InfluxDB 2.0 入门指南:采集指标、运行 Telegraf、查询数据和写入数据
作者:Sonia Gupta / 产品, 用例, 开发者, 入门指南
2019 年 5 月 6 日
导航至
既然我们已经发布了 InfluxDB 2.0 Alpha 版本,您可能很想尝试一下,但可能不知道从哪里开始。本文将指导您完成在本地机器上运行它的过程。在本文结束时,您将对 2.0 与 1.x 区分开来的一些新功能有一个很好的了解,并且您将能够轻松加载数据和浏览 UI。
使用 InfluxDB 2.0 采集指标
首先,导航到入门指南文档,并按照说明下载 Alpha 版本或运行带有 Alpha 版本的 Docker 容器。您可以在 Linux 或 Mac 上原生运行 2.0,但如果您使用的是 Windows,则需要使用 Docker 容器。要运行 Docker 容器,您需要在您的机器上安装 Docker。为了本教程的目的,我选择下载 Alpha 版本并原生运行它。
一旦您运行了 InfluxDB,无论是通过运行 influxd 命令还是运行 Docker 容器,导航到 https://:9999 ,您应该会看到此页面

点击“开始使用”将带您到此页面
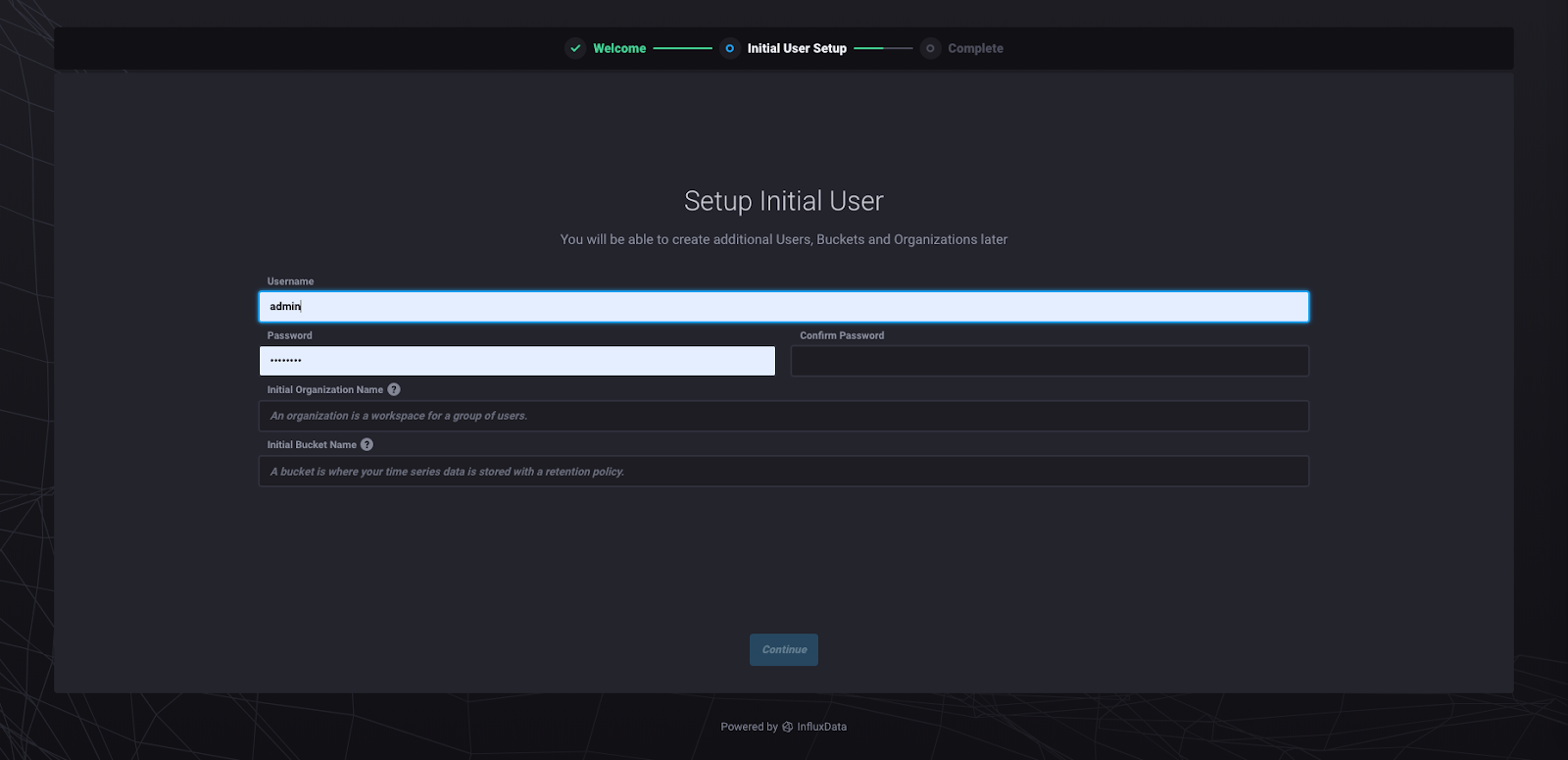
