如何使用 Grafana 和 InfluxDB 监控时间序列数据
作者:Gunnar Aasen / 产品, 开发者, 公司
2017 年 11 月 02 日
导航至
“用于美观分析和监控的开放平台”Grafana 支持各种存储时间序列数据的后端。其中一个后端是 InfluxDB。InfluxDB 是一个 时间序列数据库,专门为存储时间序列数据而构建,而 Grafana 是一个用于时间序列数据可视化的工具。鉴于这种完美匹配,Grafana 与 InfluxDB 紧密集成。
Grafana 时间序列监控简介
Grafana 绝对是我们推荐与 InfluxDB 一起使用的最流行的时间序列数据可视化工具之一。以下是关于如何使用 InfluxDB 设置 Grafana 仪表板、如何使用 Grafana InfluxDB 解决方案充分利用您的时间序列数据,以及如何使用 InfluxDB 时间序列数据库可视化您想要的内容 - 以您想要的方式 - 的一些基础知识。
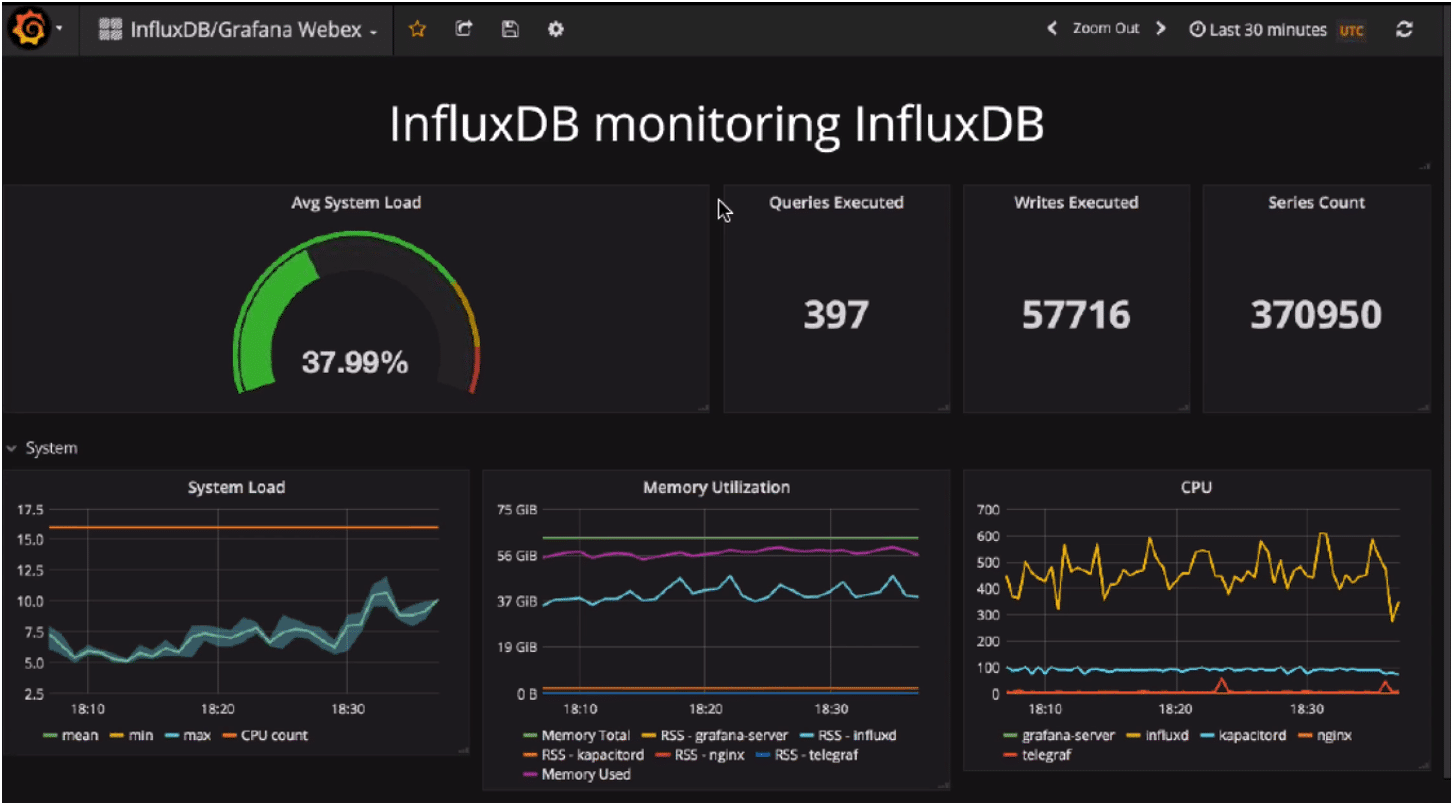
InfluxDB 的 Grafana 仪表板设置
首先,下载 InfluxDB 和 Grafana。基本设置是将 InfluxDB 和 Grafana 监控连接在一起。InfluxDB 有一个 API,默认情况下端口为 8086,而 Grafana 的 API 端口为 3000。Grafana 会在需要查询数据时调用 InfluxDB API。
当您设置 InfluxData 时间序列平台时,您将需要一个收集代理来收集您的指标。对于 InfluxDB,请使用 Telegraf,它已经有超过 200 个插件。

需要记住的一些 Grafana InfluxDB 基本设置
- InfluxDB 本质上是在服务器上运行的时间序列数据库进程。该进程也可以在 Grafana 运行的同一台机器上运行。Grafana 有一个非常轻量级的服务器端应用程序,并且大多数 Grafana 监控都在浏览器中运行。
- 在同一实例上设置 Grafana 和 InfluxDB 最为容易,但如果您发现您的 InfluxDB 安装非常庞大,Grafana 用户数量众多,或者您的组织内有特定的安全或部署配置文件,那么在单独的服务器上设置 InfluxDB 和 Grafana 也是完全可以接受的。
