InfluxDB 3.0 最新数据速度比 InfluxDB 开源版快 45 倍
作者:Charles Mahler / 产品
2023 年 8 月 9 日
导航至
随着 InfluxDB 3.0 的发布,一个重要的问题是:它与以前版本的 InfluxDB 相比如何?我们已经开始使用生产工作负载对 InfluxDB 3.0 进行基准测试,以便开始让用户更深入地了解采用 InfluxDB 3.0 的好处。在这篇文章中,我们将研究最近的基准测试,比较 InfluxDB 3.0 和 InfluxDB 开源版 (OSS) 1.8。
我们将性能基准测试结果总结如下:
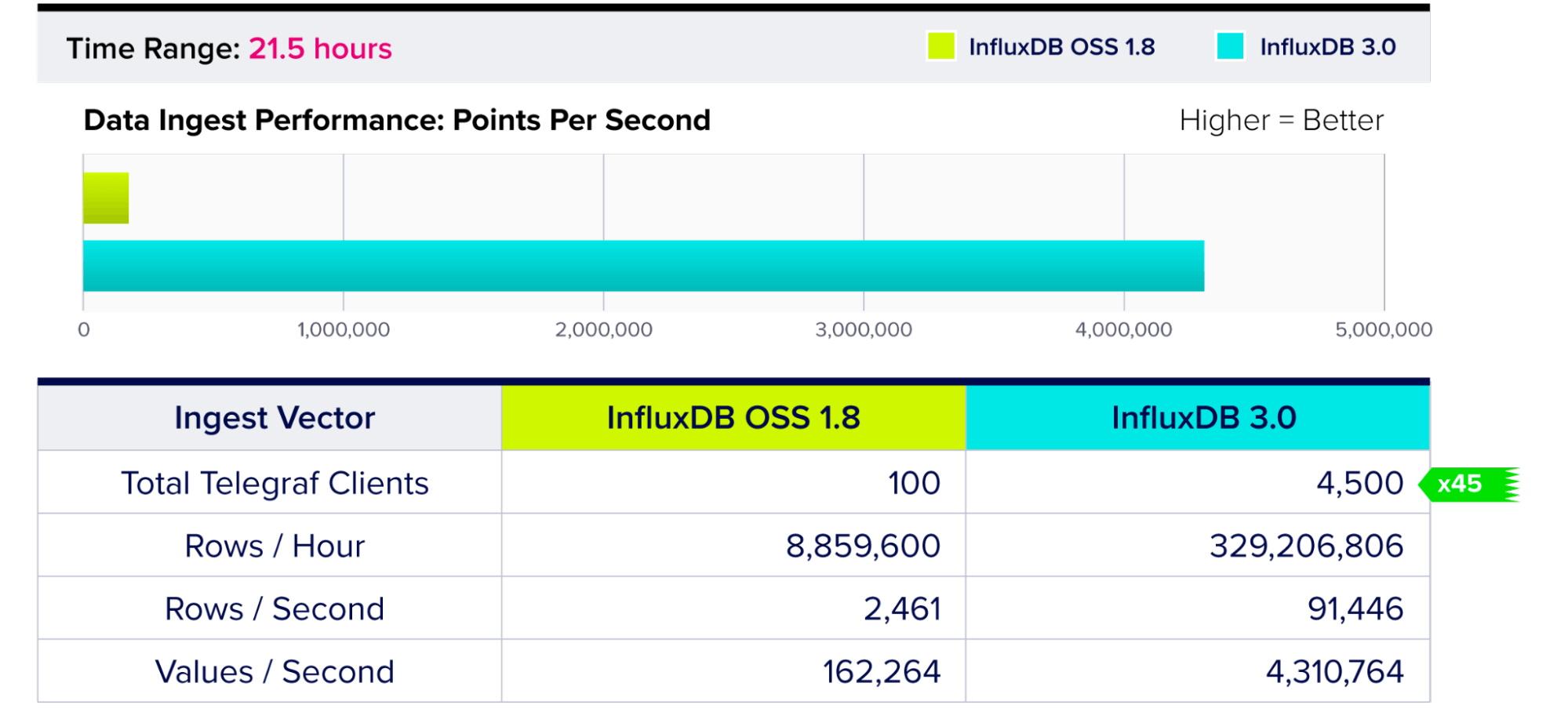
- InfluxDB 3.0 提供的写入吞吐量比 InfluxDB OSS 高 45 倍。
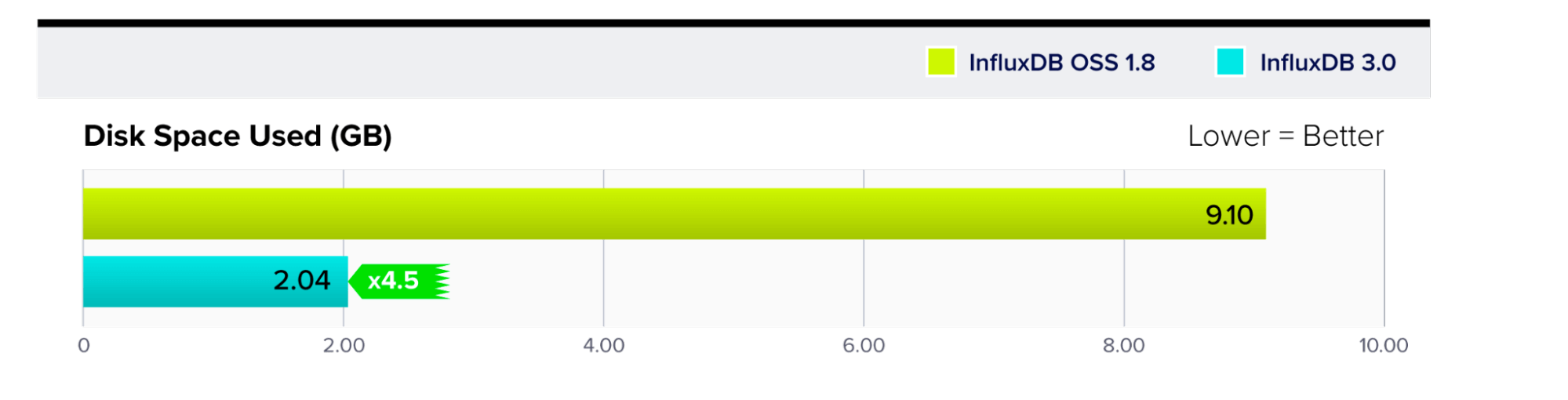
- 与 InfluxDB OSS 相比,InfluxDB 3.0 的存储压缩率提高了 4.5 倍。
- InfluxDB 3.0 对于给定的硬件资源更加高效,与 InfluxDB OSS 相比,可以将存储成本降低 90% 以上。
- 与 InfluxDB OSS 相比,InfluxDB 3.0 对于各种查询类型的最新数据 (5 分钟) 查询速度快 2.5-45 倍。
- 与 InfluxDB OSS 相比,InfluxDB 3.0 对于各种查询类型的过去 1 小时时间范围的数据查询速度快 5-25 倍。
我们的首要目标是创建一个一致且最新的比较,以反映 InfluxDB 3.0 与 InfluxDB 开源版相比的最新发展。我们将定期重新运行这些基准测试,并使用我们的发现更新我们详细的基准测试技术文档。