我建议将您的组织命名为“InfluxData”,以便您可以按照我将要向您展示的内容进行操作。组织是 2.0 中组织数据和查询的保护伞。存储桶相当于数据库。您可以选择您喜欢的任何存储桶名称、用户名和密码。点击“继续”将带您到此页面
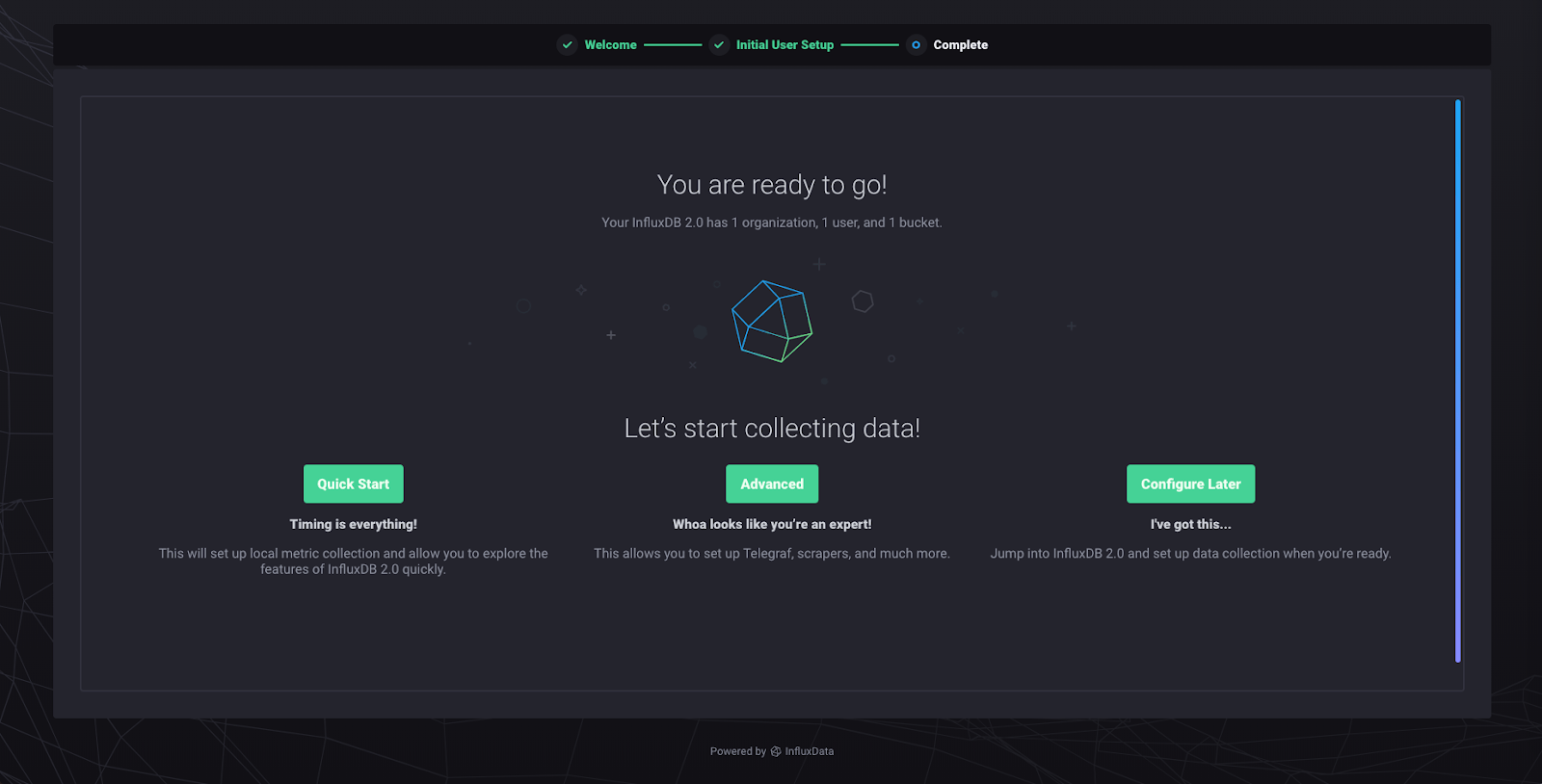
“快速入门”选项配置数据采集器。数据采集器将从您的本地 InfluxDB 2.0 实例中拉取指标。这是开始使用一些数据进行操作的最快方法。“高级”将您带到 Telegraf 代理配置区域。“稍后配置”将您带到主页,而无需创建任何内容。点击“快速入门”,您将被带到以下页面
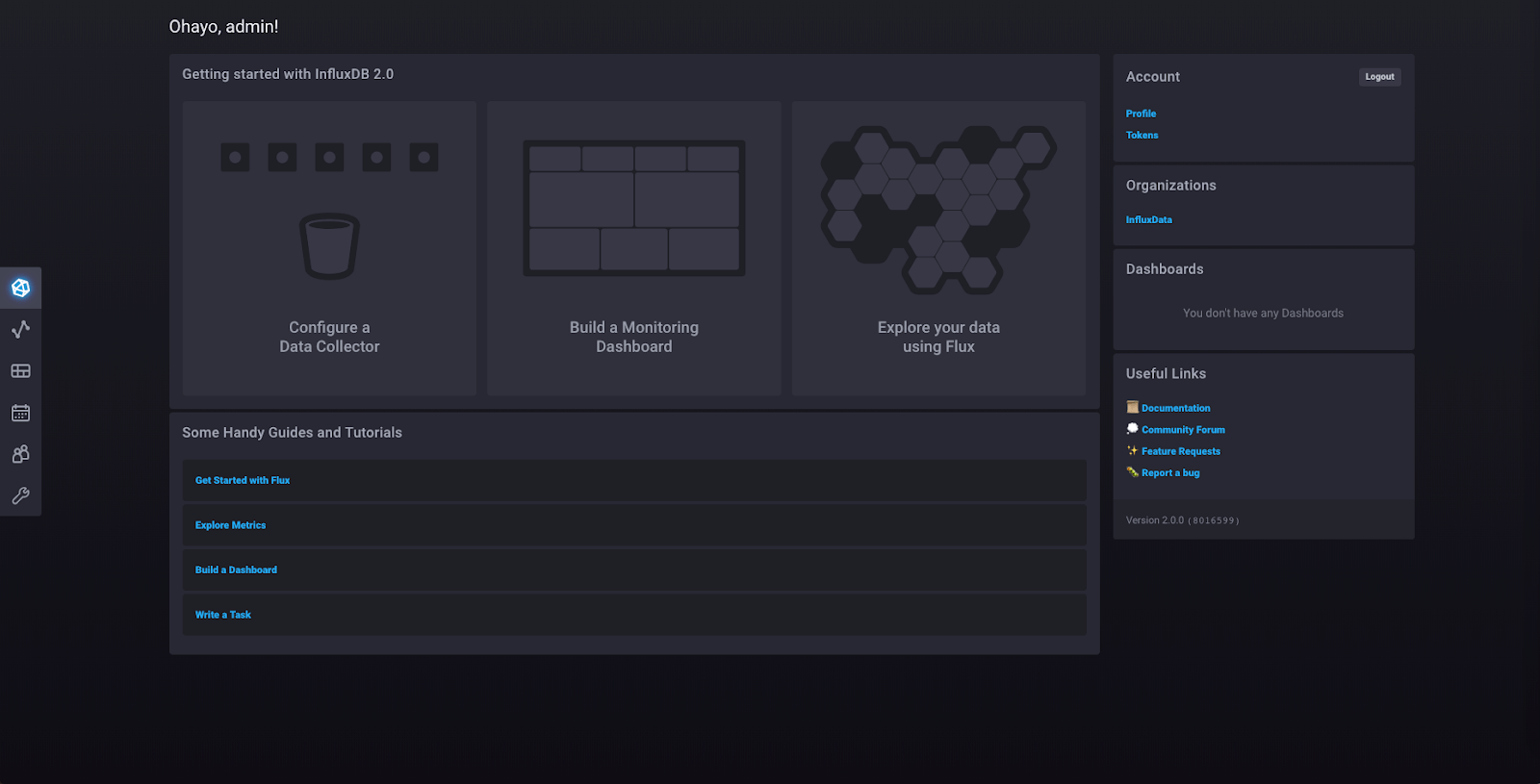
这是主页,您可以从中访问 InfluxDB 2.0 实例的每个部分。您可以从此处访问您的组织、仪表板和文档。
点击左侧边栏中的“数据浏览器”,您将被带到此视图
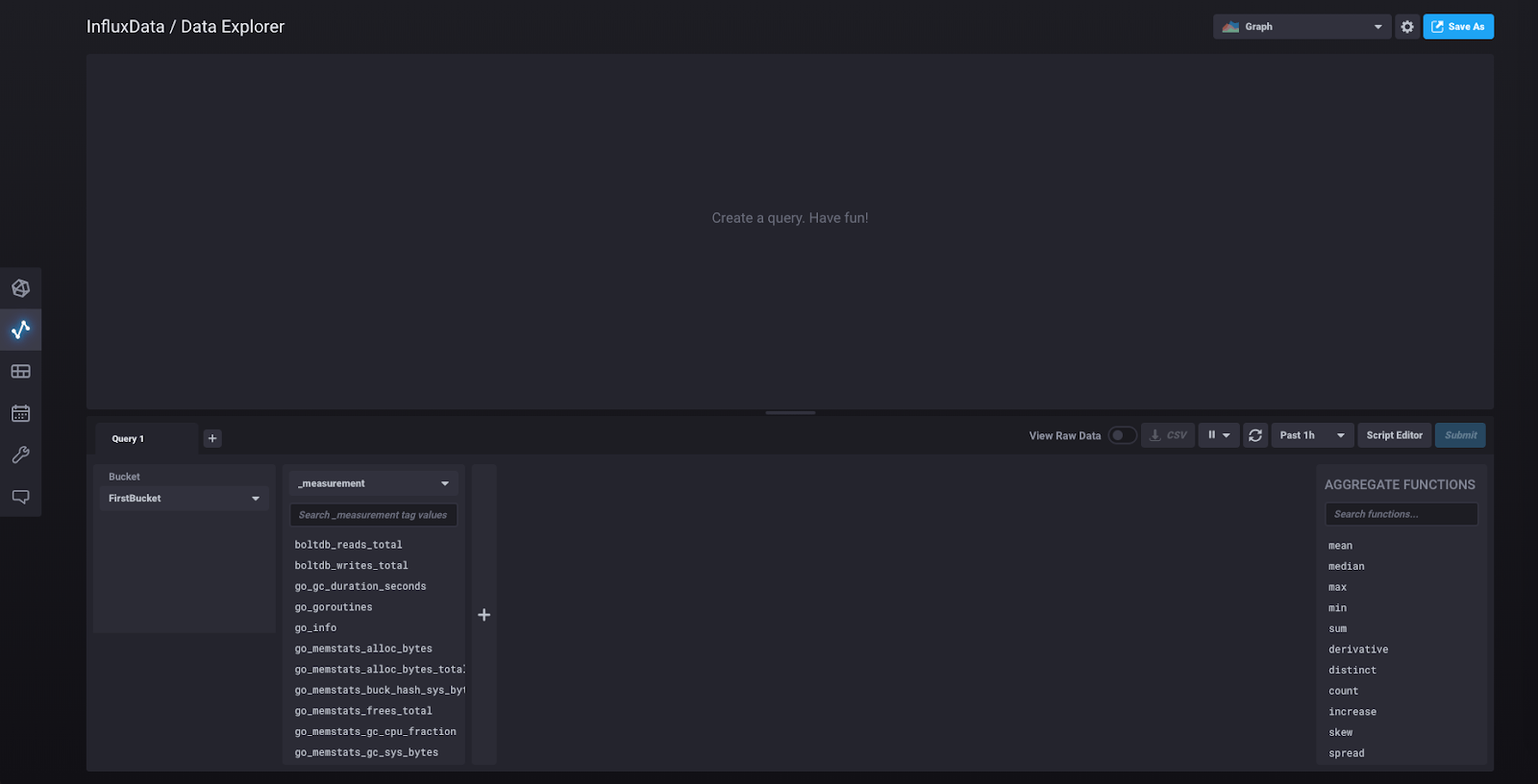
您在下半部分第二列中看到的是从采集器收集的数据的度量,该采集器在您点击“快速入门”时自动初始化。该采集器通过从 localhost:9999/metrics 拉取指标来收集有关 InfluxDB 2.0 实例的数据,您可以访问该链接以查看 Prometheus 数据格式的这些指标。
