入门指南:将数据写入 InfluxDB
作者:Anais Dotis-Georgiou / 产品, 用例, 开发者
2020 年 8 月 9 日
导航至
这是一个初学者教程,介绍如何使用以下三种方法将静态数据批量写入 InfluxDB 2.0
- 通过 InfluxDB UI 上传数据
- 直接导入到 InfluxDB
- 使用 Telegraf 和 Tail 插件
在开始之前,请确保您已安装 InfluxDB OSS 或已注册免费的 InfluxDB Cloud 帐户。注册 InfluxDB Cloud 帐户是开始使用 InfluxDB 的最快方法。
数据集
在本教程中,我使用了来自 kaggle 的比特币历史数据“BTC.csv”(33 MB),时间范围为 2016-12-31 至 2018-06-17,精度为 Unix 时间的分钟级(约 760,000 个点)。数据如下所示
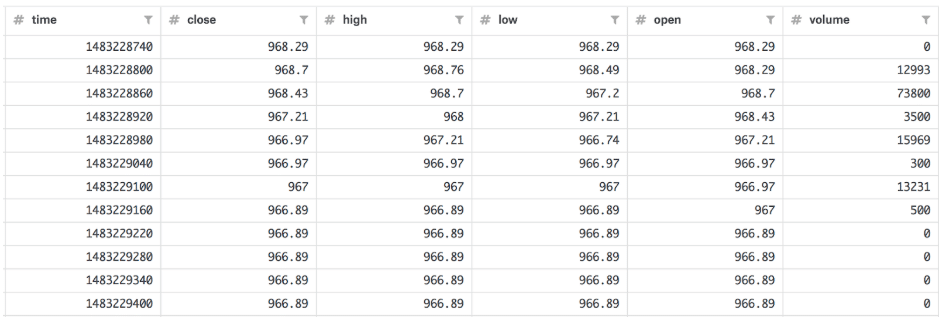
我还将时间戳转换为纳秒精度。
1. 通过 Chronograf 上传
Chronograf 对上传数据有两个要求。文件大小必须不大于 25MB,并且以 行协议 格式编写,这是 InfluxDB 的数据摄取格式。我将数据转换为 line protocol 格式,保存在 myLineProtocolData.txt 中。为了将包含上述数据的 csv 文件“BTC.csv” 转换为 line protocol 格式,我使用了以下脚本 csv_to_line.py
import pandas as pd
#convert csv to line protocol;
#convert sample data to line protocol (with nanosecond precision)
df = pd.read_csv("data/BTC_sm_ns.csv")
lines = ["price"
+ ",type=BTC"
+ " "
+ "close=" + str(df["close"][d]) + ","
+ "high=" + str(df["high"][d]) + ","
+ "low=" + str(df["low"][d]) + ","
+ "open=" + str(df["open"][d]) + ","
+ "volume=" + str(df["volume"][d])
+ " " + str(df["time"][d]) for d in range(len(df))]
thefile = open('data/chronograf.txt', 'w')
for item in lines:
thefile.write("%s\n" % item)转换后,myLineProtocolData.txt 看起来像

