基础设施监控入门
作者:Charles Mahler / 用例, 开发者
2023 年 10 月 11 日
导航至
本文最初发表于 The New Stack,经许可在此转载。
通过利用监控数据,公司可以确保其基础设施以最佳状态运行,同时降低成本。
虽然构建新功能和发布新产品很有趣,但如果您的软件不可靠,这一切都毫无意义。确保您的应用程序顺利运行的关键部分之一是拥有强大的基础设施监控。在本文中,您将了解以下内容
- 基础设施监控的不同组成部分。
- 用于基础设施监控的常用工具。
- 如何为应用程序设置监控。
如果您喜欢视频,也可以查看此演示文稿,其中涵盖了本文讨论的一些主题。
基础设施监控的组成部分
基础设施监控由许多不同的架构组件组成,这些组件是为现代应用程序提供服务所必需的。为了确保软件的可靠性,所有这些组件都需要得到适当的监控。
- 网络监控 — 网络监控侧重于类似硬件的路由器和交换机,并涉及跟踪带宽使用情况、正常运行时间和设备状态等。它用于识别瓶颈、停机时间和潜在的低效网络路由。
- 服务器监控 — 服务器监控侧重于监控物理和虚拟服务器实例的性能和健康状况。CPU、RAM 和磁盘利用率等指标很常见。服务器监控对于容量规划非常重要。
- 应用程序性能监控 (APM) — APM 侧重于软件,用于跟踪应用程序在从 UI 到数据存储方式的每一层的性能。常见的指标包括错误率和响应时间等。
- 云基础设施监控 — 云监控,顾名思义,是关于监控云基础设施,如数据库、不同类型的存储和虚拟机。目标是跟踪可用性和性能,以及资源利用率,以防止云硬件的过度或不足配置。
每种类型的监控都充当团队查看和管理其基础设施的不同视角。通过利用所有这些数据,公司可以确保其基础设施以最佳状态运行,同时降低成本。
基础设施监控工具
在创建基础设施监控系统时,为工作选择合适的工具至关重要。有许多开源和商业选项可供选择。您还可以选择全方位服务解决方案,或者通过组合专用工具来创建自己的自定义解决方案。无论如何,有三个主要问题需要考虑:您将如何收集数据,如何存储数据以及您将如何处理数据?让我们看一下可用于完成每一项任务的一些工具。
数据收集工具
基础设施监控的最大挑战之一是收集可能来自许多不同来源的数据,这些数据通常没有标准化的协议或 API。这里的关键目标应该是选择一种工具,该工具可以使您不必重新发明轮子,不会将您锁定,并且是可扩展的,以便您可以随着应用程序的更改而扩展或修改数据收集。
Telegraf
Telegraf 是一个开源服务器代理,非常适合基础设施监控数据收集。Telegraf 解决了上述大多数问题。它有 300 多个不同的输入和输出插件,这意味着您可以轻松地从新来源收集数据,并将数据输出到最适合您用例的存储解决方案。
结果是,Telegraf 通过不必编写自定义代码来收集数据,为您节省了大量工程资源,并防止了供应商锁定,因为您可以轻松更改存储输出。Telegraf 还具有用于数据处理和转换的插件,因此在某些用例中,它可以通过替换流处理工具来简化您的架构。
OpenTelemetry
OpenTelemetry 是一组开源 SDK 和工具,可以轻松地从应用程序收集指标、日志和跟踪。OpenTelemetry 的主要优势在于它与供应商无关,因此您不必担心被锁定在使用成本高昂的 APM 工具中,并且切换成本很高。OpenTelemetry 还通过提供使应用程序检测数据收集变得容易的工具,从而节省了开发人员的时间。
数据存储工具
在您开始从基础设施收集数据后,您需要一个地方来存储这些数据。虽然通用数据库可以用于此数据,但在许多情况下,您需要寻找更专业的数据库,该数据库专为处理为基础设施监控收集的时间序列数据类型而设计。以下是一些可用的选项
InfluxDB
InfluxDB 是一个开源时间序列数据库,旨在存储和分析大量时间序列数据。它提供高效的存储和检索功能、可扩展性以及对实时分析的支持。借助InfluxDB,您可以轻松捕获和存储来自各种来源的指标,使其非常适合监控和分析基础设施的性能和健康状况。
Prometheus
Prometheus 是一个开源监控和警报工具包,专为收集和存储指标数据而构建。它专门设计用于监控动态和云原生环境。Prometheus 提供灵活的数据模型和强大的查询语言,使其非常适合存储基础设施监控数据。凭借其内置的警报和可视化功能,Prometheus 使您能够深入了解基础设施的性能和可用性。
Graphite