我们只是要选择一个任意的数据系列。点击“boltdb_reads_total”,这将打开一个块,其中包含与该度量相关的字段。在“_field”标题下,点击“counter”,然后点击“提交:”
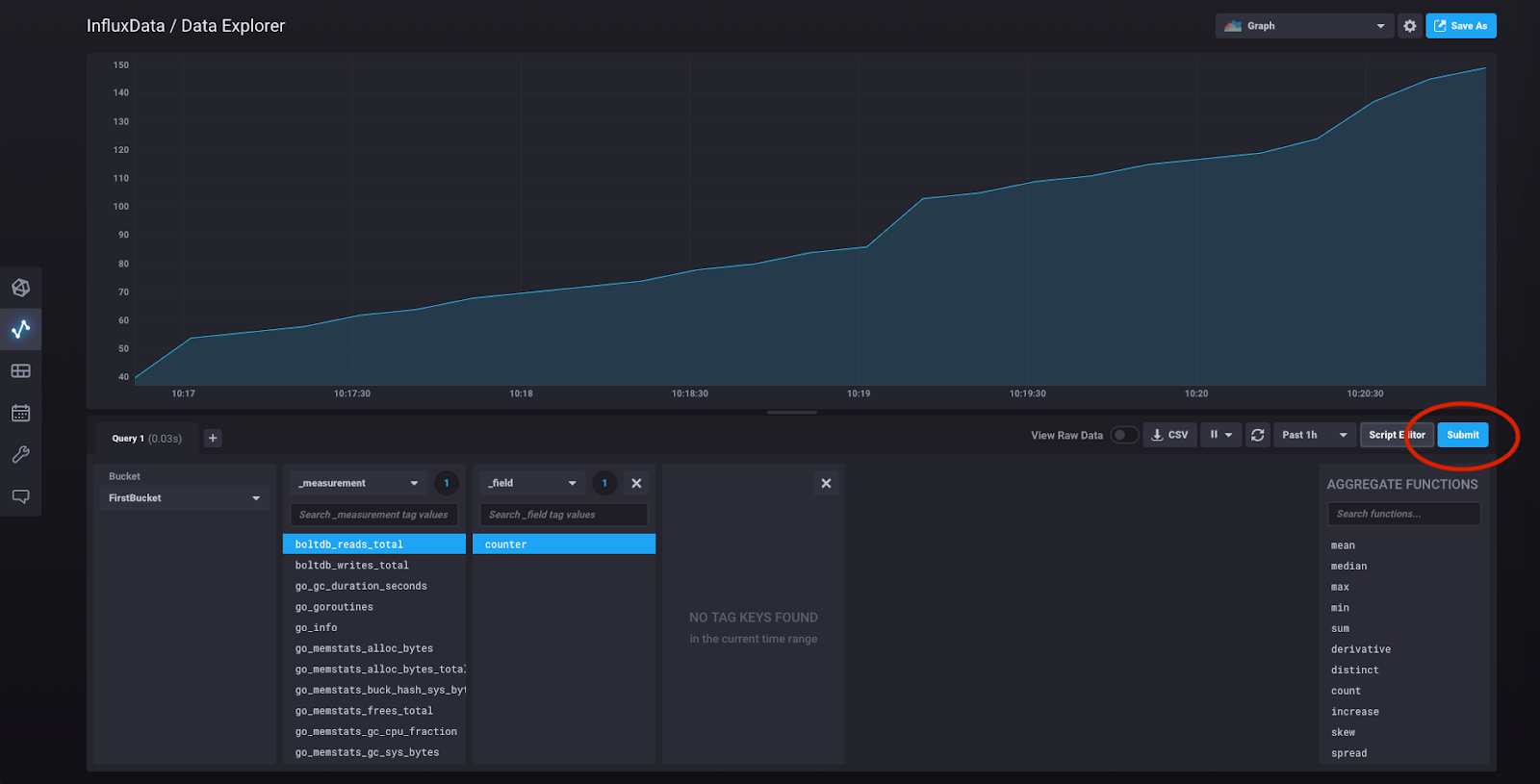
恭喜您!您刚刚使用查询构建器构建了您的第一个查询,而您现在看到的是该查询结果的可视化。
但是,如果您想看到更好的可视化系列,请点击侧边栏中的“仪表板”,您将看到“本地指标”,这是一个从采集器收集的指标创建的预定义仪表板。点击它,您应该会看到类似这样的内容
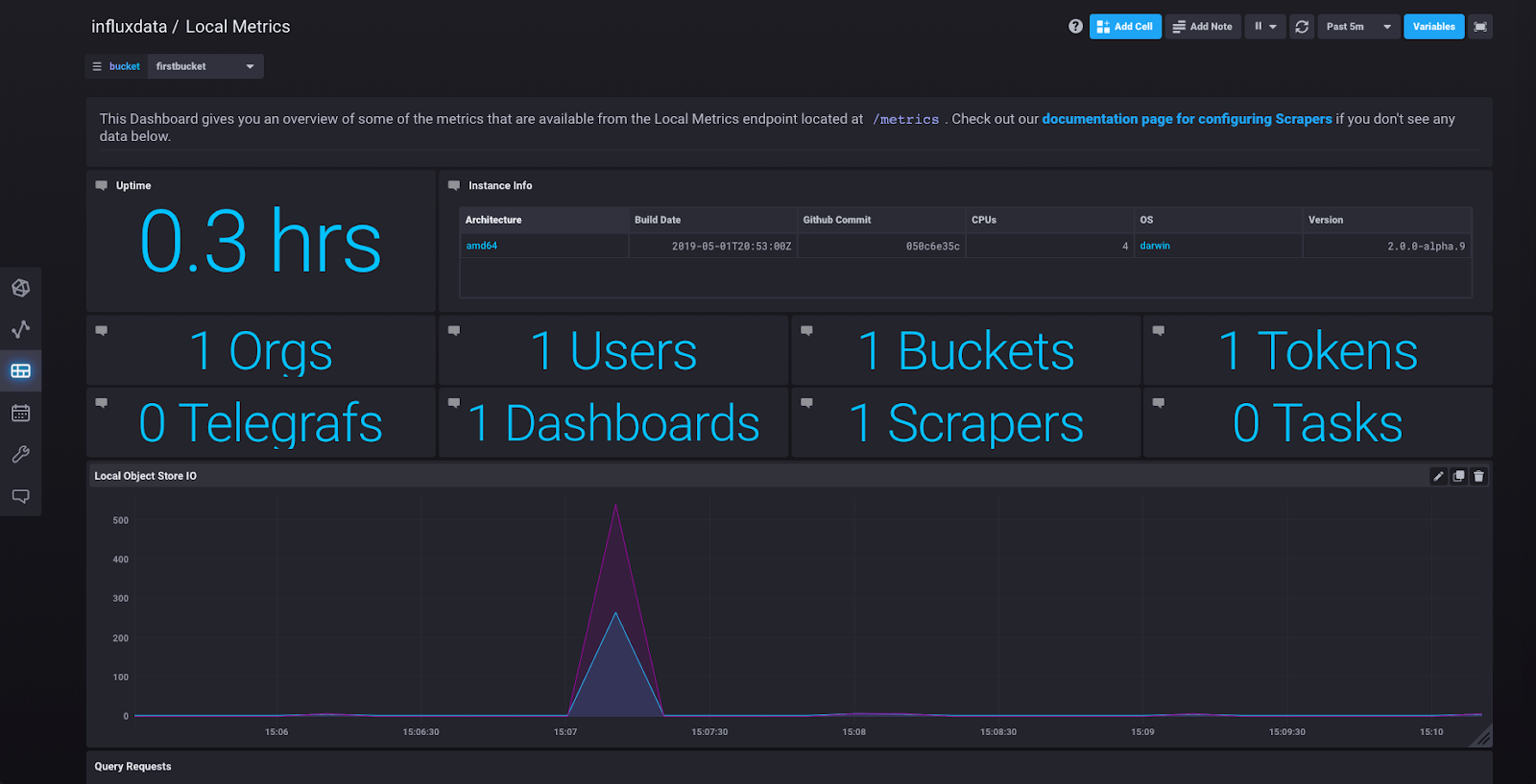
使用 InfluxDB 2.0 运行 Telegraf
现在我们将创建一个存储桶,设置 Telegraf 代理,并查看显示代理收集的数据的仪表板。点击左侧边栏中的“设置”,然后点击“存储桶”。然后点击“创建存储桶”,并创建一个新存储桶,该存储桶将存储 Telegraf 代理收集的所有时间序列数据
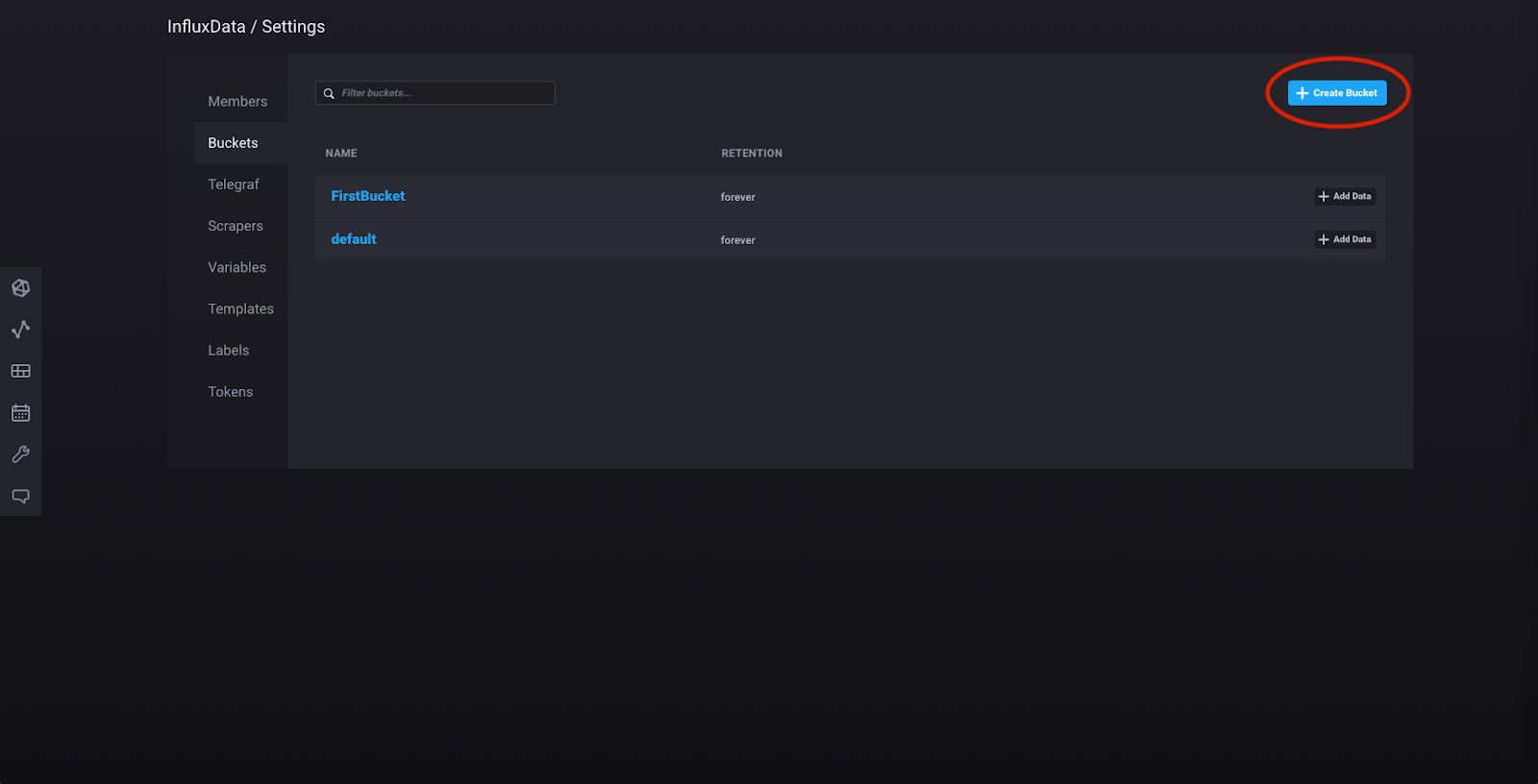