- InfluxDB 将是两者中内存和 CPU 密集型更高的应用程序,仅仅因为 Grafana 的许多工作发生在浏览器中。为了保持最佳性能,我们建议 Grafana 监控使用最新的浏览器。
Grafana 和 InfluxDB 设置配置
InfluxDB 的许多默认设置都可以保留。请注意,您可以启用查询日志 - 这将在执行查询或发送到 InfluxDB API 时记录所有查询,这对于调试 Grafana 问题非常有用。
使用 Grafana 设置 InfluxDB 时需要注意的一个重要事项是设置配置的协调器部分 - 特别是设置最大并发查询数
- 如果您遇到不同的 Grafana 用户都使用不同的打开浏览器访问 InfluxDB 并发送大量时间序列数据库查询的问题,我们建议设置最大并发查询数。您还可以设置查询超时,并将超过一定时间的查询记录下来。
- max-select-point、max-select-series 和 max-select-buckets 周围的设置在限制可以返回的结果数量方面也非常有用 - 从而防止特别庞大的查询可能导致 InfluxDB 服务器宕机或导致其他所有人速度减慢。
在浏览 Grafana 的配置文件时,您会发现大量其他很棒的方式来配置 Grafana 监控,使其更易于使用。这些包括设置 Grafana http 端口、路由器日志记录以及使用户的浏览器页面加载更快。
了解有关 Grafana 安全设置的信息
至于安全设置,每个 Grafana 实例都有一个默认管理员用户和默认密码。如果您在任何可以让人进入您的实例的地方设置 Grafana 监控,请设置您自己的自定义用户名或至少密码,以防止人们获得访问权限。
以下是一些基本的 Grafana 安全设置
- 默认情况下,Grafana 将允许用户注册和注册,并且还允许非管理员用户创建组织。因此,我们建议将“启用匿名访问”选项设置为“false”,以防止人们在您不希望他们这样做的情况下在组织上设置用户。
- 此外,匿名访问默认情况下处于禁用状态,但您可以启用匿名访问,如果您有想要推广的公共 Grafana 仪表板,这将非常有用。
- 如果您进行密码重置,需要用户接收电子邮件,您需要在 SMTP 部分进行设置。
- Grafana 还有许多日志级别,因此如果您尝试调试,请务必将日志级别提升到调试。