此基准测试为比较 InfluxDB 3.0 与以前版本的 InfluxDB(包括 1.x 和 2.x)提供了一个清晰的框架。您可以在此处试用我们的交互式基准测试工具。
测试的产品和版本
InfluxDB 3.0
InfluxDB 3.0 是 InfluxDB 的最新版本,为开发人员提供了前所未有的规模和性能。InfluxDB 3.0 支持全范围的时间序列数据,包括高基数数据,例如指标、事件和跟踪。InfluxDB 3.0 基于 Rust 构建在 Apache Arrow 之上,这种解耦架构允许计算和存储彼此独立扩展。InfluxDB 3.0 为 SQL 和 InfluxQL(自定义类 SQL 查询语言,增加了对基于时间的功能的支持)提供查询支持。InfluxDB 3.0 在市场上推出了两款产品,还有一款产品将于今年晚些时候发布。InfluxDB Cloud Serverless 是数据库的多租户实例,而 InfluxDB Cloud Dedicated 是单租户产品。两者目前都可用。InfluxDB Clustered 将于今年晚些时候发布,是 InfluxDB 3.0 的专用实例,客户可以在自己的环境中管理和操作。
InfluxDB OSS 1.8
InfluxDB 1.8 是 InfluxDB v1 系列的最新版本。它的核心是 时间结构化合并 (TSM) 树,这是一种为时间序列数据优化的自定义构建的存储引擎。InfluxDB OSS 支持 InfluxQL,并且因其特定于时间序列的功能而在社区中广受欢迎(我们专注于使用 InfluxQL 测试查询,因为 InfluxDB 3.0 和 InfluxDB 1.8 都原生支持 InfluxQL,从而实现更强大的直接比较)。
