InfluxDB 和 Pandas 入门
作者:Anais Dotis-Georgiou / 产品, 用例, 开发者, 入门
2020 年 1 月 16 日
导航至
InfluxData 以优先考虑开发者幸福感而自豪。维护开发者幸福感的一个重要部分是提供客户端库,允许用户通过他们选择的语言和库与数据库进行交互。数据分析是与 Python 用例最广泛相关的任务,占 Python 任务的 58%,因此 Pandas 成为 Python 用户第二流行的库 是有道理的。2.0 InfluxDB Python 客户端数据支持 Pandas DataFrames,以邀请数据科学家轻松使用 InfluxDB。
在本教程中,我们将学习如何查询 InfluxDB 实例并将数据作为 DataFrame 返回。我们还将探索作为客户端 repo 一部分存在的一些数据科学资源。要了解如何开始使用 InfluxDB Python 客户端库,请查看这篇 博客。

数据科学资源
InfluxDB Python 客户端 repo 中包含各种数据科学资源,以帮助您利用客户端的 Pandas 功能。我鼓励您查看示例 notebooks。它们是 Jupyter Notebooks 的集合,提供了各种时序数据科学和分析解决方案的示例,例如,如何集成 Tensorflow 和 Keras 进行预测。
从 InfluxDB 到 DataFrame
导入客户端和 Pandas
from influxdb_client import InfluxDBClient
import pandas as pd提供身份验证参数
my_token = my-token
my_org = "my-org"
bucket = "system"编写您的 Flux 查询
query= '''
from(bucket: "system")
|> range(start:-5m, stop: now())
|> filter(fn: (r) => r._measurement == "cpu")
|> filter(fn: (r) => r._field == "usage_user")
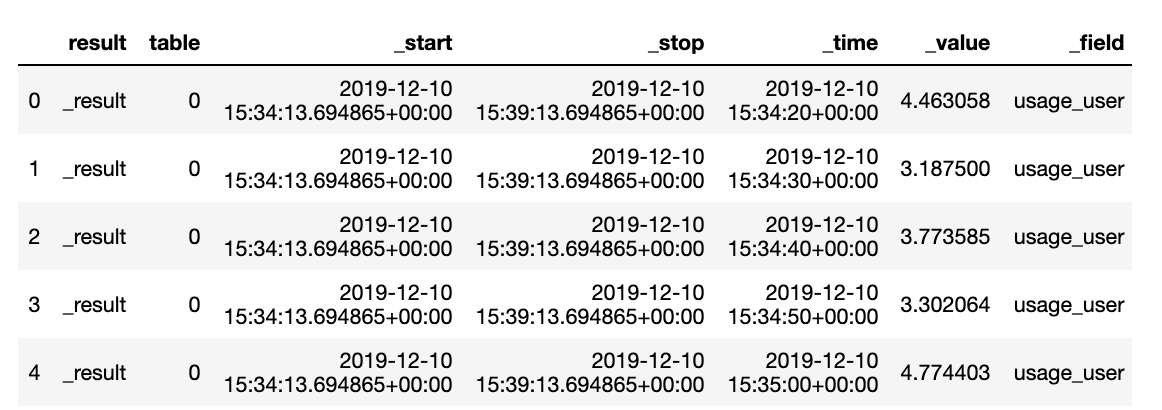
|> filter(fn: (r) => r.cpu == "cpu-total")'''查询 InfluxDB 并返回 Dataframe
client = InfluxDBClient(url="https://:9999", token=my_token, org=my_org, debug=False)
system_stats = client.query_api().query_data_frame(org=my_org, query=query)
display(system_stats.head())从 DataFrame 到 InfluxDB
将 DataFrame 写入 InfluxDB:
from influxdb_client import InfluxDBClient, Point, WriteOptions
from influxdb_client.client.write_api import SYNCHRONOUS
# Preparing Dataframe:
system_stats.drop(columns=['result', 'table','start','stop'])
# DataFrame must have the timestamp column as an index for the client.
system_stats.set_index("_time")
_write_client.write(bucket.name, record=system_stats, data_frame_measurement_name='cpu',
data_frame_tag_columns=['cpu'])
关闭客户端
_write_client.__del__()
client.__del__()Pandas 与 Flux 互补,用于 InfluxDB
尽管 Flux 具有 Pandas 的许多数据转换功能,但 InfluxDB 重视开发者的时间。如果您处理的是较小的数据集,您可能没有太多动力在服务器端进行这些转换或学习 Flux。希望这种 Pandas 功能可以帮助您更快地执行 时序分析。与往常一样,如果您遇到障碍,请在我们的 社区网站 或 Slack 频道上分享。我们很乐意获得您的反馈并帮助您解决遇到的任何问题。
