InfluxDB 集群设计 - 既非严格 CP 也非 AP
作者:Paul Dix / 公司
2015 年 6 月 3 日
导航至
几周前,我暗示了 InfluxDB 集群设计即将发生的一些重大变化。这些变化源于我们在过去 3 个月对计划在 0.9.0 版本中发布的集群设计进行的测试。简而言之,我们原本要采取的方法行不通。它既不可靠也不可扩展,并且为了我们不需要为我们的用例提供的保证而做出了牺牲。
六周前,我们退后一步,重新评估了我们整个集群方法。我们研究了我们需要提供的各种保证,更重要的是,对我们来说无关紧要的保证。最后,我们重新审视了关于分布式系统、共识和冲突解决的文献。我们意识到,通过放宽对于时间序列数据用例来说不必要的约束,我们可以构建一个更简单的系统,以实现我们对可扩展性和最大吞吐量的目标。
最终结果是将在 InfluxDB 的下一个版本中实现的集群实现。它专为吞吐量而设计,并将 CP 系统与 AP 系统结合用于主写入路径。作为一个整体,它被设计为高可用和最终一致。请继续阅读关于设计的非常详细的描述。非常感谢您的反馈。说分布式系统很困难将大大低估这一挑战。我们知道这需要迭代,但此设计是我们构建的基础。
假设和要求
在深入了解具体设计之前,我们需要列出我们针对的时间序列用例的一些关键要求。还有一些关于数据库使用方式的假设,这将使我们能够大大简化设计。
假设
- 时间序列数据几乎总是新数据(或历史回填),这些数据根据客户端提供的信息进行键控,并且是不可变的。在我们的例子中,每个数据点都根据测量名称、标签和时间戳进行键控。
- 如果相同的数据点被发送多次,则它与客户端刚刚发送两次的数据完全相同
- 删除很少发生。当它们确实发生时,几乎总是针对大范围的旧数据,这些数据对于写入来说是冷的
- 更新现有数据很少发生,并且不会发生有争议的更新
- 绝大多数写入都是针对具有非常新的时间戳的数据
- 规模至关重要。许多时间序列用例处理的数据集大小在 TB 或 PB 范围内
- 能够写入和查询数据比拥有强一致性的视图更重要
- 许多时间序列是短暂的。经常会出现仅出现几个小时然后消失的时间序列,例如,启动并报告一段时间然后关闭的新主机
从假设中注意到,我们主要讨论的是带有大范围删除的插入。有争议的更新不会出现在画面中,这使得冲突解决成为一个更容易处理的问题。稍后会详细介绍,让我们讨论具体要求。
要求
- 水平可扩展 - 设计应能够最初支持数百个节点,但能够扩展到数千个节点而无需完全重新架构。读取和写入应随着节点数量线性扩展。
- 可用性 - 对于读取和写入路径,倾向于 AP 设计。时间序列不断移动,我们很少需要最近数据的完全一致性视图。
- 应该能够支持数十亿个时间序列,其中单个序列由测量名称加上标签集组合表示。这源于短暂时间序列的假设。
- 弹性 - 节点应该能够离开,新节点可以加入集群。对于 0.9.0 版本,这不必是自动的,但设计应在未来的版本中促进这一点,而无需重新架构。
这些要求非常直接。主要是您期望从为最终一致性设计的水平可扩展分布式系统中获得的要求。InfluxDB 作为一个整体还有其他要求,但这些是驱动集群设计的要求。
如果这些要求和假设对您来说似乎不正确,请告知我们。但这些清楚地表明 InfluxDB 不是设计为通用数据库的。如果那是您需要的,请去其他地方。InfluxDB 专为时间序列、指标和分析数据而设计,这些数据是高吞吐量插入工作负载。
集群设计
新的集群设计由两个系统组成:用于存储集群元数据的 CP 系统和用于处理写入和读取的 AP 系统。本节将介绍每个系统的设计,并在最后一部分展示这两个系统如何在配置的集群中协同工作。
集群元数据 - CP
集群元数据系统是一个 Raft 集群,用于存储关于集群的元数据。具体来说,它存储
- 集群中的服务器 - 唯一 ID、主机名、是否正在运行集群元数据服务
- 数据库、保留策略和连续查询