Graphite 是一个时间序列数据库和可视化工具,专注于存储和渲染监控数据的图形。它广泛用于监控和绘制各种指标,使其成为存储基础设施监控数据的合适选择。Graphite 擅长可视化时间序列数据,使您能够创建交互式和可自定义的仪表板来监控基础设施的性能和趋势。其可扩展的架构和广泛的插件生态系统使其成为监控和分析基础设施指标的流行选择。
数据分析工具
一旦您存储了数据,就到了有趣的部分,实际上是用它做一些事情来创造价值。以下是一些可用于分析数据的工具。
Grafana
Grafana 是一款功能强大的开源数据可视化和分析工具,允许用户创建、探索和共享交互式仪表板。它通常用于通过连接到各种数据源(如数据库、API 和监控系统)来分析基础设施监控数据。借助Grafana,用户可以创建可视化效果、设置警报并深入了解其基础设施指标、日志和跟踪。
Apache Superset
Apache Superset 是一款现代化的企业级商业智能 Web 应用程序,使用户能够探索、可视化和分析数据。它为创建交互式仪表板、图表和报告提供了用户友好的界面。在分析基础设施监控数据时,Apache Superset 可用于连接到监控系统、数据库或其他数据源,以探索和可视化关键指标、生成报告并深入了解基础设施的性能和健康状况。
Jaeger
Jaeger 是一个开源的端到端分布式跟踪系统,可帮助用户监控和排除复杂的微服务架构的故障。它可以通过提供对基础设施不同组件之间交互和依赖关系的详细见解来用于分析基础设施监控数据。Jaeger 捕获并可视化跟踪,这些跟踪代表请求在系统中传输的路径,从而使用户能够识别基础设施中的瓶颈、延迟问题和性能优化。
基础设施监控教程
现在让我们看一个如何为应用程序实现监控系统的示例。本教程将重点介绍称为 TIG 堆栈的开源工具组合:Telegraf、InfluxDB 和 Grafana。TIG 堆栈使开发人员可以轻松构建一个长期可扩展的基础设施监控解决方案。
架构概览
本教程的示例应用程序是一个聊天应用程序,由 AI 模型驱动,该模型根据用户输入返回响应。该应用程序具有混合架构,后端托管在 AWS 上,而 AI 模型在云外部的专用 GPU 上运行。主要挑战是在确保服务可靠性的同时,还要由于用户快速增长而扩展基础设施。这样做需要收集大量数据以实时跟踪资源利用率,以进行监控以及基于用户增长的未来容量规划。
基础设施监控设置
现在让我们看一下如何为这个应用程序设置和配置监控。第一步是配置 Telegraf 以从我们基础设施的每个部分收集我们想要的数据。我们将利用以下 Telegraf 插件
- SNMP 输入 — SNMP 插件用于收集网络监控所需的指标。
- CPU、磁盘、Nvidia SMI、DiskIO、内存、交换、系统输入 — 这些插件用于收集服务器监控指标。
- OpenTelemetry 输入 — OpenTelemetry 用于收集应用程序性能指标,如日志、指标和跟踪。
- AWS Cloudwatch 输入 — AWS CloudWatch 插件可以轻松地从 AWS 收集我们需要的所有云基础设施指标。
- InfluxDB V2 输出 — InfluxDB 输出插件会将所有这些收集的指标发送到指定的 InfluxDB 实例。
这是此设置的 Telegraf 配置 TOML 文件的示例
[global_tags]
# dc = "us-east-1" # will tag all metrics with dc=us-east-1
# rack = "1a"
# user = "$USER"
[agent]
interval = "10s"
round_interval = true
metric_batch_size = 1000
metric_buffer_limit = 10000
collection_jitter = "0s"
flush_interval = "10s"
flush_jitter = "0s"
precision = ""
# debug = false
# quiet = false
# logtarget = "file"
# logfile = ""
# logfile_rotation_interval = "0d"
# logfile_rotation_max_size = "0MB"
# logfile_rotation_max_archives = 5
hostname = ""
omit_hostname = false
[[inputs.snmp]]
agents = ["udp://127.0.0.1:161"].