- Grafana 将公开关于自身的指标 - Telegraf 有一个内置的 Prometheus 输入,因此您可以将其定向到该输入并接收或收集内部 Grafana 指标,将其放入 InfluxDB,然后在 Grafana 中再次绘制它们。
如果您正在使用 InfluxDB Cloud 并且需要配置对 Grafana 上不同组和用户的访问权限,以查看 InfluxDB Cloud 收集的时间序列数据,请查看网络研讨会短片 “具有多租户 Grafana 的 InfluxDB Cloud。”
为 Grafana 指标设置图表
InfluxData 的“如何将 Grafana 与 InfluxDB 一起使用”网络研讨会 解释了如何使用 Grafana UI 设置图表并使用 InfluxDB 查询构建器。
以下是一些关于构建 Grafana 仪表板和自定义图表的网络研讨会重点
- 进入配置后,添加数据源,选择 InfluxDB 类型,并为该数据源命名。您可能希望将其设为 Grafana 监控实例的默认数据源。您选择 InfluxDB URL 并输入数据库、用户和凭据。一旦您收到“成功”通知,您就可以添加 Grafana 仪表板了。
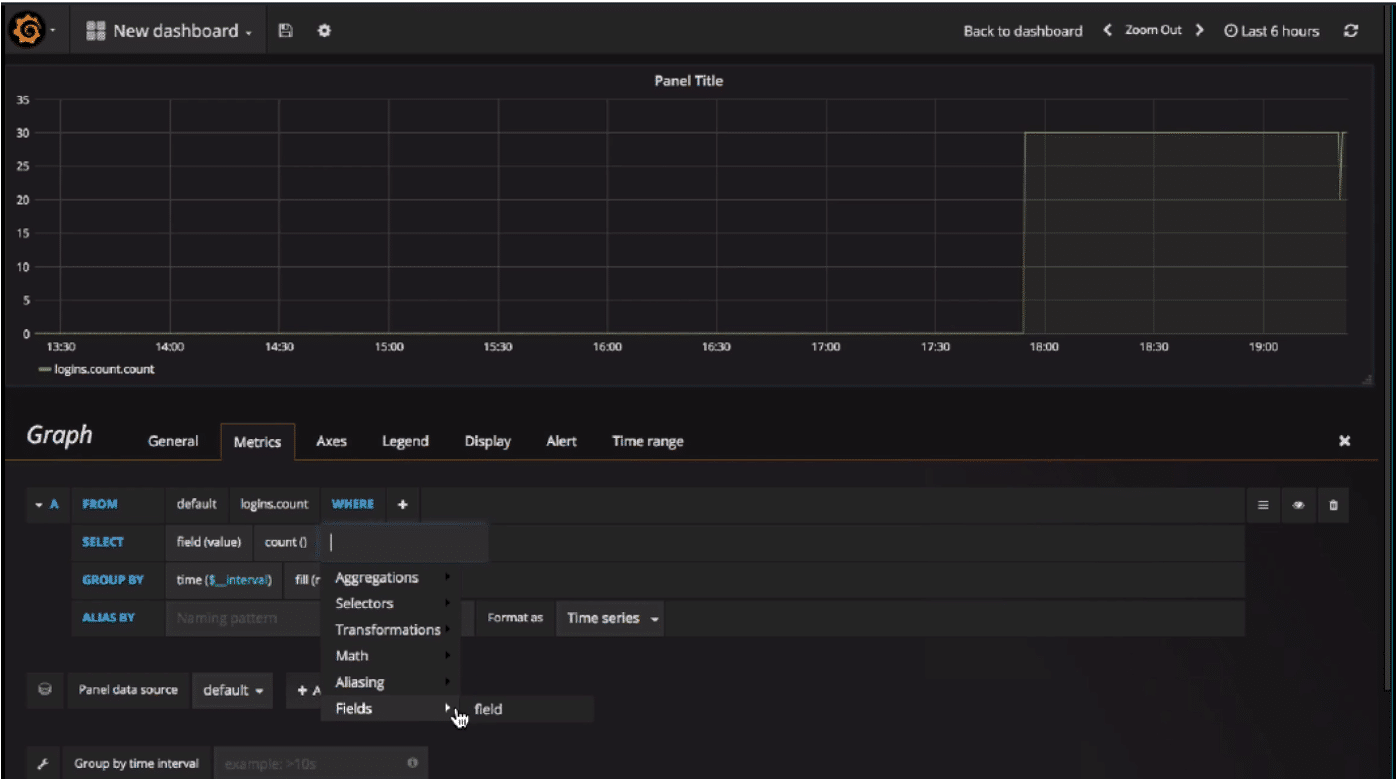
- Grafana 仪表板基于行和面板。您可以在一行上设置多个面板,并且可以编辑面板。
- 在编辑模式下,您会看到 Grafana 指标路径,您可以在其中指定 InfluxDB 查询。您还可以指定要使用的 InfluxDB 策略。
- 默认情况下使用“value”作为字段和“mean”,但您可以使用您选择的任何聚合器。您还可以选择多个字段,或选择相同的字段两次并使用不同的聚合器。
- 您可以添加各种类型的转换,例如 moving_average。
- Grafana 指标选项卡中的另一个属性是它们的 GROUP BY 方式。默认情况下,Grafana 使用预定义的间隔值进行 GROUP BY,该值根据屏幕和面板宽度计算得出。您还可以指定 InfluxDB 应如何处理空值。
- 您可以更改图表的显示方式(线条、条形图、点等),并利用不同的显示设置。
使用 Grafana 优化时间序列监控
InfluxDB 和 Grafana 协同工作良好,但您肯定会遇到一些性能问题。如果您正在收集大量时间序列数据,或者正在查询大量数据并给 InfluxDB 带来一些压力,您通常会发现 InfluxDB - 因为它正在完成许多服务器端工作 - 是 Grafana InfluxDB 链中第一个遇到问题的部分。
