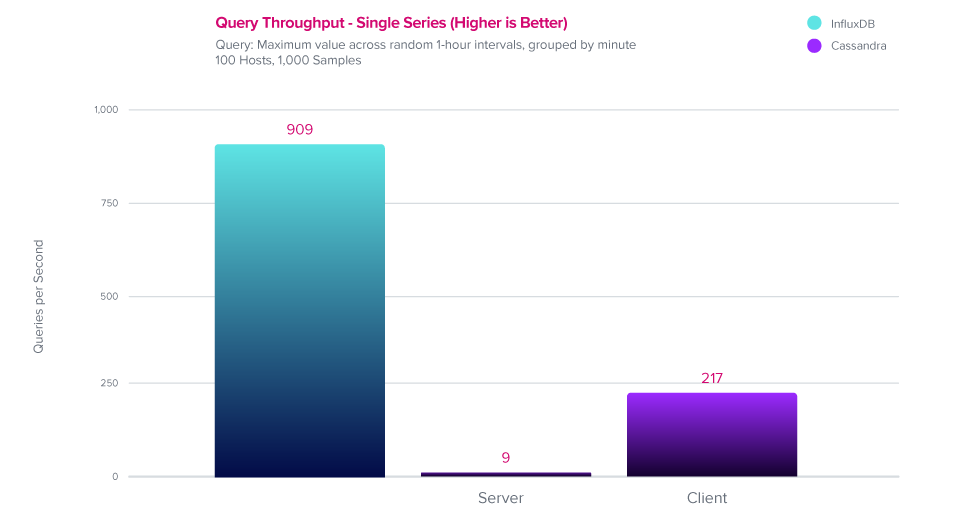
查询性能
InfluxDB 提供了高达 100 倍的查询性能,优于 Cassandra。
总结
最终,你们中的许多人可能不会感到惊讶,一个专门构建的时间序列数据库,旨在处理指标,会在这些类型的工作负载方面显著优于搜索数据库。 尤其突出的是,当工作负载需要时间查询灵活性时,就像实时分析和传感器数据系统的常见特征一样,像 InfluxDB 这样的专用时间序列数据库会带来很大的不同。
重要的是要强调,使用 Cassandra 实现最佳查询性能需要大量的额外应用程序级处理。这可能会对生产部署产生巨大影响,在生产部署中,每个查询都会给应用程序服务器带来额外的负载。
总之,我们强烈建议开发人员和架构师自行运行这些基准测试,以独立验证他们在选择的硬件和数据集上的结果。但是,对于那些正在寻找一个有效的起点,以确定哪种技术能够“开箱即用”地提供更好的时间序列数据摄取、压缩和查询性能的人来说,InfluxDB 在所有这些维度上都是明显的赢家,尤其是当数据集变得更大且系统运行时间更长时。