timeout = "15s"
version = 2
community = "SNMP"
retries = 1
[[inputs.snmp.field]]
oid = "SNMPv2-MIB::sysUpTime.0"
name = "uptime"
conversion = "float(2)"
[[inputs.snmp.field]]
oid = "SNMPv2-MIB::sysName.0"
name = "source"
is_tag = true
[[inputs.cpu]]
percpu = true
totalcpu = true
collect_cpu_time = false
report_active = false
[[inputs.disk]]
ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"]
[[inputs.diskio]]
[[inputs.mem]]
[[inputs.processes]]
[[inputs.swap]]
[[inputs.system]]
[[nvidia-smi]]
[[inputs.opentelemetry]]
service_address = "0.0.0.0:4317"
timeout = "5s"
metrics_schema = "prometheus-v2"
tls_cert = "/etc/telegraf/cert.pem"
tls_key = "/etc/telegraf/key.pem"
[[inputs.cloudwatch_metric_streams]]
service_address = ":443"
[[inputs.cloudwatch]]
region = "us-east-1"
[[outputs.influxdb_v2]]
urls = ["http://127.0.0.1:8086"]
## Token for authentication.
token = ""
## Organization is the name of the organization you wish to write to.
organization = ""
## Destination bucket to write into.
bucket = ""
## The value of this tag will be used to determine the bucket. If this
## tag is not set the 'bucket' option is used as the default.
# bucket_tag = ""
## If true, the bucket tag will not be added to the metric.
# exclude_bucket_tag = false
## Timeout for HTTP messages.
# timeout = "5s"
## Additional HTTP headers
# http_headers = {"X-Special-Header" = "Special-Value"}
## HTTP Proxy override, if unset values the standard proxy environment
## variables are consulted to determine which proxy, if any, should be used.