接下来,导航到 https://:9999/ 或您的 InfluxDB Cloud url,该 url 因地区而异,然后登录。例如,我的 InfluxDB Cloud url 是 https://us-west-2-1.aws.cloud2.influxdata.com。
登录 InfluxDB v2 后,我们现在可以将我们的 line protocol 数据写入到 InfluxDB 的 存储桶 (bucket) 中,通过 UI 完成。我们将点击着陆页左侧的 Data 选项卡
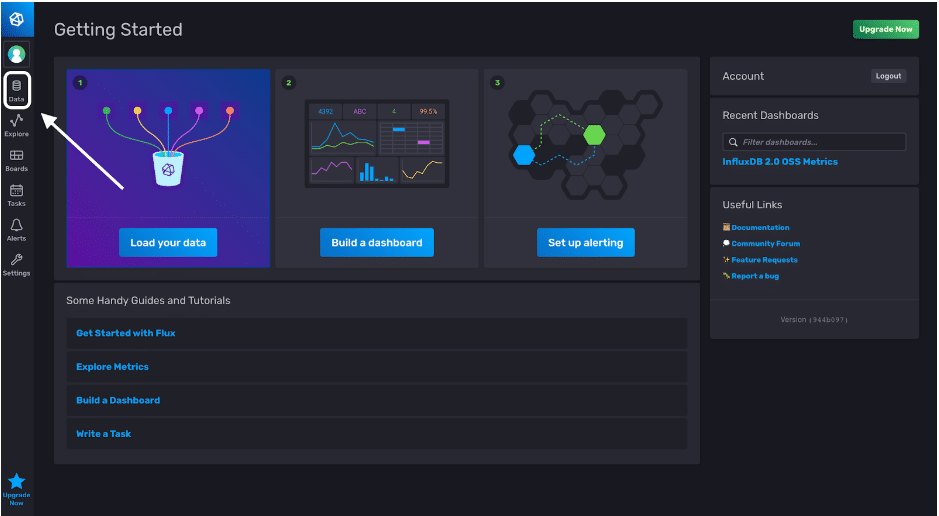
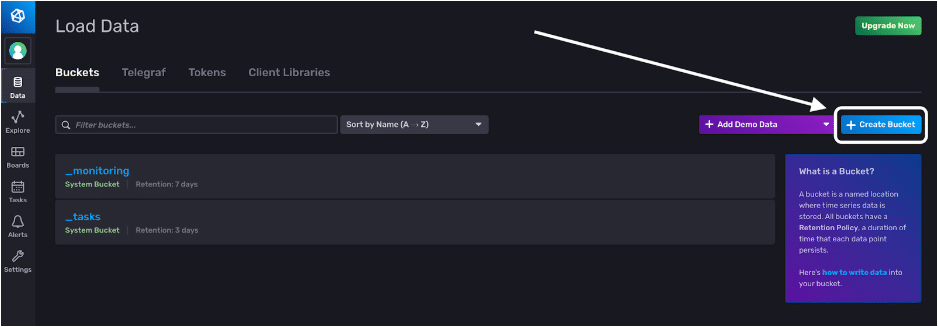
Data 选项卡允许我们创建存储桶、创建 Telegraf 配置、创建 令牌 (token) 并初始化客户端库。单击“创建存储桶”按钮,为我们的 BTC 数据创建一个目标存储桶。
现在,我们创建一个存储桶,将其命名为“BTC”,并设置保留策略。我们的数据将在超过 30 天后自动删除。
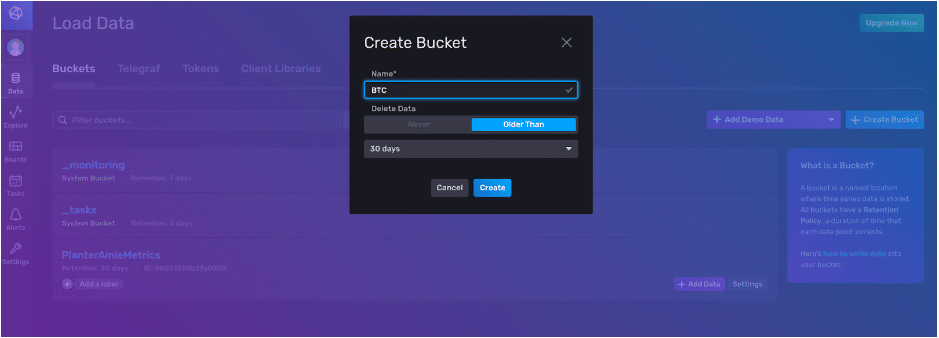
现在我们可以将我们的 line protocol 写入到我们的 BTC 存储桶中。我们单击 + Add Data 按钮,然后选择我们要将数据写入到相应存储桶的方法。
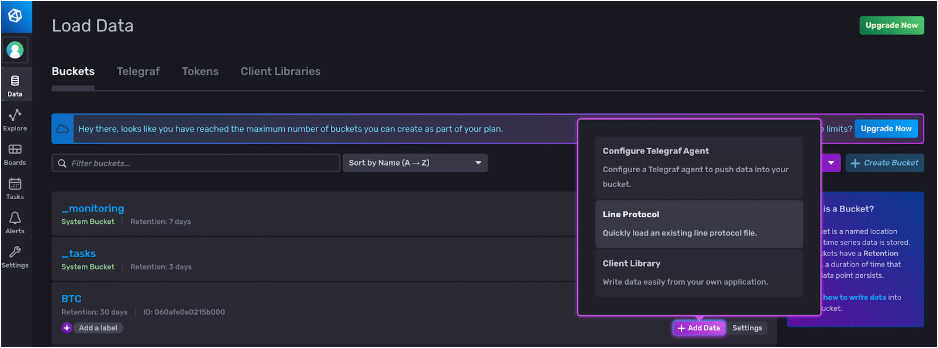
我们可以复制并粘贴我们的 line protocol,并指定我们想要写入点的精度。
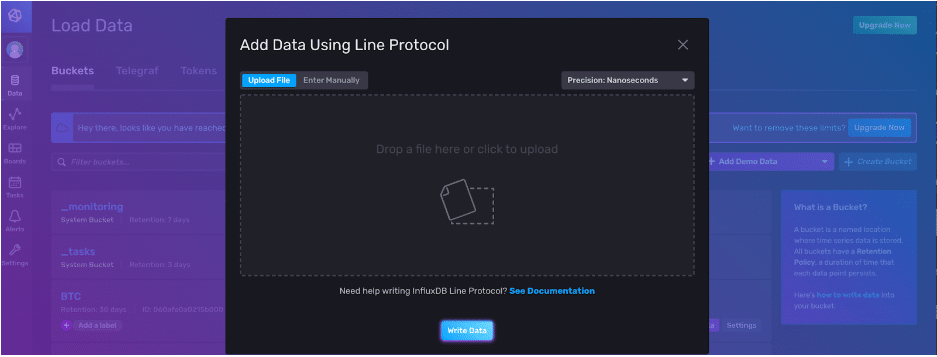
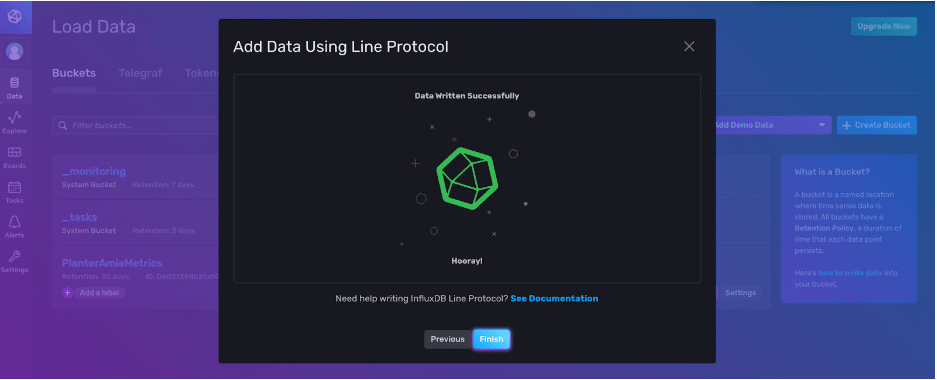
单击 Write Data 按钮完成。恭喜!您已将一个点写入 InfluxDB v2。
2. 直接导入到 InfluxDB 2.0 OSS
如果您的数据大小大于 25 MB 并且您正在使用 InfluxDB 2.0 OSS,我建议使用此方法将数据直接写入 InfluxDB v2。使用以下 CLI 命令
influx write \
-b bucketName \
-o orgName \
-p ns \
--format=lp
-f /path/to/myLineProtocolData.txt使用 influx write 您只需要指定您的存储桶名称 -b、您的组织名称 -o 和您的时间戳精度 -o、您的文件格式。在我们的示例中,我们的文件采用 line protocol 格式,即 --format=lp,以及您的文件路径。
3. 将 Telegraf 和 Tail 插件用于 InfluxDB OSS 和 InfluxDB Cloud