基准测试方法
工作负载
我们设计的此基准测试旨在模拟真实世界的条件。该测试在数据摄取期间按顺序执行各种时间范围和计划的查询,以模拟实际工作负载条件。未来的基准测试计划包括添加查询工作负载的并行执行。我们选择 Telegraf 作为数据收集代理来测试写入吞吐量。该测试增加了写入数据的客户端数量,直到观察到性能下降。
数据集
我们为此基准测试设计的数据旨在模拟使用 Telegraf 输入插件收集各种指标和测量的应用程序性能监控工作负载。以下是数据集的高级详细信息:
- 数据集持续时间:24 小时
- 测量间隔:10 秒
- 基数:160,000
有关基准测试的完整详细信息,您可以在此处下载完整报告。
写入性能
与 InfluxDB OSS 相比,InfluxDB 3.0 可以处理 45 倍 以上的客户端同时写入数据,而不会出现性能下降。InfluxDB 3.0 的卓越执行力,尽管可用的硬件资源少于 InfluxDB OSS(下载完整报告以了解硬件规格详细信息),进一步证明了新产品的效率和进步。
数据摄取性能
结果代表从不同负载的 Telegraf 实例报告的 21.5 小时指标。
存储性能
在数据压缩方面,InfluxDB 3.0 的性能大约比 InfluxDB OSS 高 4.5 倍。成本节省最大化,因为 InfluxDB 3.0 使用对象存储,这比 InfluxDB OSS 使用的基于 SSD(固态设备)的存储更便宜。
磁盘上的存储大小
查询性能观察
