InfluxDB 现在是 InfluxData,时序数据平台
作者:Paul Dix / 产品, 公司
2015 年 12 月 08 日
导航至
今天我们宣布,InfluxDB 公司现在更名为 InfluxData。这是一个长期愿景的开端:创建一个平台,用于开发依赖于时序数据的应用、服务和物联网架构。对我们而言,时序数据之所以重要,不仅仅因为它跟踪随时间变化的事物,更是因为跟踪这种变化正是为了解历史趋势、智能、洞察和预测。我们认为,开发者需要一个平台,使他们能够快速构建基于所有这些数据的全新创新应用。在这篇博客中,我们将概述我们为何认为时序数据如此重要;TICK 技术栈 (我们构建平台的堆栈);以及我们在 InfluxDB 数据库上的持续开发。
为什么是时序数据?为什么是现在?
第一波“大数据”浪潮代表了用户生成的活动和内容。但如今,世界上的传感器数量已经超过了人类的数量。传感器可以是基于软件的,例如那些跟踪应用程序、服务器、路由器或其他 IT 设备中发生的情况的传感器,也可以是物理传感器,用于测量手机、无人机、工厂设备、汽车、家用电器和无数其他设备中的数据。
所有这些传感器都在持续输出数据;通常每秒多次,而且全部都是时序数据。除了物理传感器之外,由 Docker、OpenStack 和其他容器/IaaS 技术驱动的瞬时数据量级增加才刚刚开始。
事件驱动型或传感器数据都可以理解为许多单独的时序。通过跟踪随时间的变化,我们可以查看历史趋势,深入了解当前正在发生的事情,实时检测异常,提供实时的运营可见性,并对未来做出预测。许多此类序列都是瞬时的,这对现有技术堆栈提出了特殊的挑战。
传感器革命才刚刚起步,它所创造的数据浪潮将使“大数据”相形见绌,如同池塘中的涟漪。我们正在为那个未来而构建。
时序数据的四大问题
我们构建平台的目标源于我们对时序数据工作者面临的四个关键问题的认识:采集、存储、可视化和处理。许多开发者都向我们寻求这些问题的解决方案。到目前为止,我们主要关注问题的存储部分。在这方面我们还有很多工作要做,稍后我会谈到这一点,但首先我想谈谈与时序相关的四个问题的每个部分以及 TICK 技术栈。
数据采集是这一切的起点。如何将数据从您的应用程序、服务器、传感器、路由器、工厂设备、电器或汽车传输到您可以存储、监控或使其可用于分析的地方?
对许多人来说,存储是显而易见的部分——您将采集的时序数据存储在哪里?在处理时序数据时,存储层中需要解决一些独特的问题。您可能拥有数十亿或数万亿个由任意元数据索引的单独数据点。通常,基于时间的数据和与其相关的元数据是瞬时的,这意味着您删除的数据量与写入的数据量一样多——这对数据库来说是一个特别困难的问题。
可视化完全是为了汇总数据,以帮助人们深入了解他们正在测量的任何因素。同时,数据处理完全是为了转换、监控以及通过算法从您的数据中获得洞察,这可以包括 ETL、警报和异常检测等内容。
我们发现,在开发者使用时序数据的几乎所有用例中都会出现这四个问题,包括 DevOps、实时分析、传感器数据、物联网、自动化、金融、商业智能以及许多其他领域。我们的目标是构建一个平台,帮助开发者在所有这些领域构建智能应用程序。这就是我们推出 TICK 技术栈的原因。
隆重推出 TICK 技术栈
在我们深入了解 TICK 技术栈的起源和特定组件之前,我应该解答你们许多人可能有的一个问题:当这些工具已经存在并且是开源的时候,为什么还要为采集、可视化和处理构建新工具?我们的努力是否应该仅仅集中在构建 InfluxDB 上?
构建其他工具的最重要原因是,我们在 InfluxDB 中的数据模型与任何现有工具都不完全匹配。我们从数据库底层重新思考了时序问题,这意味着我们需要新工具来与 InfluxDB 无缝集成并利用其架构。
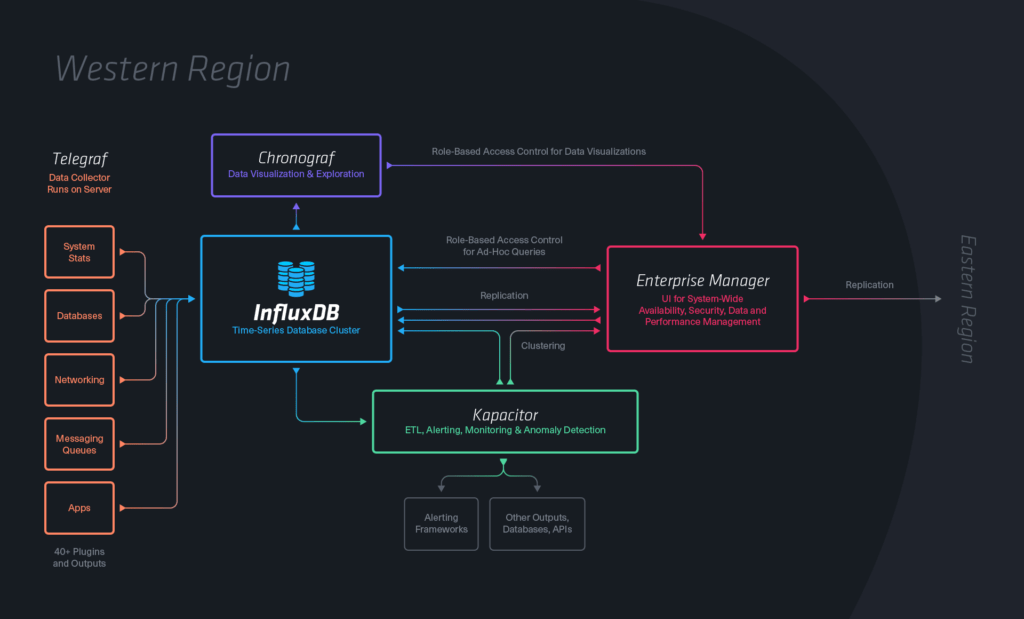
TICK 技术栈正是这样一组工具。它是一个首字母缩略词,代表 Telegraf、InfluxDB、Chronograf 和 Kapacitor。稍后我将介绍这些工具中的每一个,并链接到更详细的博客文章,但首先我想谈谈 TICK 名称的由来。

TICK 是金融术语“价格报价的最小变动单位”的缩写。