每个 Grafana 图表实际上都是对 InfluxDB 的查询。您拥有的图表越多,InfluxDB 服务器上的负载就越大。因此,如果您有一个包含 30 个图表的 Grafana 仪表板,那么您将向 InfluxDB 发送 30 个查询,并且需要 InfluxDB 整理 30 个查询的结果,然后通过 Grafana 监控将其发送回去。如果您有大量查询或图表,请考虑您正在绘制的内容以及您显示的图表是否真的对您有用。
为了进一步提高 InfluxDB 的性能 和 Grafana,以下是一些有用的技巧
- 将您的行设置为可折叠 - 当您折叠行时,Grafana 将不会显示或渲染该图表,因此不会生成对 InfluxDB 的查询。因此,如果您碰巧有一个 Grafana 仪表板,其中包含许多有用的图表,但这些图表可能并非一次全部有用,那么使用可折叠行是减少或加速您使用 InfluxDB 的 Grafana 监控体验的好方法。
- 还有几种图表类型和其他选项可以添加到图表中。例如,如果您只关心执行的查询数量,您可以只返回最后执行的查询数量,而不是一段时间内的图表。您还可以进行模板化和注释。
- Grafana 图表生成的每个查询通常都有一个 GROUP BY 选项,因此您会在每次加载图表时看到大量重新计算。
- 如果您执行非常庞大的查询进行计算,并且 InfluxDB 需要一段时间才能响应,并且查询超时,并且您的 Grafana 图表中出现错误,请在点击“刷新”按钮之前稍等片刻。
- InfluxDB 和 Grafana 监控都提供了许多日志记录选项。如果 Grafana 显示图表错误,请仔细检查并找出导致该错误的原因(如果在一两次刷新后错误没有消失)。InfluxDB 不缓存查询,因此每次发送查询时,它都会重新计算结果。通常,如果您缩小或选择更大的时间范围(例如 24 小时),InfluxDB 需要更长的时间才能提取所有这些结果。您累积的数据越多,Grafana 和 InfluxDB 需要处理的数据就越多才能加载。
结论
一个图表上显示的 Grafana 指标数量没有限制,但请记住跟踪那些对时间序列监控性能、提取见解或启用预测最有用的指标。如果您正在考虑一次要显示多少 Grafana 指标,您可能还需要考虑该时间序列数据实际显示的内容以及您试图通过读取所有这些数据来完成什么。