- 用户和权限
- 分片组 - 开始和结束时间、分片
- 分片 - 唯一分片 ID、具有分片副本的服务器 ID
对任何此类数据的更新都必须通过集群元数据服务运行。该服务是一个简单的 HTTP API,由 Hashicorp Raft 实现 支持,并使用 BoltDB 作为底层存储引擎。
集群中的每个服务器都保留集群元数据的内存副本。每个服务器都将定期刷新整个元数据集以获取任何更改。对于传入的请求,如果存在缓存未命中(例如它尚不知道的数据库),它将从 CP 服务请求相关信息。
写入 - AP
为了处理读取和写入,我们利用了时间序列数据几乎总是新的不可变数据这一事实。这意味着我们可以绕过冲突解决方案,例如向量时钟或将其推送到客户端。我们倾向于接受写入和读取,而不是强一致性。
一个需要注意的地方是,分片组和分片是在 CP 系统中创建的。在正常操作期间,这些将在数据写入之前很久就创建。但是,这意味着如果节点与 CP 系统隔离的时间过长,它将无法写入数据,因为它没有分片组定义。
例如,让我们看一下写入传入时会发生什么。假设我们有一个由 4 台服务器组成的集群
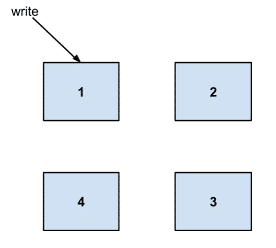
并且数据由服务器 2-3 拥有。
为了确定哪个服务器拥有数据,我们查看数据点的时间戳,以查看它属于哪个分片组。如果分片组不存在,我们调用 CP 集群元数据服务以获取或创建该数据点时间范围的分片组。
从元数据服务返回的分片组应包含分片,并且这些分片应分配给集群中的服务器。因此,集群元数据服务负责布局数据在集群中的位置。分片组将在可能的情况下提前创建,以避免在出现新的时间范围时出现大量写入冲击集群元数据服务。
一旦我们有了分片组,我们就对测量名称和标签集进行哈希处理,并对其与分片数量进行取模,以查看数据点应写入组中的哪个分片。请注意,这不是一致性哈希算法。我们不费心使用一致性哈希的原因是,一旦分片组对于写入来说变冷,我们就不需要担心在调整大小的集群中平衡这些分片。虽然获得更高的读取可扩展性就像将对于写入来说冷的分片复制到集群中的其他服务器一样简单。
数据的键是测量名称、标签集和纳秒时间戳。例如,假设分片存在于服务器 2、3 和 4 上
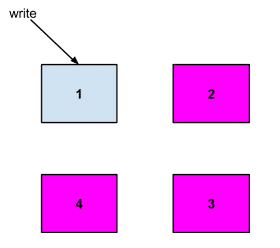
接下来会发生什么取决于请求的写入操作的一致性级别。不同的级别是
- 任意 - 如果拥有数据的任何服务器接受写入,或者一旦接收服务器(在我们的示例中为 1)将数据写入为持久的提示移交(稍后详细介绍),则成功
- 一个 - 一旦拥有数据的服务器之一(2、3、4)响应成功,则成功
- 仲裁 - 当 n/2 + 1 个服务器接受写入时成功,其中 n 是具有分片副本的服务器数量
- 全部 - 当所有服务器(2、3、4)接受写入时成功
写入数据的请求是并行发出的,当达到请求的级别时,会将成功返回给客户端。
写入失败
当写入失败或部分成功时会发生什么?例如,假设您请求了仲裁,但只能写入主机 2,而主机 3 和 4 超时。
此时,我们利用了关于时间序列数据的关键假设之一:写入始终是针对根据客户端提供的信息进行键控的新数据。
我们向客户端返回部分写入失败。与此同时,写入可以在后台通过提示移交进行复制。然后,客户端可以选择失败,也可以再次发出请求,这将仅覆盖现有值。但重要的是要注意,失败的部分写入最终可能会被接受并完全复制。
提示移交
提示移交有助于从短期中断(例如服务器重启或由 GC 暂停或导致系统过载的大型查询引起的临时不可用)中快速恢复。
在我们之前的示例中,当写入进入服务器 1 时,它将尝试将该数据点写入服务器 2、3 和 4。如果写入一致性为仲裁或更低,则写入可能会对任何宕机服务器使用提示移交。
例如,如果我们有仲裁级别的写入,则具有分片的服务器中的 2 个(2、3 或 4)必须接受写入。成功返回给客户端。然后,假设由于某种原因服务器 4 超时。然后,服务器 1 会将数据点写入为提示移交。