在查询性能类别中,InfluxDB 3.0 的性能比 InfluxDB OSS 高 2.5-45 倍。这 22 种不同类型的查询按时间序列数据的真实世界用例分组。对于特定类型的查询,性能提升甚至更大。
我们在查询测试用例中为每个产品运行每个查询 10 次。查询延迟指标的第 95 个百分位数确定了性能。查询包括两个单独的时间范围:最近 5 分钟的数据和最近 60 分钟的数据。
查询可以大致分为以下几类:
- 聚合:聚合查询包括输出从原始行派生的聚合值(例如,计数、总和、最小值、最大值等)的查询。
- 统计/数学:统计/数学查询对选定的行执行数学(例如,众数、中位数等)或统计(例如,离差、标准差、百分位数等)函数。
- 阈值:阈值查询返回字段满足一个或多个阈值条件的行。
- In / Or:In / Or 查询返回与 IN / OR 子句提供的多个值匹配的行。
- 按时间分组:按时间分组查询对返回的行执行基于时间的操作。
- 按组分组/按顺序排序:按组分组/按顺序排序查询返回某些列分组的结果行,或包含按排序顺序排列的结果。
- 限制/顶部/底部:限制/顶部/底部查询仅返回 LIMIT 或 TOP 或 BOTTOM 子句指定的行。
- Like / Union:Like / Union 查询通过匹配 LIKE 子句提供的模式返回多行,或返回多个查询的并集。
以下一些图表显示了基准测试运行 24 小时后,以及查询最近 5 分钟内的数据时,InfluxDB 3.0 和 InfluxDB OSS 的性能比较。
查询性能 – 聚合查询类型
输出从选定行派生的聚合值(例如,计数、总和、最小值、最大值等)的查询。
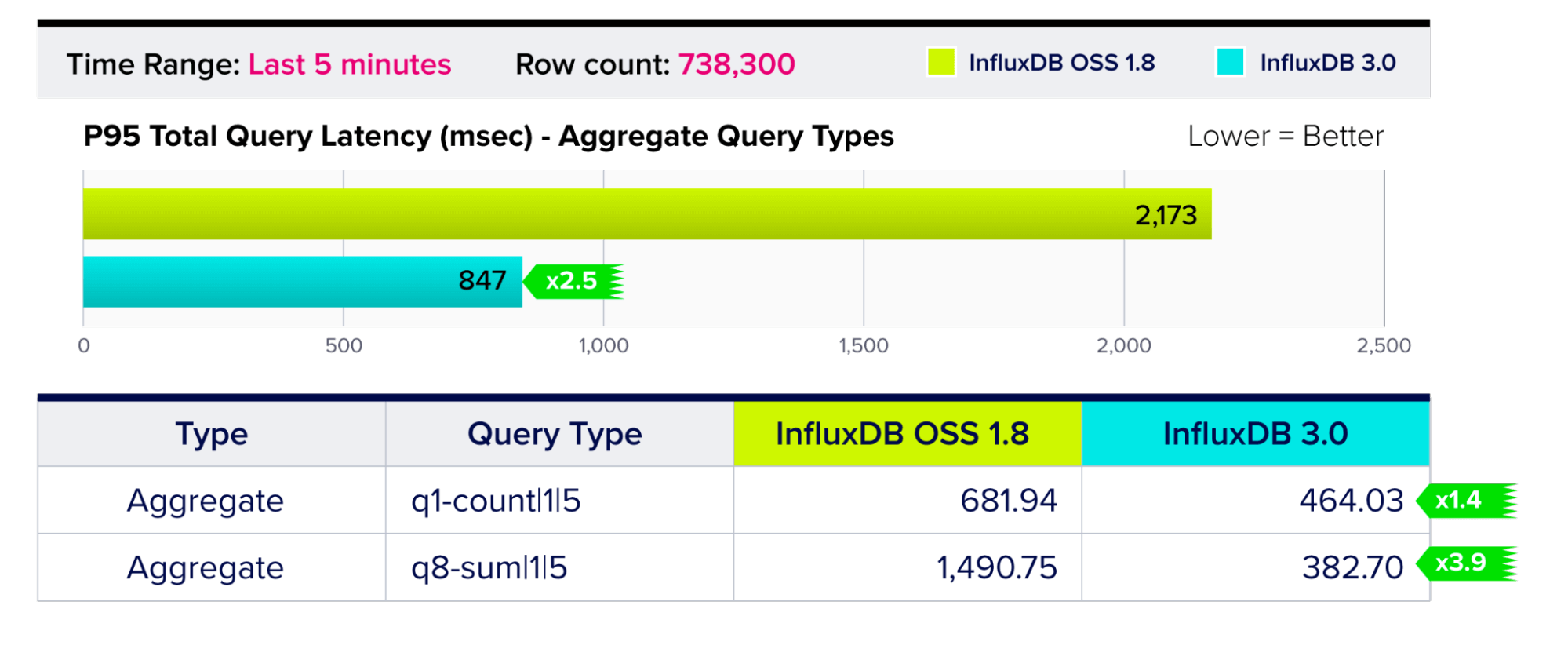