Tail 插件 实际上是用于读取流式数据的。例如,您可以连续向 API 发出请求,将您的新数据附加到您的 myLineProtocolData.txt 文件中,Telegraf 和 Tail 插件将写入新点。但是,您可以更改 tail 输入的配置文件 (conf) 中的读取设置,以便您可以读取静态文件。我们将在稍后介绍。
接下来,您需要创建一个 telegraf.conf 文件。如果您在本地安装了 Telegraf,您可以运行此 CLI 命令来生成一个带有适当输入和输出过滤器的 Telegraf 配置
telegraf --input-filter tail --output-filter influxdb_v2 config > telegraf.conf也可以随意将您的 conf 命名为更具描述性的名称,例如 tail.conf,这样您就可以记住您稍后在您的 conf 中包含了哪些插件。
如果您没有在本地安装 Telegraf,您可以在此处搜索正确的配置,并将配置手动复制并粘贴到 UI 中。
对配置文件进行以下更改
- 指定数据的精度(第 64 行)。在本示例中,我们的 BTC 数据已转换为 ns 精度,因此:
precision = "ns" - 由于我们没有执行监控任务,因此我们不关心设置“host”标签。设置
omit_hostname = true,以便 Telegraf 不设置“host”标签(第 93 行)。 - 导航到 OUTPUT PLUGIN 部分。
- 指定您的 InfluxDB 实例(第 111 行):
urls = ["https://us-west-2-1.aws.cloud2.influxdata.com"] # 必需 - 指定您的存储桶、令牌和组织(第 113-120 行)
- 导航到 SERVICES INPUT PLUGIN 部分。
- 指定您的 line protocol txt 文件的绝对路径(第 544 行)
- 通常(使用 Tail 插件),Telegraf 不会开始写入 InfluxDB,除非数据已附加到您的 .txt 文件,因为 Tail 插件的主要目的是将流式数据写入 InfluxDB。这由 from_beginning 配置确定,该配置通常设置为 false,以便您不写入重复的点。由于我们的数据是静态的,请将此配置更改为 true(第 546 行)
from_beginning = true
- 指定数据消化方法(最后一行)
data_format = "influx"
要在 InfluxDB v2 中使用此 Telegraf 配置,请按照有关如何使用 UI 手动配置 Telegraf 的以下文档进行操作。本质上,您只需要将您的配置复制并粘贴到正确的位置即可。
我希望本教程可以帮助您开始使用 Telegraf。如果您有任何问题,请将它们发布在社区站点上,或在 Twitter 上 @InfluxDB 上给我们发推文。谢谢!
既然您已经阅读了本教程(我们的入门系列的第一部分),请务必阅读第二部分,“入门指南:将流式数据导入 InfluxDB”。