现在点击左侧边栏中的“admin”,然后点击“配置数据收集器”,这将带您到此页面
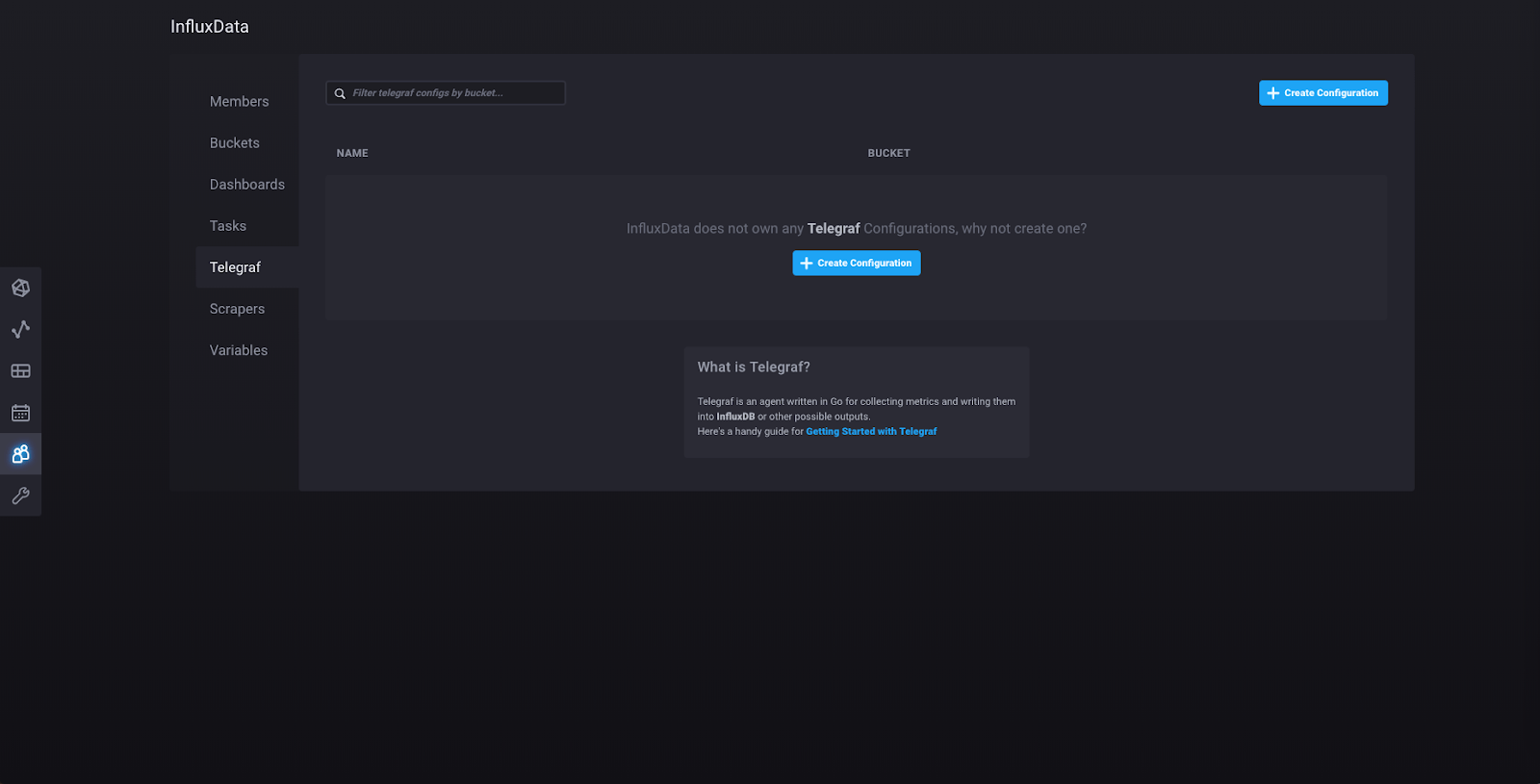
点击“创建配置”,您将被带到此页面,您将在此页面看到 2.0 中当前可用的插件集合。随着 2.0 的进一步开发,将添加更多集合。选择“系统”插件集合(确保点击左侧的“存储桶”下拉菜单,并选择您刚刚创建的存储桶)
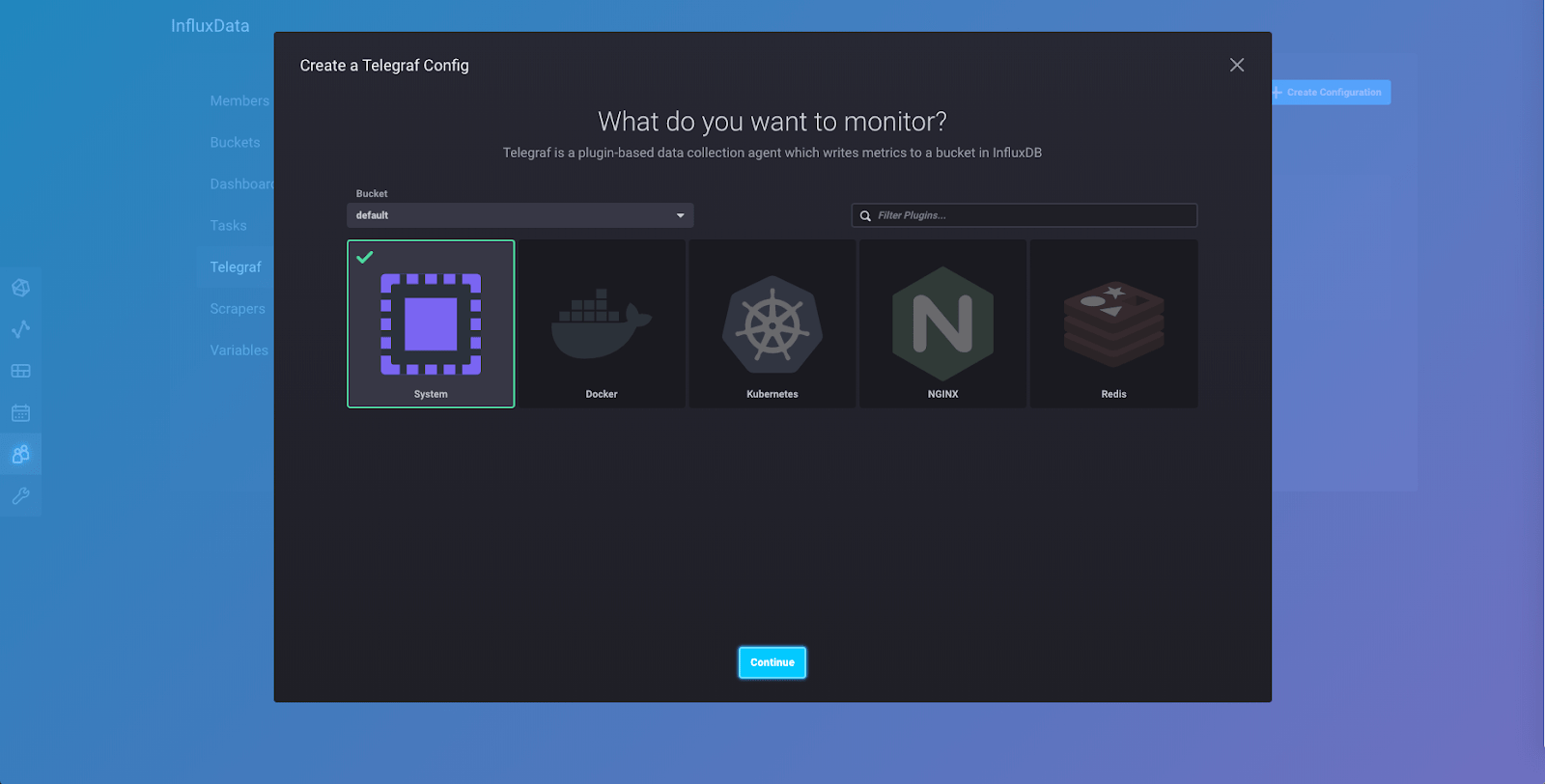
“系统”插件集合从您的 Linux 机器收集指标,并且是开始操作数据以便您了解 InfluxDB 2.0 如何工作的最佳方法之一。点击“继续”,您将被带到此页面
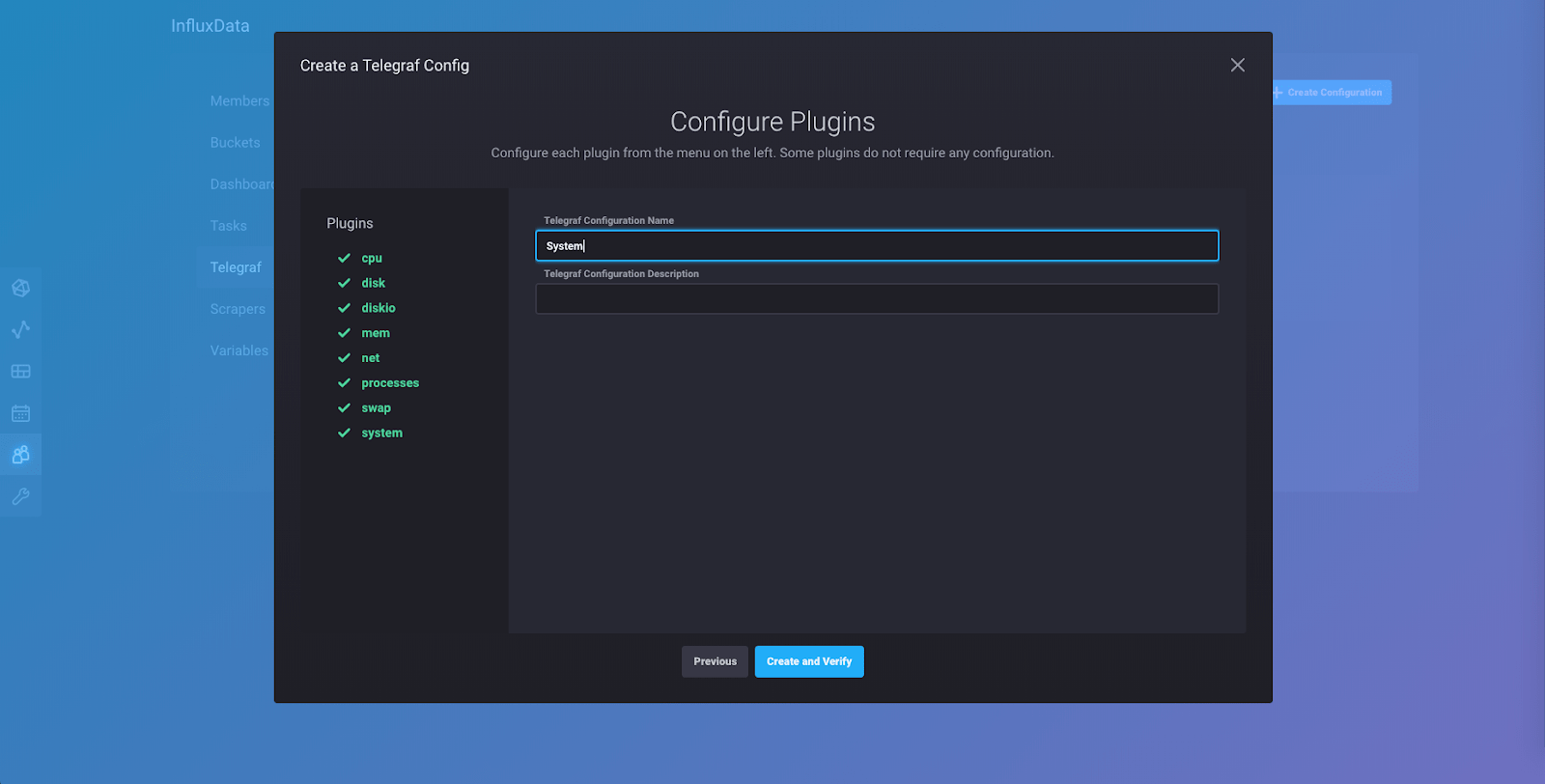
继续并将您的配置命名为“System”,以便您可以按照本教程进行操作。您可以将描述留空。点击“创建并验证”,您将被带到此页面
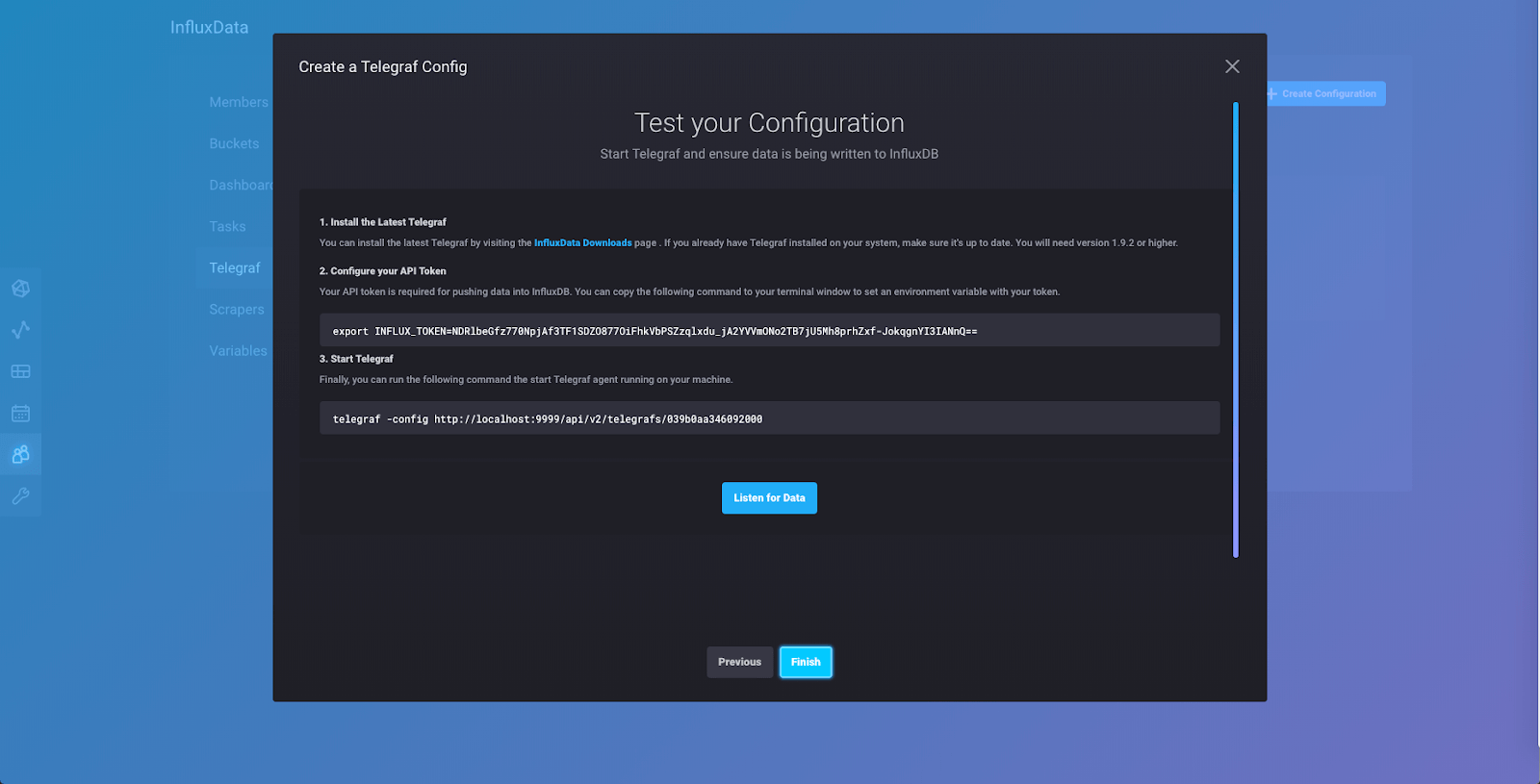
如果您尚未安装 Telegraf,现在是安装的时候了。您可以点击链接访问下载页面,并按照那里的说明安装 Telegraf,具体取决于您的系统以及您是否要使用 Docker。
