InfluxDB 在时间序列工作负载中比 MongoDB 快 5 倍
作者:Chris Churilo / 产品, 用例
2022 年 11 月 17 日
导航至
本博客文章已于 2022 年 11 月 17 日更新,包含 InfluxDB v1.8.10 和 MongoDB v5.0.6 的最新基准测试结果。为了向您提供最新发现,本博客会定期更新最新的基准测试数据。
在 InfluxData,近几个月来,开发者和架构师经常向我们提出的一个常见问题是:“对于时间序列工作负载,InfluxDB 与 MongoDB 相比如何?” 提出这个问题可能有几个原因。首先,如果他们正在启动一个全新的项目,并且正在尽职调查地对几个解决方案进行正面比较,那么这有助于创建他们的比较表格。其次,他们可能已经在现有应用程序中使用 MongoDB 来摄取数据,但现在想了解如何将指标收集集成到他们的系统中,并认为可能存在比 MongoDB 更好的解决方案来完成这项任务。
在过去几周,我们着手比较 InfluxDB 和 MongoDB 在常见时间序列工作负载中的性能和功能,特别是关注数据摄取率、磁盘数据压缩和查询性能。 InfluxDB 在所有三项测试中均优于 MongoDB,**写入吞吐量提高了 1.9 倍**,同时**磁盘空间减少了 7.3 倍**,并且在查询速度方面提供了 **5 倍更高的性能**。
要阅读基准测试和方法的完整详细信息,下载 “InfluxDB 与 MongoDB 在时间序列数据和指标管理方面的基准测试” 技术白皮书,或观看录制的网络研讨会。
我们的首要目标是创建一个一致的、最新的比较,以反映 InfluxDB 和 MongoDB 的最新发展,并在稍后涵盖其他数据库和时间序列解决方案。我们将定期重新运行这些基准测试,并使用我们的发现更新详细的技术白皮书。这些基准测试的所有代码都可以在 Github 上找到。如果您有任何问题、意见或建议,请随时在该存储库上提出问题或拉取请求。
现在,让我们看一下结果…
测试版本
InfluxDB v1.8.10
InfluxDB 是一款用 Go 编写的开源时间序列数据库。其核心是一个名为 Time-Structured Merge (TSM) Tree 的定制存储引擎,该引擎针对时间序列数据进行了优化。 InfluxDB 由一种名为 InfluxQL 的自定义类 SQL 查询语言控制,它为跨时间范围的数学和统计函数提供开箱即用的支持,非常适合自定义监控和指标收集、实时分析以及物联网和传感器数据工作负载。
MongoDB v5.0.6
MongoDB 是一款开源的、面向文档的数据库,俗称 NoSQL 数据库,用 C 和 C++ 编写。虽然它通常不被认为是真正的时间序列数据库本身,但其创建者经常推广其在 时间序列工作负载 中的使用。它以时间戳和分桶的形式提供建模原语,使用户能够存储和查询时间序列数据。
关于基准测试
在构建具有代表性的基准测试套件时,我们确定了处理时间序列数据最常评估的特征。我们研究了三个向量的性能:
- 数据摄取性能 - 以每秒值数衡量
- 磁盘存储需求 - 以字节为单位衡量
- 平均查询响应时间 - 以毫秒为单位衡量
关于数据集
对于此基准测试,我们专注于模拟常见 DevOps 监控和指标用例的数据集,其中服务器集群定期以规则的时间间隔报告系统和应用程序指标。我们每 10 秒对 9 个子系统(CPU、内存、磁盘、磁盘 I/O、内核、网络、Redis、PostgreSQL 和 Nginx)中的 100 个值进行采样。对于关键比较,我们查看了一个数据集,该数据集代表 100 台服务器在 6 小时内的运行情况,这代表了一个相对适中的部署。
- 服务器数量:100
- 每台服务器测量的指标值数量:100
- 测量间隔:10 秒
- 数据集持续时间:24 小时
- 数据集中的总值数:每天 8600 万
这只是整个基准测试套件的一个子集,但它是一个具有代表性的示例。如果您对更多细节感兴趣,可以在 GitHub 上阅读有关测试方法的更多信息。
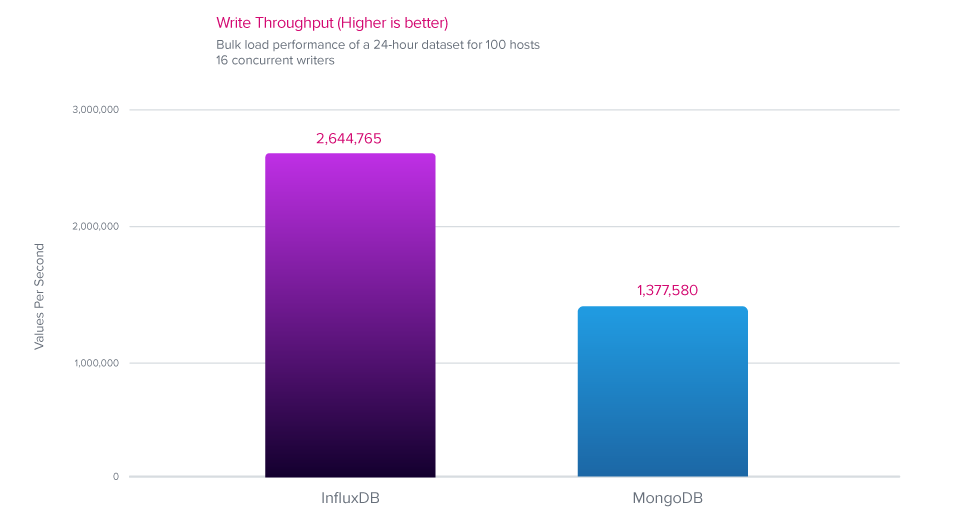
写入性能
在数据摄取方面,InfluxDB 的性能比 MongoDB 高出 1.9 倍。
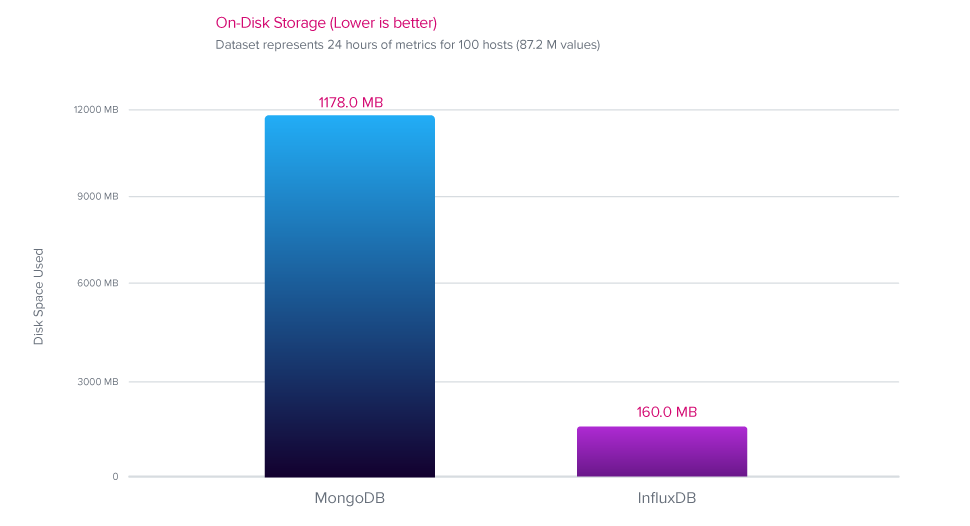
磁盘压缩
InfluxDB 提供了 7.3 倍更好的压缩率,性能优于 MongoDB。
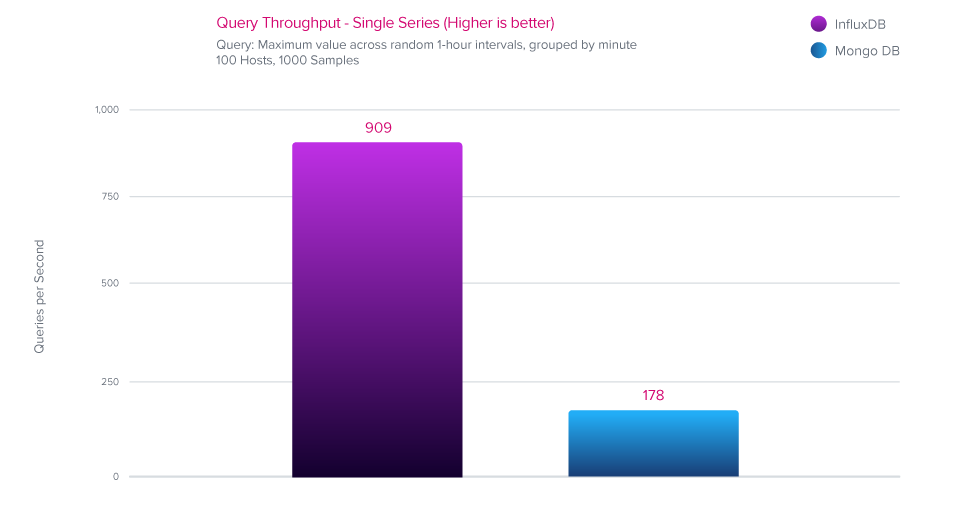
查询性能
在查询速度方面,InfluxDB 的性能比 MongoDB 高出 5 倍。
总结
基准测试和结果数据表明,InfluxDB 在数据摄取和磁盘存储方面明显优于 MongoDB。具体来说:
- 在数据摄取方面,InfluxDB 的性能比 MongoDB 高出 1.9 倍
- InfluxDB 提供了 7.3 倍更好的压缩率,性能优于 MongoDB
- InfluxDB 提供了 5 倍更好的查询性能,性能优于 MongoDB
同样重要的是要注意,配置 MongoDB 以处理时间序列数据并非易事。它需要预先决定如何构建您的集合和数据类型,这可能非常耗时,并且会对您如何与数据交互以及您可以运行的查询类型产生长期的影响。另一方面,InfluxDB 开箱即用,可用于时间序列工作负载,无需额外配置。
总之,我们强烈建议开发人员和架构师自己运行这些基准测试,以独立验证其选择的硬件和数据集上的结果。但是,对于那些正在寻找有效的起点来确定哪种技术可以提供更好的时间序列数据摄取、压缩和查询性能“开箱即用”的人来说,InfluxDB 在许多维度上都是明显的赢家,特别是当数据集变得更大且系统运行时间更长时。
下一步是什么?
- 下载详细的技术白皮书:“InfluxDB 与 MongoDB 在时间序列数据、指标和管理方面的基准测试”。
- 查看配套网络研讨会的视频回放。
- 下载并开始使用 InfluxDB。
- 加入社区!