# http_proxy = "http://corporate.proxy:3128"此 Telegraf 配置通过收集所有指定数据并将其发送到 InfluxDB 进行存储,从而处理数据收集和数据存储步骤。让我们回顾一下您可以使用这些数据的一些方法。
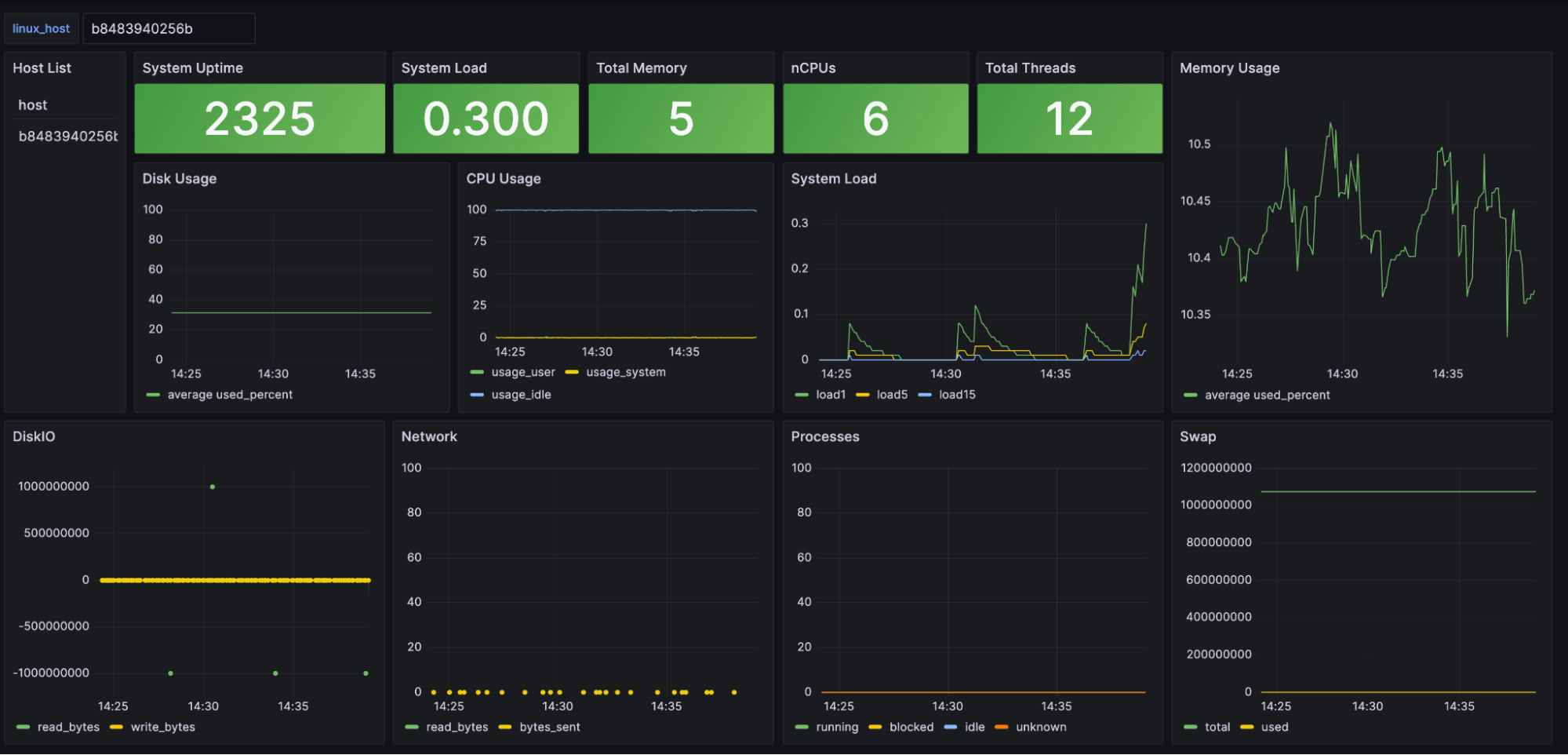
数据可视化
许多公司的第一步是为其基础设施监控系统创建仪表板和数据可视化。这些仪表板可用于从高级报告到工程师实时监控事物的详细分析的任何内容。这是一个使用为本教程收集的数据构建的 Grafana 仪表板示例
警报
虽然仪表板很好,但要大规模手动跟踪基础设施中发生的一切是不可能的。为了解决这个问题,设置自动化警报是基础设施监控系统的常见功能。这是一个 Grafana 如何用于为指标设置值阈值并在违反这些阈值时创建自动化警报的示例。
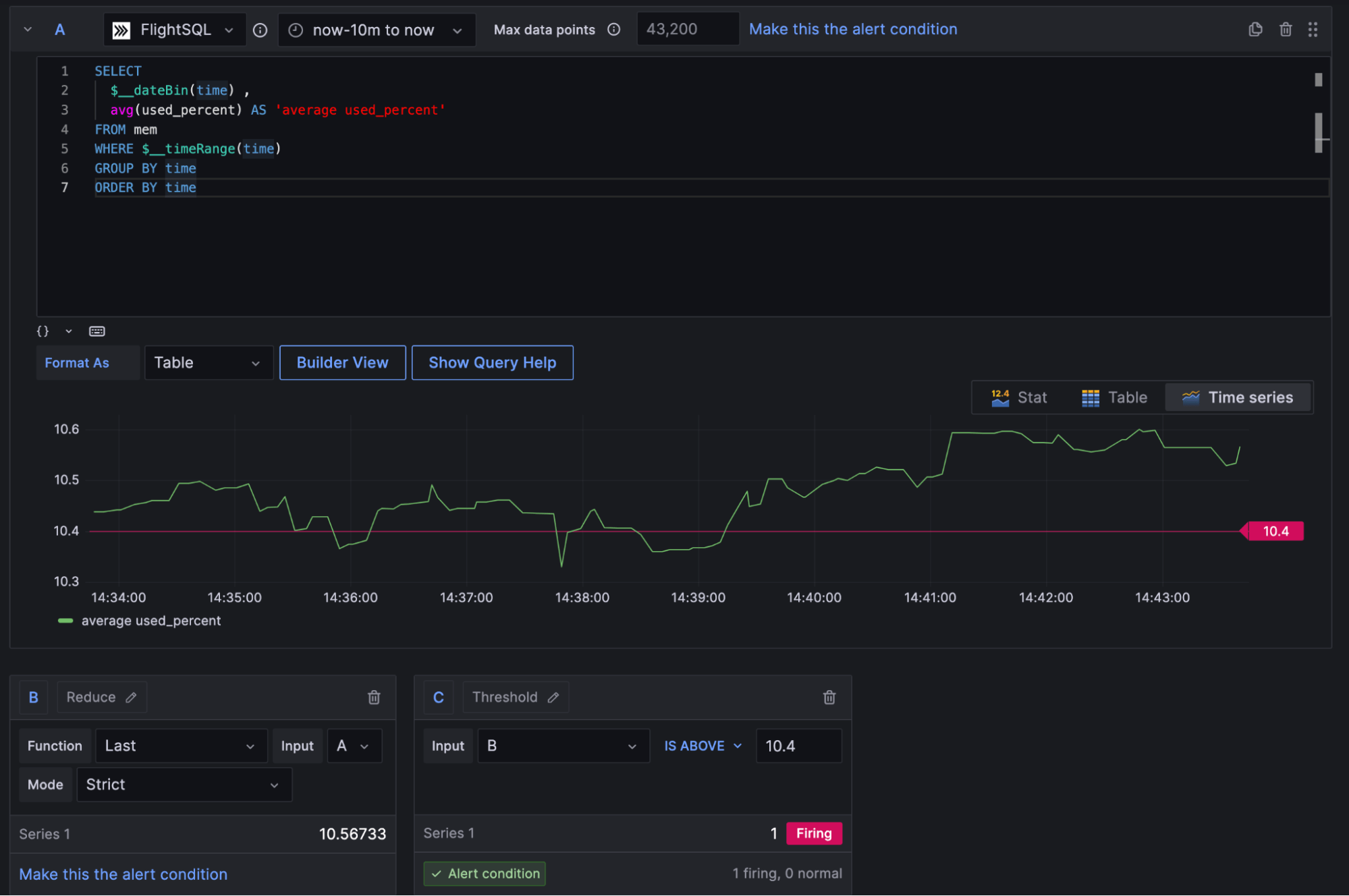
Grafana 与 PagerDuty 和 Slack 等第三方工具集成,以便在出现问题时可以通知工程师。在某些情况下,像这样的警报可以用于完全自动化某些操作,例如在硬件利用率达到一定水平时自动扩展云容量。
预测分析和预测
预测分析和预测可能是许多工程团队的理想最终目标。虽然警报是一种反应式方法,仅在出现问题后才起作用,但预测分析和预测使您可以在问题发生之前采取措施。创建准确的预测显然说起来容易做起来难,但是如果做得正确,它会带来巨大的好处。
后续步骤
希望本文能帮助您更好地了解基础设施监控以及一些可用于构建自己的系统的工具。如果您想使用一些真实数据进行操作,可以查看以下资源