安装 Telegraf 后,您将需要使用您的 telegraf 导出令牌设置一个环境变量,如步骤 2 中所述。导出令牌是一种安全的方式,可为另一个应用程序提供写入数据到您的实例的权限。打开一个新的终端选项卡,然后将步骤 2 中的命令复制并粘贴到该选项卡的提示符中。
在同一个选项卡中(您现在应该打开两个选项卡,第一个选项卡是 Alpha 从您的下载或 Docker 容器中运行的位置),您将运行步骤 3 中的命令。

这将启动 Telegraf 代理,该代理将使用我们之前选择的“系统”输入插件集合从您的计算机收集指标。
点击“监听数据”,如果一切都正确连接,您将收到“连接已找到!”通知并看到此页面
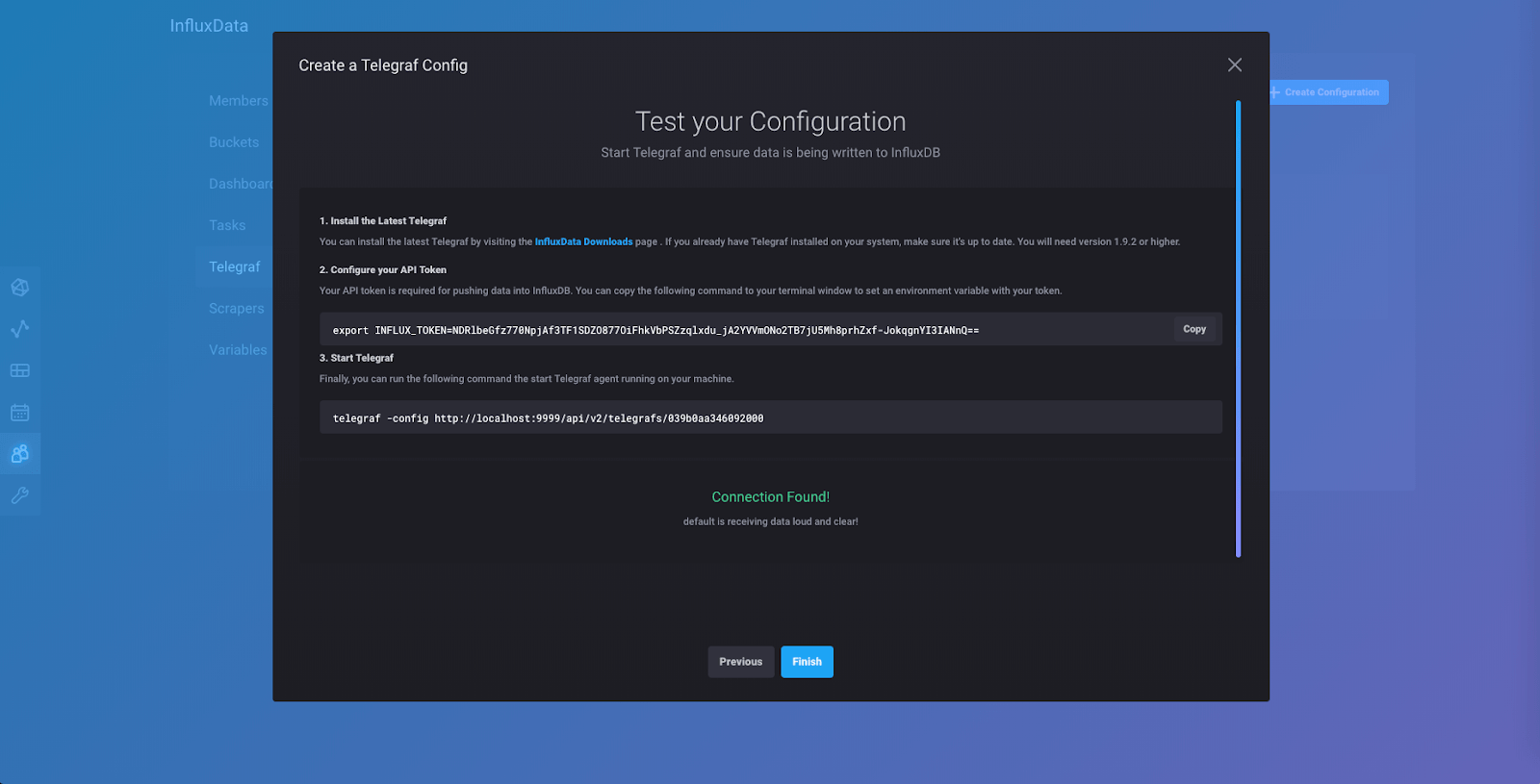
点击“完成”,您将被带到此页面
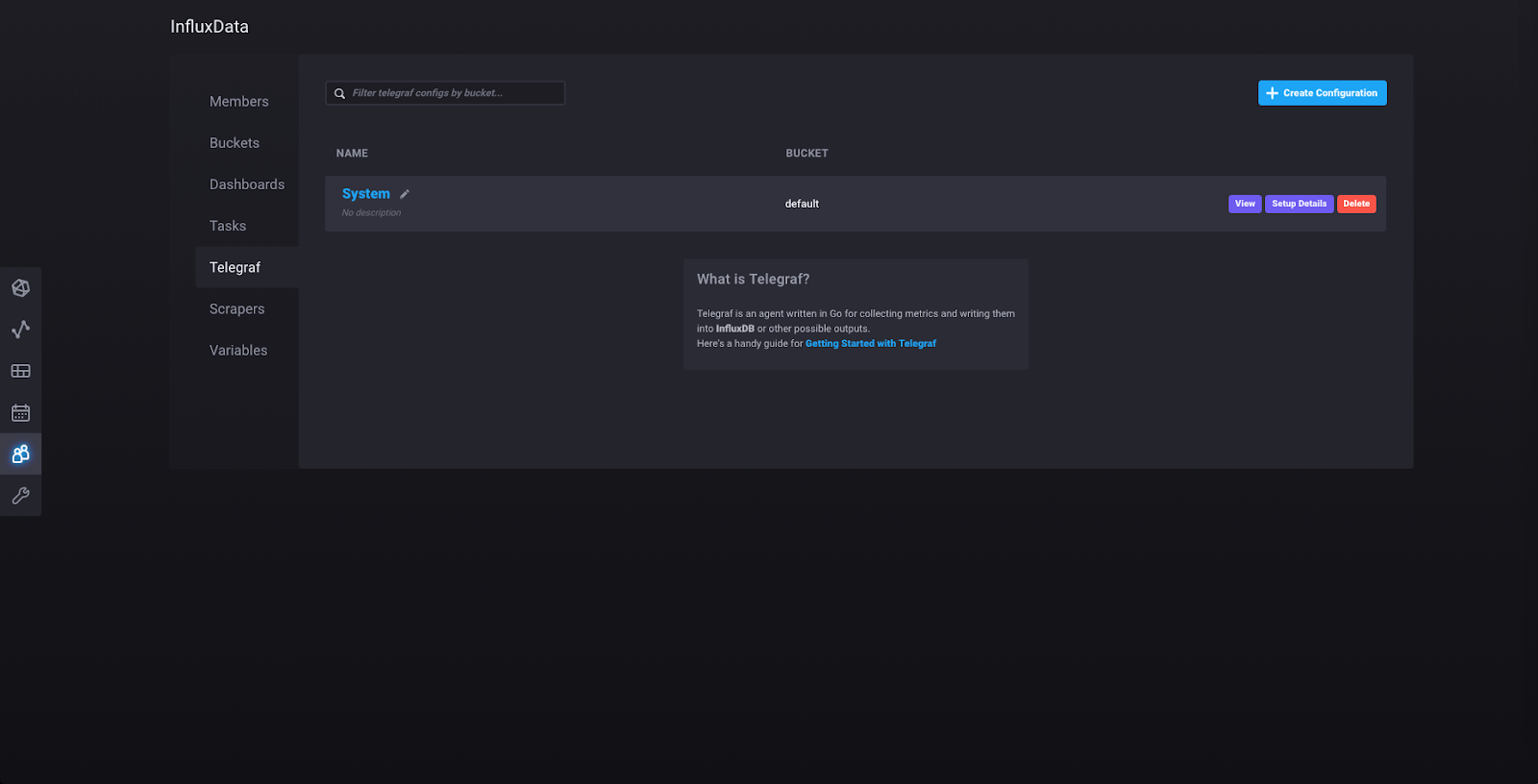
在这里,您可以看到您刚刚创建的 Telegraf 配置。点击配置的名称(“System”)将显示配置文件
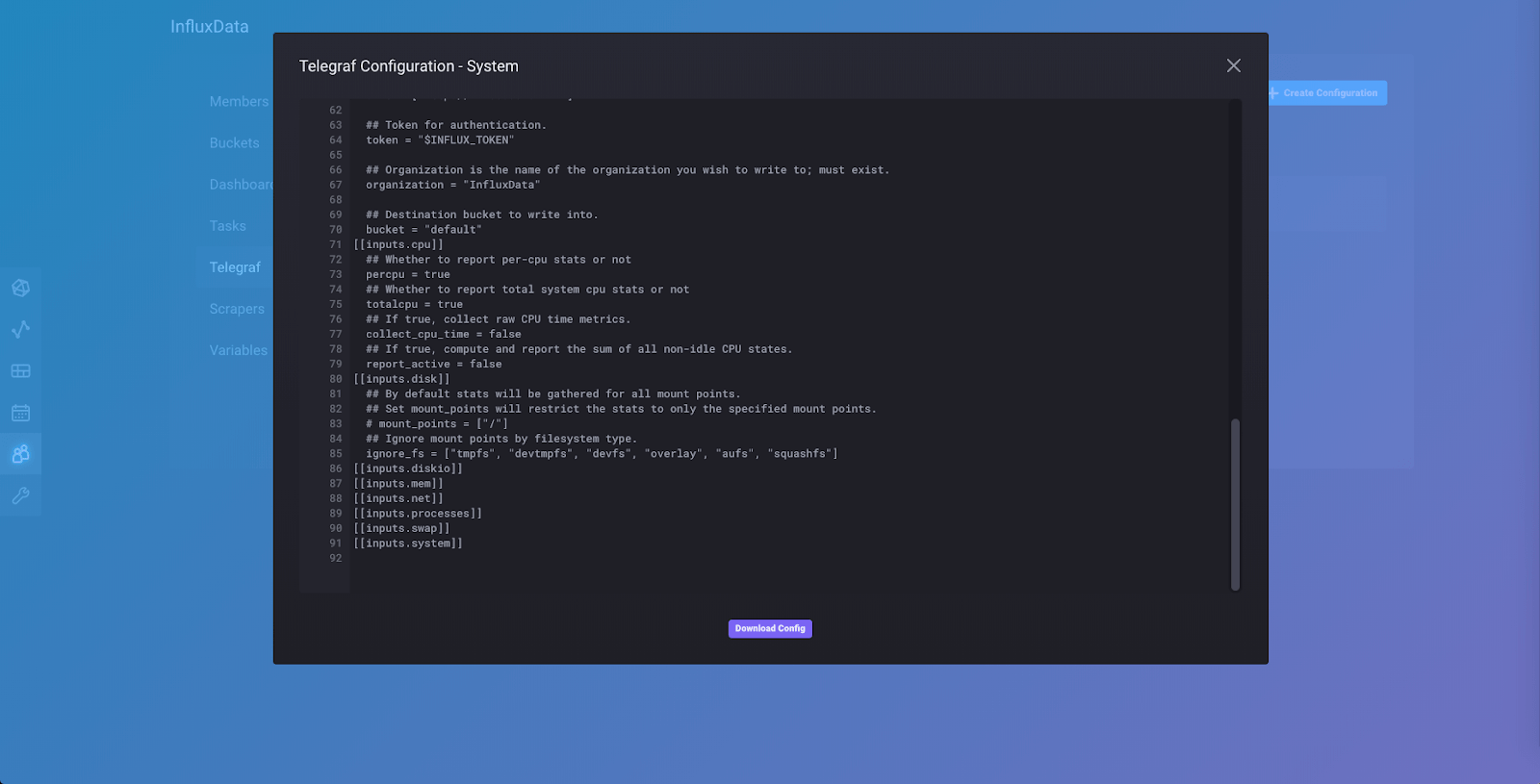