提示移交是服务器错过的任何写入的持久写入队列。因此,服务器 1 现在将在磁盘上存储服务器 4 的写入。当服务器 4 恢复运行时,服务器 1 会将其提示移交队列中的写入推送到服务器 4。
我们应该对提示移交队列的最大大小进行设置。还应限制来自提示移交队列的写入,以避免使在中断后最近恢复运行的服务器过载。
如果提示移交写入达到其 TTL,或者如果服务器 1 填满了服务器 4 的队列,则服务器 4 将必须通过反熵修复过程进行恢复。
反熵修复
反熵修复确保我们在所有数据上获得最终一致性。集群中的服务器将偶尔交换信息,以确保它们具有相同的数据。反熵适用于服务器宕机时间过长,并且提示移交无法缓冲所有必要写入的情况。
每个分片的 Merkle 树 将与其他拥有该分片的服务器进行比较。在这里,我们将再次利用时间序列假设:写入始终是针对新数据,并且我们想要所有数据。
因此,如果两个服务器发现分片具有不匹配的数据,它们将协同工作以遍历 Merkle 树,以查找不匹配的数据点。它们将交换其不同的数据,并且分片将是来自服务器的分片数据的并集。
时间序列数据中的另一个关键假设将帮助我们减轻比较的负担。具体来说,除了加载历史数据外,所有写入的数据都用于最近的时间范围。
因此,我们将不经常检查旧分片的一致性。可能每小时或每天一次,它是可配置的。完全修复是用户应该能够请求的操作(例如 Cassandra 的节点修复工具)。
对于写入热分片,我们将仅对早于某个小的可配置时间量的数据运行比较。例如,我们将仅对分片中早于 5 分钟的数据运行哈希比较。
冲突解决
仅当用户执行对现有数据点的更新时,冲突解决才会发挥作用。我们处理冲突解决的方案很简单:值更大者胜出。如果情况是一个或多个服务器上缺少数据,则最终集合应是来自所有服务器的数据的并集。
这使我们进行冲突解决的开销非常低。不需要向量时钟或任何其他东西。
鉴于此,更新和删除操作应设置 ALL 一致性级别,以确保它们成功且不会丢失。如果 ALL 没有响应,则当反熵修复启动时,删除可能会被还原,或者更新被覆盖。
这意味着持久删除和更新不是高可用的。我们的假设是这两种操作都很罕见。
此方案的缺点是保留策略强制执行的数据保留实际上将是最终一致的。每个节点都将针对其分片在本地强制执行保留策略。
删除大量的历史数据段
如果使用 ALL 一致性级别,则通过正常写入路径运行的删除操作不是高可用的。但是,删除旧历史数据的完整分片的删除操作可以更具容错性。
那是因为删除分片会通过集群元数据服务。请记住,分片是时间顺序数据的连续块。删除大量旧历史数据最有效的方法是删除整个分片或分片组。
这些操作是针对 CP 集群元数据服务执行的。请求可以进入集群中的任何服务器,并将被相应地路由。
可调查询一致性
集群的初始版本将检查每个分片的副本的单个服务器,从而使有效的一致性级别为 ONE。后续版本将启用可调的一致性级别。
结论
在所有这一切之后,您可能会问,此设计在 CAP 频谱中的哪个位置?答案是它既不是纯 CP 系统也不是纯 AP 系统。有一部分是 CP,但来自该系统的数据在整个集群中是最终一致的。还有一些部分是 AP,但如果这些节点与 CP 系统之间存在足够长的分区,则这些部分将不再可用。
关于集群设计,我们可以谈论更多的事情。特别是关于如何处理每种故障情况。关于删除和更新集群元数据,我们可以介绍更深入的细节。在接下来的几个月中,我们将致力于记录这些内容,并详细阐述每种情况。生产环境中的这些情况比它是 CP 还是 AP 更重要,我们将努力提供尽可能多的信息和数据。
此设计基于 InfluxDB 中集群的三个迭代。我们根据我们认为可以接受的权衡以及通过关注我们用例的一些最重要部分:具有低写入开销的水平可扩展性,最终确定了此设计。欢迎反馈、想法甚至挑战!