结果反映了 InfluxDB 3.0 在常见分析查询方面的性能改进,例如对时间范围内多个列值的所有值求和。
查询性能 – 按组分组/按顺序排序查询类型
查询返回从对某些列进行分组得出的行,或包含按排序顺序排列的结果。

这组查询使用 Order by / Group by 子句来筛选和排序数据。Order by 查询专门显示 InfluxDB 3.0 比 InfluxDB OSS 性能提升 78 倍。
查询性能 – 限制/顶部/底部查询类型
查询仅返回 LIMIT 或 TOP 或 BOTTOM 条件指定的行。

这些查询涉及使用 Limit 和 Top 子句选择 10 个最新值和 5 个最新 CPU 值。
查询性能 – 统计/数学查询类型
对选定的行执行数学(例如,众数、中位数等)或统计(例如,离差、标准差、百分位数等)函数的查询。
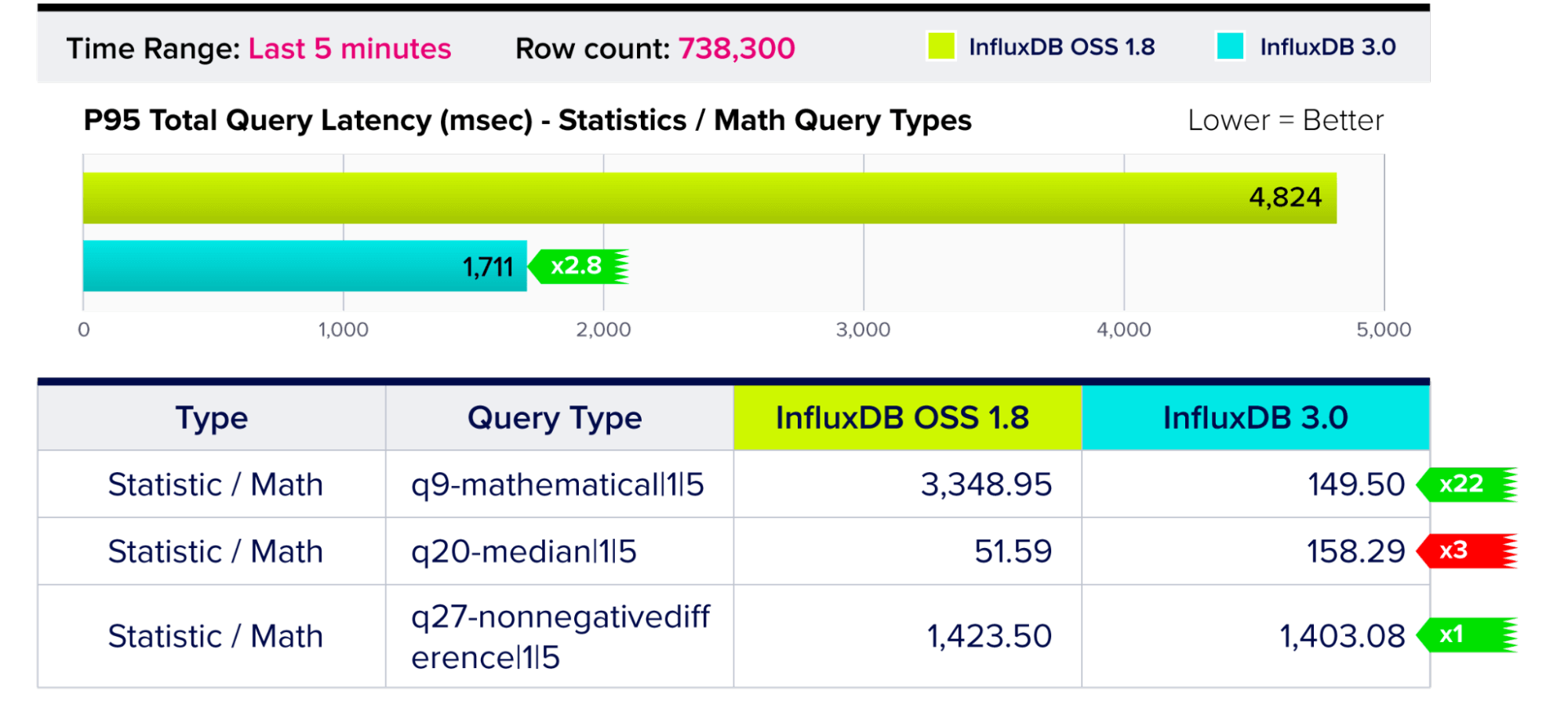
此图表包含三个不同的查询,结果范围各不相同。统计/数学查询包括基准测试开始时的五分钟时间范围。对于某些查询,InfluxDB 3.0 快 22 倍,对于其他查询则相同,而对于中位数运算符查询则稍慢。
后续步骤
在这篇文章中,我们回顾了最近的基准测试,比较了 InfluxDB 3.0 与 InfluxDB OSS 在三个方面:数据摄取、查询性能和存储。在所有领域,InfluxDB 3.0 的性能都明显优于 InfluxDB OSS。
我们在多年开发以前版本的 InfluxDB 的经验之后构建了 InfluxDB 3.0。我们相信这反映在整个基准测试研究的基准测试和详细部分中。下载您的免费副本完整基准测试报告。
对概念验证感兴趣?立即与我们的销售团队成员交谈!