如果您向下滚动到配置文件的底部,您将看到我们添加到配置文件中的输入插件集合,其中一个是 [[inputs.cpu]]。您也可以在此处下载配置以对其进行更改,并手动添加其他输入和输出插件。然后,您可以从下载的配置文件而不是通过 API 运行 Telegraf。您可以通过点击弹出窗口右上角的“x”来关闭配置。
现在开始有趣的部分!“系统”插件集合包括一个预定义的仪表板,您现在可以通过点击“仪表板”来查看
点击“System”,您将被带到一个看起来像这样的页面
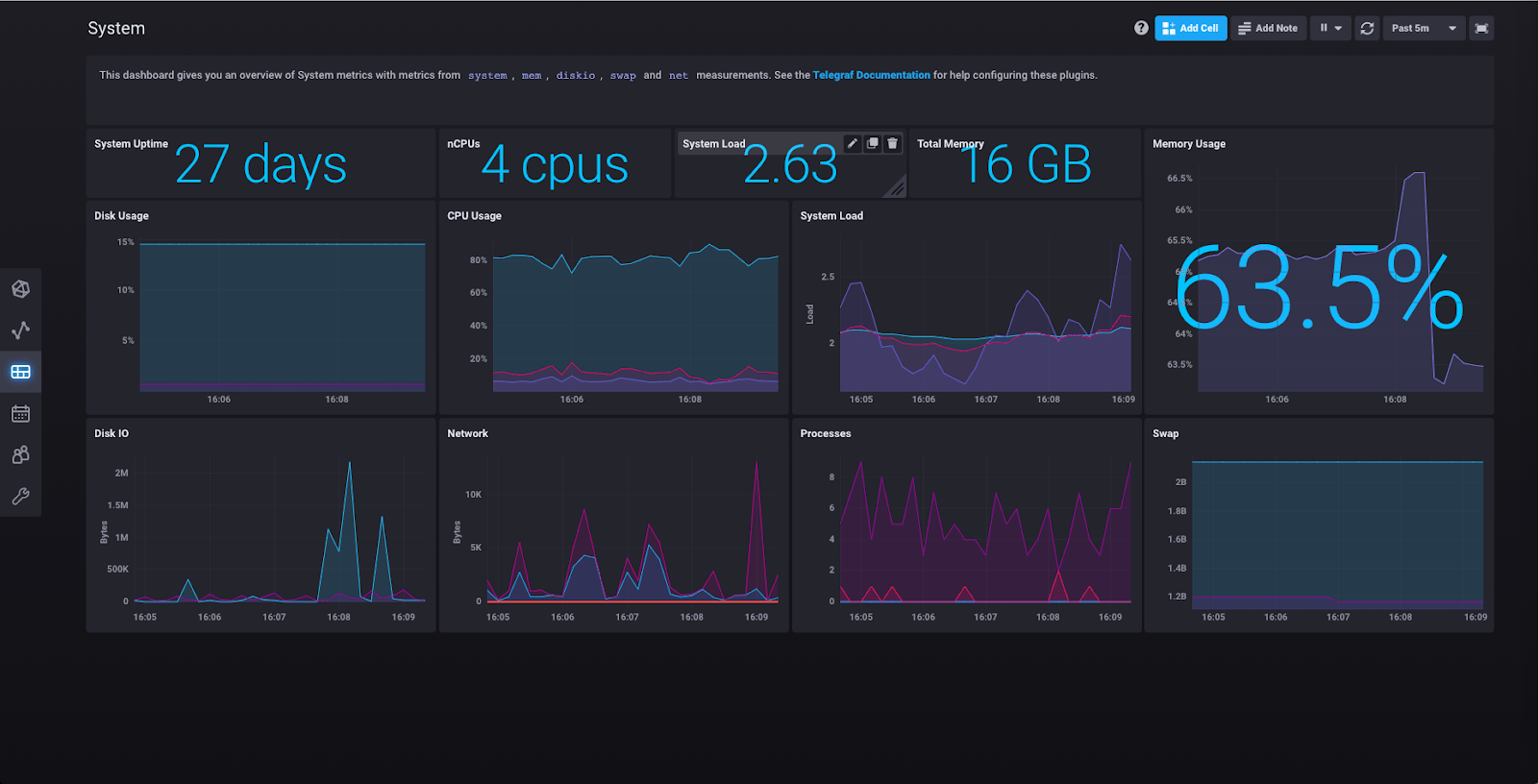
在这里,您可以看到“系统”插件集合收集有关您的机器的各种指标的结果。
使用 InfluxDB 2.0 查询数据
接下来,点击左侧边栏中的“数据浏览器”
您现在位于查询构建器中。在“_measurement”下,选择“cpu”。这应该弹出一个包含与该度量相关的字段的另一个块,如下所示
点击“usage_idle”,将弹出另一个块,其中包含标签键“cpu”及其所有可能的值
在本查询构建过程中的任何时候,您都可以点击“提交”并查看您构建的查询的结果
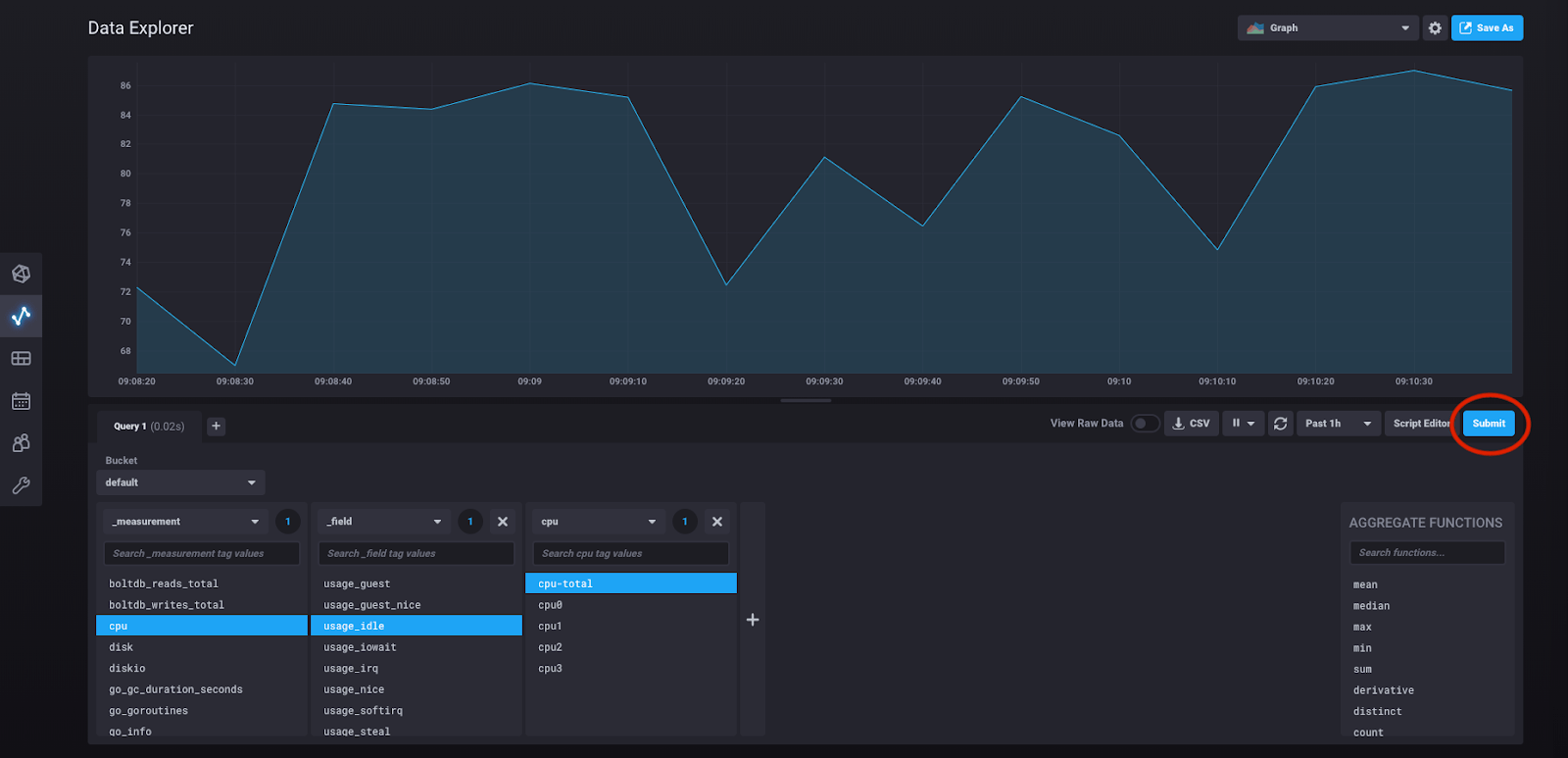
那么我们实际构建的查询是什么?我们可以通过点击“脚本编辑器”来查看它。
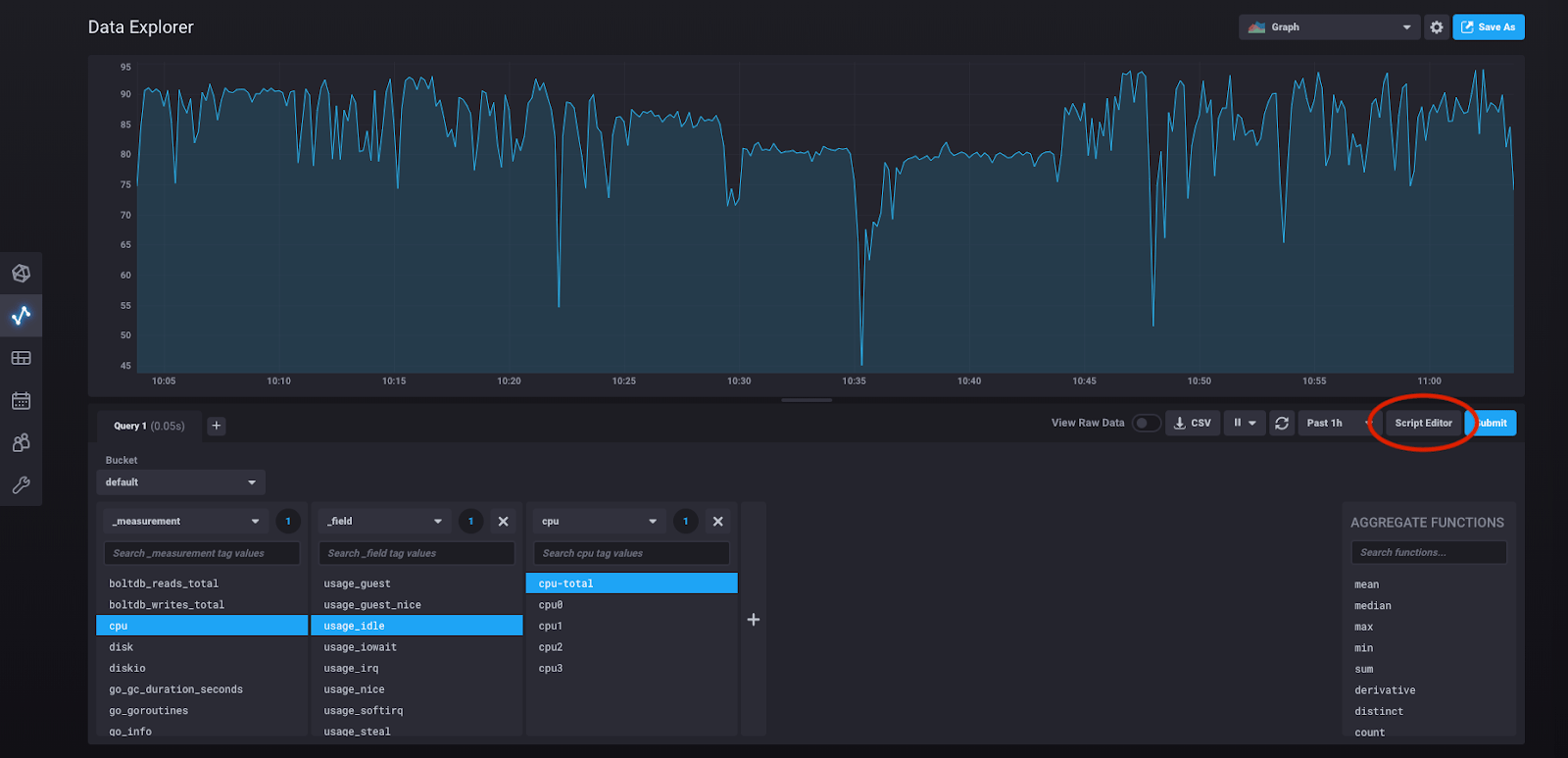
这样做会将我们带到此视图
