StatsD 指标发送到 Telegraf 和 InfluxDB 入门
作者:Steven Soroka / 用例、产品、开发者、入门
2020 年 9 月 10 日
导航至
为什么选择 StatsD?
有很多充分的理由使用 StatsD,以及 许多 好的 博客 介绍了它为何如此出色。StatsD 简单、占用空间小,并且拥有出色的客户端库生态系统。它不会使您的应用程序崩溃,并且已成为大规模指标收集的标准。工作原理
Telegraf 是用 Go 编写的代理,它通过 UDP 接受 StatsD 协议指标,然后定期将指标转发到 InfluxDB。StatsD 指标可以从应用程序中使用许多可用的 客户端库 发送。以下是收集 StatsD 指标的标准设置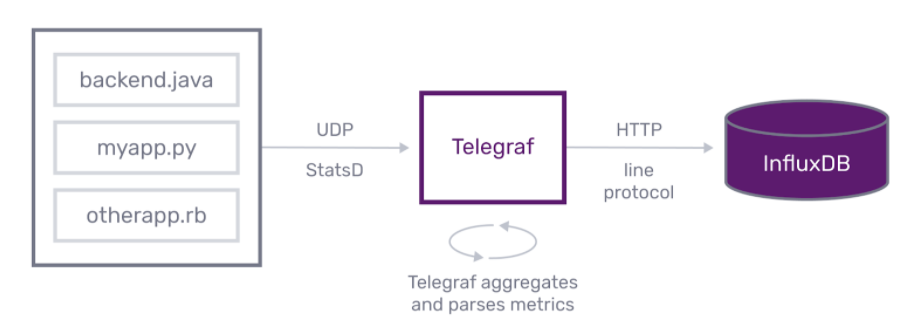
为什么选择 UDP?
UDP 通常被称为“发射后不管”协议。UDP 是一种无连接协议,不等待响应。UDP 数据包在不等待响应的情况下发送,不会因网络延迟而减速,也不会受到可能导致连接中断的网络闪断的影响。这意味着 UDP 是有损的,但这对于指标数据通常是可以接受的。
设置
首先,您需要安装 Telegraf。接下来,您需要使用 statsd 插件设置 Telegraf。--sample-config 选项告诉 Telegraf 输出配置文件。--input-filter 和 --output-filter 告诉 Telegraf 要配置哪些插件 (StatsD) 和输出 (InfluxDB)。(请注意,InfluxDB 2.0 云或 OSS beta 版应使用 influxdb_v2,本地 InfluxDB 2.0 之前版本应使用 influxdb)
$ telegraf --sample-config --input-filter statsd --output-filter influxdb_v2 > telegraf.conf
$ telegraf --config telegraf.conf配置文件 (telegraf.conf) 将假定您的 InfluxDB 实例在 localhost 上运行,如果不是这种情况,则需要对其进行编辑。StatsD 服务器也有许多配置选项,但我不会在本指南中详细介绍所有选项,请参阅文档了解更多详细信息。
发送 StatsD 指标
默认情况下,Telegraf 将开始侦听端口 8125 以接收 UDP 数据包。可以使用 echo 和 netcat 将 StatsD 指标发送到它
$ echo "mycounter:10|c" | nc -C -w 1 -u localhost 8125
或使用您最喜欢的客户端库。
Influx StatsD
由于 InfluxDB 支持标签,我们的 StatsD 实现也支持!向 StatsD 指标添加标签类似于它们在 行协议 中的显示方式。
这意味着您可以像下面这样标记您的 StatsD 指标。此特定指标将 theuser_login counter 递增 1,并带有我们使用的服务和区域的标签。
user.logins,service=payroll,region=us-west:1|c
就是这样!只需添加以逗号分隔的 key=value 格式的标签列表即可。
对于那些使用 StatsD 客户端的用户,可以将这个额外位添加到 bucket 中。我将使用 Python 客户端 作为示例
>>> import statsd
>>> c = statsd.StatsClient('localhost', 8125)
>>> c.incr('user.logins,service=payroll,region=us-west') # Increment counter刷新后,该指标将在 InfluxDB 中以其所有标记荣耀的形式提供。
> SELECT * FROM statsd_user_logins
name: statsd_user_logins
------------------------
time host metric_type region service value
2015-10-27T03:26:40Z tyrion counter us-west payroll 1
2015-10-27T03:26:50Z tyrion counter us-west payroll 1指标
Telegraf 支持所有标准的 StatsD 指标,详细信息如下。
计数器
logins.total:1|c
logins.total:15|c一个简单的计数器,在上面的示例中,logins_total metric 将递增 1 和 15。计数器可以是始终递增的,或者您可以选择使用 delete_counters 配置选项在每次刷新时清除它们。
采样
logins.total:1|c|@0.1 告诉 StatsD 此计数器每 1/10 的时间发送一次采样。在本示例中,logins_total metric 将递增 10。
仪表
current.users:105|g 仪表会随着每个后续发送的值而更改。到达 InfluxDB 的值将是最后记录的值。仪表将保持相同的值,直到发送新值。您可以选择使用 delete_gauges 配置选项在每次刷新时清除它们。
添加符号可以更改仪表的 value,而不是覆盖它
current.users:-10|g
current.users:+12|g计时和直方图
response.time:301|ms
response.time:301|h计时旨在跟踪某事花费的时间。它们是跟踪应用程序性能的宝贵工具。
当 Telegraf 接收到计时指标时,它将聚合它们并将以下统计信息写入 InfluxDB,有关这些统计信息的更多详细信息,请参见文档。
stat_name_lowerstat_name_upperstat_name_meanstat_name_stddevstat_name_countstat_name_percentile_90
采样
response.time:301|ms|@0.1
计时(如计数器)也可以进行采样。这将让 Telegraf 知道此计时仅在每 10 次运行中进行一次。
注意事项
Telegraf 会在指标到达时对其进行聚合,并限制缓存的计时数量以保持其内存占用量较低。默认情况下,Telegraf 在计算百分位数时将跟踪每个统计信息 1000 次计时。可以使用 percentile_limit 配置选项调整此设置。
集合
unique.users:100|s
集合可用于计算唯一事件的次数。在上面的示例中,unique.users 指标将递增 1,然后无论值 100 发送多少次,都不会再递增。
模板
该插件支持指定模板,用于使用关键字将 statsd bucket 转换为 InfluxDB 测量名称、标签和字段。这些模板可用于指定 bucket 中要用于测量名称的部分。模板中的其他单词用作标签名称。例如,以下模板
templates = ["cpu.* measurement.field.region"]
这意味着对于每个以 cpu. 开头的指标,您打算将 bucket 名称拆分为三个段,第一个段属于测量名称,第二个段属于字段,最后一个段将被拆分出来,并转换为名为“region”的标签。如果原始指标如下所示
cpu.load.us-west:100|g
则在 InfluxDB 中创建的指标将如下所示
cpu,metric_type=gauge,region=us-west load=100
其中指标名称为 cpu_load,并且它有一个名为 region 的标签,其值为 us-west。
这使您可以详细控制 StatsD bucket 名称到 influxdb 中指标和标签的映射。
另外,请通过在 GitHub 上打开 issue 让我们知道您希望看到什么。
下一步
- 下载 Telegraf
- 开始 InfluxDB Cloud 的免费试用