虽然 InfluxData 的公司总部位于旧金山,但 InfluxDB 诞生于纽约市,一个充满金融气息的地方。事实上,我第一次构建“时序数据库”是为一家位于纽约市中城的金融科技初创公司。除了与纽约市和金融业的明显联系之外,我们喜欢 tick 这个概念还有另一个更微妙的原因:tick 只有在时间变化的事物框架内才有意义。
对我们来说,这就是时序。不仅仅是随时间变化的事物,更是能够跟踪随时间的变化,这正是为了解被跟踪对象的整个历史过程中的智能和洞察。
我们知道我们必须构建四个不同的项目来解决我们在采集、存储、可视化和处理方面的每个关键领域。以 tick 为起点,我们已经有了 InfluxDB,因此我们决定选择其他工具的名称来与首字母缩略词 TICK 对齐。
Telegraf 是一款开源工具,用于从服务器、知名服务、第三方 API 以及未来从路由器、ARM 硬件上的传感器等采集数据。访问 Telegraf 页面 了解更多信息。
InfluxDB 是我们的开源分布式时序数据库,也是这一切的起点。在本文的下一节中,我将更深入地讨论我们关于 InfluxDB 的未来计划。
Chronograf 是我们免费使用的可视化工具,用于构建仪表板和对 InfluxDB 中的数据进行临时探索。我们还在努力开源 Chronograf 中的可视化组件,使构建自定义应用程序的开发者能够在几分钟内从无到有地在其应用程序中存储和可视化时序数据。访问 Chronograf 页面 了解更多信息。
最后,Kapacitor 是我们的开源工具,用于处理时序数据。它可以处理流数据或批处理数据,非常适合进行 ETL、监控、警报以及实时统计和排行榜。访问 Kapacitor 页面 了解更多信息。
 通过 TICK 技术栈,我们希望为开发者提供他们快速构建 DevOps、分析、传感器、物联网以及所有时序领域应用程序所需的所有工具。我们的驱动目标之一是最大限度地提高开发者的幸福感,我们相信当开发者能够快速构建他们梦想中的应用程序时,幸福感就会到来。
通过 TICK 技术栈,我们希望为开发者提供他们快速构建 DevOps、分析、传感器、物联网以及所有时序领域应用程序所需的所有工具。我们的驱动目标之一是最大限度地提高开发者的幸福感,我们相信当开发者能够快速构建他们梦想中的应用程序时,幸福感就会到来。
InfluxDB 的开发和近期目标
虽然这篇文章是关于我们更名为 InfluxData,但许多读者可能对 InfluxDB 的现状和我们的近期目标感兴趣。InfluxDB 的开发是公司内部的首要任务。
目前有数千名 InfluxDB 用户(包括较旧的 0.8.8 版本和较新的 0.9.x 版本)。然而,有些人正在场外等待我们在性能和集群方面的进展。对于已经启动并运行的用户,我们收到了关于我们所做工作的非常积极的反馈。
这就是我们在开放环境中开发所做的权衡——一些用户会立即获得价值,而另一些用户会对我们的进展或早期的重大更改感到失望。在开放环境中开发并愿意进行重大更改的优势在于,我们避免了局部最优。也就是说,InfluxDB 的后续版本将更加强大和通用,因为我们愿意尽早进行重大更改。我们已经实现了 4 个版本的 API 稳定性,并计划仅在即将发布的版本中进行增量更改。
我们相信迭代和持续改进是构建出色产品的关键。我们将努力在我们所做的工作中追求卓越,并且我们对用户负责。
在接下来的几个月中,我们在存储引擎、集群和整体稳定性方面对 InfluxDB 进行了重大改进。 InfluxDB 0.9.6 版本仅仅是一个开始,您可以立即开始使用 TSM 存储引擎进行测试,该引擎已专门针对时序数据进行了优化。有关更多详细信息,请参阅今天的 InfluxDB 0.9.6 版本发布公告。
不止 InfluxDB
现在我们是 InfluxData,我们不仅仅是一家时序数据库公司 InfluxDB。我们是一个全面的时序数据平台,使开发者能够构建很酷的东西。我们看到许多用户在解决采集、可视化和处理问题以及存储问题时遇到困难。InfluxData 是我们帮助开发者和用户解决所有四个领域问题的努力。
从更高的层面来看,我们对我们正在做的事情感到兴奋,因为我们正在帮助人们构建事物。正如一位顾问最近告诉我的那样,“您很高兴为构建酷炫事物的人们构建酷炫的事物。” 我们确实如此。
