十月产品月度更新 – InfluxDB 新引擎及更多!
作者 Bharat Bhat / 产品, 用例
2022年11月01日
导航至
我们热爱编写和发布代码,以帮助开发者将他们的想法和项目变为现实。因此,我们不断致力于根据开发者的需求改进我们的产品,以确保他们的满意度并加速实现精彩时刻。
本月非常特别。我们现在有了一个新引擎,它显著提高了 InfluxDB 的“马力和扭矩”。
我们还扩展了 Data Explorer UI,使您更轻松地将自定义数据保留应用于您的组织,并为 Arduino 平台添加了入门向导 – 当然还有错误修复。
1 - 新引擎 – 无限制基数、SQL 和实时分析
使用新存储引擎的 InfluxDB Cloud 客户的基数限制已完全解除。用户可以写入任何类型的事件数据,具有无限基数,并在任何维度上对数据进行切片和切块,而不会牺牲性能。这开启了事件、追踪和各种短暂的无限制基数数据等用例。
新引擎还带来了极速查询。与我们以前版本的 InfluxDB 相比,使用新引擎查询大量时间序列的速度要快几个数量级。查询 10 个序列或 100 万个序列都是一样的。这使得以您想要的方式执行实时分析成为现实。
新引擎原生支持 SQL,我们的云客户很快将能够使用与 Postgres 兼容的客户端(如 psql)、Grafana 的 Postgres 数据源以及 BI 工具(如 PowerBI 和 Tableau)进行连接。随着标准的成熟,我们还将推出 Apache Arrow FlightSQL,为用户提供对数百万行时间序列数据的高性能访问。
以下是其内部结构
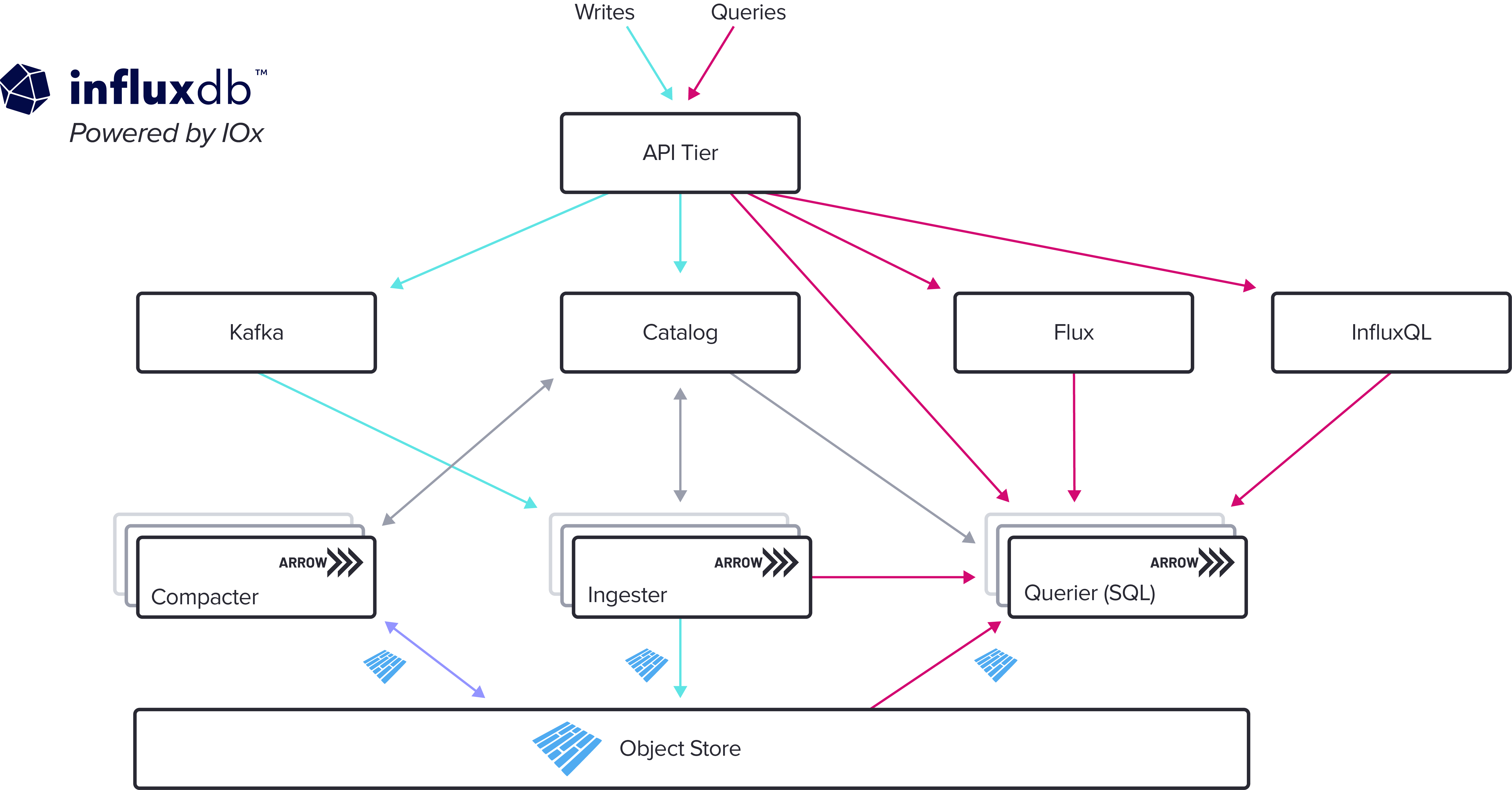
新存储引擎代表了一个先进的核心,我们计划在此基础上构建许多新功能。批量数据摄取、批量数据导出以及与其他第三方系统的集成都在近期计划中。我们还将基于这些新引擎功能推出专用云层和新的本地 Enterprise 产品。
要利用所有这些进步,请在此处注册。
2 - 十月份发布的其他主要功能
除了新引擎,我们还发布了与 Data Explorer、自定义数据保留和 Arduino 入门相关的主要新功能。请查看下面我的博客文章以获取更多信息。
-
Data Explorer - 原始数据模式在解析和显示方面得到了显著改进。您现在还能够同时搜索多个指标。
-
自定义数据保留 - 鉴于 InfluxDB 能够每秒处理数十万个数据点,您可能需要一种方法来管理不再有价值的过期数据。InfluxDB 提供保留策略,可自动执行过期旧数据的过程。
-
Arduino 入门 - 新的 Arduino 入门向导允许您在登录后的前 5 分钟内向 InfluxDB 写入数据并从 InfluxDB 查询数据。
3 - 错误修复
本月,我们修复了许多未解决的错误,以改善 InfluxDB 的用户体验
-
改进了渲染期间图表和单统计可视化效果的样式
-
现在可以从主页上的“有用链接”部分访问 InfluxDB University
-
解决了简单表格的表头渲染问题
-
防止了小数点自定义导致可视化崩溃
如果您有任何具体的设计或实施问题,请与我们联系。我们随时为您提供帮助。