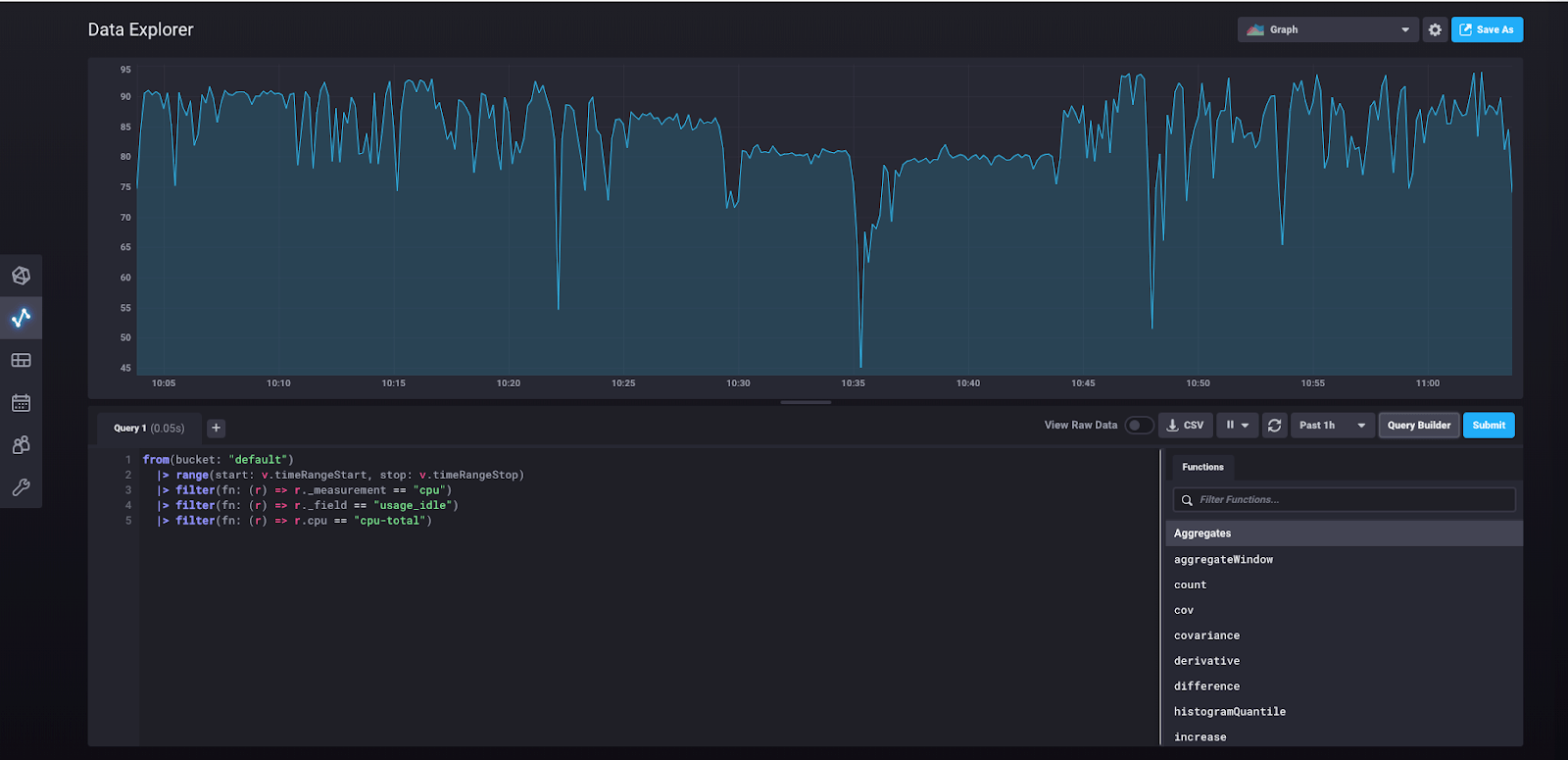
您在此处看到的是在查询构建器中构建并在您点击“提交”时运行的底层 Flux 查询。
使用 InfluxDB 2.0 写入数据
现在我们可以尝试手动将一些数据写入数据库(而不是通过采集器或 Telegraf 代理收集数据),并使用 UI 查询该数据。
在侧边栏中的“配置”下,点击“存储桶”。您应该看到此视图,其中包含我们之前创建的存储桶。
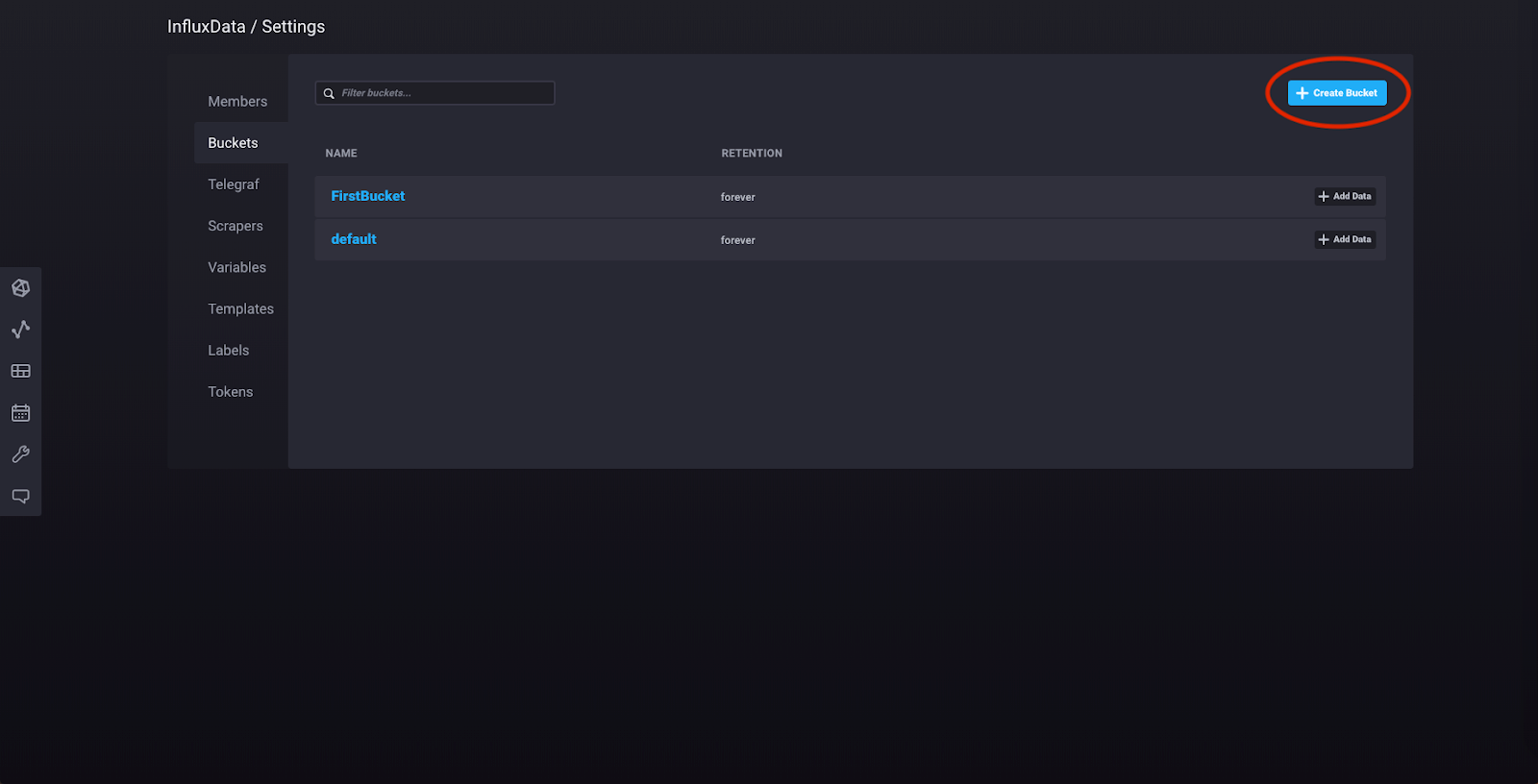
点击右上角的“创建存储桶”。
将您的存储桶命名为“trains”,并保持保留策略不变(将“多久清理数据?”设置为“从不”)。现在点击您的“trains”存储桶的“添加数据”。
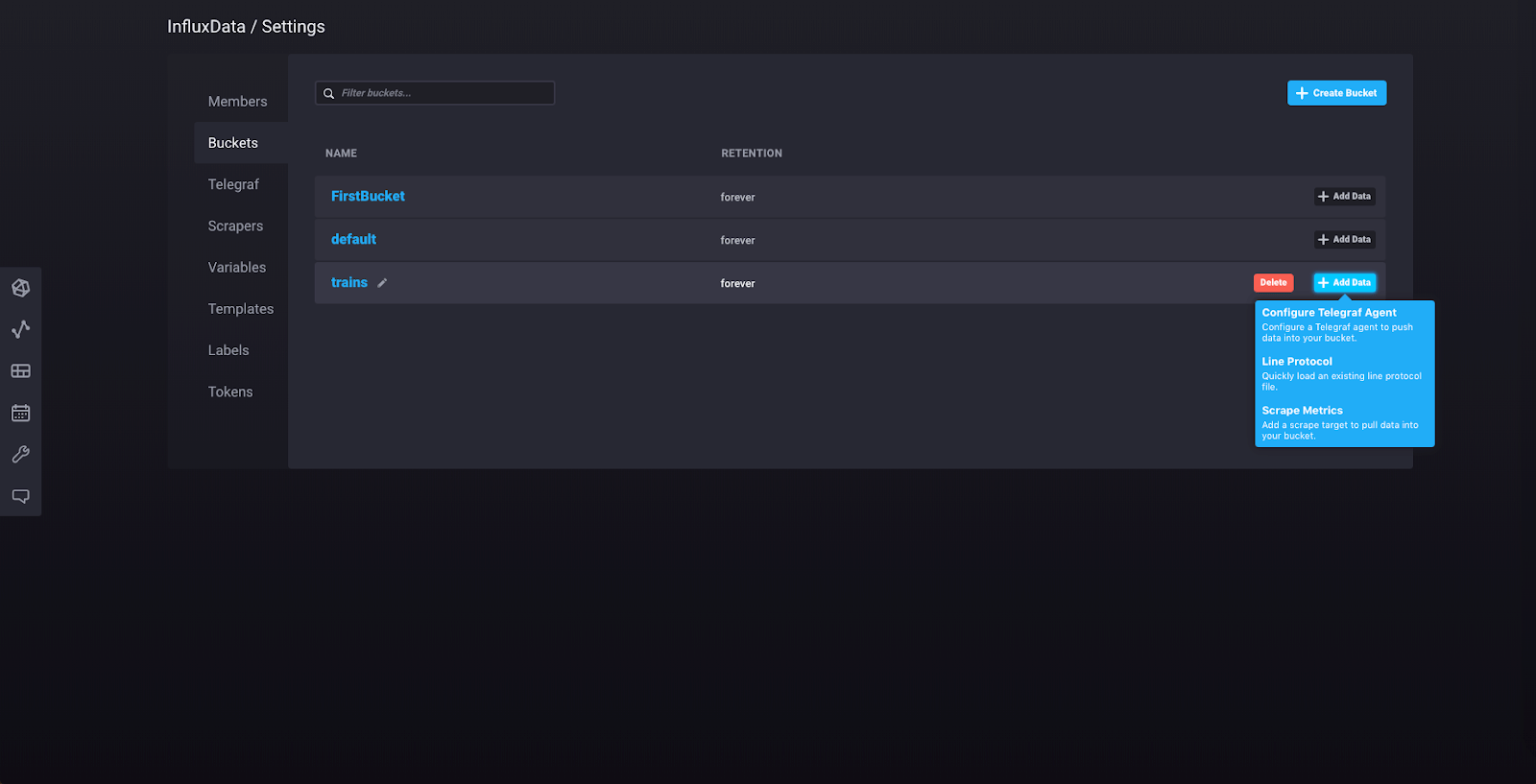
从下拉菜单中选择“Line Protocol”,您将看到此视图
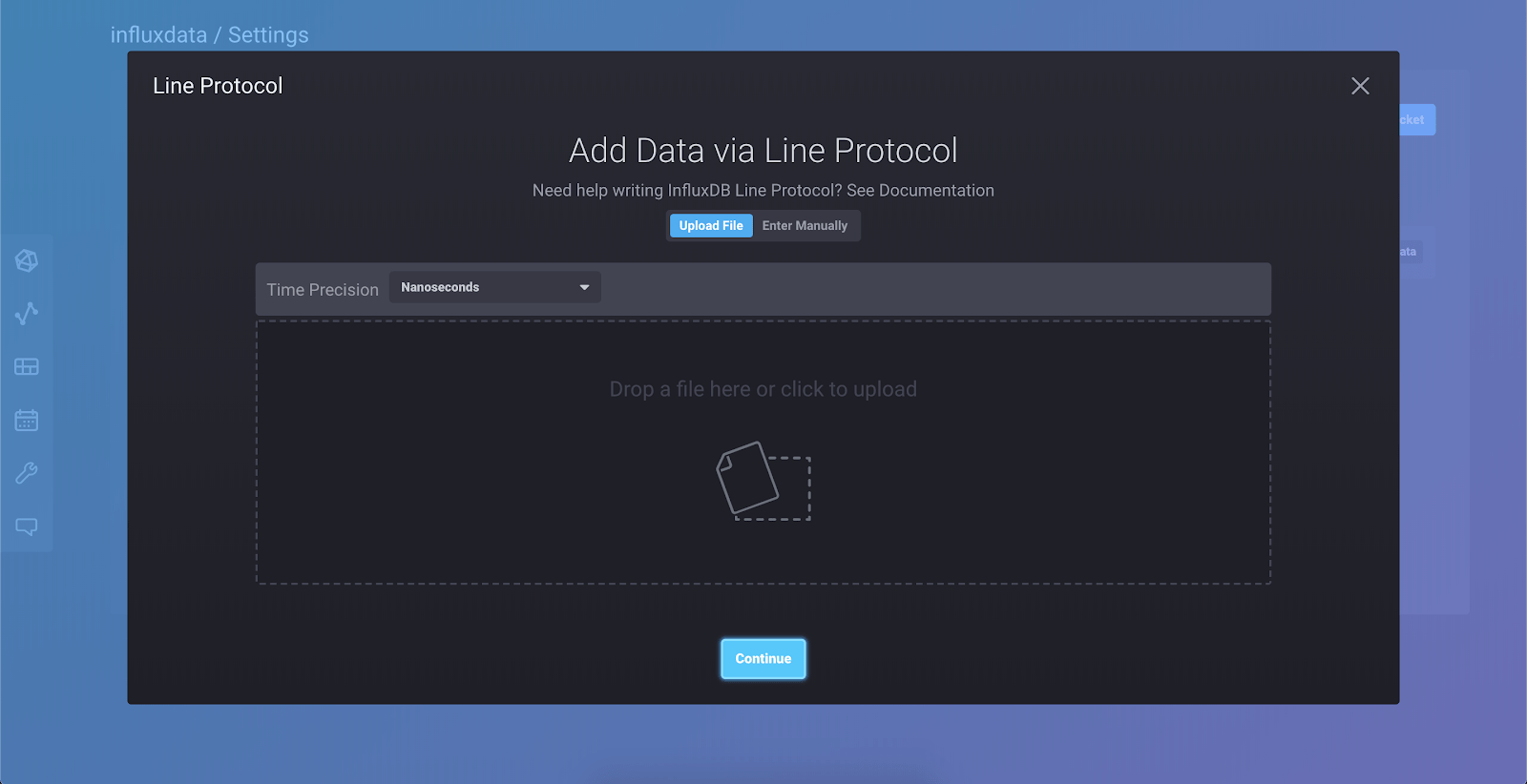
选择“手动输入”并将此行粘贴到窗口中
passengers_in_car,train=a,car=one,driver=gupta count=125现在点击“继续”。您刚刚将您的第一个点写入数据库!
让我们查询数据库以检索该数据点。点击左侧边栏中的“数据浏览器”。从“存储桶”下拉菜单中,选择“trains”。
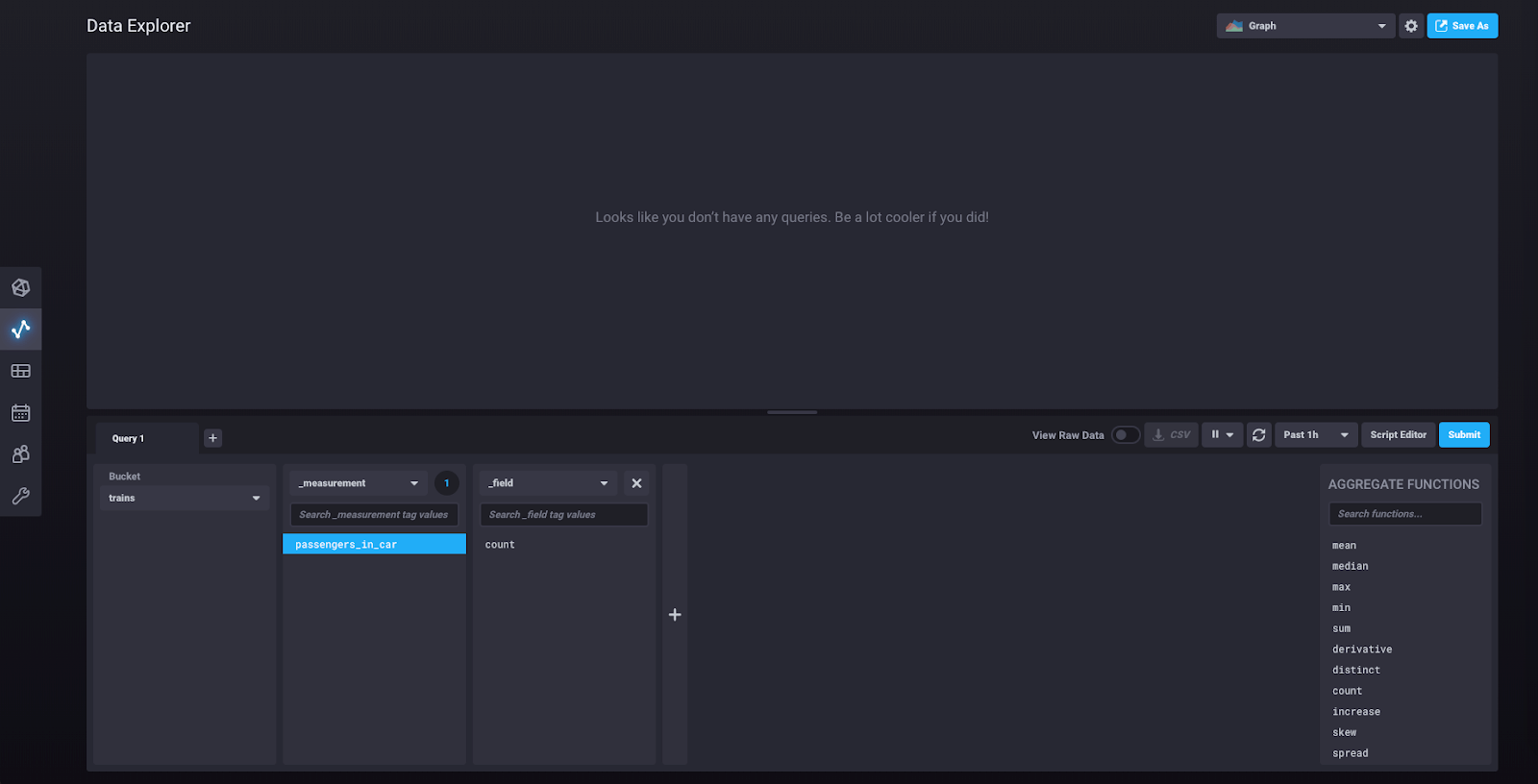
您现在应该能够看到“passengers_in_car”作为度量。点击它,将弹出另一个块,如下所示
此时,您可以点击“提交”,您将看到我们刚刚写入的单个数据点的图形。如果您点击右上角显示“图形”的下拉菜单,您会找到一个选项以表格形式查看您的数据。选择该选项。您现在应该看到此视图
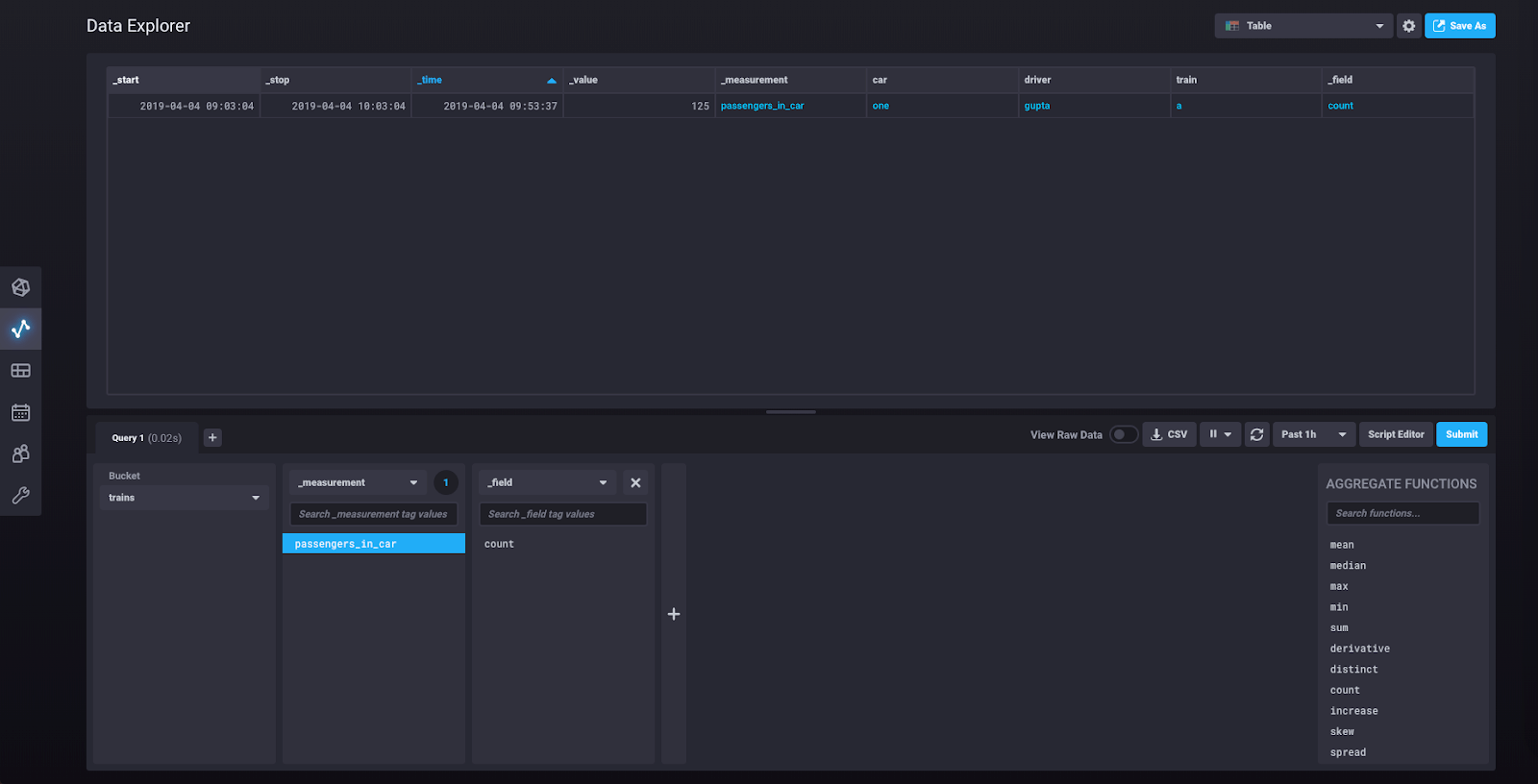
您现在可以通过点击“脚本编辑器”来查看底层查询:
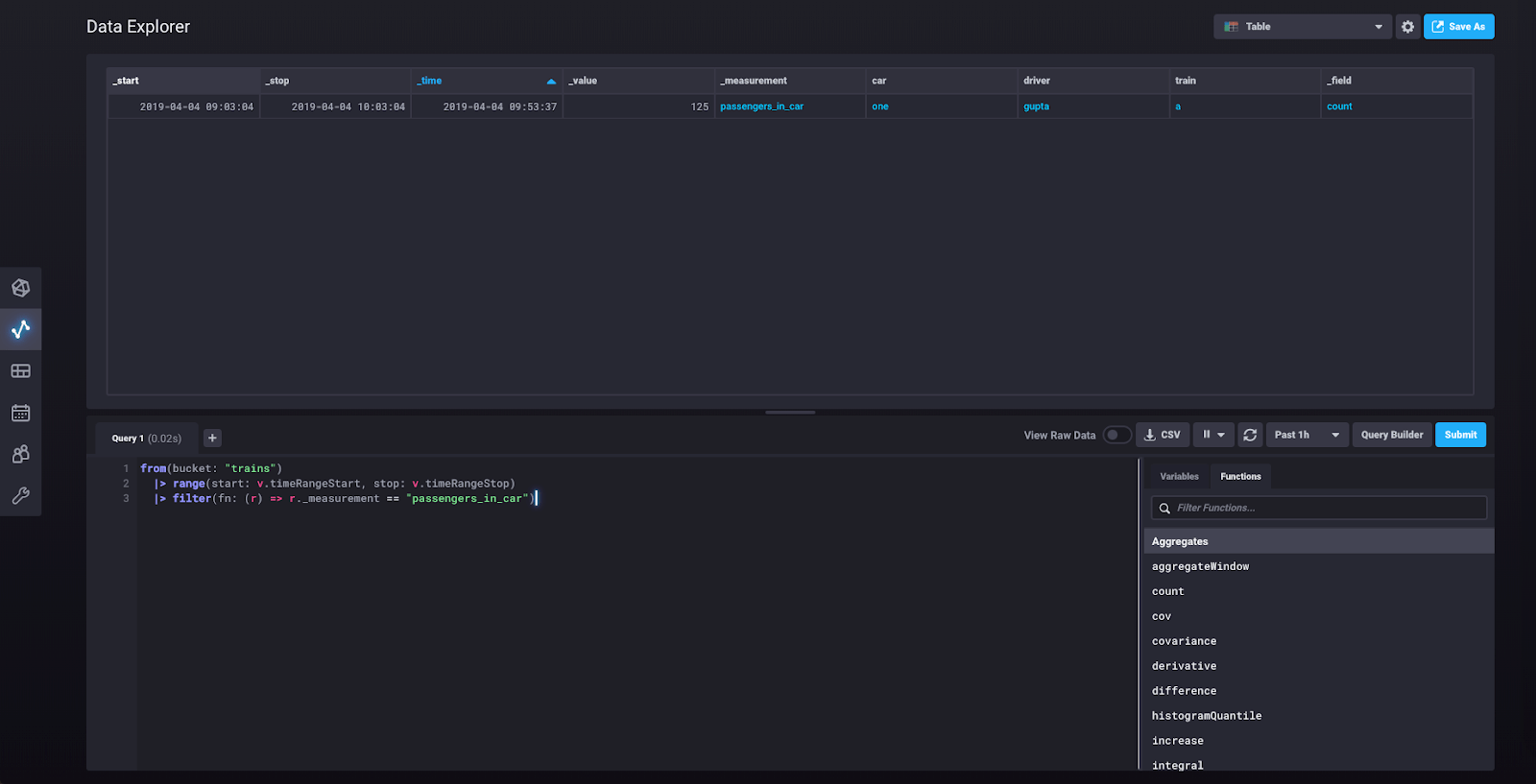
这向您展示了在您在查询构建器中创建查询时为您构建的 Flux 查询。您可以从此视图修改查询。
我们已经到了本教程的结尾,因此如果您想关闭 influxd 守护程序和 Telegraf 代理,您可以使用 Mac 上的 ctrl + c 退出它们。
InfluxDB 2.0 演练摘要
您现在已经看到了 InfluxDB 2.0 的一些主要功能,包括采集指标、运行 Telegraf、查询数据和写入数据。还有许多其他功能我们在此处尚未介绍,因此您可以期待在未来看到更多关于这些功能的文章。请注意,InfluxDB 2.0 尚未准备好用于生产环境,但我们欢迎您的反馈,并鼓励您在发布新版本时尝试 Alpha 版本。玩得开心!
